
Unity 游戏性能优化
Ultimate Guide to Profiling Unity Games
核心目标
- 流畅性能是创造沉浸式游戏体验的基础。
- 通过对游戏进行性能分析和优化,适配更广泛的平台和设备,从而扩大玩家基础,提高成功机会。
指南内容
- 提供关于如何在 Unity 中进行应用性能分析、内存管理和功耗优化的高级建议。
性能分析工作流程 (Profiling Workflow)
- 建立一个持续、端到端的性能分析工作流程对于高效游戏开发至关重要。
- 关键三步:
- 重大变更前分析 (Profile before changes): 建立性能基准。
- 开发过程中分析 (Profile during development): 跟踪变更,确保不破坏性能或超出预算。
- 变更后分析 (Profile after changes): 验证变更是否达到预期效果。
优化的益处
- 精简、高效的代码和优化的内存使用能提升低端和高端设备的性能表现。
- 关注散热控制 (Thermal control) 有助于节省移动设备的宝贵电量。
- 整体良好的性能可以提升玩家的舒适度,从而可能带来更高的用户接纳度 (Adoption) 和用户留存率 (Retention)。
Profiling 101
什么是 Profiler (性能分析器)
- 是开发者工具箱中极其有用的工具,用于识别代码中的内存和性能瓶颈。
- 如同侦探工具,帮助揭示应用性能滞后或内存分配过多的根本原因。
- 有助于理解 Unity 引擎的底层运行机制。
Unity 的 Profiling 工具
- Unity 自带多种分析工具,可在编辑器内使用或连接到硬件设备。
- 主要工具包括:
- Unity Profiler: 测量编辑器、播放模式下或连接到设备的应用性能。
- Profiling Core package: 提供 API,可向 Profiler 捕获的数据添加上下文信息。
- Memory Profiler: 提供深入的内存性能分析。
- Profile Analyzer: 用于比较两个性能分析数据集,评估代码更改对性能的影响。
- 建议同时使用目标平台的原生分析工具 (如 Arm, Apple, PlayStation, Xbox)。
性能分析方法 (Sample-based vs. Instrumentation)
- 两种常见方法:
- 基于采样 (Sample-based):
- 定期探测调用堆栈,收集统计数据。
- 通过提高采样频率来提高准确性,但这会增加开销。可能漏掉短时间的函数调用。
- 基于插桩 (Instrumentation-based):
- 在代码中添加标记 (Profiler markers),记录每个标记内代码执行的详细计时信息。
- 捕获每个标记的开始和结束事件,不会丢失信息,但依赖于标记的放置。
- 基于采样 (Sample-based):
- Unity Profiler 是基于插桩的。 它通过标记大部分 Unity API 接口和重要的脚本消息调用(如
Start(),Update()),在细节和开销之间取得了良好平衡。
基于插桩的 Profiling 细节 (Unity)
- 默认情况下,像
Start(),Update()等 MonoBehaviour 方法会被插桩标记。 - 当你的脚本调用已插桩的 Unity API 时(如
Camera.main会产生FindMainCamera标记),也能在 Profiler 中看到。 - 深度分析 (Deep Profiling):
- 自动为所有脚本方法调用(包括 C# 属性的 Getter/Setter)插入标记。
- 提供最全面的脚本分析细节,但会带来显著开销,可能影响报告的计时数据。
- 手动添加 Profiler Markers:
- 在关键函数中手动插入
Profiler Marker是一种有效的方式,可以在不承受深度分析全部开销的情况下,提高分析的详细程度。
- 在关键函数中手动插入
Profiler 模块 (Profiler Modules)
- Profiler 按帧捕获性能指标。
- 包含多个模块(如 CPU 使用率、GPU、渲染、内存、物理等),用于深入分析特定性能领域。
- Profiler 窗口下方会显示当前选中模块捕获的详细信息(如 CPU 使用率模块的时间线或层级视图)。
重要实践建议 (Important Best Practice)
- 注意: 在编辑器中进行性能分析与在独立构建版本中分析,结果会有很大差异。
- 强烈推荐: 将 Profiler 连接到在目标硬件上运行的独立构建版本 (Standalone Build) 进行分析。这样可以避免编辑器自身的开销,获得最准确的性能数据。
性能分析工作流程
设定帧预算 (Set a Frame Budget)
- 核心理念: 不能仅看重平均帧率 (FPS),应为每一帧设定一个明确的时间预算 (Frame Time Budget),单位为毫秒 (ms)。
- 计算方法: 帧时间预算 = 1000ms / 目标 FPS。
- 目标 30 FPS → 每帧预算 33.33 ms
- 目标 60 FPS → 每帧预算 16.66 ms
- 重要性:
- 提供清晰的优化目标,有助于创造更流畅、更一致的玩家体验。
- 避免因单帧耗时过长(即使平均 FPS 达标)导致的卡顿 (stutter/hitch)。
- 游戏进行中绝不能超出预算,非交互部分(如菜单、加载)允许例外。
- 对 VR 游戏尤其关键,稳定的高帧率可避免玩家不适,是平台认证的要求。
FPS vs. 帧时间 (Frame Time): 一个易误导的指标
- 常见误区: 玩家常用 FPS 衡量性能,但对开发者而言,它有欺骗性。
- 推荐指标: 使用帧时间 (Frame Time, ms) 进行性能基准测试和优化。
- 原因: FPS 的变化与实际耗时的变化不成线性关系。同样是增加 1.11ms 的耗时,可能导致 FPS 从 900 降到 450(看似腰斩),或者从 60 降到 56.25(看似小降)。
- 实践建议: 关注点应是让帧时间稳定在预算内,而不是盲目追求高 FPS(除非已低于目标帧率)。
移动端挑战:散热控制与电池寿命
- 散热控制 (Thermal Control):
- 是移动平台优化的最重要领域之一。
- 低效代码导致 CPU/GPU 持续高负载 → 芯片过热 → 操作系统降频 (Thermal Throttling) 以免损坏硬件 → 性能下降、卡顿、用户体验差。
- 电池寿命 (Battery Lifetime):
- 高帧率和高计算量(包括内存访问)会加速电池消耗并产生更多热量。
- 性能不佳可能导致无法覆盖低端设备,错失市场机会。
- 应对策略:
- 将散热视为系统级预算问题。
- 尽早进行性能分析,从项目开始就进行优化。
- 调整项目设置以适应目标硬件。
调整移动端帧预算
- 推荐做法: 为应对长时间游戏产生的热量和电池消耗,建议在帧预算内预留约 35% 的空闲时间。
- 这让芯片有时间冷却,减少过度耗电。
- 计算示例:
- 目标 30 FPS (预算 33.33ms): 实际执行时间目标 ≈ 33.33ms * (1 - 0.35) ≈ 21.66ms (通常取 22ms)。
- 目标 60 FPS (预算 16.66ms): 实际执行时间目标 ≈ 16.66ms * 0.65 ≈ 10.83ms (这在多数移动设备上难以稳定实现,且耗电量约是 30 FPS 的两倍)。
- 普遍选择: 基于以上原因,大多数移动游戏选择 30 FPS 作为目标。可通过
Application.targetFrameRate设置。 - 动态调频 (Frequency Scaling):
- 移动芯片会根据负载动态调整工作频率,这使得在 Profiler 中直接看帧时间判断优化效果变得复杂。优化可能导致频率降低(设备运行更凉爽),而不是帧时间显著缩短。
- 建议使用 FTrace、Perfetto 等原生工具监控移动芯片的频率、空闲时间和温度变化。
- 优化成功的标准:
- 在稳定达到目标帧率(如 30 FPS)的前提下,观察到设备工作负载降低(如芯片频率降低或温度下降)。
- 环境因素: 预留一部分帧预算也有助于应对现实世界中环境温度升高(如炎热天气)对设备散热能力的影响。
减少内存访问操作 (Reduce Memory Access Operations)
- 核心原因: DRAM(内存)访问在移动设备上是高耗电操作(Arm 举例 LPDDR4 约 100 皮焦耳/字节)。
- 降低内存访问的方法:
- 降低目标帧率。
- 在可能的情况下降低显示分辨率。
- 使用更简单的网格模型(减少顶点数量、降低顶点属性精度)。
- 使用纹理压缩和 Mipmapping 技术。
- 相关工具:
- 对于 Arm 或 Arm Mali 硬件,可使用 Arm Mobile Studio(特别是 Streamline Performance Analyzer)工具,通过其提供的性能计数器来识别内存带宽问题(例如由 Overdraw 引起的带宽饱和)。(注意:GPU 分析需 Arm Mali 硬件)
性能分析方法:从高层到低层 (From High- to Low-Level Profiling)
- 推荐流程: 采用自顶向下 (Top-to-bottom) 的方法。
- 第一步 (高层分析):
- 在禁用深度分析 (Deep Profiling disabled) 的情况下开始。
- 收集数据,记录在核心游戏循环中导致不必要托管内存分配 (GC.Alloc markers) 或 CPU 耗时过高的场景。
- 收集
GC.Alloc标记的调用堆栈信息。
- 第二步 (低层分析 - 如有必要):
- 如果高层分析的调用堆栈不够详细,无法追踪分配或性能下降的源头,则进行第二次性能分析,此时启用深度分析 (Deep Profiling enabled)。
- 记录要点:
- 记录耗时高的“罪魁祸首”时,要关注其相对于帧内其他部分的耗时比例。因为启用深度分析会增加整体开销,影响绝对耗时数据。
尽早并经常分析 (Profile Early and Often)
- 核心建议: 在项目开发的早期就开始性能分析,并经常进行,这样能获得最大的优化收益。
- 益处:
- 帮助团队理解并记住项目的“性能特征 (performance signature)”。
- 当性能突然下降时,能更容易发现问题发生的时间点并进行修复。
- 获取最准确结果:
- 始终在目标设备上运行构建版本 (Build) 进行分析。
- 结合使用平台特定的分析工具来深入了解各平台的硬件特性。
- 这种结合能提供跨所有目标设备的整体性能视图 (holistic view)。
建立硬件分层基准 (Establish Hardware Tiers for Benchmarking)
- 目的: 确保游戏在所有目标硬件上都能良好运行。
- 做法:
- 为你希望支持的每个平台和质量等级,确定硬件分层 (tiers) 或指定一个最低规格设备 (lowest-spec device)。
- 针对每个层级的最低规格设备进行性能分析和优化。
- 示例:
- 移动平台:可能设定高、中、低三个层级,通过质量设置开关功能。优化时需确保每个层级的最低规格设备达标。
- 主机平台:若同时为 PlayStation 4 和 PlayStation 5 开发,则必须在两个平台上都进行性能分析。
查找瓶颈 (Find the Bottlenecks): CPU 限制 vs. GPU 限制
- 目标: 判断应用程序的性能瓶颈在于 CPU (CPU-bound) 还是 GPU (GPU-bound)。
- 识别方法:
- 平台工具: 某些平台(如 Xcode for iOS)可以直接显示 CPU 和 GPU 的耗时对比图。(注意:移动设备上显示的 CPU 时间通常包含等待 VSync 的时间)
- Unity Profiler: 即使某些平台难以获取 GPU 计时数据,Unity Profiler 也提供了足够的信息来定位瓶颈。
- 使用 CPU Usage 模块 的 Timeline 视图可以查看 CPU 的完整活动,包括等待 GPU (WaitForGPU 或类似标记) 的时间。
- 熟悉常见的 Profiler markers (标记名称可能因平台而异),通过在各目标平台上抓取性能数据来了解项目的“正常”表现。
- VSync (垂直同步) 解释:
- 将应用的帧率与显示器的刷新率同步。
- 作用:防止画面撕裂 (screen tearing),减轻 GPU 负担。
- 影响:如果游戏运行速度快于刷新率对应的时间(如 60Hz -> 16.66ms),会被强制等待,表现为恒定帧率。
- 可在 Unity 的质量设置 (Quality Settings) 中配置 VSync Count。
- 瓶颈判断与优化策略:
- 瓶颈定义: 性能受限于耗时最长的那个部分(CPU 线程或 GPU)。优化应聚焦于瓶颈。
- 示例场景分析 (假设目标 30fps ≈ 33.3ms, VSync 开启):
- CPU 25ms, GPU 20ms: CPU 限制,但均在预算内。优化任何一方不会提高帧率至 30fps 以上(除非两者都降到 16.66ms 以下才能跳到 60fps)。
- CPU 40ms, GPU 20ms: CPU 限制,超出预算。需优化 CPU。优化 GPU 无益;甚至可以考虑将部分 CPU 工作转移到 GPU (如使用 Compute Shaders) 来平衡负载。
- CPU 20ms, GPU 40ms: GPU 限制,超出预算。需优化 GPU。
- CPU 40ms, GPU 40ms: 两者都是瓶颈,超出预算。需同时优化 CPU 和 GPU,使两者都低于 33.3ms。
Structure of a frame, the CPU and GPU | Introduction to profiling in Unity
Unity CPU Optimization: Is Your Game… Draw Call Bound?
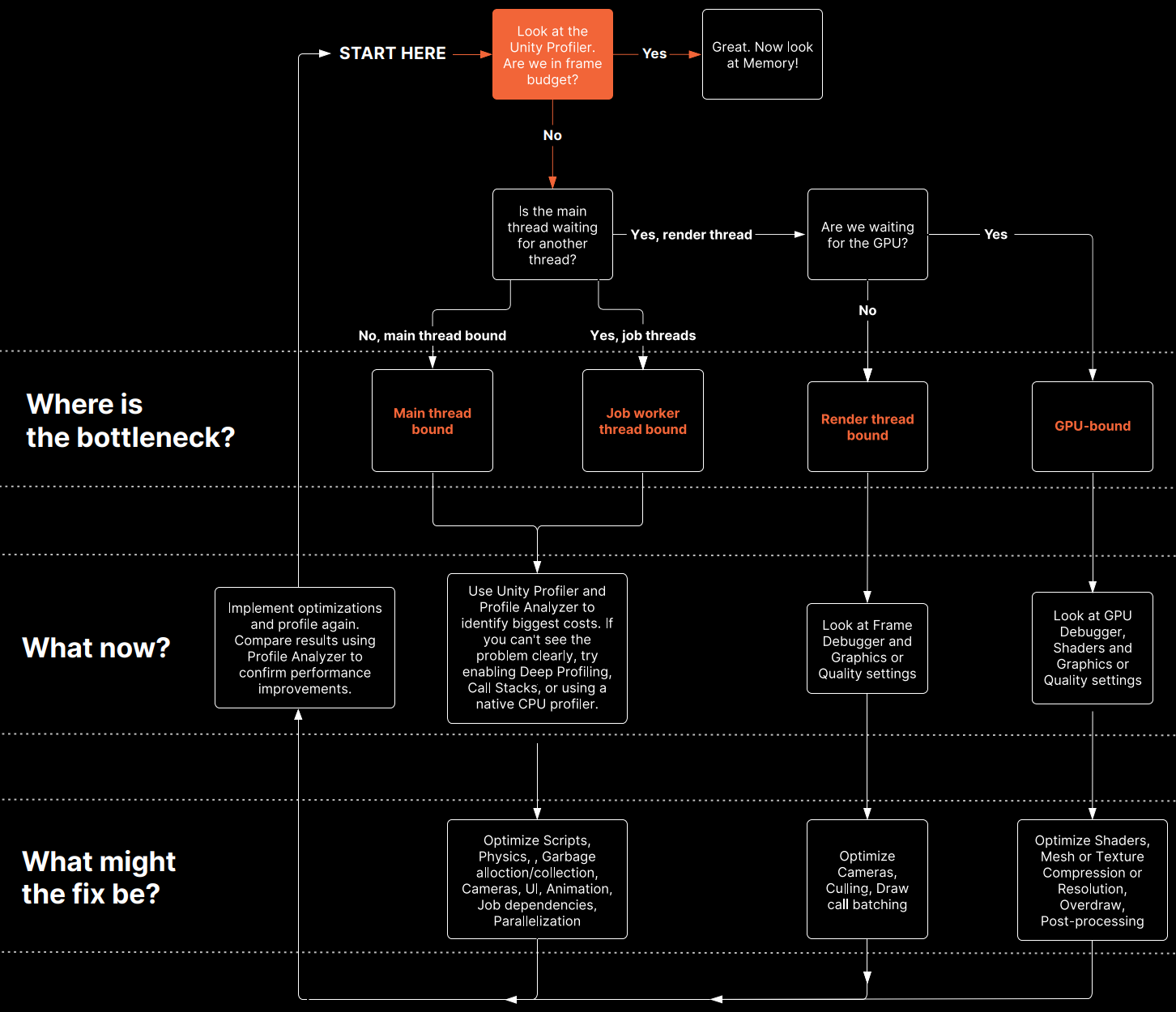
是否在帧预算内?(Are you within frame budget?)
- 重要性: 在开发过程中尽早并经常进行性能分析,有助于确保所有 CPU 线程和整体 GPU 帧时间都保持在帧预算之内。
- 示例解读 (移动端游戏):
- 一个持续进行性能分析优化的 Unity 手游项目。高配手机目标 60fps,中低配目标 30fps。
- 关键标记 (
WaitForTargetfps- 黄色): 在 30fps 目标下(Application.targetFrameRate = 30且 VSync 开启),主线程实际工作在约 19ms 完成,剩余时间显示为WaitForTargetfps,直到 33.33ms 的帧预算时间结束才开始下一帧。 - 标记含义: 虽然显示为 Profiler 标记,但此时主 CPU 线程基本处于空闲 (idle) 状态。
- 好处: 允许 CPU 降温,并最大限度地减少电池消耗。
- 标记变体: 等待标记的名称可能因平台或 VSync 是否禁用而异(如
Gfx.WaitForPresent等)。 - 核心检查点:
- 主线程是否在帧预算内完成工作?(或刚好达到预算,并显示某种等待 VSync 的标记)
- 其他线程(渲染线程、工作线程)是否有空闲时间?
- 空闲时间的表现:
- 通常显示为灰色或黄色的 Profiler 标记。
- 渲染线程空闲:
Gfx.WaitForGfxCommandsFromMainThread表示它已完成向 GPU 发送上一帧的绘制调用 (Draw Call),正在等待 CPU 发来下一帧的请求。 - 工作线程空闲:
Idle标记(例如,在完成Canvas.GeometryJob后)。
- VSync 间隔观察:
- 可以通过观察 Timeline 视图中
Gfx.Present标记 逐帧的结束时间来判断 VBlank(垂直消隐)间隔。 - 可以使用 Timeline 区域的时间刻度尺测量两个
Gfx.Present之间的时间。
- 可以通过观察 Timeline 视图中
- 结论: 大量的等待/空闲标记表明应用程序舒适地运行在帧预算之内。
如果游戏在帧预算内 (If your game is in frame budget)
- 恭喜! 性能分析工作暂时完成。
- 下一步建议: 运行 Memory Profiler,确保应用程序也符合其内存预算。
CPU 限制 (CPU-bound)
- 条件: 游戏的 CPU 耗时超出了帧预算。
- 下一步: 调查 CPU 的哪个部分是瓶颈,即哪个线程最繁忙。
- 关键原则: 性能分析的目的是识别瓶颈作为优化目标。切勿猜测,否则可能优化了非瓶颈部分,导致性能提升甚微甚至恶化。
- 现代 CPU 特点: 拥有多个核心,不同线程可在不同核心上独立并行工作。瓶颈通常是某个特定线程,而不是整个 CPU。
- Unity 中常见的瓶颈线程:
- 主线程 (Main Thread):
- 默认执行所有游戏逻辑/脚本 (
Update,Start等)。 - 大部分特性和系统(物理、动画、UI、渲染的准备工作如剔除/排序/合批列表生成)都在此线程。
- 最常见的瓶颈所在。
- 默认执行所有游戏逻辑/脚本 (
- 渲染线程 (Render Thread):
- 接收主线程生成的渲染列表。
- 将 Unity 内部的、平台无关的渲染指令翻译成特定平台所需的图形 API 调用,提交给 GPU。
- 工作线程 (Job Worker Threads):
- 执行由开发者(使用 C# Job System)或 Unity 内部系统(物理、动画、渲染的部分功能)调度的任务。
- 目的是分担主线程的负载。
- 主线程 (Main Thread):
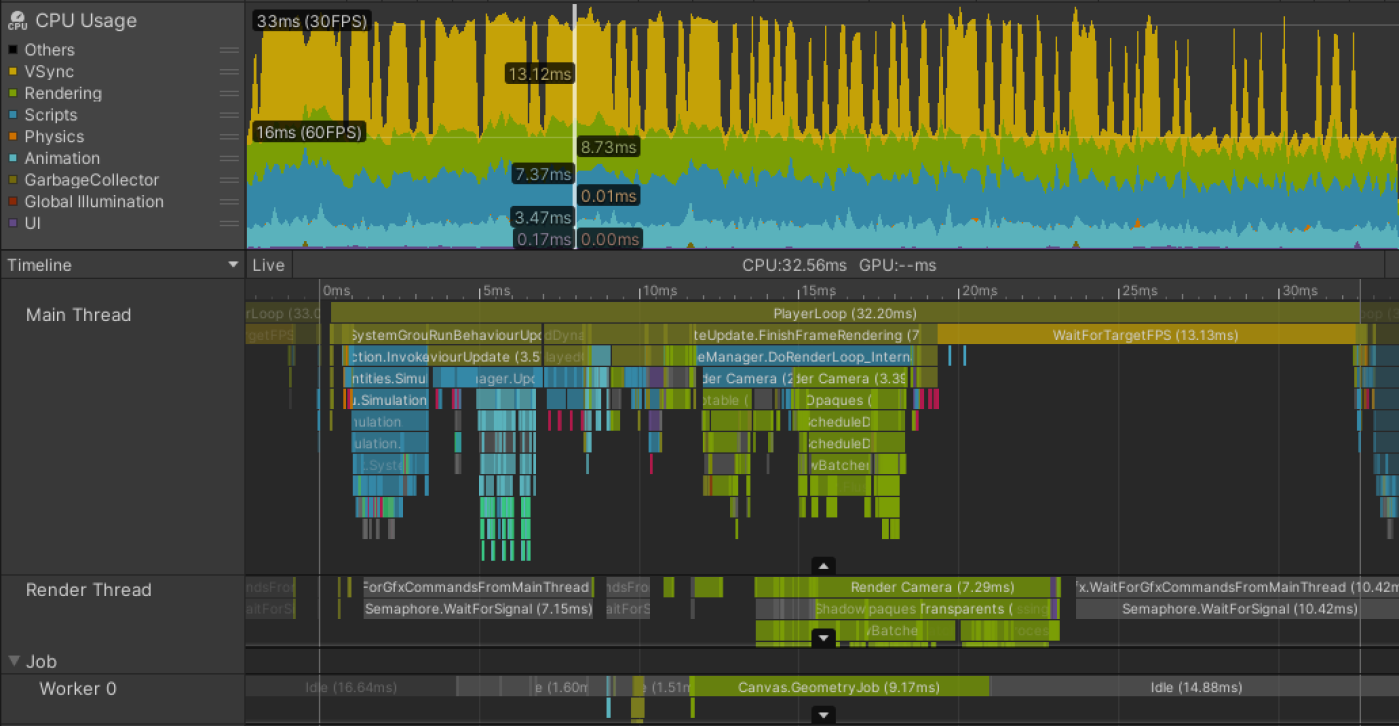
主线程瓶颈分析 (Main Thread Bound)
- 示例场景 (Meta Quest 2 - VR):
- VR 设备为避免晕动症,通常需要高帧率(如 72fps → 13.88ms, 120fps → 8.33ms)。
- 示例中主线程耗时 > 45ms (帧率 < 22fps),即使目标是 30fps 也远超预算。
- Profiler 表现:
- 主线程在整个帧期间都处于繁忙状态,几乎没有或完全没有等待/空闲标记。
- 渲染线程和工作线程可能看起来正常(有空闲时间)。
- 调查步骤: 找出主线程上耗时最长的部分。
- 示例分析:
PostLateUpdate.FinishFrameRendering(16.23ms):- 内部有 5 个
Inl_RenderCameraStack标记 → 5 个活动相机在渲染场景。 - 问题: 每个相机都会触发完整的渲染管线(剔除、排序、合批等)。
- 优先级最高的优化: 减少活动相机数量,理想情况是只有一个。
- How to optimize game performance with Camera usage: Part 1
- 内部有 5 个
BehaviourUpdate(所有MonoBehaviour.Update()): 耗时 7.27ms。- 托管堆内存分配 (Managed Heap Allocations):
- Timeline 中显示为洋红色 (magenta) 部分,或在 Hierarchy 视图用
GC.Alloc过滤。 GC.Alloc标记显示的耗时 (如 0.33ms) 具有误导性!- 它只记录了开始时间戳和分配大小,为保证可见性仅赋予极短时间。
- 实际分配耗时可能更长(尤其当需要向操作系统申请新内存时)。
- 如何观察实际影响?
- 在分配代码周围手动添加
Profiler Marker。 - 在深度分析模式下,
GC.Alloc标记之间的间隙 (gaps) 可以间接反映耗时。
- 在分配代码周围手动添加
- 内存分配的隐藏成本:
- 向 OS 请求内存可能影响移动设备的功耗预算,导致 CPU/GPU 降频。
- 新内存需加载到 CPU L1 缓存,会挤出现有缓存行 (Cache lines)。
- 可能直接或间接触发增量或同步垃圾回收 (Garbage Collection)。
- Timeline 中显示为洋红色 (magenta) 部分,或在 Hierarchy 视图用
Physics.FixedUpdate(帧初 4 个实例): 共 4.57ms。LateBehaviourUpdate(所有MonoBehaviour.LateUpdate()): 耗时 4ms。- Animators (动画): 约 1ms。
- 示例分析:
- 优化方向: 优先优化耗时最长的部分,以获得最大性能提升。
- 主线程常见优化点:
- 物理 (Physics)
- MonoBehaviour 脚本更新 (
Update,LateUpdate等) - 垃圾分配与回收 (Garbage Allocation / Collection)
- 相机剔除与渲染 (Camera culling and rendering)
- 不佳的绘制调用批处理 (Poor draw call batching - CPU 侧)
- UI 更新、布局与重建 (UI updates, layouts and rebuilds)
- 动画 (Animation)
- 辅助诊断工具:
- 耗时脚本但原因不明: 手动添加
Profiler Markers或启用Deep Profiling查看完整调用栈。 - 脚本中的内存分配: 在 Profiler 中启用
Allocation Call Stacks查看来源;或用Deep Profiling;或使用Project Auditor(可按内存问题过滤代码)。 - 批处理问题: 使用
Frame Debugger。
- 耗时脚本但原因不明: 手动添加
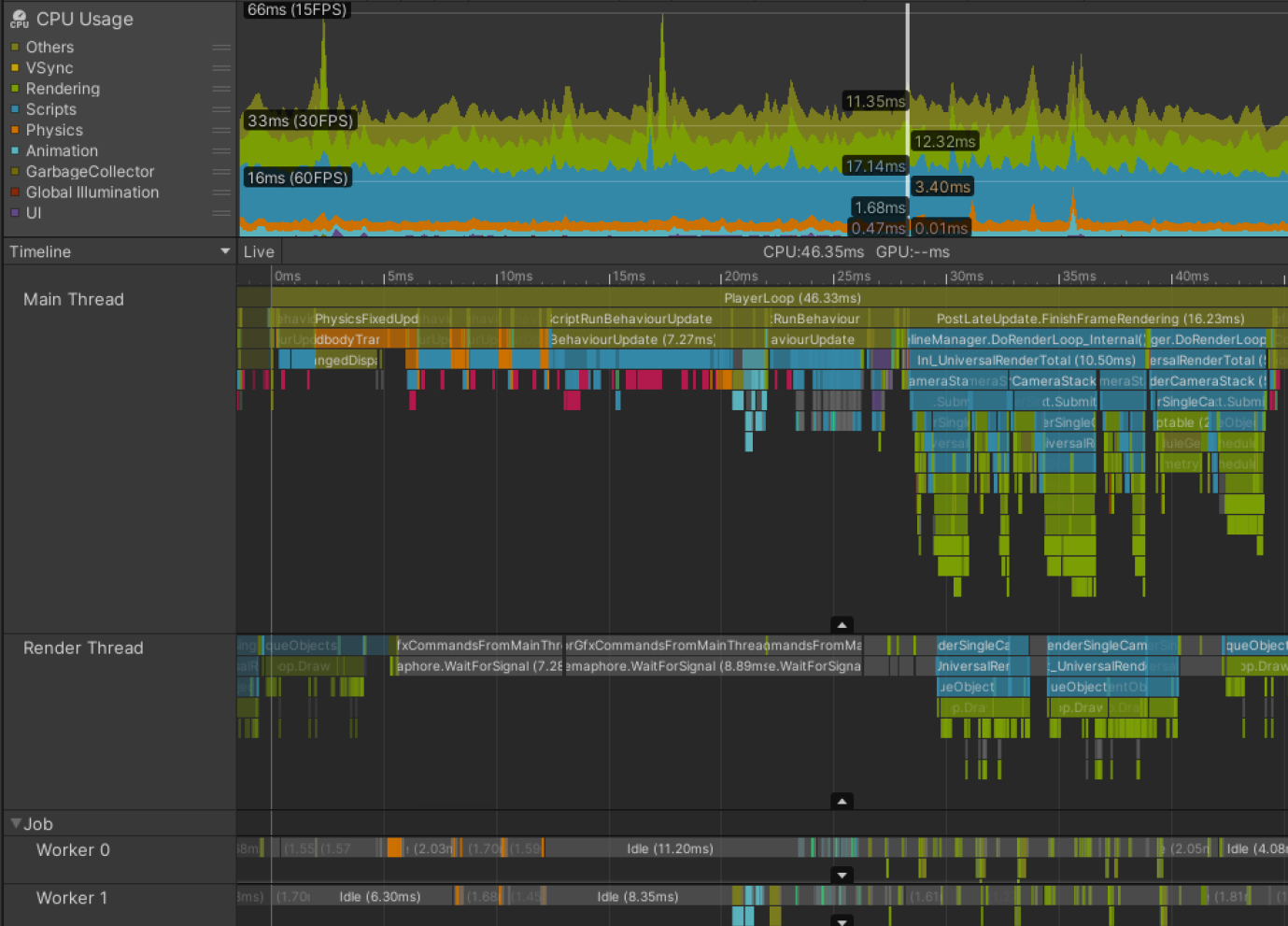
渲染线程瓶颈分析 (Render Thread Bound)
- 示例场景 (主机游戏): 等距视角,目标 33.33ms。
- Profiler 表现:
- 主线程在帧开始时等待渲染线程 (
Gfx.WaitForPresentOnGfxThread)。 - 同时,渲染线程仍在处理上一帧的渲染命令 (
Camera.Render等标记颜色较深)。 - 当前帧的渲染命令在渲染线程上耗时 > 100ms,导致下一帧主线程继续等待。
- 主线程在帧开始时等待渲染线程 (
- 示例根源分析:
- 渲染设置复杂:9 个不同相机、替换着色器 (Replacement Shaders) 导致额外 Pass、使用了前向渲染路径 (Forward Rendering) 渲染了 130+ 个点光源(每个光源可能增加多个透明绘制调用)。
- 结果: 每帧超过 3000 个绘制调用 (Draw Call)。
- 渲染线程常见优化点:
- 不佳的绘制调用批处理 (Poor draw call batching): 尤其在使用旧图形 API (如 OpenGL ES, DirectX 11) 时。
- 过多的相机 (Too many cameras): 除非是分屏多人游戏,否则通常只需要一个活动相机。
- 不佳的剔除 (Poor culling): 导致绘制了过多物体。
- 检查相机的视锥体 (Frustum) 尺寸和剔除层蒙版 (Cull Layer Masks)。
- 考虑启用遮挡剔除 (Occlusion Culling)。
- 可根据场景布局创建自定义的简单遮挡剔除系统。
- 检查投射阴影的物体数量(阴影剔除与常规剔除是分开的 Pass)。
- 辅助诊断工具:
- Rendering Profiler 模块: 显示每帧的 Draw Call Batches 和 SetPass 调用数量概览。
- Frame Debugger: 最佳工具,用于调查渲染线程具体向 GPU 发送了哪些绘制调用批次。
工作线程瓶颈分析 (Worker Threads Bound)
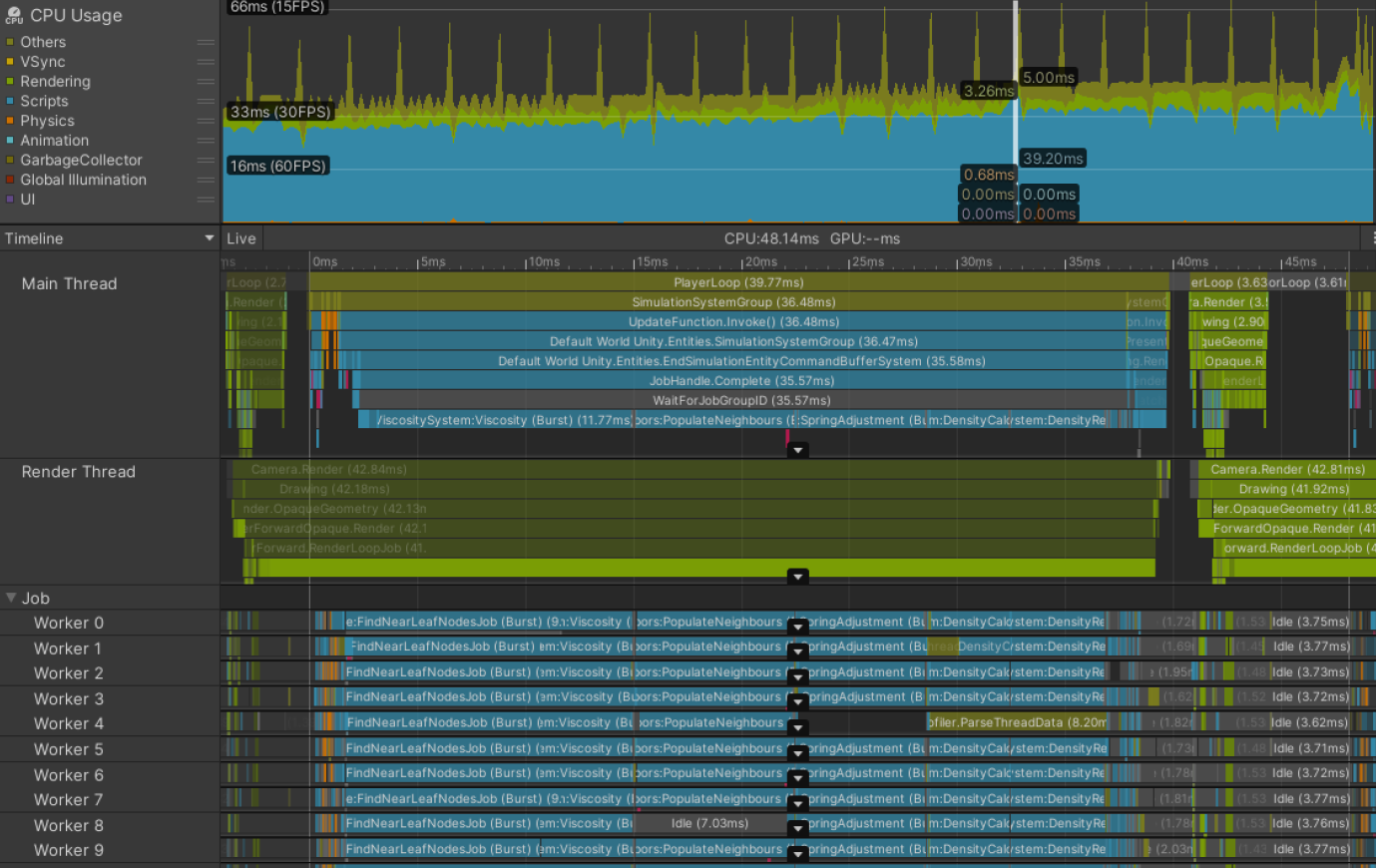
- 普遍性: 不如主线程或渲染线程瓶颈常见。
- 发生场景: 更多出现在使用 DOTS (Data-Oriented Technology Stack) 的项目中,特别是当大量工作通过 C# Job System 移到工作线程时。
- 示例场景 (DOTS 粒子流体模拟): 编辑器 Play 模式。
- Profiler 初看: 工作线程被 Burst 编译的 Jobs 紧密填充,似乎成功将工作移出主线程。
- 问题迹象:
- 帧时间 48.14ms (远超预算)。
- 主线程出现灰色的
WaitForJobGroupID标记,耗时 35.57ms。
WaitForJobGroupID含义: 主线程调度了异步 Jobs,但在这些 Jobs 完成之前需要它们的计算结果,导致主线程阻塞等待。等待期间主线程会尝试执行其他已就绪的 Job(标记下方蓝色部分)以加速完成。- 示例根源分析:
- Jobs 虽然经过 Burst 编译,但计算量仍然很大。
- 可能原因:空间查询结构(用于查找临近粒子)需要优化或替换;Jobs 的调度时机(应尽早调度,晚点取结果);模拟的粒子数量过多。
- 解决方案思路: 需要分析 Jobs 代码,添加更细粒度的
Profiler Markers来定位耗时部分。 - 其他情况: 即使只有一个长时间运行的 Job 在单个工作线程上,如果主线程需要结果的时间早于 Job 完成时间,也会导致主线程等待(如上图所示)。
- 工作线程瓶颈/同步点 (Sync Points) 的常见原因:
- Jobs 没有被 Burst 编译器编译。
- 长时间运行的 Jobs 在单个线程上执行,而没有并行化到多个工作线程。
- 从 Job 被调度到需要其结果之间的时间不足。
- 帧内存在多个“同步点”,要求所有(或相关)Jobs 必须立即完成。
- 辅助诊断工具:
- CPU Usage Profiler 模块 Timeline 视图中的 Flow Events 功能:可视化 Jobs 的调度时间点和主线程期望获取结果的时间点。
- 参考 DOTS 最佳实践指南。
GPU 限制 (GPU-bound)
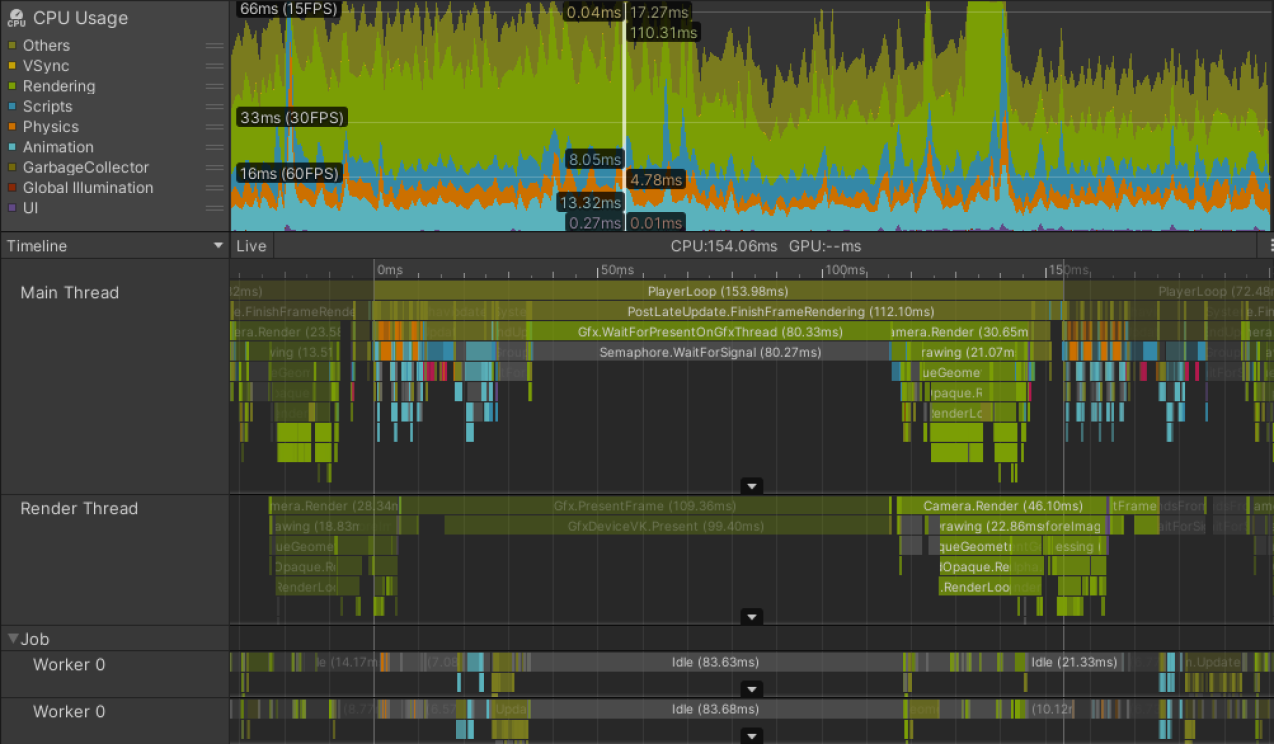
- 条件: 应用程序的性能受限于 GPU 的处理速度。
- Profiler 表现:
- 主线程花费大量时间在如
Gfx.WaitForPresentOnGfxThread的标记中。 - 同时,渲染线程显示如
Gfx.PresentFrame或<GraphicsAPIName>.WaitForLastPresent等标记。(这些通常表示等待 GPU 完成上一帧的渲染)。
- 主线程花费大量时间在如
- 示例场景 (移动端游戏): 三星 Galaxy S7 (Vulkan API)。
- 示例分析:
Gfx.PresentFrame标记时间极长,表明大部分时间是等待 GPU,而非仅等待 VSync。 - 示例根源: 某个游戏事件触发了一个着色器 (Shader),导致 GPU 渲染的绘制调用数量增加了两倍。
- GPU 性能常见优化点:
- 昂贵的全屏后处理效果 (Post-processing effects): 如环境光遮蔽 (Ambient Occlusion)、辉光 (Bloom)。
- 昂贵的片段着色器 (Fragment Shaders):
- 存在分支逻辑 (Branching)。
- 使用了完整浮点精度 (full float precision) 而非半精度 (half precision)。
- 过度使用寄存器,影响 GPU 的波前占用率 (wavefront occupancy)。
- 透明渲染队列中的过度绘制 (Overdraw): 由低效的 UI、粒子系统或后处理效果引起。
- 过高的屏幕分辨率: 如 4K 显示器或移动设备上的 Retina 屏。
- 微小三角形 (Micro triangles): 由过于密集的网格几何体或缺少 LOD (Level of Detail) 引起,在移动 GPU 上尤其成问题,但也可能影响 PC 和主机 GPU。
- 缓存未命中 (Cache misses) 和浪费的 GPU 内存带宽: 由未压缩纹理、或高分辨率纹理未使用 Mipmaps 引起。
- 几何着色器 (Geometry Shaders) 或曲面细分着色器 (Tesselation Shaders): 如果启用了动态阴影,这些可能每帧运行多次。
- 辅助诊断工具:
- Frame Debugger: 可以快速了解发送到 GPU 的绘制调用批次是如何构造的,但无法提供具体的 GPU 耗时信息。
- GPU Profiler (外部工具): 调查 GPU 瓶颈的最佳方式。需要使用适合目标硬件和图形 API 的 GPU 性能分析器(如 Xcode Metal Debugger, RenderDoc, Snapdragon Profiler, Arm Mobile Studio, PIX for Windows, NSight 等)。
内存分析 (Memory Profiling)
内存分析的目的与相关性
- 主要目的: 内存分析主要与运行时性能 (Runtime Performance) (即 CPU/GPU 速度) 关系不大。其主要用途在于:
- 测试应用程序是否超出目标硬件平台的内存限制。
- 调查游戏崩溃问题(通常由内存不足引起)。
- 次要相关性: 在某些情况下也可能与性能相关,例如:
- 当为了提升 CPU/GPU 性能而做出的改动增加了内存使用量时,需要评估这种权衡。
- 核心作用: 帮助确保应用程序稳定运行,不因内存问题而失败。
Unity 中的内存分析工具
Unity 提供两种主要方式来分析应用程序的内存使用情况:
- Memory Profiler 模块 (Memory Profiler module):
- Unity 编辑器内置的 Profiler 模块之一。
- 提供关于应用程序内存使用位置的基本信息。
- Memory Profiler 包 (Memory Profiler package):
- 需要通过 Package Manager 额外添加到项目中的 Unity 包。
- 在编辑器中添加一个独立的 Memory Profiler 窗口。
- 提供更深入、更详细的内存分析能力。
- 核心功能:
- 存储和比较内存快照 (Snapshots),用于查找内存泄漏 (Memory Leaks)。
- 查看内存布局 (Memory Layout),以发现内存碎片 (Memory Fragmentation) 问题。
- 共同能力: 使用这些工具可以监控内存使用、定位内存占用超预期的区域、发现并改善内存碎片问题。
- 本节说明: 此处仅为简要介绍,详细解释请参阅指南后续的“Unity profiling and debug tools”部分。
理解和定义内存预算 (Understand and define a memory budget)
- 重要性: 对于多平台开发,理解并为目标设备的内存限制制定预算至关重要。
- 实践:
- 设计场景和关卡时,必须遵守为每个目标设备设定的内存预算。
- 设定限制和指导方针,确保应用能在各平台硬件规格内良好工作。
- 查找限制: 参考目标平台的开发者文档获取设备内存规格(例如,文档说明 Xbox One 主机可供前台游戏使用的最大内存约为 5GB)。
- 内容预算: 设定针对特定内容类型的预算也很有用,例如:
- 网格 (Mesh) 和着色器 (Shader) 的复杂度。
- 纹理压缩 (Texture Compression)。
- 这些都直接影响内存分配量,可在开发周期中作为参考。
确定物理 RAM 限制 (Determine physical RAM limits)
- 前提: 每个目标平台都有内存上限,了解它是设定预算的第一步。
- 工具应用: 使用 Memory Profiler Package 查看捕获的快照。
- Hardware Resources 视图会显示设备的物理 RAM 和 显存 (VRAM) 大小。
- 注意事项:
- 该数值显示的是总物理内存,不代表所有空间都可供应用程序使用。
- 它提供了一个有用的粗略估算值 (ballpark figure) 作为起点。
- 务必交叉参考官方硬件规格,Profiler 显示的数字可能不完全准确(例如,开发套件有时内存更大;或者设备采用统一内存架构 (Unified Memory Architecture))。
确定各目标平台支持的最低规格 (Determine the lowest specification to support for each target platform)
- 方法: 找出你支持的每个平台上 RAM 最低的硬件规格,以此为基础来指导内存预算决策。
- 可用性考量: 再次强调,并非所有物理内存都可用(例如,操作系统、主机上的虚拟机监视器 (Hypervisor) 都会占用一部分)。
- 预算策略:
- 可以考虑使用总物理内存的一个百分比作为预算(例如,总量的 80%)。
- 移动平台分层 (Tiering): 可以考虑将移动设备分为多个规格层级(低/中/高),为高端设备提供更好的质量和特性,每个层级基于该层最低规格设备设定预算。
为大型团队考虑按团队分配预算 (Consider per-team budgets for larger teams)
- 实施: 确定总体内存预算后,可以考虑为不同团队分配额度。
- 例如:环境美术团队为每个加载的关卡/场景分配一定内存;音频团队为音乐和音效分配内存等。
- 灵活性: 预算应随项目进展保持灵活。如果一个团队远低于预算,可以将剩余额度分配给其他团队,前提是这能改进他们负责的游戏部分。
- 后续步骤: 确定并设定预算后,使用分析工具来监控和跟踪游戏中的内存使用情况。
Memory Profiler 模块的视图 (Simple and detailed views with Memory Profiler module)
- 提供两种视图: Simple (简单视图) 和 Detailed (详细视图)。
- Simple View: 提供应用程序内存使用的高层级概览。
- Detailed View: 需要时切换到此视图进行深入探究。
Simple View (简单视图)
- 关键指标:
Total Used Memory: Unity 跟踪的对象实际使用的内存。等同于 “Total Tracked by Unity Memory”。不包括 Unity 已保留但未使用的内存。Total Reserved Memory: Unity 向操作系统申请并保留的总内存(包括已使用的和未使用的)。System Used Memory: 操作系统认为你的应用程序正在使用的内存。
- 特殊情况: 如果
System Used Memory显示为 0,表示该计数器在你正在分析的平台上未实现。此时,应依赖Total Reserved Memory作为主要参考。在这种情况下,也建议切换到原生平台分析工具获取详细内存信息。
Detailed View (详细视图)
- 用途: 用于分析可执行文件、DLL、Mono 虚拟机等占用的内存(这些信息无法通过逐帧数据获得)。需要捕获快照 (Take Sample) 才能查看。
- 功能: 允许深入查看 Assets 和 Scene 对象的内存占用情况。
- 粗略估算是否接近预算:
- 使用以下“餐巾纸估算法”:
[System Used Memory (如果为0则用 Total Reserved Memory)] + [未跟踪内存的粗略缓冲值] - 将此结果与平台总内存预算比较。
- 当这个数字开始接近平台内存预算的 100% 时,应使用 Memory Profiler Package 来找出具体原因。
- 使用以下“餐巾纸估算法”:
使用 Memory Profiler Package 进行深入分析 (In-depth analysis with Memory Profiler package)
- 优势: 提供更详细的内存分析能力。
- 核心功能与好处:
- 除了捕获原生对象 (Native Objects)(像模块一样),它还能让你查看托管内存 (Managed Memory)。
- 保存和比较快照 (Save and Compare Snapshots): 这是查找内存泄漏的关键功能。
- 更详细地探索内存内容,提供可视化的内存使用分解图。
- 更强的引用关系查看: 能显示对象间的引用关系,包括托管引用(例如,哪个类的哪个字段引用了某个 Texture2D),而 Memory Profiler Module 的 Detailed 视图主要只显示原生引用,即使显示了托管对象的“外壳”,也通常是因为其下有原生对象,无法看到具体的托管类型或字段引用信息。需要这种详细信息时必须使用 Package。
Memory Profiler 模块与 Package 的关系
- 演进: Memory Profiler Package 的许多功能已经取代 (superseded) 了 Memory Profiler Module 的对应功能。
- 模块的补充作用: 尽管如此,模块仍可在某些方面辅助内存分析工作:
- 发现 GC 分配 (Spot GC Allocations): 虽然模块中会显示,但使用 Project Auditor 工具更容易追踪来源。
- 快速查看堆的 Used/Reserved 大小: 较新版本的 Memory Profiler 模块会显示此信息。
- 着色器内存分析 (Shader memory analysis): 较新版本的 Memory Profiler 模块已报告此信息。
内存分析时的注意事项与实践建议
- 分析目标: 设定和检查内存预算时,务必在目标平台支持的最低规格设备上进行分析。
- 分析环境:
- 通常建议使用内存充裕的强大开发机进行分析,因为需要足够空间存储大的内存快照,并能快速加载/保存。
- 分析自身的开销:
- 内存分析本身会产生额外的内存开销。这一点与 CPU/GPU 分析不同。
- 可能需要在内存更大的高端设备上进行分析(以容纳游戏本身内存 + 分析工具开销),但分析结果必须对照低端目标规格的内存预算来解读。
- 跨设备内存差异因素: 不同设备上的设置可能导致内存使用量显著不同,需注意:
- 质量设置 (Quality Level) / 图形层级 (Graphics Tier): 可能影响用于阴影贴图等的 RenderTexture 大小。
- 分辨率缩放 (Resolution Scaling): 可能影响屏幕缓冲区、RenderTexture 和后处理效果的大小。
- 纹理质量 (Texture Quality): 可能影响所有纹理的大小。
- 最大 LOD (Maximum LOD): 可能影响加载的模型等。
- AssetBundle 变体 (Variants): 根据设备规格加载不同版本(如高清 HD / 标清 SD)会导致资源大小不同。
- 屏幕分辨率 (Screen Resolution): 直接影响用于后处理效果的 RenderTexture 大小。
- 支持的图形 API (Graphics API): 可能影响加载的 Shader 变体及其大小。
- 分层系统测试的复杂性:
- 使用分层的质量设置、图形层级和 AssetBundle 变体是覆盖更广设备范围的好方法(例如,4GB 内存设备加载 HD 包,2GB 加载 SD 包)。
- 但必须考虑到上述内存使用差异,确保在每个层级的代表性设备上进行测试,同时也要测试不同屏幕分辨率或支持不同图形 API 的设备。
- 编辑器内存占用:
- 重要提示: Unity 编辑器通常会显示比实际构建版本大得多的内存占用,因为它会加载额外的编辑器和 Profiler 相关对象。切勿基于编辑器的内存数据来做最终的预算判断或发布决策。
Unity 分析和调试工具深入探讨
本节深入介绍 Unity 中可用的每种分析和调试工具的功能。
关于工具差异的说明
- 本节提到的一些工具(如 Frame Debugger)也属于其他类别(如调试工具)。
- 虽然严格来说它们不是性能分析器(Profiler),但它们是分析和改进 Unity 项目时工具箱中的重要组成部分。
性能分析 (Profiling)、调试 (Debugging) 和静态分析 (Static Analysis) 工具的区别:
- 性能分析工具 (Profiling Tools):
- 检测并收集与代码执行相关的计时数据。
- 调试工具 (Debugging Tools):
- 允许你单步执行程序、暂停并检查变量值等高级功能。
- 例如:Frame Debugger 允许你单步浏览帧的渲染过程、检查着色器值等。
- 静态分析器 (Static Analyzers):
- 接收源代码或其他资源作为输入,使用内置规则分析输入的“正确性”,无需运行项目。
Profiler (性能分析器)
- 核心功能: Unity Profiler 帮助你检测运行时瓶颈或卡顿的原因,并更好地理解在特定帧或时间点发生了什么。
- 工作原理: Unity 中的性能分析是基于插桩 (instrumentation-based) 的,提供了大量的 Profiler 标记数据供分析。
- 重要注意事项:
- 直接在编辑器 (Editor) 中进行性能分析会增加一些开销,可能使结果产生偏差。
- 你的开发机器性能可能远超目标设备。
- 建议:
- 只启用你希望使用的 Profiler 模块。
- 或者使用 Standalone Profiler (独立性能分析器),其优点包括:
- 提供更干净的分析数据。
- 减少分析开销。
- 通用经验法则: 始终启用 CPU、Memory (内存) 和 Renderer (渲染器) 模块。根据需要启用其他模块,如 Audio (音频) 和 Physics (物理)。
Unity 性能分析入门步骤
- 必须使用 Development Build (开发版本):
- 通过
File > Build Settings > Select Development Build勾选。
- 通过
- 勾选 Autoconnect Profiler (可选):
- 注意: 这会增加大约 10 秒 的初始启动时间,仅应在你想要分析第一个场景的初始化时启用。
- 如果不启用,你始终可以在运行开发版本后手动将 Profiler 连接到它。
- 为目标平台构建 (Build):
- 打开 Unity Profiler:
- 通过
Window > Analysis > Profiler打开。
- 通过
- 禁用不需要的 Profiler 模块:
- 每个启用的模块都会给 Player (运行的应用) 带来性能开销(可以使用
Profiler.CollectGlobalStats标记观察到部分开销)。
- 每个启用的模块都会给 Player (运行的应用) 带来性能开销(可以使用
- 设备网络设置:
- 禁用设备的移动网络 (Mobile Network),保持 WiFi 启用。
- 在目标设备上运行构建。
- 连接 Profiler:
- 如果勾选了 Autoconnect Profiler: 构建中会嵌入编辑器机器的 IP 地址。应用启动时会尝试直接连接到该 IP 的 Unity Profiler。Profiler 会自动连接并开始显示帧和分析信息。
- 如果未勾选 Autoconnect Profiler: 需要使用 Target Selection (目标选择) 下拉菜单手动连接到你的 Player。
- 在编辑器中分析 (替代方案):
- 为了节省构建时间(但会降低准确性),可以直接在 Unity 编辑器中运行并分析你的应用。
- 在 Profiler 窗口的
Attach to Player(或类似名称) 下拉菜单中选择 Playmode。
Profiler 使用技巧
- 在 CPU Usage Profiler 模块中禁用 VSync 和 Others 类别:
- VSync 标记代表 CPU 主线程等待垂直同步时的“空闲时间”。
- 有时隐藏标记会使理解其他类别的时间或总帧时间如何构成变得困难。另一种选择是将 VSync 重新排序到列表顶部,这样可以提供更清晰的图表视图,减少 VSync 标记带来的“噪音”,使整体情况更清晰。
- Others 标记代表分析开销 (profiling overhead),可以安全忽略,因为它不会出现在项目的最终构建中。
- 在构建中禁用 VSync:
- 为了更清晰地了解主线程、渲染线程和 GPU 之间的交互,可以分析一个完全禁用了 VSync 的构建。
- 前往
Edit > Project Settings > Quality,选择目标设备使用的质量级别 (Quality Level),并将 VSync Count 设置为 Don’t Sync。 - 构建一个 Development build,并将 Profiler 连接到它。此时,游戏将在上一帧完成后立即开始下一帧,而不是等待 VBlank 信号。
- 注意: 禁用 VSync 可能在某些平台上导致视觉伪影 (visual artifacts),例如画面撕裂(因此,发布版本记得重新启用它)。
- 好处: 移除人为的等待可以使 Profiler 捕获的数据更易于阅读,尤其是在调查项目瓶颈时。
- 了解何时在 Playmode 或 Editor mode 下进行分析:
- Playmode: 用于分析你的游戏/应用程序本身。
- Editor mode: 用于查看围绕游戏的 Unity 编辑器本身在做什么。
- 以 Editor 为目标进行分析会对分析精度产生很大影响,因为 Profiler 窗口实际上在递归地分析自身。
- 价值: 当编辑器性能下降时,分析 Editor 模式很有价值。可以识别出拖慢编辑器、影响生产力的脚本和扩展。
- 何时分析 Editor 的示例:
- 按下 Play 按钮后进入 Play 模式需要很长时间。
- 编辑器变得迟钝和无响应。
- 项目打开需要很长时间。(文中提到可以使用
-profiler-enable命令行选项从编辑器启动时就开始分析)。
- 使用 Standalone Profiler (独立性能分析器):
- 当你想进行 Play mode 或 Editor mode 分析时,Profiler 会作为一个独立于 Unity 编辑器的新进程启动。
- 优点: 避免 Profiler UI 或编辑器本身影响测量到的计时结果。
- 优点: 你会得到一套更干净的分析数据来进行过滤和处理。
- 在编辑器中进行分析以实现快速迭代:
- 当你想要快速迭代修复性能问题时,在编辑器中进行分析。
- 工作流程示例:
- 在构建 (build) 中发现性能问题。
- 在编辑器中分析,确认该问题在编辑器中也能复现。
- 如果能复现,使用 Play mode 分析来快速迭代修改,寻找潜在解决方案。
- 一旦问题解决,制作一个构建并在目标设备上验证解决方案同样有效。
- 好处: 这种工作流程减少了构建更改和部署到设备的时间。你可以在编辑器中快速迭代,并使用分析工具验证更改结果。
更多资源
How to profile and optimize a game | Unite Now 2020
Frame Debugger (帧调试器)
- 核心功能: 通过让你冻结正在运行的游戏的特定帧,并查看用于渲染该帧的单个绘制调用 (draw calls),来帮助你优化渲染。
- 工作方式: 该工具允许你逐一单步执行绘制调用列表,这样你可以看到帧是如何由其图形元素逐步构建成一个场景的。
- 独特优势: 相较于其他帧调试工具,如果一个绘制调用对应于某个 GameObject 的几何体,该 GameObject 会在主 Hierarchy (层级) 面板中高亮显示,有助于识别。
- 其他用途: 可以通过逐帧分析渲染顺序来测试过度绘制 (overdraw)。
如何使用 Frame Debugger
- 打开: 通过菜单
Window > Analysis > Frame Debugger打开。 - 启用: 当你的应用程序在编辑器或设备上运行时,点击 Enable 按钮。
- 这将暂停应用程序,并在 Frame Debug 窗口左侧按顺序列出当前帧的所有绘制调用(也包括帧缓冲清除等额外细节事件)。
- 浏览:
- 窗口顶部的滑块 (slider) 允许你快速在绘制调用之间拖动,以快速定位感兴趣的项目。
- 在左侧的列表层级 (list hierarchy) 中选择一个绘制调用。
- Game 窗口将显示场景渲染到包含并完成所选绘制调用时的状态。
理解绘制调用与渲染状态
- 绘制调用 (Draw Call): Unity 向图形 API 发出指令以在屏幕上绘制几何体。它告诉图形 API 要画什么以及如何画,包含了图形 API 所需的所有信息(如纹理、着色器、缓冲区等)。
- 准备开销: 通常,为绘制调用做准备比绘制调用本身更耗费资源。
- 渲染状态 (Render State): 这个准备过程被归类为“渲染状态”。
- 优化方向: 优化此领域性能的一种方法是减少渲染状态的更改次数。
- Frame Debugger 的作用:
- 帮助识别绘制调用的来源。
- 可视化并理解渲染过程,以指导如何分组绘制调用来减少渲染状态的更改。
Frame Debugger 窗口详解
- 左侧列表: 按层级结构列出绘制调用和事件。
- 右侧面板 (Details): 提供关于每个绘制调用的详细信息:
- 几何体细节 (Geometry details)。
- 使用的着色器 (Shader)。
- 未能与之前的调用进行批处理 (batching) 的原因。
- 输入到着色器的确切属性值 (shader property values)。
- ShaderProperties 部分: 除了属性值,还会揭示该属性在哪些着色器阶段 (shader stages) 被使用(例如:顶点 vertex, 片段 fragment, 几何 geometry, 外壳 hull, 域 domain)。
远程帧调试 (Remote Frame Debugging)
- 可行性: 可以在支持的平台上将 Frame Debugger 远程附加到一个 Player (不支持 WebGL)。
- 桌面平台要求: 对于桌面平台构建,需要启用 Run In Background (后台运行) 选项。
- 设置步骤:
- 为目标平台创建一个项目的标准构建(选择 Development Player 开发版本)。
- 运行该 Player。
- 在编辑器中打开 Frame Debug 窗口。
- 点击 Player selection (目标选择) 下拉菜单,选择正在运行的活动 Player。
- 点击 Enable。
- 结果: 现在可以在编辑器中单步执行 Frame Debug 列表中的绘制调用和事件,并在活动的 Player 上观察结果。
渲染目标显示选项 (Render Target Display Options)
- 窗口工具栏:
- 允许你隔离当前 Game 视图状态的红 (R)、绿 (G)、蓝 (B)、透明 (A) 通道。
- Levels 滑块 (通道按钮右侧): 根据亮度级别隔离视图区域(仅在渲染到 RenderTexture 时启用)。
- RenderTarget 下拉列表:
- 当一次渲染到多个渲染目标 (Multiple Render Targets, MRT) 时,可以选择在 Game 视图中显示哪一个。
- 包含一个 Depth (深度) 选项,用于显示深度缓冲区的内容。
五个针对常见陷阱的渲染优化技巧
使用这些技巧来优化常见的渲染性能问题,这些问题可以通过 Frame Debugger 和其他渲染调试工具识别。
- 首先识别性能瓶颈:
- 找到 GPU 负载高的帧。大多数平台提供强大的工具来分析 CPU 和 GPU 性能(例如:Arm Mobile Studio、PIX for Xbox、Razor for PlayStation、Xcode Instruments for iOS)。
- 使用相应的原生分析器 (native profiler) 将帧成本分解为具体部分,这是改进图形性能的起点。
- 绘制调用优化:
- PC 和当代主机硬件能处理大量绘制调用,但每个调用的开销仍然值得去减少。在移动设备上,绘制调用优化至关重要。
- 可以通过绘制调用批处理 (draw call batching) 来实现。
- Frame Debugger 作用: 帮助识别哪些绘制调用可以被重组以实现最佳分组和批处理,并帮助识别某些绘制调用无法被批处理的原因。
- 减少绘制调用批次的技巧:
- 遮挡剔除 (Occlusion Culling): 移除被前景物体遮挡的物体,减少过度绘制。注意: 这需要额外的 CPU 处理,因此使用 Profiler 确认将工作从 GPU 移到 CPU 是有益的。
- GPU 实例化 (GPU Instancing): 如果有许多共享相同网格 (Mesh) 和材质 (Material) 的对象,这可以减少批次。场景中模型种类少可以提高性能。
- SRP Batcher: 通过批处理 Bind 和 Draw GPU 命令来减少绘制调用之间的 GPU 设置开销。要从此受益,可以使用所需数量的材质,但将它们限制在少量兼容的着色器变体 (shader variants) 内(例如 URP/HDRP 中的 Lit 和 Unlit Shaders),并且不同关键字组合之间的差异尽可能小。
- 通过减少过度绘制来优化填充率 (Fill Rate):
- 过度绘制 (Overdraw) 可能表明应用程序试图每帧绘制比 GPU 处理能力更多的像素。这不仅影响性能,还会影响移动设备的散热和电池寿命。
- 通过理解 Unity 在渲染前如何排序对象来对抗过度绘制。
- 内置渲染管线 (Built-In Render Pipeline): 根据对象的 Rendering Mode 和 renderQueue 排序。对象的着色器将其放入一个渲染队列,这通常决定了其绘制顺序。
- 可视化过度绘制 (Built-in): 使用 Scene 视图控制栏,将绘制模式切换到 Overdraw。亮像素表示高过度绘制。
- HDRP: 渲染队列控制略有不同(详见 Renderer 和 Material Priority 文档)。
- 可视化过度绘制 (HDRP): 使用 Render Pipeline Debug 工具 (
Window > Render Pipeline > Render Pipeline Debug) -> Rendering 部分 -> Fullscreen Debug Mode 设置为 TransparencyOverdraw。此模式将像素显示为热力图(黑色=无透明像素,蓝色到红色=透明像素增多,红色表示达到 Max Pixel Cost)。 - 操作: 在此模式下运行应用,记录过度绘制严重的区域。
- 检查最昂贵的着色器:
- 这是一个深入的话题,但总的来说,目标是尽可能减少着色器复杂度。
- 简单的优化: 尽可能降低精度(例如,如果可以,使用半精度
half浮点变量)。 - 了解目标平台的波前占用率 (wavefront occupancy),并学习如何使用 GPU 分析工具来辅助获得健康的占用率。
- 渲染的多核优化:
- 在
Player Settings > Other Settings中启用 Graphics Jobs,以利用 PlayStation 和 Xbox 中的多核处理器。 - Graphics Jobs 允许 Unity 将渲染工作分散到多个 CPU 核心,减轻渲染线程的压力。
- 在
- 分析后处理效果:
- 确保你的后处理资源针对目标平台进行了优化。
- 从 Asset Store 获取的、最初为 PC 游戏编写的工具可能在主机或移动设备上消耗过多资源。
- 使用目标平台的原生分析器工具进行分析。
- 为移动或主机目标编写自己的后处理效果时,保持尽可能简单。
Profile Analyzer (性能分析器分析工具)
- 核心区别: 标准的 Unity Profiler 允许你进行单帧分析,而 Profile Analyzer 可以聚合和可视化来自一组 Unity Profiler 帧的分析标记数据。
Profile Analyzer 入门
- 安装: 通过
Window > Package Manager安装 Profile Analyzer Package。 - 推荐做法: 在使用 Profile Analyzer 时,一个好的方法是保存分析会话 (profiling sessions),以便比较性能优化工作前后的效果。
功能与用途
- Profile Analyzer 拉取 (pull) 在 Unity Profiler 中捕获的一组帧,并对它们执行统计分析。
- 显示的数据为每个函数生成有用的性能计时信息,例如 Min (最小)、Max (最大)、Mean (平均) 和 Median (中位) 计时。
- 解决问题与优化: 帮助你在开发过程中回答问题和进行优化决策。
- A/B 测试: 对比游戏场景不同实现的性能差异。
- 前后对比: 比较代码重构、优化、新功能添加甚至 Unity 版本升级前后的分析数据。
- 聚合数据视图 (Single View): 可以预先回答关于一段时间内性能的高层次问题,这通常比一次只看一帧数据更好。例如,在一个 300 帧(10 秒)的游戏捕获或 20 秒加载序列中:
- 主线程和渲染线程上最大的 CPU 开销是什么?
- 这些标记的平均/中位数/总开销是多少?
- 回答这些问题对于精确定位最大问题所在以及确定优化优先级至关重要。
- 深入分析: Profile Analyzer 提供的统计数据和细节使你能够更深入地研究代码在跨多帧运行时的性能特征,甚至可以与之前的分析捕获会话进行比较。
Memory Profiler (内存分析器)
- 性质: Unity Package Manager 中可用的附加包 (add-on package)。
- 核心功能: 用于为内存创建快照 (snapshot),可以在编辑器中或在运行的 Player 中进行。
- 快照用途: 显示引擎中的内存分配情况,允许你:
- 快速识别过度或不必要的内存使用的原因。
- 追踪内存泄漏 (memory leaks)。
- 查看堆碎片化 (heap fragmentation)。
入门与基本操作
- 安装: 在 Package Manager 中安装 Memory Profiler 包。
- 打开: 点击
Window > Analysis > Memory Profiler。 - 顶部菜单栏:
- 更改 Player 目标选择 (Target selection)。
- 捕获 (Capture) 或 导入 (Import) 内存快照。
- Workbench (工作台) 区域 (左侧):
- 管理、打开或关闭已保存的内存快照。
- 在 Single (单一) 和 Compare Snapshots (比较快照) 视图之间切换。
- 重要提示:
- 务必在目标硬件上进行内存分析: 使用 Target selection 下拉菜单将 Memory Profiler 连接到远程设备。在 Unity 编辑器中分析会因编辑器和其他工具添加的开销而给出不准确的数字。
比较快照功能
- 类似于 Profile Analyzer,Memory Profiler 允许你加载**两个数据集(内存快照)**进行比较。
- 特别有用:
- 查看内存使用量随时间或在场景之间如何增长。
- 搜索内存泄漏。
内存分析技术和工作流程
- 一般检查:
- 加载 Memory Profiler 快照,浏览 Tree Map 视图,按内存占用从大到小检查各个类别。
- 项目资源 (Assets) 通常是内存消耗大户。使用表格视图定位纹理 (Texture)、网格 (Meshes)、音频剪辑 (AudioClips)、渲染纹理 (RenderTextures)、着色器变体 (shader variants) 和预分配的缓冲区 (preallocated buffers)。这些都是内存优化的良好候选对象。
- 定位内存泄漏:
- 发生原因:
- 对象未通过代码手动从内存中释放。
- 对象因意外引用 (unintentional reference) 而留在内存中。
- 工具: Memory Profiler 的 Diff (差异) 视图可以通过比较特定时间范围内的两个快照来帮助查找内存泄漏。
- 常见场景: Unity 游戏中常见的内存泄漏可能发生在卸载场景之后。Memory Profiler 包提供了一个工作流程,指导你使用 Diff 视图发现这类泄漏。
- 发生原因:
- 定位应用程序生命周期内的重复内存分配:
- 通过对多个内存快照进行差异比较,可以识别应用程序生命周期内持续内存分配的来源。
用于定位托管分配的相关工具
除了 Memory Profiler 包本身,还有其他工具可以帮助定位托管内存分配:
- Memory Profiler 模块 (在标准 Profiler 内):
- 标准 Unity Profiler 中的 Memory Profiler 模块用红线表示每帧的托管分配。
- 这条线大部分时间应为 0,因此该线上的任何峰值 (spikes) 都表明你应该调查这些帧的托管分配。
- Timeline (时间线) 视图 (在 CPU Usage Profiler 模块内):
- CPU Usage Profiler 模块的时间线视图将分配(包括托管分配)显示为粉红色,使其易于查看和定位。
- Allocation Call Stacks (分配调用堆栈):
- 一种快速发现代码中托管内存分配的方法,其开销低于深度分析 (deep profiling)。
- 可以在标准 Profiler 中动态启用。
- 启用方法: 在 Profiler 窗口的主工具栏中点击 Call Stacks 按钮。将 Details 视图更改为 Related Data (相关数据)。
- 查看:
GC.Alloc样本(在 Hierarchy 或 Raw Hierarchy 视图中选择)现在将包含其调用堆栈。也可以在 Timeline 视图的选择工具提示中看到GC.Alloc样本的调用堆栈。Related Data 面板也会显示调用堆栈细节。 - 注意: 如果使用较旧版本的 Unity(在支持分配调用堆栈之前),则深度分析 (deep profiling) 是获取完整调用堆栈以帮助查找托管分配的好方法。
- Hierarchy (层级) 视图 (在 CPU Usage Profiler 模块内):
- CPU Usage Profiler 模块的层级视图允许你点击列标题以将其用作排序标准。按 GC Alloc 列排序是专注于托管分配的好方法。
- Project Auditor (项目审计器):
- 一个实验性的静态分析工具。
- 功能很多,其中一项是能够生成项目中导致托管分配的每一行代码的列表,而无需运行项目。是查找和调查此类问题的非常有效的方法。
内存与 GC (垃圾回收) 优化
减少垃圾回收 (GC) 的影响
- Unity 使用 Boehm-Demers-Weiser 垃圾回收器,它会停止运行你的程序代码,并在其工作完成后才恢复正常执行。
- 注意: 避免不必要的堆分配 (heap allocations),它们会导致 GC 峰值。
- 避免产生垃圾的方法:
- 字符串 (Strings): C# 中的字符串是引用类型。每个新字符串都会在托管堆上分配,即使只是临时使用。
- 减少不必要的字符串创建或操作。
- 避免解析基于字符串的数据文件(如 JSON、XML),应将数据存储在 ScriptableObjects 或 MessagePack、Protobuf 等格式中。
- 如果需要在运行时构建字符串,请使用 StringBuilder 类。
- Unity 函数调用: 一些 Unity API 函数会创建堆分配,特别是那些返回托管对象数组的函数。
- 缓存对数组的引用,而不是在循环中间分配它们。
- 利用某些避免产生垃圾的函数。例如,使用
GameObject.CompareTag而不是手动比较字符串与GameObject.tag(因为返回新字符串会产生垃圾)。
- 装箱 (Boxing): 避免在需要引用类型变量的地方传递值类型变量。
- 这会创建一个临时对象和潜在的垃圾(隐式地将值类型转换为
object类型,例如object o = 123;)。 - 尝试提供接受你想要传递的值类型的具体重载。泛型也可用于这些重载。
- 这会创建一个临时对象和潜在的垃圾(隐式地将值类型转换为
- 协程 (Coroutines):
yield本身不产生垃圾,但new WaitForSeconds()对象会。- 缓存并重用
WaitForSeconds对象,而不是在yield行中创建它。
- 缓存并重用
- LINQ 和正则表达式: 两者都会通过幕后的装箱产生垃圾。
- 如果性能是问题,请避免使用 LINQ 和正则表达式。
- 使用
for循环和List作为创建新数组的替代方案。
- 泛型集合和其他托管类型: 不要在
Update中每帧声明并填充List或集合(例如,玩家一定半径内的敌人列表)。- 将
List声明为 MonoBehaviour 的成员,并在Start中初始化它。 - 每帧使用前用
Clear()清空集合即可。
- 将
- 字符串 (Strings): C# 中的字符串是引用类型。每个新字符串都会在托管堆上分配,即使只是临时使用。
尽可能地控制垃圾回收时机
- 如果你确定某个垃圾回收冻结不会影响游戏的特定时间点(例如加载屏幕、菜单打开时),你可以使用
System.GC.Collect()手动触发垃圾回收。 - 参考 “Understanding Automatic Memory Management” 文档了解如何利用这一点。
使用增量式垃圾回收器 (Incremental Garbage Collector) 分摊 GC 工作负载
- 增量式 GC 使用多次、更短的中断将工作负载分散到多个帧上,而不是在程序执行期间造成一次长时间的中断。
- 适用场景: 如果垃圾回收导致帧率不规则,尝试此选项看是否能减少 GC 峰值问题。使用 Profile Analyzer 来验证它对你的应用程序是否有益。
- 注意 - 开销: 在增量模式下使用 GC 会给某些 C# 调用增加读写屏障,这带来一些开销,可能增加 约 1 毫秒/帧 的脚本调用开销。
- 理想情况: 为了获得最佳性能,理想的是在主要游戏循环中没有 GC 分配,这样你就不需要增量 GC 来获得平滑的帧率,并且可以将
GC.Collect隐藏在用户不会注意到的地方(例如打开菜单或加载新关卡时)。
Deep Profiling (深度分析)
-
基本原理: 默认情况下,Unity 只分析那些被显式 Profiler 标记包裹的代码(以及引擎原生代码调用的托管代码的第一层调用堆栈深度)。启用 Deep Profiling 会在每个函数调用的开始和结束处插入 Profiler 标记。
-
优点:
- 能够捕获非常详细的信息。
- 用于分析那些没有显示足够调用堆栈信息的、耗时较长的 Profiler 标记内部到底发生了什么。
- 这种测量游戏性能的粒度化方法可能优于基于快照的分析(采样分析),后者有可能在捕获中丢失细节。
-
替代方案:
ProfileMarkerAPI: 作为一种手动插桩 (instrument) 可疑代码区域的方法。- 性能影响可能比深度分析低得多。
- 有时,添加一个
ProfileMarker并重新构建游戏,比启用深度分析并导航到你想要测试的游戏部分更快。
- 原生 CPU 分析器 (Native CPU Profiler): 在设备构建上运行以获取完整的调用堆栈。在某些情况下,这比深度分析更容易,对性能的侵入性也更小。
何时使用深度分析
- 时机: 仅在你已经确定了应用程序或托管代码中需要进行更详细检查的特定部分之后,才应启用深度分析设置。
- 注意: 深度分析是资源密集型的,会消耗大量内存。启用后,你的应用程序运行会变慢。
- 目的: 允许你详细地向下遍历调用树,发现代码中的低效或问题。
如何使用深度分析
- 启用支持 (Player 构建): 需要通过
File > Build Settings > Deep Profiling Support(文件 > 构建设置 > 深度分析支持) 来启用它。- 版本注意: 从 Unity 2019.3 开始,Mono 和 IL2CPP 后端都添加了对深度分析的支持(这对 IL2CPP 是强制要求的平台如 iOS 是个好消息)。
- 切换开关: 一旦在构建中启用了支持,你可以在 Profiler 窗口中随时轻松地为你的构建打开或关闭深度分析。
- 如果连接到 Player 时 Deep Profile 按钮是灰色的,则表示你的构建没有启用深度分析支持。
深度分析技巧
- 自顶向下方法 (Top-to-bottom approach):
- 分析应用程序时,从高层级开始,尝试在不使用深度分析的情况下找到可以改进性能的区域。
- 当你需要更多信息时,可以在 Profiler 中启用深度分析,以更细粒度的级别深入挖掘。
- 这种方法有助于将 Profiler Hierarchy 中显示的信息量保持在最低限度,让你专注于当前目标。
- 仅在绝对必要时进行深度分析:
- 通常,最好只在需要获取关于代码性能的更低级别细节时才使用深度分析。
- 虽然在构建中启用深度分析标志本身不会影响性能(除非实际切换开启该功能),但一旦启用,它会导致应用程序运行缓慢。
- 替代查找托管分配: 如果你只对查找代码中托管分配的来源感兴趣,请记住 Unity 2019.3 及更高版本允许你在无需启用深度分析的情况下执行此操作。使用 Profiler 中的 Call Stacks (调用堆栈) 切换按钮和 Calls (调用) 下拉菜单来帮助定位托管分配。
- 自动化流程中的深度分析:
- 要在从命令行进行分析时打开深度分析,请将
-deepprofiling参数添加到你的构建可执行文件。 - 对于 Android / Mono 脚本后端的构建,使用
adb命令行参数,如下所示:adb shell am start -n com.company.game/com.unity3d.player.UnityPlayerActivity -e 'unity' '-deepprofiling'
- 要在从命令行进行分析时打开深度分析,请将
- 在低规格硬件上进行深度分析:
- 低规格硬件的内存和性能有限,可能会影响你使用深度分析的能力。
- Unity 的 Profiler 样本存储在一个环形缓冲区 (ring buffer) 中,在较慢设备上使用深度分析设置时,该缓冲区可能会被填满。如果发生这种情况,Unity 会显示错误消息。
- 你可以通过设置
Profiler.maxUsedMemory属性(单位:字节)为 Profiler 分配更多内存用于此缓冲数据(Player 默认为 128 MB,Editor 默认为 512 MB)。如果在低速设备的 Player 构建上进行深度分析时遇到问题,请根据需要增加此值。 - 如果硬件因深度分析开销而运行过慢(或根本无法运行),但你仍需更详细地分析代码,可以使用你自己的标记进行更深入的分析。即,不启用 Deep Profile 设置,而是在代码中你感兴趣的特定区域添加
Profiler标记。这些标记将在查看 CPU Usage 模块时出现在 Profiler Timeline 或 Hierarchy 中。
何时使用哪种分析工具?
- 最佳实践: 分析最好在项目生命周期的开始阶段就进行。通过早期开始,你可以建立基线 (baselines),这对于在游戏和应用程序开发的后期检查点进行比较非常有用。
- 关键: 了解何时从“分析工具箱”中选择哪种工具。
一旦你理解了每种工具的用途和好处,就更容易知道何时使用它们。请务必学习 Unity 提供的每种分析工具。
以下是一些项目生命周期中的检查点建议,可能有助于规划分析策略:
- 原型设计阶段 (Prototyping):
- 分析对于降低项目原型阶段的风险很重要。
- 如果游戏设计文档要求屏幕上有 10,000 个敌人,你需要能够构建并分析一个原型,以证明在目标平台上这是可能的。如果不可行,你需要更改设计。
- 项目早期阶段 (Early stages):
- 在一系列目标设备硬件上建立项目性能的基线。
- 使用 Memory Profiler 对内存使用情况有一个大致了解。
- 确保项目范围的规划不会趋向于导致后续在目标硬件上出现内存限制问题。
- 冲刺结束时 (End of sprint - 敏捷开发):
- 如果你在敏捷团队中按冲刺工作,那么冲刺结束时的发布候选版本 (RC) 是运行一套标准化的分析工具的好时机。
- 确保有标准格式来记录结果和指标(例如,在数据库或电子表格中)。
- 使用 Unity Profiler 执行以下分析活动并捕获数据:
- CPU 使用率 (CPU Usage)
- GPU 使用率 (GPU Usage)
- 内存使用率 (Memory Usage)
- 渲染 (Rendering)
- 物理 (Physics)
- 使用以下工具进行更深入的分析,记录结果和关键差异指标(与之前的冲刺版本相比):
- Profile Analyzer: 加载先前发布的分析数据捕获,进行比较并记录差异。
- Memory Profiler: 比较先前发布候选构建的内存快照,记录内存增加或减少的差异。
自动化关键性能和分析指标
- 通过自动化常见和重复的任务来提升你的项目分析和数据捕获水平。
- 好处:
- 节省时间。
- 获得始终保持最新的指标。
- 应用:
- 可以将指标绘制成图表并添加到项目仪表板 (dashboard),让团队能够看到性能在何处急剧下降(例如,新添加的功能或错误),或者在优化和错误修复冲刺后情况有所改善。
- 绘制项目在所有游戏关卡随时间变化的总体内存使用情况。通过使用 Memory Profiler 捕获内存快照并在所有关卡中取平均值,你可以记录每个目标设备/平台、冲刺或发布周期的内存占用 (memory footprint)。
- 工具与技术:
- 使用
ProfilerRecorder记录高级分析统计数据(如总预留内存 Total Reserved Memory 或系统已用内存 System Used Memory),并将这些数据输出到 CI(持续集成)系统,再将它们导向图表或绘图工具(如 Grafana)。 - 使用 Unity DevOps 工具(如 Cloud Build)来自动化发布构建的创建,并将此过程与自动化的设备分析工作流程集成。
- 使用
原生分析工具 (Native Profiling Tools)
总体建议:
- 从 Unity 自带的工具开始进行分析。
- 如果需要更深入的细节,再使用适用于你目标平台的原生分析器 (native profilers) 和调试工具。
以下是一些可用的原生分析工具:
-
Android / Arm:
- Android Studio: 最新版包含新的 Android Profiler(取代了之前的 Android Monitor 工具)。用它来收集 Android 设备上的实时硬件资源数据。
- Arm Mobile Studio: 一套工具,用于在运行 Arm 硬件的设备上非常详细地分析和调试你的游戏。
- Snapdragon Profiler: 仅限用于搭载骁龙 (Snapdragon) 芯片组的设备。分析 CPU、GPU、DSP、内存、功耗、散热和网络数据,以帮助查找和修复性能瓶颈。
-
Intel:
- Intel VTune: 一套工具,用于在 Intel 平台上快速查找和修复性能瓶颈(仅限 Intel 处理器)。
- Intel GPA suite: 一套专注于图形的工具,通过快速识别问题区域来帮助你提高游戏性能。
-
Xbox / PC:
- PIX: 面向使用 DirectX 12 的 Windows 和 Xbox 游戏开发者的性能调优和调试工具。包含用于理解和分析 CPU 及 GPU 性能的工具,以及监控各种实时性能计数器。
-
PC / 通用:
- AMD μProf (uProf): 性能分析工具,用于理解和分析在 AMD 硬件上运行的应用程序的性能。
- NVIDIA NSight: 使开发者能够使用最新的 NVIDIA 视觉计算硬件来构建、调试、分析和开发顶尖软件的工具。
- Superluminal: 高性能、高频率的分析器,支持分析 Windows、Xbox One 和 PlayStation 上用 C++、Rust 和 .NET 编写的应用程序。注意:这是一个付费产品,必须获得许可才能使用。
-
PlayStation:
- 提供用于 PlayStation 硬件的 CPU 分析工具。需要注册为 PlayStation® 开发者才能获取更多详细信息(需从指定入口开始)。
-
iOS:
- Xcode Instruments 和 XCode Frame Debugger: Instruments 是 Xcode 工具集的一部分,是一个强大且灵活的性能分析和测试工具。
-
WebGL:
- Firefox Profiler: 使用 Firefox Profiler 可以深入研究 Unity WebGL 构建的调用堆栈并查看火焰图等。它还具有比较工具,可以并排查看分析捕获。
- Chrome DevTools Performance: 另一个可用于分析 Unity WebGL 构建的网络浏览器工具。
GPU 调试和分析工具 (GPU Debugging and Profiling Tools)
- 目的: Unity Frame Debugger 捕获并说明从 CPU 发送的绘制调用 (draw calls),而以下工具可以帮助显示 GPU 在接收到这些命令时做了什么。
- 特点: 有些是平台特定的,并提供更紧密的平台集成。
请查看与你感兴趣的平台相关的工具:
- Arm Graphics Analyzer: Arm Mobile Studio 软件套件的一部分。
- RenderDoc: 用于桌面和移动平台的 GPU 调试器。
- Intel GPA: 用于 Intel 平台的图形分析。
- Apple Frame Capture Debugging Tools: 用于 Apple 平台的 GPU 调试。
- Visual Studio Graphics Diagnostics: 用于基于 DirectX 的平台(如 Windows 或 Xbox)(可选择此项和/或 PIX)。
- NVIDIA Nsight Frame Debugger: 用于 NVIDIA GPU 的基于 OpenGL 的帧调试器。
- AMD Radeon Developer Tool Suite: 用于 AMD GPU 的 GPU 分析器。
- Xcode frame debugger: 用于 iOS 和 macOS。