
GPU 架构演进
从固定管线到 Tesla 统一着色器
GPU 概念的诞生与早期发展
-
GPU 名称的由来:
- 1999年,NVIDIA 发布 GeForce 256 (代号 NV10),首次将其搭载的芯片称为 GPU (Graphics Processing Unit),意图与 CPU 平起平坐。
- 在此之前,显卡通常被称为“图形加速器”或“显卡”。
-
GeForce 256 的关键特性:
- 将坐标变换、灯光照明、三角形设置/裁剪以及一个每秒能处理一千万个多边形的渲染引擎集成到单一芯片上。
- 核心能力:对大量数据执行相同操作 (SIMD),这是并行计算的基础。
- 局限性:仍属于固定管线 (fixed-pipeline) 架构,处理的数据操作是内置的,更像是特定算法的加速器。
走向可编程性的 GPU 时代
为了克服固定管线的局限性,GPU 开始朝着可编程性发展:
-
GeForce 3 (2001年, NVIDIA):
- 引入了顶点着色器 (Vertex Shader)。
- 拥有可配置的片元管线。
- 进入 DirectX 8 时代。
-
Radeon 9700 (2002年, ATI):
- 支持24位可编程的片元着色器 (Fragment Shader/Pixel Shader)。
- 全面拥抱 DirectX 9。
-
GeForce FX (2003年, NVIDIA):
- 支持32位可编程片元着色器。
这一时期的核心主题是:GPU 可编程性的不断提高。
Tesla 架构的登场: 统一着色器的革命
-
发布时间: 2006年,NVIDIA 随 GeForce 8000 系列推出了基于 Tesla 架构的 GPU。
-
核心创新: 首次采用统一着色器设计 (Unified Shader Design)。
-
统一着色器设计的背景与原因:
- 传统分离设计:
- 顶点计算单元: 为坐标变换设计,特点是低延迟、高精度数学运算。因任务复杂,最早实现可编程性。
- 片元计算单元: 为纹理过滤设计,特点是高延迟、低精度。
- 问题与挑战:
- 功能重叠: 随着可编程性的发展,顶点和片元计算单元功能上出现越来越多的重合。
- 负载不均:
- 通常顶点与片元计算单元数量比约为 1:3。
- 不同程序对顶点和片元处理量的需求差异巨大,难以提前确定最佳比例。
- 处理大三角形时,顶点单元空闲;处理小三角形时,片元单元空闲。
- DirectX 10 推出的几何着色器 (Geometry Shader) 进一步增加了负载的不可预测性。
- 统一设计的优势:
- 灵活性: “全栈工程师"式的设计,可以根据需求处理顶点、片元等多种任务。
- 效率: 更好地平衡工作负载,避免资源闲置。
- 可扩展性: 为未来 GPU 执行更多通用计算任务奠定基础。
- 传统分离设计:
-
Tesla 架构的意义:
- 奠定了现代 GPU 的基础设施框架和设计思想,历久弥新。
Tesla 架构详解
Tesla 架构虽然与现代 GPU 相比核心数量较少,但五脏俱全,是理解 GPU 架构的良好起点。
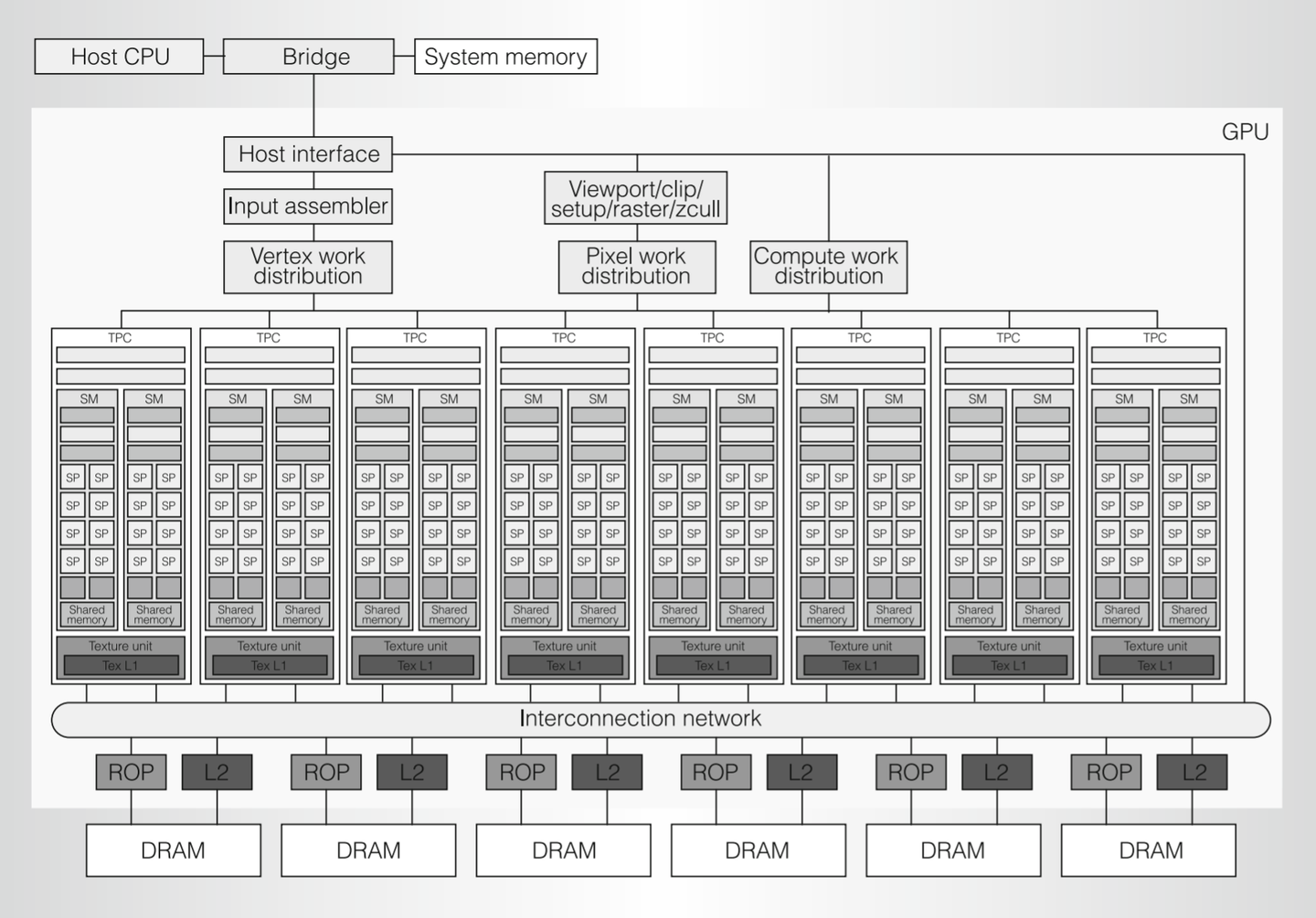
主要组件及功能:
-
Host Interface (主机接口):
- 与 CPU 通信,负责接收来自 CPU 的指令和数据。
- 处理 GPU 在不同任务间的上下文切换。
- 从系统内存获取待处理数据 (顶点数据、纹理数据、各种 buffer 等),存入显存。
-
Input Assembler (IA, 输入装配器):
- 根据顶点索引和图元类型组装从 CPU 传入的顶点数据。
- 为顶点数据搭配相应的顶点属性。
- 将组装好的数据传递给顶点工作分发单元。
-
Vertex, Pixel, Compute Work Distribution (顶点、像素、计算工作分发单元):
- 负责将各自领域 (顶点着色、片元/像素着色、计算着色) 的具体工作任务分发给底层的 TPC/SM。
-
TPC (Texture Processing Clusters, 纹理处理簇):
- 核心的计算单元,是统一着色器架构的具体体现。
- 每个 TPC 内部包含:
- 1个 纹理单元 (Texture Unit)。
- 2个 SM (Streaming Multiprocessor, 流式多处理器),负责实际的计算任务。
- TPC/SM 负责完成顶点、片元、计算等所有着色器任务。
-
Viewport/Clip/Setup/Raster/Zcull Block (视口/裁剪/设置/光栅化/Z剔除模块):
- 处理顶点着色器输出的裁剪坐标 (此时尚未进行透视除法)。
- 负责视口变换、裁剪、三角形设置 (计算边方程等)、光栅化 (将矢量图形转换为像素片元)、Z剔除 (早期深度测试剔除被遮挡片元) 等固定功能。
-
ROP (Raster Operations Processor, 光栅操作处理器):
- 在片元着色器处理完毕后,对像素进行最终测试和混合操作。
- 功能包括:
- 深度测试 (Depth Test) 和模板测试 (Stencil Test) 及写入。
- 颜色混合 (Color Blending)。
- 抗锯齿 (Anti-aliasing)。
- 负责将最终像素颜色数据写入帧缓冲 (Framebuffer)。
-
L2 Cache (二级缓存)、Memory Controller (显存控制器) 和 DRAM (显存):
- 通常有多组 (图中为6组),每组由 ROP、L2 Cache、Memory Controller 和对应的 DRAM 物理显存部分构成。
- L2 Cache 作为 SM 和 ROP 访问显存的共享缓存。
- Memory Controller 负责管理对 DRAM 的数据读写请求,合并请求、根据优先级调度,以最大化数据传输效率。
- DRAM (显存) 用于存储顶点数据、纹理、帧缓冲等 GPU 处理所需和产生的全部数据。
总结: Tesla 架构通过统一的 TPC/SM 结构实现了计算资源的灵活调度和高效利用,其分层、并行的设计思想对后续 GPU 发展产生了深远影响。
Tesla 架构: TPC, SM 与并行计算核心机制
TPC (纹理处理簇) 内部结构与功能
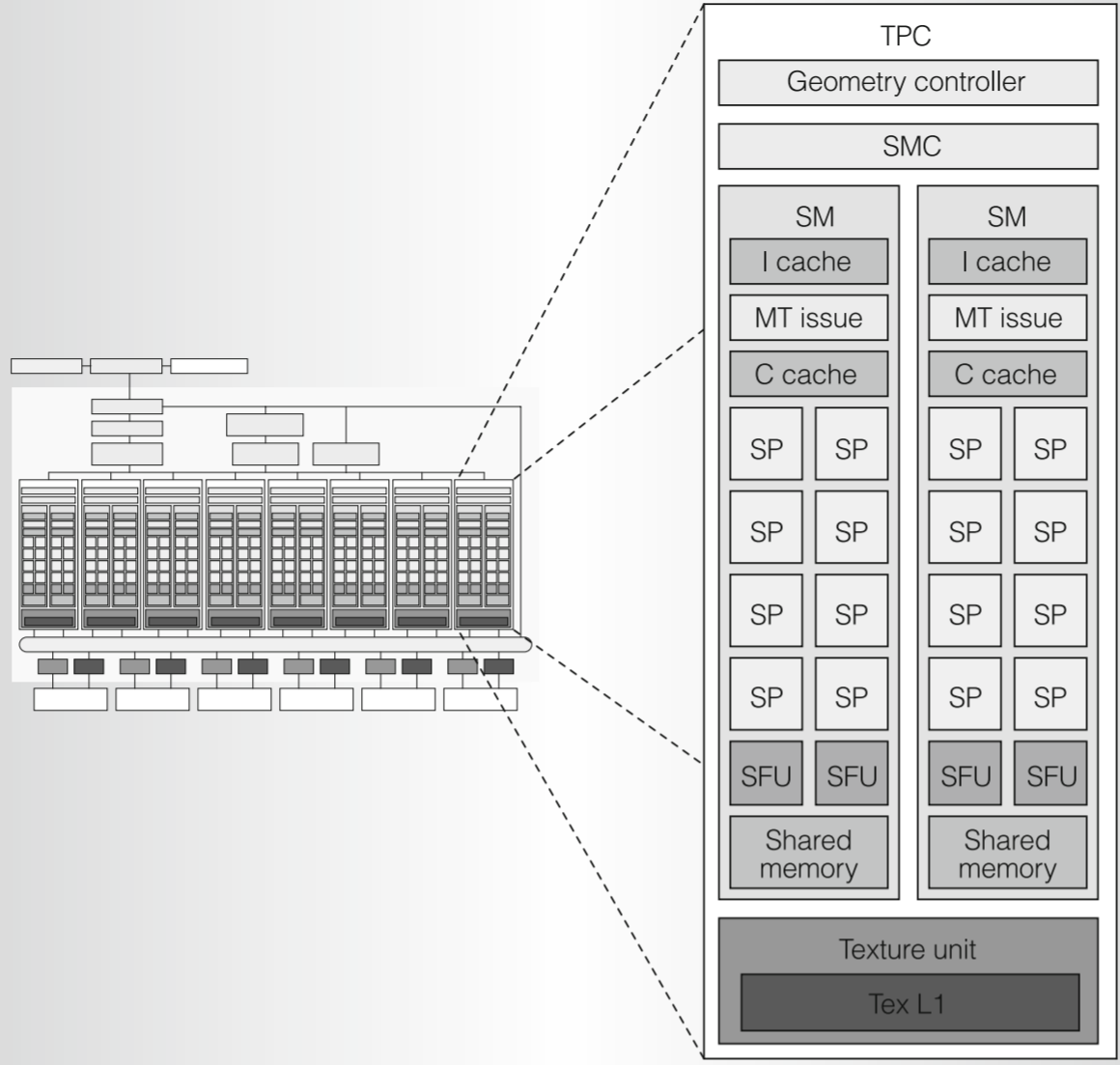 TPC (Texture Processing Clusters) 是 Tesla 架构中执行具体工作的主要单元。一个 GPU 内通常有多个 TPC。
TPC (Texture Processing Clusters) 是 Tesla 架构中执行具体工作的主要单元。一个 GPU 内通常有多个 TPC。
-
Geometry Controller (几何控制器):
- 职责: 管理光栅化之前的几何阶段,包括顶点属性在芯片内的输入输出。处理几何着色器 (Geometry Shader) 中增减顶点、改变拓扑结构的操作。
- 运算执行: 顶点着色器和几何着色器的运算指令仍由 SM 执行。
- 数据流向: 将最终结果送往
Viewport/clip/setup/raster/zcull block模块进行光栅化,或通过 Stream Out 输出回内存。 - 后续演进: 在 Fermi 架构中被升级为 PolyMorph Engine。
-
SMC (SM Controller, SM 控制器):
- 职责: 作为 TPC 内的高层管理者,负责将来自上层分发的各种任务 (顶点、几何、片元着色器,以及 CUDA 等并行运算任务) 拆分打包成 Warp,并交给其内部的 SM 处理。
- 资源协调:
- 协调 SM 与共享的 Texture Unit 之间工作,以获取外部纹理资源。
- 通过 ROP (光栅操作处理器) 与外界进行显存中其他非纹理资源的读写及原子操作。
- 核心功能: 对接外部资源,进行内部任务分配,实现负载平衡。
-
Texture Unit (纹理单元):
- 构成: 例如,包含4个纹理地址生成器和8个滤波单元 (支持全速的2:1各向异性过滤)。
- 指令特性: 与 SM 内的标量运算不同,纹理单元指令源是纹理坐标 (向量),输出是经过插值的纹理值 (如RGBA,向量)。
- 缓存: 获取到的纹理数据会存放在 Tex L1 cache 中。
-
SM (Streaming Multiprocessor, 流式多处理器): 最底层的运算执行单元。
- I-Cache (Instruction Cache, 指令缓存): 缓存来自 SMC 的大量指令,分批执行。
- C-Cache (Constant Cache, 常量缓存) 与 Shared Memory (共享内存): 用于通用计算 (CUDA),后续章节详解。
- MT Issue (Multi-threaded Issue, 多线程指令发射单元): SM 内部的调度核心。
- 负责将 Warp 任务进一步拆分成一条条指令,分发给 SP 和 SFU 执行。
- 其对 Warp 的调度是 GPU 并行能力的关键。
- SP (Streaming Processor, 流处理器):
- 主要的计算单元,执行基本的浮点型标量运算 (如 add, multiply, multiply-add) 和各种整数运算。
- SFU (Special Function Unit, 特殊功能单元):
- 执行更复杂的运算,例如:
- 超越函数 (指数、对数、三角函数等)。
- 属性插值 (将顶点属性插值到光栅化后的每个片元)。
- 透视校正插值 (先插值除以w的属性,插值完再乘回w)。
- 执行更复杂的运算,例如:
Warp: GPU 并行执行的基础
-
指令流:
- 高级着色器代码或 CUDA Kernel 程序 -> 编译成中间指令 -> 优化器转化为二进制 GPU 指令。
- Tesla 架构中,运算 SIMD 指令的计算单元已被移除,向量指令 (如4维向量相加) 会被拆分成多条 SM 标量指令 (如4个标量相加)。
-
ISA (Instruction Set Architecture, 指令集架构) 主要类型:
- 运算指令: 浮点/整数加法、乘法、最小/最大值、比较、类型转换、超越函数等。
- 流控制指令: 分支、调用、返回、中断、同步。
- 内存访问指令: 对各类内存的读写、原子操作。
-
Warp 定义与执行:
- SMC 将需要执行相同着色器/Kernel 指令的 32个线程 组成一个 Warp。
- 一个 Warp 的所有指令存储在 SM 的 I-Cache 中。
- MT Issue 单元每次从 Warp 中取一条指令,分发给 SP 或 SFU。
- 一个 SM 内的 SP 数量 (如8个) 通常少于 Warp 中的线程数 (32个)。因此,SP 需要多个周期 (如 32线程 / 8SP = 4个周期) 才能完成 Warp 中所有线程对单条指令的执行。
- 这种执行模式称为 SIMT (Single Instruction, Multiple Thread, 单指令多线程)。
-
分支发散 (Branch Divergence):
- 问题: 由于每个线程的输入数据不同,一个 Warp 内的不同线程可能会在条件分支处进入不同的执行路径。
- 处理机制:
- 编译器预测: 在某些情况下,编译器可以判断 Warp 中所有线程是否必然进入同一分支。
- Warp Voting (Warp表决): 若无法预测,则在执行时进行硬件表决。如果所有线程仍走同一分支,则跳过其他分支。
- 串行化 (Serialization): 如果线程进入不同分支,则这些不同分支路径必须串行执行。不进入当前执行分支的线程将被 屏蔽 (Masked) 并等待。即使只有一个线程进入某个分支,其他31个线程也必须等待。
- 代价: 为了实现一条指令指挥32个线程的效率,牺牲了部分灵活性,这是锁步运行 (Lock-step execution) 的特性。
延迟隐藏 (Latency Hiding): 榨干硬件性能的关键
-
核心挑战: 硬件计算速度远快于内存访问速度,内存访问延迟是主要瓶颈。
-
延迟隐藏机制:
- 当一个 Warp 中的线程遇到内存访问指令 (由 SMC 向外界请求数据),会导致执行停顿。
- 为了避免 SP 空闲,MT Issue 单元会快速切换到另一个已就绪、可以执行的 Warp 上继续执行。
- SM 内的 I-Cache 能够存储足够多 Warp 的指令 (Tesla 架构最多支持24个活动 Warp,可以是不同类型),支持这种快速切换。
- 当之前等待数据的 Warp 获取到数据后,它可以被重新调度执行。
- 目标: 通过在多个 Warp 之间快速切换,保持计算单元 (SP、SFU) 持续繁忙,隐藏内存延迟。
-
Warp 调度策略:
- MT Issue 单元从多个待执行的 Warp 中挑选一个来执行其下一条指令。
- 计分板 (Scoreboarding) 机制:根据 Warp 类型、指令类型和公平性原则等因素为每个待选 Warp打分。
- MT Issue 每两个处理器周期从中挑选一个得分最高的 Warp,分配给对应的计算单元 (SP 或 SFU) 执行。
- 指令分发频率: 例如,每两个处理器周期分发一次指令。这种频率设计是为了保证 MT Issue 有充足的时间为 SP 和 SFU 分配任务,使所有计算单元都能满负荷运转。
- 例如,若 SP 执行 Warp 的一条指令需要4个周期,而 MT Issue 2个周期分发一次,可以确保在 SP 忙碌时,SFU 也能被调度任务。
-
Warp 粒度的影响:
- 粒度过粗 (Warp 数量少): 可供调度的 Warp 不足,不利于有效隐藏延迟。
- 粒度过细 (单个 Warp 执行的线程少): 每次切换 Warp 的相对开销变高。 (32线程/Warp 是一个长期实践中相对优化的选择)
总结: Warp 调度和延迟隐藏是 GPU 高性能并行运算的核心。通过精心设计的硬件单元 (TPC, SMC, SM, SP, SFU) 和调度机制 (MT Issue, Warp, SIMT),Tesla 架构旨在最大限度地利用每一个计算资源,榨干硬件性能,即使这意味着复杂的内部管理和调度。这一核心思想贯穿了后续 GPU 架构的发展。
Tesla 架构: 通用计算及其内存体系
从图形处理到通用计算 (GPGPU)
-
SM 的通用性:
- GPU 的核心计算单元 SM (Streaming Multiprocessor) 本质上已与图形处理解耦,成为通用的并行计算单元。
- NVIDIA 有意将图形相关的固定操作 (如光栅化) 剥离到独立硬件单元 (如 Geometry Controller, Rasterizer),使 SM 能专注于更广泛的并行计算任务。
-
图形管线 vs. 通用计算管线:
- 图形管线:
- 流程相对固定,有专门硬件处理不可编程模块以提高效率。
- 程序员对线程分配 (如何运行顶点/片元计算) 和数据流 (顶点到片元) 的控制有限,大部分由 GPU 自动管理。
- 线程协作模式固定 (如片元着色器中2x2线程组用于计算ddx/ddy差分)。
- 通用计算管线:
- 程序员完全控制: 线程的分配、调用、每个线程处理的任务 (计算内容、数据获取与输出) 均由程序员定义。
- 协作式线程: 程序员可以根据线程ID分配不同任务,并设计线程间的数据传递与协作模型。
- 性能: 提供了更高的性能上限 (通过定制化优化),但也存在性能下限的风险 (若缺乏硬件理解和优化技巧)。
- 图形管线:
-
CUDA 与 计算着色器 (Compute Shader):
- CUDA (Compute Unified Device Architecture): NVIDIA率先推出的通用并行计算平台和编程模型,最初与图形API分离。
- 计算着色器: 后续由各图形API (如DirectX, Vulkan) 引入,允许在图形管线内利用GPU的通用计算能力。底层硬件与CUDA使用的通用计算模型一致。
线程组织结构 (以 CUDA 为例)
-
三级层次结构:
Grid->Block->Thread- Thread (线程): 最基本的执行单位。
- Block (线程块):
- 包含一组线程 (数量在核函数中定义)。
- 是协作发生的基本单位 (也称 CTA, Cooperative Thread Array)。
- Block 内的线程可以通过 共享内存 (Shared Memory) 高效传递数据并进行同步。
- Grid (线程格):
- 包含一组 Block (数量在应用程序调用时指定)。
- 同一个 Grid 内的不同 Block 之间通常是完全独立的,默认无直接数据依赖或通信机制 (更高级的同步可通过 “Cooperative Groups” 等新特性实现)。
-
线程ID:
- 由于线程与任务的映射由程序员决定,需要唯一的线程ID来区分并分配工作。
- Grid 和 Block 均可组织为一维、二维或三维结构。
- API 提供内置变量 (如
threadIdx,blockIdx,blockDim,gridDim在CUDA中;DirectX中有类似的SV_DispatchThreadID,SV_GroupID,SV_GroupThreadID,SV_GroupIndex) 来方便地获取各种维度的线程ID,避免手动计算开销。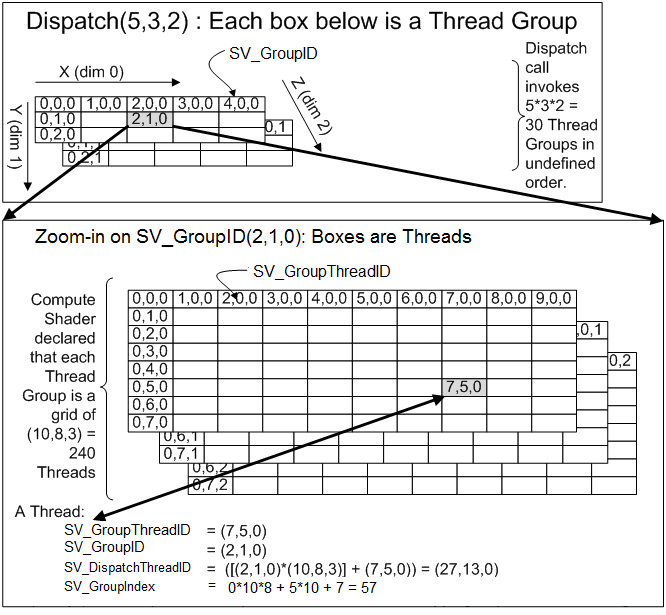
Warp: 真正的并行与优化核心
尽管上层线程组织复杂,但GPU硬件层面真正的并行执行单位始终是 Warp (通常为32个线程)。GPGPU 优化多围绕 Warp 进行:
-
Block 线程数:
- 建议将每个 Block 分配的线程数设为 Warp 大小 (32) 的整数倍。
- 例如,33个线程与64个线程同样需要执行两个 Warp,前者会造成资源浪费。
-
分支一致性 (Branch Coherence):
- 尽量让同一个 Warp 内的线程执行相同的代码分支。
- 如果算法中不同线程需执行不同分支,若能通过任务重排使 Warp1 只执行分支A,Warp2 只执行分支B,可提升性能 (避免Warp内分支发散导致的串行化)。
-
同步 (Synchronization):
- Warp 内: 由于 Warp 内线程锁步执行 (lock-step),它们之间读取由同一Warp内其他线程写入的数据通常无需显式同步 (数据已写入)。
- Warp 间: 若不同 Warp 间存在数据依赖 (如 Warp1 读取 Warp2 写入共享内存的数据),则必须同步。因为 Warp 的调度由硬件决定,对程序员不透明,无法预知Warp2的执行进度。
GPU 内存层级详解 (以 CUDA 视角)
高效的内存访问是支撑 GPU 高速计算的关键。GPU 拥有分级的内存“物流”系统:
-
全局内存 (Global Memory) 与 L2 缓存 (L2 Cache):
- 全局内存: 即显卡上的显存 (DRAM),容量最大,延迟最高,带宽相对较低。GPU外的存储。
- L2 缓存: 片上缓存,位于SM之外,可供所有SM共同使用,用于缓存对全局内存的访问。
- Grid 间同步: 不同 Grid 的执行是串行的。若它们对同一块全局内存数据存在依赖,由硬件负责同步。
- 内存合并 (Memory Coalescing): 当一个 Warp 中的连续线程访问全局内存中的连续地址时,这些访问可以被硬件合并为更少次数的内存事务,显著提高有效带宽。
-
共享内存 (Shared Memory) 与 L1 缓存 (L1 Cache):
- 位置: 位于每个 SM 内部,访问速度远快于全局内存和L2缓存。
- 共享内存:
- 可见性: 对同一个 Block 内的所有线程可见并共享。这意味着一个 Block 内的所有线程都在同一个 SM 上执行。
- 协作基础: 是实现 Block 内线程高效协作和数据交换的关键 (例如,并行归约算法如生成Mipmap)。
- Block 间隔离: 不同 Block 之间通常不能通过共享内存通信 (因为它们可能在不同SM上)。这也是一个Block的最大线程数受限的原因之一 (一个SM能容纳的Warp和资源有限)。
- Bank 冲突 (Bank Conflicts):
- 共享内存被划分为多个独立的存储体 (Bank,如32个)。每个Bank在一个周期内通常只能服务一个读或写请求 (32位数据)。
- 如果一个Warp内的多个线程同时访问映射到同一个Bank的不同地址,这些访问会串行化,降低并行度。
- 读操作: 现代硬件通常支持对同一Bank同一地址的广播读取,不会冲突。
- 写操作: 需小心安排内存访问模式,使各线程写入的地址尽可能分布到不同Bank。
- L1 缓存:
- Tesla架构: L1缓存主要用于缓存纹理数据。
- 后续架构: L1缓存通常与共享内存共享同一块片上物理存储单元,其各自的大小可以由用户配置。
-
局部内存 (Local Memory) 与 寄存器文件 (Register Files):
- 寄存器文件 (Register Files):
- 每个线程私有的最快存储。用于存放局部变量。
- 数量有限。
- 局部内存 (Local Memory):
- 当线程的局部变量过多,无法全部存放在寄存器中时 (寄存器溢出),这些变量会被存储到“局部内存”中。
- 局部内存在物理上通常是 L1 缓存,如果L1也不足,则可能进一步溢出到L2缓存,甚至全局内存。每次溢出都会带来显著的性能下降。
- Shuffle 指令:
- 较新的硬件支持。允许在一个 Warp 内的线程间直接交换数据 (寄存器级别),无需通过共享内存读写,速度更快。
- 寄存器文件 (Register Files):
Fermi 架构概述
背景与目标
- 定位: 作为Tesla架构的成熟后续者,旨在解决Tesla的瓶颈,通常科技产品的第二代是集大成之作。
- 核心特性:
- 完整支持 DirectX 11 的所有硬件功能。
- 关键技术包括 细分曲面 (Tessellation) 和 计算着色器 (Compute Shader)。
- 主要解决的问题:
- 提升几何处理能力,以追求电影级的几何真实感。
- 2010年时,游戏每帧百万级三角形远少于电影的数亿级,导致模型精细度差异巨大。Fermi旨在缩小这一差距。
回顾: Tesla 架构的几何瓶颈
Tesla架构虽然统一了着色器,但在几何处理上存在瓶颈:
- 计算与几何处理单元失衡:
- SM (流式多处理器) 内的计算单元众多。
- 负责视口变换、裁剪、属性设置、光栅化、剔除等固定管线的几何操作单元相对集中且数量有限。
- 具体瓶颈点:
- CPU-GPU 带宽限制: GPU能从CPU获取的初始顶点数量有限。随着计算单元增强,带宽瓶颈更突出。
- 固定几何管线拥塞: 顶点着色器处理后产生的大量顶点,都必须通过集中的固定几何操作管线才能转化为片元,容易造成堵塞。
Fermi 架构的关键改进
 为解决上述瓶颈,Fermi架构进行了显著调整:
为解决上述瓶颈,Fermi架构进行了显著调整:
-
制程工艺与资源提升:
- 制程: 从Tesla的90nm提升至 40nm,允许集成更多晶体管。
- SM内部: 每个SM集成了更多的计算单元。
- ROP (光栅操作处理器): 每组显存控制器/L2分区从Tesla的1个ROP增加至 8个ROP。ROP单元位于L2 Cache附近的“ROP分区”,便于与SM快速数据传输。
-
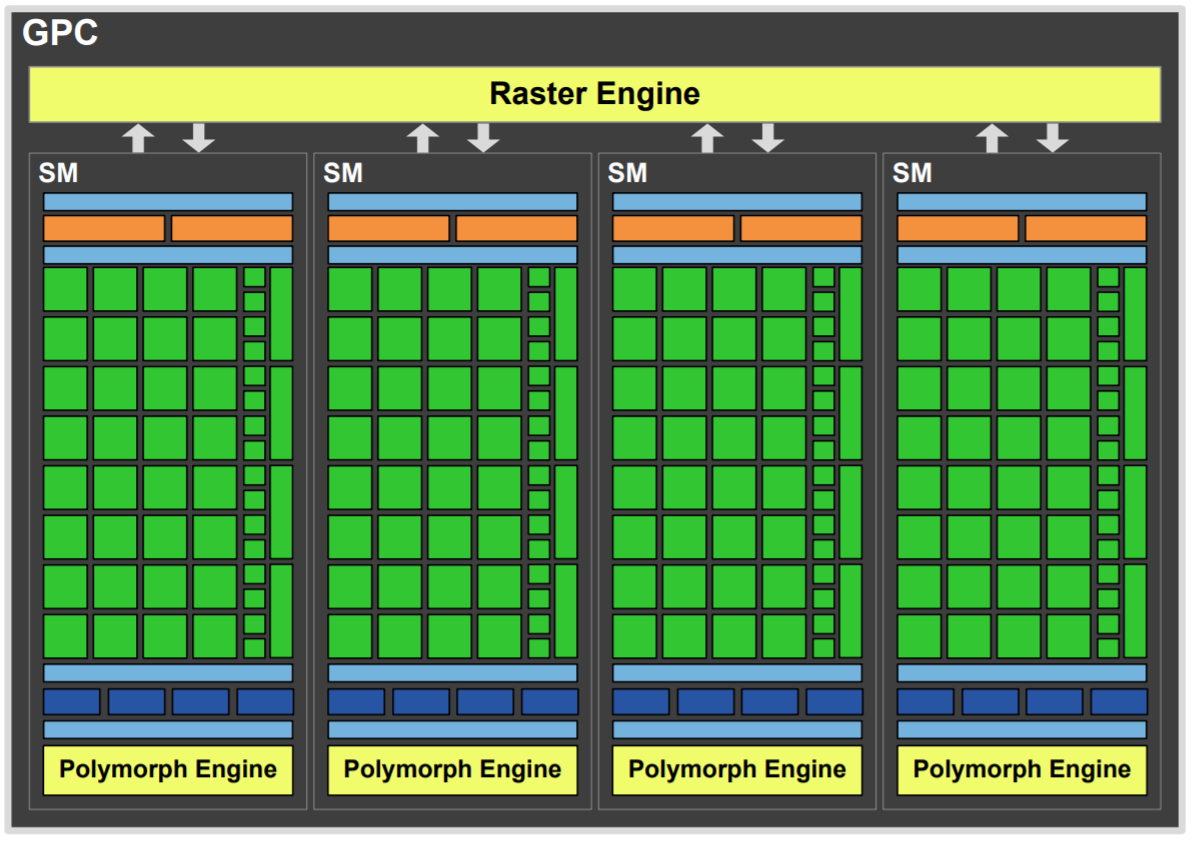
GPC (Graphics Processing Clusters, 图形处理簇):
- 由Tesla架构中的TPC (Texture Processing Clusters) 演变而来。
- GPC功能更完整、更独立,几乎可以完成GPU的绝大多数功能 (只要能通过L2 Cache与外界接触),便于针对不同市场灵活调整GPU规模。
-
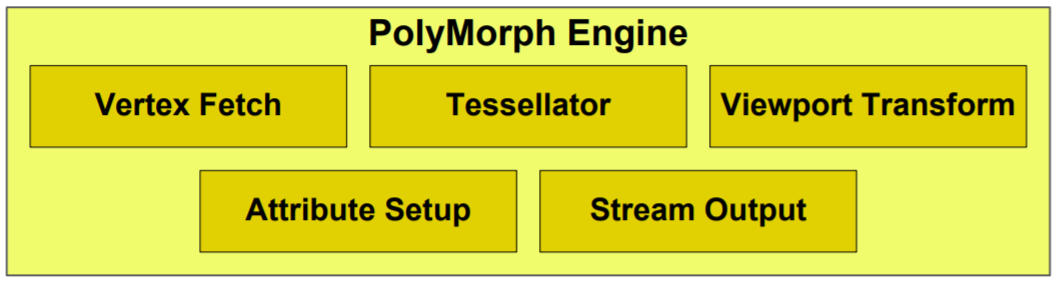
关键单元的重构与并行化:
- PolyMorph Engine (多形体引擎):
- 每个SM标配一个。
- 集成了所有几何相关的固定功能和可配置阶段,包括顶点拾取、细分曲面单元 (Tessellator)、视口变换、属性设置、流输出 (Stream Output) 等。
- 核心作用: 将原本集中的几何处理能力分散到每个SM中,实现几何处理的并行化,是解决几何瓶颈的关键。
- Raster Engine (光栅化引擎):
- 每个GPC拥有一个 (例如,服务于其内部的4个SM)。
- 配合PolyMorph Engine,进一步并行化处理光栅化任务,以应对增加的三角形数量。

- 纹理单元 (Texture Units):
- 数量大幅增加,并且移入每个SM内部 (后续章节会说明一个SM有4个纹理单元)。这解决了Tesla中1个纹理单元服务2个SM可能存在的瓶颈。
- PolyMorph Engine (多形体引擎):
核心技术与应用: 突破几何瓶颈
Fermi通过引入新技术并辅以硬件架构调整来突破几何瓶颈:
-
细分曲面 (Tessellation):
- 目的: 解决CPU-GPU带宽瓶颈,允许GPU根据较少的输入顶点动态生成大量新顶点,从而提升模型表面的平滑度和细节层次。
- 处理流程 (三阶段):
- 外壳着色器 (Hull Shader / Tessellation Control Shader - TCS): 可编程阶段 (由SM内的CUDA core执行)。负责决定每个输入面片 (Patch) 的细分程度(输出Tessellation Factors)和传递控制点。
- 细分器 (Tessellator): 固定功能单元 (位于每个SM的PolyMorph Engine内部)。根据HS/TCS输出的参数,按照内置规则生成新的顶点和图元拓扑。
- 域着色器 (Domain Shader / Tessellation Evaluation Shader - TES): 可编程阶段 (由SM内的CUDA core执行)。功能类似顶点着色器,但处理的是由细分器生成的所有顶点 (包括原始顶点和新生成的顶点),计算它们的最终位置和其它属性。
- 架构支持: 每个SM配备PolyMorph Engine (内含Tessellator) 使得海量细分请求得以并行处理,避免了数据传输和处理瓶颈。增加的Raster Engine数量也适应了细分后三角形数量的激增。
-
置换贴图 (Displacement Mapping):
- 目的: 在细分曲面提供的平滑基础上,进一步增加模型表面的精细几何细节,实现更真实的视觉效果。
- 原理: 一种高级的纹理技巧。在TES阶段 (或后续的顶点处理阶段),使用置换贴图中的数据来实际改变顶点在三维空间中的位置,这一过程发生在光栅化之前。
- 优势:
- 内存效率: 模型细节以纹理形式存储,相比直接存储大量顶点数据,内存占用更紧凑,减少了带宽需求。
- LOD (Level of Detail): 纹理的Mipmap机制可为置换效果提供天然的LOD支持。
- 动态修改: 作为纹理,内容更易于在游戏中实时修改,可用于贴花 (Decals) 等效果。
- 架构支持: Fermi架构中大幅增加的ROP数量和每个SM内部集成的多个纹理单元 (如4个),为置换贴图以及其他纹理密集型渲染技术 (如PBR管线、延迟渲染) 的普及提供了强大的硬件基础。
总结
Fermi架构通过将几何处理单元 (PolyMorph Engine) 分散到每个SM,并增加光栅化引擎 (Raster Engine) 和纹理单元 (Texture Units) 的数量,成功地并行化了原先集中的几何处理流程。结合细分曲面和置换贴图等DirectX 11关键技术,显著提升了GPU的几何处理能力和渲染真实感,标志着GPU发展的一个重要成熟阶段。
GPU 图形渲染管线详解 (Fermi 架构)
本文详细梳理了图形渲染管线,以NVIDIA Fermi架构为背景,介绍了从数据准备到最终像素输出的完整流程。
数据从 CPU 到 GPU
数据准备与传输
- 数据源: 三角形等图元最初存储在硬盘中,顶点数据(Vertex Buffer)和顶点索引(Index Buffer)是其基本构成。一个顶点可能被多个三角形共享。
- CPU 处理: CPU 发出指令,数据从硬盘加载到系统内存。
- 显存传输: 数据从系统内存传输到 GPU 的显存 (DRAM)。
图形 API 与 GPU 指令
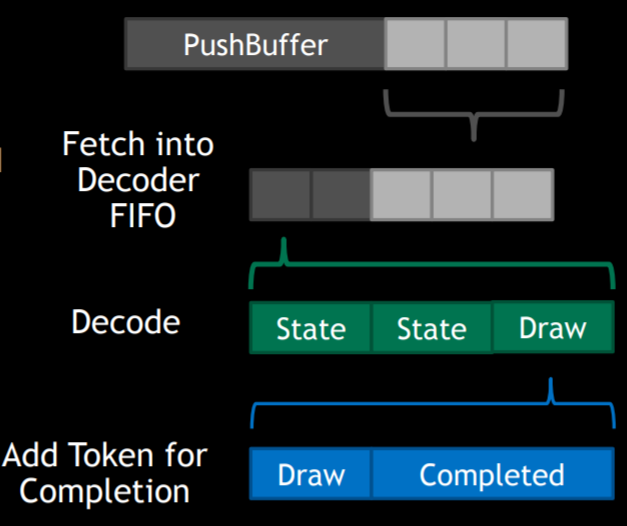
- 图形 API: 应用程序通过图形 API (如 DirectX, OpenGL) 发出渲染指令。
- 驱动转换: 驱动程序将 API 调用翻译成 GPU 可读的指令编码。
- Pushbuffer: 这些 GPU 指令存放在 Pushbuffer 中,待机发射。
- Host Interface: GPU 的 Host Interface 接收指令,并交由 Front End 处理。
- Front End:
- 解码和分类指令。
- 处理状态 (State) 类操作:有些立即执行,有些等待光栅化后执行,重复多余的状态设置会被丢弃。
Drawcall指令是驱动 GPU 开始处理几何数据的关键。
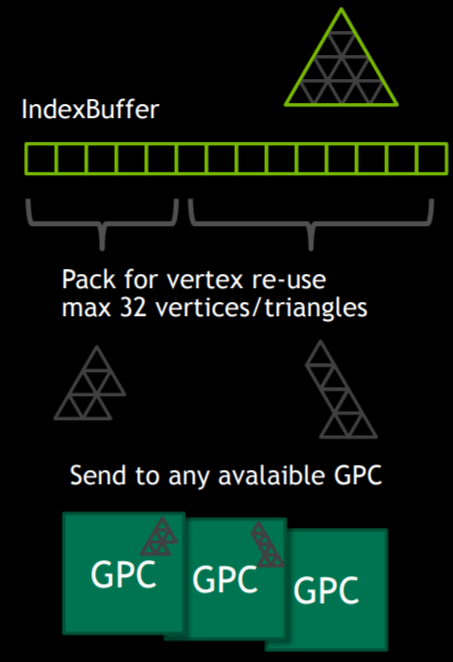
图元分发 (Primitive Distributor)
- Batching: 为适应 GPU 并行处理,图元数据被拆分成小的批次 (Batch)。
- 一个 Batch 最多包含32个顶点或32个图元 (如三角形)。
- 这种小批次限制了单个 Batch 内顶点的平均复用率(例如,32个顶点的batch,若都是独立三角形,复用率低;若要填满warp,平均复用率最高为3)。
- 索引压缩: 原始顶点索引被压缩,剔除重复索引,生成更精简的批次内顶点索引。
- 并行处理: 不同的 Batch 可能被分发到不同的 GPC (Graphics Processing Cluster) 或 SM (Streaming Multiprocessor) 中独立处理。
- 顶点冗余: 处于 Batch 边缘的共享顶点可能会被重复处理,以保证并行性。
顶点获取 (Vertex Fetch)
- 组件: 由 Polymorph Engine 内的 Vertex Fetch 单元负责。
- 功能: 当一个 Batch 被分配到特定 SM 时,Vertex Fetch 单元将相应的顶点数据从显存 (DRAM) 加载到该 SM 的 L1 Cache 中,供后续着色器使用。
几何阶段
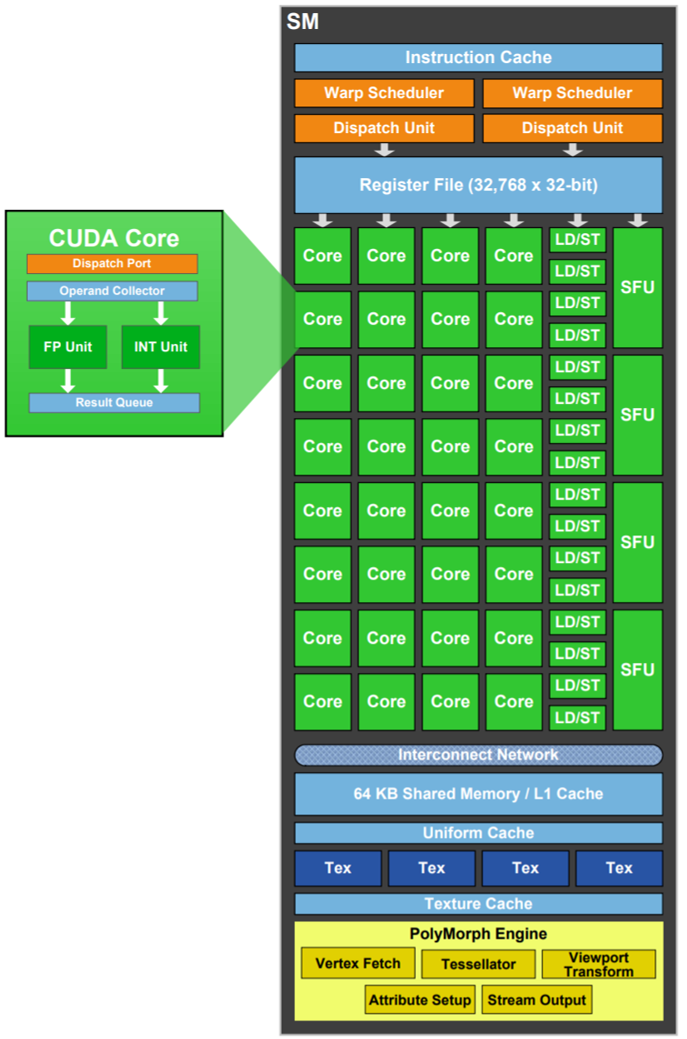
GPU 的 SM (Streaming Multiprocessor) 在 Fermi 架构中得到改进,包括更多的计算核心和纹理单元,FMA 指令支持双精度,以及双 Warp 调度机制(每个周期可向两个执行块分发一或两个Warp)。Warp 切换周期仍为两个处理器周期。
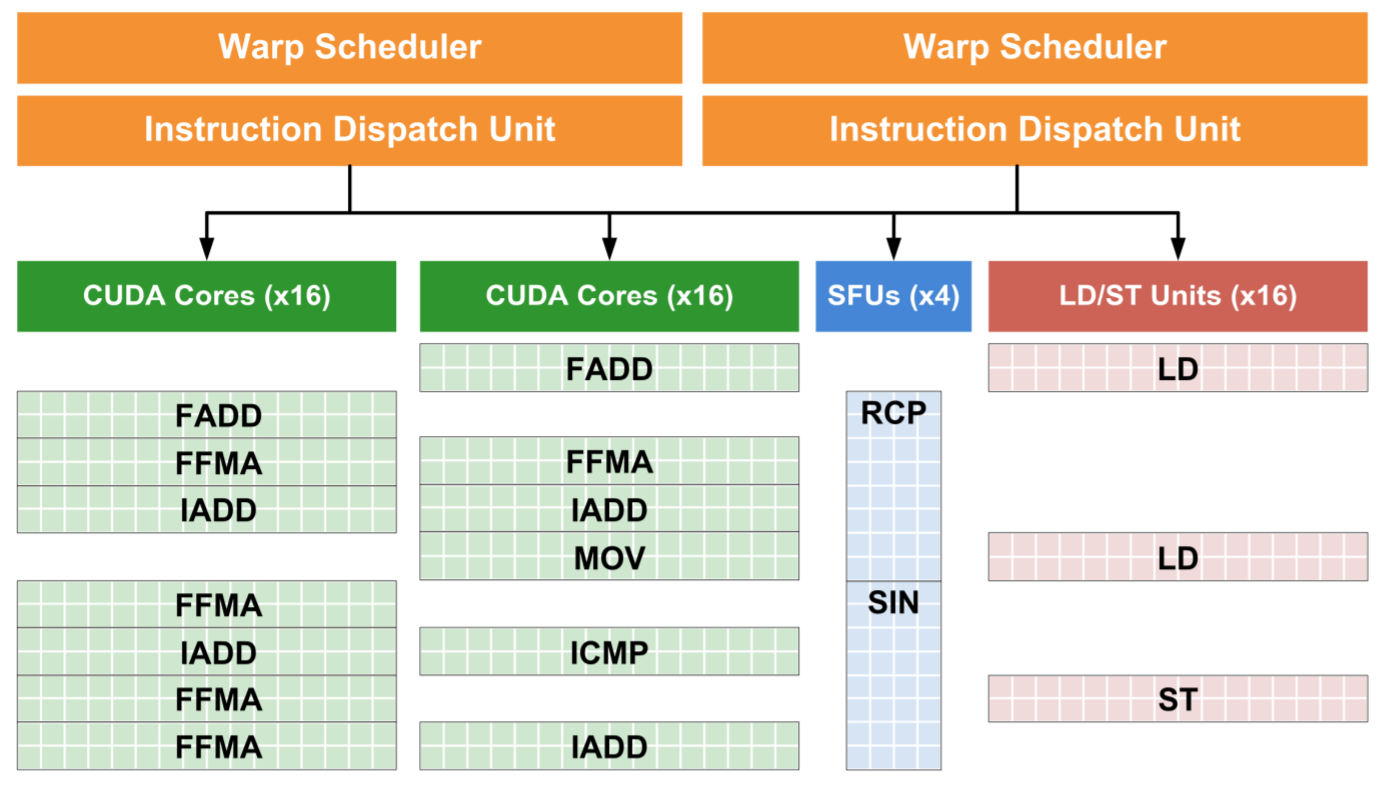
顶点着色器 (Vertex Shader)
- 执行单位: 一个 Batch 的顶点 (如32个) 组成一个 Warp,在 SM 内的 CUDA Core 上并行执行。
- 数据隔离: 每个顶点着色器线程处理一个顶点,线程间通常不直接通信。
- Warp 调度:
- SM 内有多个 Warp (可能来自顶点、片元、计算着色器等)。
- Warp Scheduler 按调度策略切换执行的 Warp。
- Dispatch 单元指挥 Warp 从寄存器文件读取数据,在 Core 中执行指令,执行后写回数据,让出 Core 给其他 Warp。
- 主要任务:
- 对顶点进行坐标变换 (例如,从模型空间到世界空间,再到观察空间,最终输出到裁剪空间)。
- 如果后续有细分或几何着色器,裁剪空间变换也可由它们完成。
细分控制着色器 (TCS / Hull Shader)
- 执行位置: 通常在顶点着色器所在的 SM 中执行。
- 处理单位:
Patch(由drawcall指定,如一个三角形 patch 有3个控制点)。一个 Patch 最多32个顶点。 - 线程分配: TCS 输出顶点数决定 Patch 的线程数,每个线程有
gl_InvocationID。 - 数据共享: Patch 内的 TCS 线程可以访问该 Patch 的所有输入和输出数据,可能需要
barrier()同步。 - 主要职责:
- 传递顶点属性给 TES (Tessellation Evaluation Shader)。
- 计算细分因子 (
gl_TessLevelInner,gl_TessLevelOuter),指导 Tessellator 如何细分 Patch。
- 数据流: TCS 输出的顶点是数据,供 TES 插值使用,不直接决定最终顶点数量。如果细分因子由 API 预设,TCS 可选。
- Work Distribution Crossbar: 根据细分因子,Patch 可能会被转移到其他 SM 处理,以应对顶点数量的急剧膨胀。
镶嵌器 (Tessellator) - 固定管线单元
- 位置: Polymorph Engine 内部署。
- 输入:
- TCS 输出的细分因子。
- TES 中指定的参数:图元生成域 (triangles, quads, isolines)、细分顶点空间划分规则、图元面朝向、点模式。
- 功能:
- 在抽象的 Patch (由图元生成域决定,如标准三角形或正方形) 上根据细分因子和参数插入新的点。
- 输出这些新顶点在抽象 Patch 中的归一化坐标 (如重心坐标)。
- 不处理实际顶点属性数据。
细分评估着色器 (TES / Domain Shader)
- 输入:
- Tessellator 生成的新顶点细分坐标 (
gl_TessCoord)。 - TCS 输出的整个 Patch 的控制点顶点数据。
- Tessellator 生成的新顶点细分坐标 (
- 功能:
- 每个 TES 线程负责一个新顶点。
- 使用
gl_TessCoord和 Patch 控制点数据进行插值,计算新顶点的最终属性。
- 图元重构: 新顶点诞生后,旧 Patch 结构消失,根据图元类型和朝向形成新的图元 (如三角形)。
几何着色器 (Geometry Shader) - 可选阶段
- 分配: Task Distributor 将图元分配给几何着色器。
- 执行单位: 一个 Warp 由多个图元 (如32个三角形) 组成,每个线程处理一个输入图元。
- 数据访问: 几何着色器线程可以访问其输入图元的所有顶点数据。
- 强大功能 (及代价):
- 可输出任意数量、任意类型的图元 (点、线、三角形)。
- 可修改顶点属性,甚至实例化图元 (分层渲染、多流输出)。
- 性能问题 (“诅咒”):
- 高自由度带来串行化: 输出可变数量图元类似CPU端的API调用,破坏并行性。
- 缓存压力: 为保证图元输出顺序,需缓存所有输出顶点。每个GS线程所需缓存远大于VS或TCS/TES。
- NVIDIA 方案: 缓存于片内 (on-chip),容量小,易满,导致SM能容纳的Warp数受限,引发拥塞。
- AMD 方案: 缓存于显存 (DRAM),容量大,但带宽高延迟,导致SM空闲等待数据。
流输出 (Stream Output) - 可选阶段
- 功能: 几何阶段 (顶点、细分或几何着色器) 处理后的顶点数据可以不进入光栅化,而是直接写回显存中的缓冲区。
- 后续: 这些数据可被CPU回读,或作为下一轮渲染管线的输入。
顶点后处理 (Vertex Post-Processing)
- 位置: Polymorph Engine 内部署。
- 图元装配 (Primitive Assembly): 将独立的顶点组装成图元 (如三角形)。
- 视锥裁剪 (View Frustum Culling & Clipping):
- 完全在内: 保留。
- 完全在外: 剔除。
- 相交:
- 与近平面相交: 必须裁剪。原因:1) 计算相对简单;2) 不裁剪会导致后续透视除法错误 (三角形翻转)。
- 与其他平面相交: (“Guard-band clipping”) 若裁剪计算复杂,且不裁剪不影响光栅化结果 (超出视口部分不被光栅化),则尽量不裁剪。除非顶点坐标过大,超出硬件处理范围 (通常硬件坐标用定点数存储,范围有限),则必须裁剪。
- 透视除法 (Perspective Divide):
- 顶点的 $x, y, z$ 坐标除以其 $w$ 坐标,得到归一化设备坐标 (NDC)。
- 视口变换 (Viewport Transform):
- 将 NDC 坐标转换到屏幕坐标 (像素坐标)。
- 公式示例: $p_x = (NDC_x + 1) \times \frac{ScreenWidth}{2}$, $p_y = (NDC_y + 1) \times \frac{ScreenHeight}{2}$。
光栅阶段
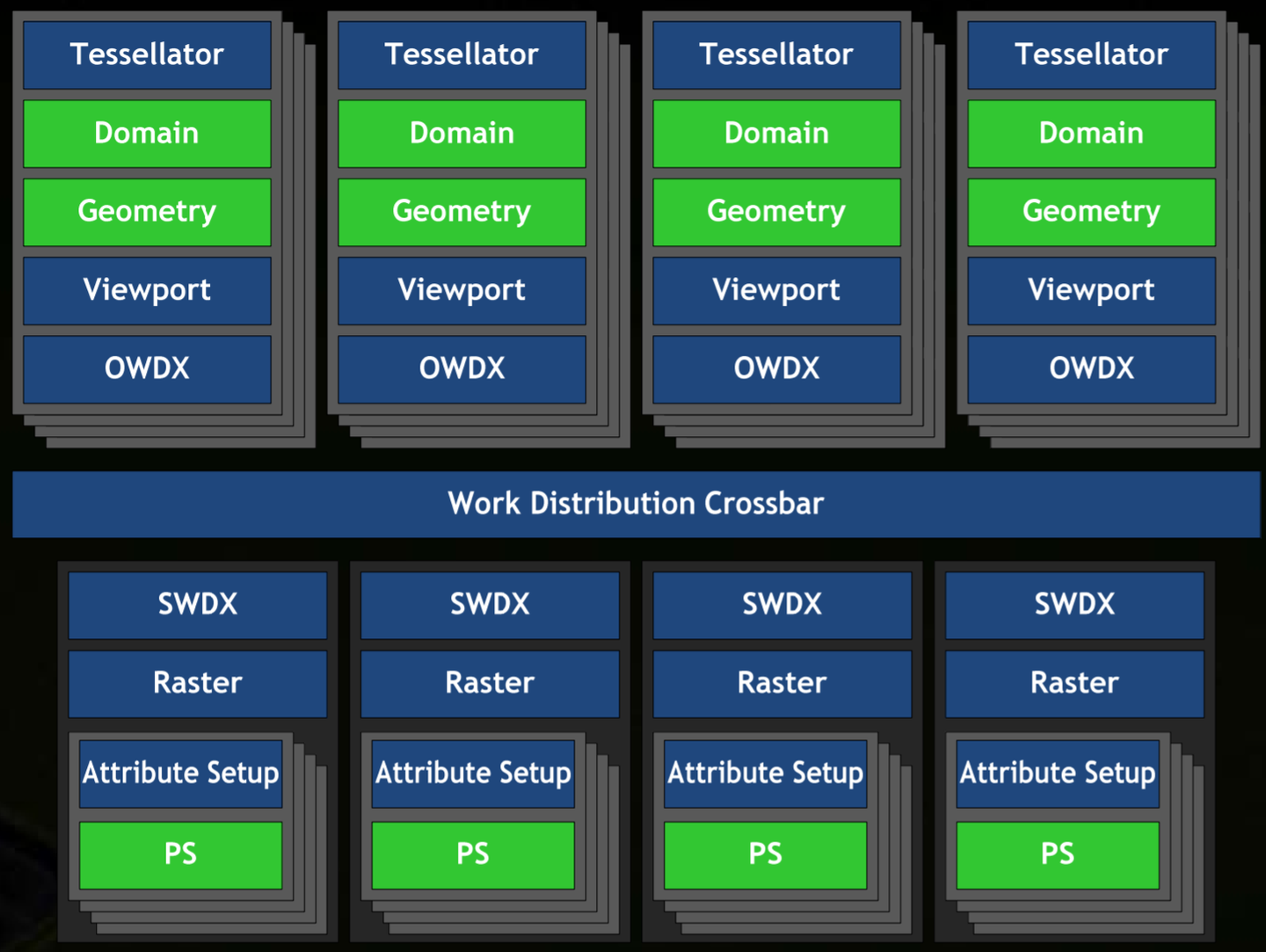
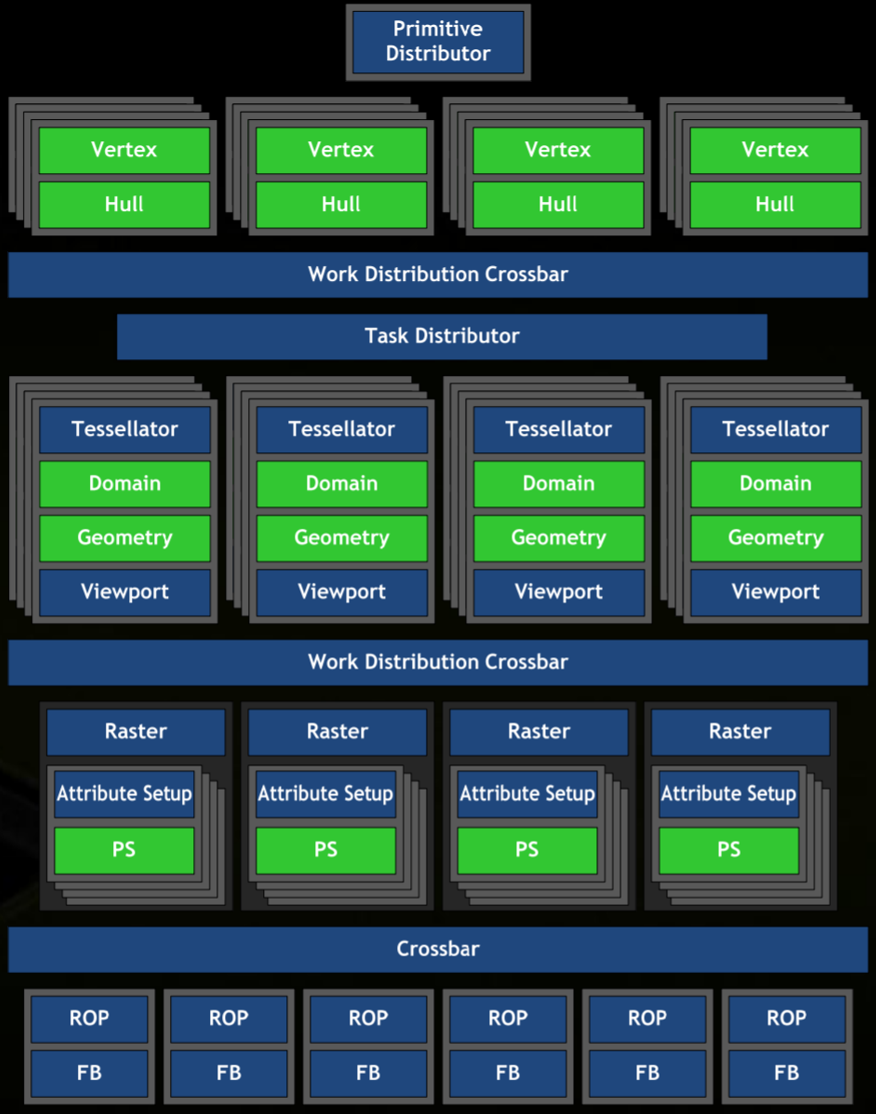
工作分配与排序 (Work Distribution Crossbar)
- 目标: 将几何阶段输出的图元分配到 GPC 内的 Raster Engine。
- OWDX (Output Work Distributor Crossbar):
- 分块 (Tiling): 将三角形的包围盒切割成小块 (tiles),并将这些小块分发到对应的 Raster Engine 进行并行处理。
- 与移动端 TBDR 不同:仅 Raster Engine 并行处理块,SM 不与特定块绑定,无专属帧缓冲,非延迟渲染。
- 块大小权衡:太大则并行性差;太小则三角形跨越多块的概率增加,导致三角形设置开销增大。
- 分块 (Tiling): 将三角形的包围盒切割成小块 (tiles),并将这些小块分发到对应的 Raster Engine 进行并行处理。
- 面剔除 (Face Culling): 根据顶点顺序和定义的正面朝向,剔除背面或正面三角形。原文推测此阶段执行最合理。
- SWDX (Sorting Work Distributor Crossbar):
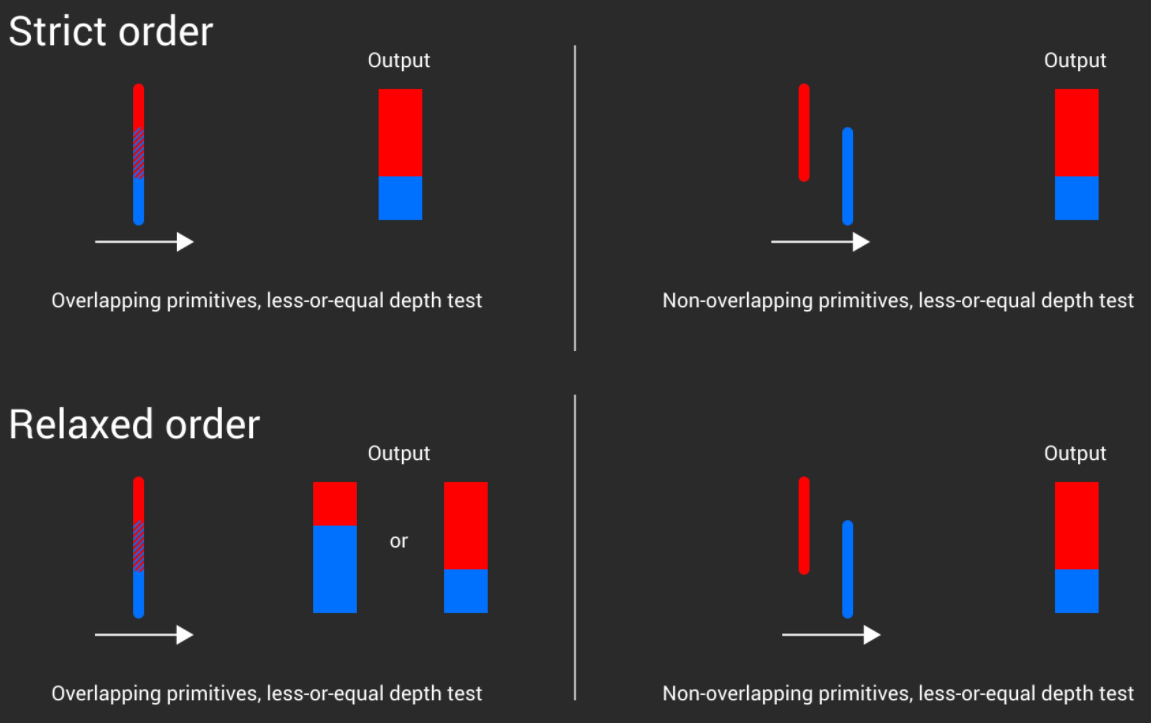
- 排序: 保证三角形按提交顺序进入 Raster Engine。
- 目的: 避免透明物体或重叠物体因处理顺序不定导致的闪烁问题。对于无重叠情况,新硬件可关闭排序以提高效率。ROP 阶段会保证输出顺序是提交顺序。
边设置 (Edge Setup / Triangle Setup Part 1)

- 位置: Raster Engine 内部。
- 功能: 为三角形的每条边生成边方程 $e(x,y) = Ax + By + C = 0$。
- 屏幕空间点 $(x,y)$ 代入方程:
- $e(x,y) = 0$: 点在边上。
- $e(x,y) > 0$: 点在边的一侧 (通常是法线指向的一侧,即三角形内部)。
- $e(x,y) < 0$: 点在边的另一侧。
- 系数计算: $A, B, C$ 由三角形顶点的屏幕空间坐标计算得出。
- 对于边 $p_0p_1$,向量为 $(p_{1x}-p_{0x}, p_{1y}-p_{0y})$。
- 旋转90度得到法线方向相关的系数:$A = -(p_{1y}-p_{0y})$, $B = (p_{1x}-p_{0x})$。
- $C = (p_{1y}-p_{0y})p_{0x} - (p_{1x}-p_{0x})p_{0y}$ (整理后)。
- 这些系数是三角形的“烙印”,用于后续像素覆盖判断。
- 屏幕空间点 $(x,y)$ 代入方程:
光栅化 (Rasterization / Triangle Traversal)
- Inside Test:
- 将屏幕像素中心的坐标代入三角形的三条边方程。若三个结果均 $>0$ (或符合预定规则),则像素被该三角形覆盖。
- 保守光栅化 (下一代架构) 有其他覆盖判断方式。
- 像素四边形 (Quads):
- 像素通常以 $2 \times 2$ 的 Quad 形式组织和处理。
- 若 Quad 中任一像素被覆盖,则整个 Quad 都可能被激活并进入片元着色阶段,以便计算像素间的差分 (导数)。
- 增量计算:
- 利用 $e(x+1,y) = e(x,y) + A$ 和 $e(x,y+1) = e(x,y) + B$ 加速计算相邻像素的边函数值。
- 边界规则 (Tie-Breaking Rule):
- 处理像素中心恰好落在边上的情况,确保共享边的像素归属于唯一三角形,避免缝隙或重复绘制。
- 例如 DirectX 的 “top-left rule”:像素归属于左边或水平上边。
- 点和线的处理: 通常被当作矩形 (两个三角形) 处理,以复用三角形光栅化流水线,简化硬件。
- 多重采样抗锯齿 (MSAA - Multi-Sample Anti-Aliasing):
- 每个像素内有多个采样点 (samples)。
- 光栅器判断哪些采样点被三角形覆盖。
- MSAA: 片元着色器通常对整个像素执行一次 (若至少一个样本被覆盖),其结果 (颜色、深度) 写入所有被覆盖的样本。代价是需要更大的帧缓冲。
- EQAA (AMD): 通过间接索引层减少帧缓冲内存。
- CSAA (NVIDIA, 后被移除): 需要光栅化的点更多 (如额外*4),用于估算覆盖权重,帧缓冲相比MSAA未扩大,每个像素增加少量覆盖信息 (如16bit)。
- 分层遍历 (Hierarchical / Tiled Traversal):
- 屏幕空间被划分为更小的 tile。
- 通过测试 tile 角点与边方程的关系,快速剔除完全不被三角形覆盖的 tile (类似加速结构)。
- Tile 按 Z 序 (或类似Morton序) 遍历,提高缓存命中率 (相邻像素可能访问相邻纹素,纹理也常按块存储)。
Z-Cull (早期 Z 剔除的优化)
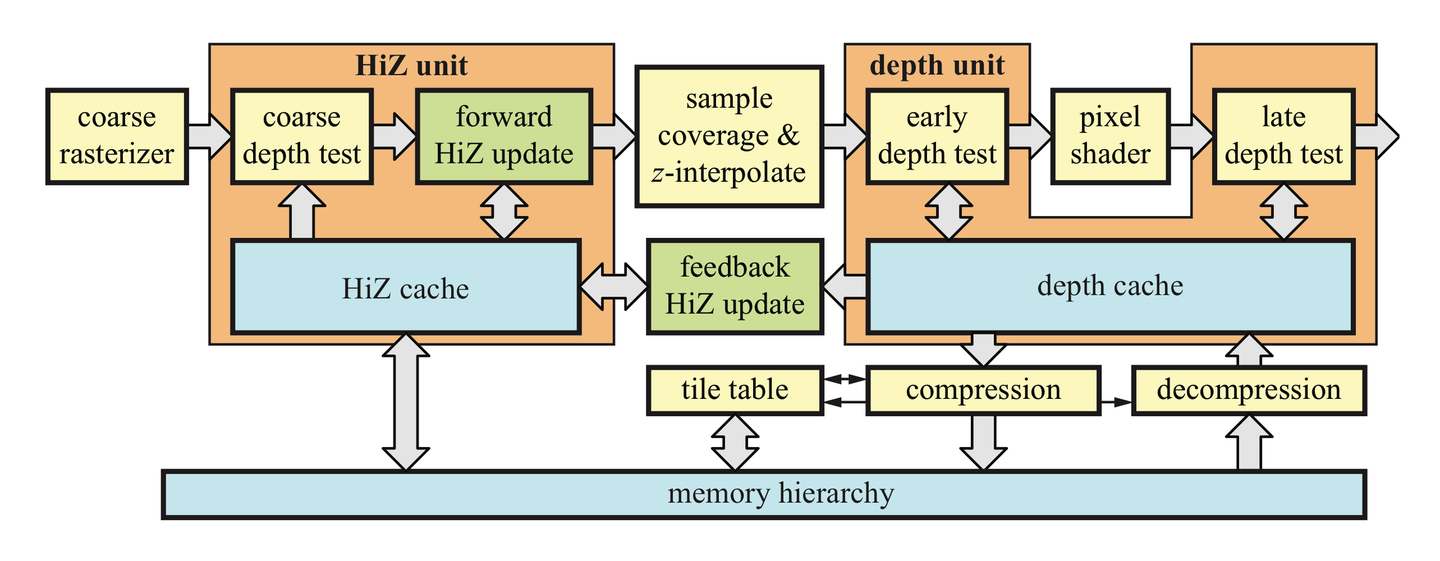
- 时机: 在精细的逐像素光栅化之前,对图块 (block/tile) 进行粗略光栅化。
- 机制:
- Z-Cull 单元维护每个屏幕块的深度缓存的最大Z值 (far Z)。
- 如果一个三角形在该块内光栅化出的像素的最小Z值 (near Z) 大于该块已存的最大Z值,则该三角形在此块中完全被遮挡,无需进行后续的逐像素光栅化和深度测试。
- 深度估算: 三角形在块内的最小Z值可以通过其三个顶点的最小Z值,或在该块四个角点处插值得到的深度值的最小值等方式保守估算。
- 作用: 节省逐像素深度测试。但本身不节省片元着色器执行 (Early-Z 才负责此)。
- Early-Z 依赖: Z-Cull 和 Early-Z 的有效性依赖于物体近似从前到后的顺序提交。移动端的 TBDR 或 PC 端的 Z-Prepass 可以不依赖排序。
- 双向 Z-Cull:
- 也可以维护块的最小Z值,若三角形最大Z值小于块最小Z,则该三角形完全遮挡已有内容,后续深度测试可简化。
- 与分层遍历区别: 分层遍历是屏幕空间2D加速,Z-Cull是深度方向(Z轴)加速,均基于块思想。
片元阶段
属性设置 (Attribute Setup / Triangle Setup Part 2)
- 位置: Polymorph Engine 内的属性设置单元。
- Fermi 架构将 Tesla 架构中统一的三角形设置拆分为 Raster Engine 中的边设置和 Polymorph Engine 中的属性设置。
- 功能: 计算将顶点属性正确插值到每个被覆盖片元 (像素/样本) 所需的参数。
- 重心坐标 (Barycentric Coordinates):
- 用于在三角形内部插值顶点属性。通常表示为 $(u,v,w)$ 且 $u+v+w=1$。
- 可由片元位置与三角形顶点形成的子三角形面积之比计算:$u = \frac{Area_1}{Area_{total}}$, $v = \frac{Area_2}{Area_{total}}$。
- 边函数值 $e_i(P)$ 正比于点 P 与对应边所形成的子三角形面积的两倍 ($e_i(P) = 2 \times Area_i$)。
- $Area_{total}$ (原三角形面积的两倍) 可通过任一顶点代入对边边函数得到。
- 理论上,属性设置单元存 $\frac{1}{Area_{total}}$,然后用 $u(x,y) = \frac{e_1(x,y)}{Area_{total}}$, $v(x,y) = \frac{e_2(x,y)}{Area_{total}}$ 计算。
- 透视校正插值 (Perspective-Correct Interpolation):
- 由于透视投影,屏幕空间直接线性插值顶点属性会导致错误。
- 方法: 对每个属性 $Attr$ 和 $1/w$ 分别进行屏幕空间线性插值,然后相除: $Attr_{pixel} = \frac{Interpolated(Attr/w)}{Interpolated(1/w)}$。
- 硬件实现: 调整重心坐标计算公式,引入每个顶点的 $w$ 值。 $f_i(x,y) = \frac{e_i(x,y)}{w_i}$ (其中 $w_i$ 是顶点 $i$ 的 $w$ 分量)。 $\tilde{u}(x,y) = \frac{f_1(x,y)}{\sum f_k(x,y)}$, $\tilde{v}(x,y) = \frac{f_2(x,y)}{\sum f_k(x,y)}$ (调整后的重心坐标)。
- 深度值例外: 经过透视除法的深度值 ($z/w$) 在屏幕空间是线性的,可以直接进行线性插值,无需特殊校正。这是因为它已是NDC空间的值。其他属性通常仍在世界或观察空间,投影到屏幕是非线性的。
片元着色器 (Fragment Shader / Pixel Shader)
- 输入: 插值后的顶点属性 (颜色、纹理坐标、法线等)。
- 执行单位: 片元 (通常与 Quad 内其他片元打包成 Warp) 在 SM 内执行。
- 功能:
- 执行程序员定义的着色代码,进行纹理采样、光照计算、雾化等操作,最终计算出片元的颜色。
- 可利用 Quad 内相邻片元信息计算导数 (e.g.,
ddx,ddy) 用于 mipmapping 等。
- 硬件调度: 遵循 Warp 调度机制。
ROP (Render Output Unit / Raster Operations Pipeline)

- 位置: 通常分布在 GPC 外部,靠近 L2 Cache。
- 分块管理: 每个 ROP 单元负责屏幕像素的特定区域 (块/tile),仅需在此块内维持三角形顺序。
- 主要功能 (后处理操作):
- 深度测试 (Late Depth Test): 在片元着色后,比较片元深度与深度缓冲区的值。
- 模板测试 (Stencil Test): 根据模板缓冲区的值和测试条件决定片元是否通过。
- 混合 (Blending): 将新片元颜色与帧缓冲中已有的颜色根据混合因子进行混合。
- MSAA Resolve (多重采样解析): 如果开启了 MSAA,将一个像素内多个样本的颜色值合并成最终的单一像素颜色。
- 这是渲染管线上,数据在写入帧缓冲前的最后阶段。
Fermi 架构总结与 GPU 架构特性展望
本文档总结了NVIDIA Fermi架构的关键改进及其在GPU发展中的地位,并探讨了GPU架构的一些通用特性。
Fermi 架构的关键改进
Fermi 架构在Tesla架构的基础上引入了多项重要改进,旨在提升并行计算能力和灵活性,使其不仅是图形处理器,也为更广泛的并行计算应用奠定基础。
增强对多样化并行算法的支持
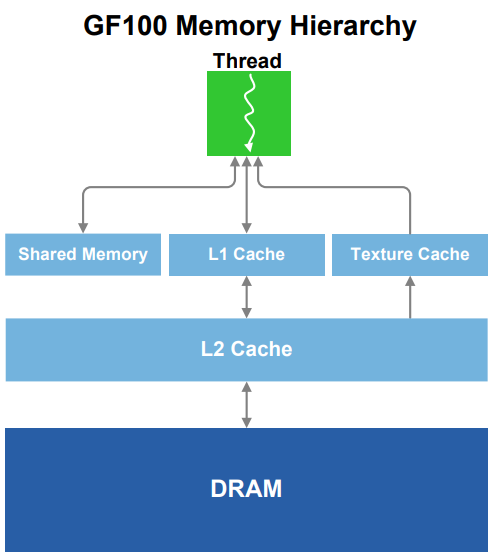
- L1 Cache 与共享内存 (Shared Memory):
- 背景: Tesla架构的共享内存利于程序员预先设计内存访问模式的算法(如矩阵乘法)。但对于内存局部性在运行时才体现的算法(如光线追踪、物理模拟、AI),共享内存效果有限。
- Fermi改进: 引入了L1 Cache,与共享内存共用一块硬件单元,大小可由程序员手动配置。这使得需要随机内存访问的算法也能自动利用内存局部性优势。
- L2 Cache 的通用化与扩展:
- Fermi改进: 大幅增加了L2 Cache的容量,并使其对所有类型的数据开放(不再仅为纹理专用)。
- 意义: 表明GPU开始从纯粹的图形处理向通用并行计算领域转型,为后续AI等领域的发展埋下伏笔。
更灵活的 Warp 调度机制
- 背景: Tesla架构主要针对一次执行一个大型内核、上下文切换较慢的场景。游戏等应用常涉及多种小型内核的执行(如布料、流体、刚体模拟)。
- Fermi改进: 引入双调度机制 (Dual Warp Scheduler)。
- 效果: 允许更多不同类型的内核在同一个SM中并行执行,并能进行快速切换,从而最大限度利用 CUDA核心,有效隐藏指令延迟。
更快速的上下文切换
- 重要性: 在游戏应用中,上下文切换(如在不同API或计算任务间切换)每帧都可能发生,其速度至关重要。
- Fermi改进: 将上下文切换时间缩短至约 20 微秒。
- 设想应用: 允许在一帧内进行细粒度的内核切换,例如在 DirectX 11 渲染、CUDA 光线追踪、DirectCompute 后处理和 PhysX 物理模拟之间切换。
硬件与算法的演进关系
GPU硬件与图形/计算算法之间存在相互促进、协同发展的关系:
- 算法驱动: 算法在现有硬件上实现,逐渐暴露出硬件的瓶颈。
- 硬件革新: 硬件架构针对这些瓶颈进行修改和优化,拓宽边界。
- 专用硬件: 当某一类算法显示出巨大潜力或成为刚需时,硬件可能集成专用单元来加速该算法。
- 新机遇: 新的硬件架构和单元为新算法的出现和发展提供了舞台。
示例:光线追踪 (Ray Tracing)
- 早期挑战: 光线追踪技术历史悠久,但在GPU上高效实时运行困难,因其光线弹射方向不可预测且具有递归性,需要大量随机内存访问。
- Fermi的贡献:
- 硬件递归支持: Fermi架构首次在硬件层面支持了递归调用,为高效实现光线追踪及其他依赖递归的图形算法提供了可能。
- Cache优化: L1 Cache 增强了相邻光线间的内存局部性;L2 Cache 的改进(扩大帧缓存带宽,更准确地说是提升了对各类数据,包括渲染目标和追踪结构数据的访问效率)。
GPU 架构的通用特性
并行性 (Parallelism)
- 核心驱动: 通过不断增加和特化计算单元来解决特定瓶颈,提升GPU整体及特定任务的并行处理能力。
- 演进示例:
- Tesla架构: 大量CUDA核心,统一顶点与片元着色器,奠定基础并行处理能力。
- Fermi架构: 引入多个Polymorph引擎和Raster引擎,大幅提升几何阶段的并行处理能力。
- Turing架构: 独立的INT32和FP32处理单元,加入RT Core (光线追踪核心) 和Tensor Core (张量核心),实现更多特定领域的并行加速。
- 趋势: 未来将有更多针对特定需求的计算单元被集成到GPU中。
继承性 (Inheritance)
- 演化而非革命: GPU架构的设计是基于前代架构的迭代演进。
- 示例: Fermi架构虽然有重大改动,但其整体框架(如SM和Warp调度机制)仍能看到Tesla架构的影子。
- 核心灵魂: 即使是Turing这类重大革新的架构,其核心调度机制等设计思想也一脉相承自早期架构(如Tesla)。
扩展性 (Scalability)
- 横向扩展 (产品线):
- 通过调整GPC (Graphics Processing Cluster) 和SM (Streaming Multiprocessor) 的数量,可以快速设计出同一架构下不同性能和定位的产品,满足不同市场需求。
- 纵向扩展 (代际发展):
- 随着芯片制程的进步,可在GPU内集成更多晶体管。现有硬件单元可以“超级加倍”,并根据负载调整比例。
- 当出现新的技术需求时,可在上一代架构基础上,向SM中添加新的计算单元,而无需完全重新设计。
时代性 (Timeliness)
- 与时代同步: GPU架构的推出紧密跟随并推动着时代技术的发展。
- 双重角色:
- 技术助推者: 针对有前景的技术调整架构或推出专用硬件单元进行加速。
- 创新孵化器: 新架构引入的特性往往具有探索空间,能激发围绕新特性的技术探索和创新浪潮。
Kepler 架构摘要: 以低功耗为核心设计目标
主题转变:从追求高性能转向追求高能效(Perf/Watt),代表 GPU 发展进入“高质量发展阶段”。
核心变化概览
-
工艺制程:从 Fermi 的 40nm → Kepler 的 28nm(提升集成度)
-
SM(Streaming Multiprocessor)重构:
- Fermi:每个 GPC 包含多个 SM
- Kepler:每个 GPC 只有两个 SMX,但每个 SMX 的 CUDA 核心数是 Fermi 的 6 倍
-
设计哲学:增加并行单元数量而非提高频率,从而降低能耗
SMX 内部优化详解
CUDA Core / SFU
- 不再使用 2 倍图形时钟频率,统一采用 1 倍图形时钟以节能
- 用“人海战术”替代高频精英核:更多核心、低频运行 → 延迟隐藏更容易、功耗更低
LD/ST & Texture Units
- LD/ST(读写单元)数量未显著增加,但受益于内存读写速度提升 1.5 倍
- 纹理单元数量同步增长,为无绑定纹理支持打基础
Warp Scheduler
- 每个 SMX 有 4 个调度器,每个时钟周期可发射两条指令
- 调度逻辑简化:Kepler 记录指令延迟,不再动态解析依赖,硬件复杂度和功耗大幅降低
Polymorph Engine 2
- 每个 SMX 仍只配一个,但性能提升至前代的 2 倍,以支撑更大 SMX
内存与缓存优化
内存子系统
- 内存控制器数量:6(Fermi)→ 4(Kepler)
- 每控制器连接:128KB L2 Cache + 8 ROP
- 带宽持平(速度提升补偿结构缩水)
- 原子操作性能显著增强
带宽提升
- 内部总线改进 + GDDR5 推到 6 Gbps 极限
- 支持更多纹理访问能力,配合新特性
无绑定纹理(Bindless Textures)
- 传统绑定表最大支持 128 个纹理插槽
- Kepler 首次硬件支持无绑定纹理(提前于现代API)
- GPU 可直接访问纹理资源,CPU 开销下降
- 纹理资源管理更加灵活、高效
GPU Boost 技术: 热功耗墙下的智能超频
- 每代 GPU 都有 TDP(功耗上限)约束
- 传统频率设置按最恶劣情况测试设定
- Boost:如果未达到 TDP,则可动态提升图形时钟频率
- 用户可设置功率目标,散热能力越好 → 实际性能越高
- 散热 = 潜在性能
总结: Kepler 架构设计理念
- 没有引入全新硬件,但所有模块都围绕降低功耗优化
- 典型的“守成一代”:在前代创新基础上精细打磨
- 显示了 GPU 架构的设计趋势:
- 极致并行 + 功耗控制
- 平衡性能与能耗
- 预示移动端/嵌入式/能效优先场景将成为下阶段重心
Maxwell 架构摘要: 为新算法与图形特性保驾护航
架构核心目标
- 相比 Kepler,更强调硬件资源分配的效率与适配实际应用场景。
- 主要围绕图形算法(如体素化)进行架构级优化。
- 注重节能、提升单位面积性能,以及针对实时全局光照和复杂场景的硬件支持。
架构调整与资源分配
纹理单元和 ROPs
- 每个 SM 配置 8 个纹理单元,数量与 Kepler 相同,但频率提升带来 12% 填充率增长。
- ROP(像素输出单元)数量翻倍:32 → 64,配合频率提升使像素填充率提升 2 倍以上。
SMM(Streaming Multiprocessor Maxwell)
- 从 SMX(192 CUDA 核)转变为 SMM(128 CUDA 核),资源被划分为 4 个独立组,对应 4 个 Warp 调度器。
- 每组资源独立调度、缓冲,调度效率更高,面积更小。
- 每个 GPC 的 SM 数量翻倍(2 → 4),整体 CUDA 数量仍提升。
资源结构变化
- L1 Cache 与纹理缓存合并
- Polymorph Engine 升级到 3.0,在细分高密度场景下性能提升最高达 3 倍。
面向体素化渲染的硬件支持
背景: 体素全局光(VXGI)
- 将光照信息存入体素中,作为间接光源用于 Cone Tracing。
- 对体素的写入(体素化)和查询均需实时高效支持。
针对体素化的三项关键硬件支持
-
Viewport Multicast(视口多播)
- 自动将几何体广播到多个渲染目标,避免重复提交和几何阶段重复计算。
- 典型应用:三方向投影(体素化)、Cube Map、CSM 等。
-
保守光栅化(Conservative Rasterization)
- 确保三角形触碰像素即算覆盖,避免孔隙。
- 由硬件实现,无需软件模拟扩展。
-
稀疏纹理(Sparse Texture / Tiled Resources)
- 支持纹理按需分配,极大节省体素化中的内存占用。
其他图形相关特性
-
Raster Ordered Views(ROVs) 支持多 Draw Call 下的顺序一致性写入,关键于透明排序(如 OIT)。
-
Multi-Pixel Programmable Sampling 采样点位置可编程,配合 MFAA(多帧采样反走样)提升抗锯齿效果,低成本模拟更高 MSAA。
-
Dynamic Super Resolution(DSR) 驱动级高分渲染 + 高斯滤波降采样,在低分屏上提升画质。
内存压缩机制优化
多层压缩策略
-
块压缩
- 4×2 区域恒定:8:1 压缩
- 2×2 区域恒定:4:1 压缩
-
增量颜色压缩(Delta Color Compression)
- 使用像素间差值进行编码。
- Maxwell 提供第三代 delta 压缩,通过多个基准点选择提高压缩效率。
NVENC 视频编码器升级
-
H.264 吞吐量提升 4 倍
-
新增支持 H.265 / HEVC
- 相同画质下带宽节省显著
-
为云游戏、视频推流等提供编码能力基础
- 在客户端侧,视频编解码器成为关键性能瓶颈
总结
- Maxwell 不再单纯堆砌硬件,而是通过架构精细化、特性定向优化支持更复杂场景与算法(如 VXGI)。
- 通过多播渲染、保守光栅化、稀疏纹理等新特性,显卡首次以硬件方式为高阶图形算法“保驾护航”。
- 兼顾能效、可编程性和渲染带宽,奠定后续架构的演化方向。
Pascal 架构摘要
核心硬件升级
与上一代Maxwell架构相比,Pascal架构在硬件层面有显著提升。
- 制造工艺: 16nm FinFET
- 核心频率: 显著提升 (以GTX 1080为例: 1607 MHz / 1733 MHz)
- 硬件单元变化:
- GPC (Graphics Processing Cluster): GeForce GTX 1080 仍包含4个GPC,但每个GPC内的SM(Streaming MultiProcessor)数量增加。
- SM (Streaming MultiProcessor): 命名从Maxwell的SMM改回SM,但内部元器件配比无重大变化。
- TPC (Texture Processing Cluster):
Polymorph Engine从SM中被独立出来,与SM共同组成TPC。 - Polymorph Engine升级: 内部的
Viewport Transform模块被升级为功能更强大的SMP (Simultaneous Multi-Projection)单元。
Simultaneous Multi-Projection (SMP) 引擎
SMP是Pascal架构的核心升级之一,旨在通过一次几何管线处理,将渲染结果输出到多个不同的投影视口,实现了几何处理与投影计算的解耦。
-
核心功能:
- 支持最多 16个 预设的独立视口(Viewport)。
- 支持 2个 不同的投影中心(Projection Center)。
- 允许对每个视口进行独立地倾斜、旋转,以及沿X轴平移投影中心。
-
主要应用场景 (针对VR):
- Single Pass Stereo (SPS) / 单通道立体渲染
- Lens Matched Shading (LMS) / 晶状体匹配着色
Single Pass Stereo (SPS)
- 目标: 在一个渲染通道(Pass)内同时为VR的左右眼生成图像,避免对同一场景进行两次完整的几何渲染。
- 实现方式: 利用SMP平移投影中心的特性,在一次绘制中,通过移动裁剪坐标的x分量,为左右眼生成具有视差的独立视图。
Lens Matched Shading (LMS)
- 背景: VR透镜会产生“桶形畸变”,因此渲染时需要预先生成“反向桶形畸变”的图像来抵消。传统方法是渲染一张远大于最终显示像素的完整图像再进行重采样,造成边缘区域大量像素被浪费(过采样)。
- 目标: 提高渲染效率,避免对最终会被压缩或丢弃的边缘像素进行全分辨率着色。
- 实现方案:
- 中策 (Multi-Resolution Shading): 将屏幕划分为多个区域(如九宫格),对中心区域使用高分辨率渲染,对边缘区域使用低分辨率渲染。实现简单但效率优化较为粗糙。
- 上策 (Pascal方案): 利用SMP将屏幕划分为4个视口,并通过调整 W分量 来实现从中心到边缘的像素密度线性降低。
- 原理: 通过给每个视口设定不同的缩放参数A和B,修改顶点的W值: $$w' = w + Ax + By$$
- 效果: 在透视除法后,边缘区域的像素会自然地向中心汇聚,从而在渲染时就匹配了最终畸变图像的采样率分布,大幅提升性能。
Vulkan API 扩展支持
- SPS: 通过
VkRenderPassMultiviewCreateInfoKHR扩展实现,将左右眼图像渲染到帧缓冲附件(Framebuffer Attachment)的不同层(Layer)。 - LMS: 通过
VK_NV_clip_space_w_scaling扩展实现,将帧缓冲附件的同一层划分为多个视口,并对不同视口应用不同的W缩放。 - 组合使用: 这两种技术是正交的,可以同时启用以达到最佳VR渲染性能。
带宽与压缩技术
为满足VR所需的高分辨率和高刷新率,Pascal在显存带宽和数据压缩方面进行了增强。
- 显存: 首次采用 GDDR5X,数据传输速率从Maxwell的7Gbps提升至 10Gbps。
- Delta颜色压缩: 在Maxwell的基础上进一步增强。
- 2:1 压缩: 增强算法,提升压缩成功率。
- 4:1 压缩: 新增的Delta颜色压缩模式。
- 8:1 压缩: 组合压缩模式。当一个2x2的像素块成功实现4:1压缩时,会尝试对这四个压缩后的块再次进行2:1压缩,适用于颜色单一的大面积区域。
异步计算与抢占
Pascal提升了GPU处理图形与计算混合负载的效率。
动态负载均衡 (Dynamic Load Balancing)
- 对比Maxwell: Maxwell使用静态分区来划分图形和计算任务,当负载不均衡时会导致部分GPU资源闲置。
- Pascal改进: 引入动态负载均衡,允许图形和计算任务根据实际需求动态共享GPU资源,避免资源空闲,提升整体吞吐量。
任务抢占 (Preemption)
Pascal实现了更细粒度的任务抢占,以支持对延迟敏感的任务,如VR中的 ATW (Asynchronous Timewarp)。
- Pixel Level Preemption (像素级抢占):
- 图形任务可以在像素级别被中断。
- GPU保存当前渲染进度,切换到高优先级任务,任务切换耗时可在 100微秒 以内完成。
- Thread Level Preemption (线程级抢占):
- 计算任务(CUDA)可以在线程块(Thread Block)级别被中断。
- 当前SM上运行的线程完成后,Grid中的其余线程被挂起,进行任务切换,耗时同样在 100微秒 以内。
- Instruction Level Preemption (指令级抢占):
- CUDA任务中实现的更精细粒度的抢占,速度更快,但需要保存更多上下文状态(如寄存器数据)。
显示同步技术 (Fast Sync)
为解决传统V-Sync(垂直同步)带来的输入延迟问题,Pascal引入了Fast Sync。
- 问题回顾:
- 无同步: 画面撕裂。
- V-Sync (FIFO): 消除撕裂,但当渲染速度快于刷新率时,GPU会强制等待,导致延迟。
- Fast Sync (Mailbox):
- 原理: 采用“三缓冲”机制(前缓冲、后缓冲、最新渲染缓冲)。
- 流程:
- 前缓冲(Front Buffer)负责向显示器输出图像。
- 后缓冲(Back Buffer)存放一帧已完成渲染、等待显示的图像。
- 最新渲染缓冲(Last Rendered Buffer)供GPU无限制地渲染最新帧。
- 优势: GPU无需等待显示器,可以全速渲染,从而显著降低输入延迟,同时通过保留一个完整的后缓冲来避免画面撕裂。
- Vulkan呈现模式对应:
- 无同步:
VK_PRESENT_MODE_IMMEDIATE_KHR - V-Sync:
VK_PRESENT_MODE_FIFO_KHR - Fast Sync:
VK_PRESENT_MODE_MAILBOX_KHR
- 无同步:
多GPU技术
- SLI: 针对游戏玩家,通过连接器桥接多个GPU协同工作。
- DirectX 12模式:
- LDA (Linked Display Adapter): 链接多个GPU的显存,形成统一内存池,适用于同型号GPU。
- MDA (Multi Display Adapter): 每个GPU内存独立,适用性更广(如集显+独显),但需要开发者手动管理跨GPU通信。
- NVLink: 面向高性能计算(HPC)和AI领域,提供远高于PCIe总线带宽的GPU间互联技术,可将多达8个GPU紧密连接成一个计算节点。
Turing 架构: Mesh Shader
核心思想: 革新传统几何渲染管线
Mesh Shader 是对传统光栅化渲染管线的一次重大革新,其目标是取代传统的几何管线(顶点着色器 Vertex Shader、细分着色器 Tessellation Shader、几何着色器 Geometry Shader)。
- 并非取代光栅化:Mesh Shader 优化和革新的是光栅化管线中的几何处理阶段,而非要用光追管线取代光栅化。
- 演进方向:硬件厂商预见,未来将是光追与光栅化两条管线并存并进的局面。而 Mesh Shader 标志着对光栅化管线自身潜力的深度挖掘。
传统管线的瓶颈与挑战
渲染大规模、高细节的场景(如元宇宙愿景)时,传统几何管线面临以下核心瓶颈:
永无止境的几何数据
- 无限细节 (Infinite Detail):现实世界物体细节丰富,在数字世界中表达需要海量的模型数据,给存储、内存、显卡都带来巨大压力。
- 无限场景 (Infinite Scene):开放世界等应用需要超远视距,海量物体的剔除(Culling)和细节层次(LOD)切换至关重要。
传统几何管线的固有缺陷
- 几何着色器 (Geometry Shader):设计过于灵活(一个线程可输出任意数量图元),导致硬件实现困难,性能长期不佳。
- 细分着色器 (Tessellation Shader):设计相对保守,由硬件 Tessellator 产生固定模式的顶点,虽然高效但牺牲了灵活性。其线程与顶点的固定映射关系,限制了其应用场景。
真正的性能瓶颈: 图元分发器 (Primitive Distributor, PD)
PD 是一个固定功能的硬件单元,负责将顶点数据拆分为 GPU Warp 可以处理的块(Batch)。其工作方式虽然巧妙,但存在两大“原罪”:
- 不必要的重复工作:对于静态模型,每一帧都需要通过 PD 进行完全相同的拆分和组织工作。当追求海量数据时,这种重复的固定开销成为瓶颈。
- 顶点复用率限制:
- PD 输出的每个 Batch 的顶点数和图元数有上限(例如,顶点上限32个)。
- 当一个三角形的顶点被频繁复用时(顶点复用率 > 3),图元数量会先于顶点数量达到 Batch 上限。
- 这导致 Batch 中顶点空间未被填满,后续处理该 Batch 的 Warp 无法满载,造成计算资源浪费。
硬件支持前的探索: 基于 GPU 的渲染 (GPU-Driven Rendering)
在 Mesh Shader 出现前,顶尖游戏厂商为解决上述瓶颈,采用了一种基于计算着色器 (Compute Shader) 的“曲线救国”方案。
核心流程
-
预生成 Meshlet:
- 将模型数据在预处理阶段拆分成自定义的、更小的数据块,称为 Meshlet。
- Meshlet 内部使用“顶点索引的索引”,即局部索引,大大减小了索引数据大小。
- 好处: a. 数据量变小;b. 剔除粒度从整个模型缩小到小块 Meshlet。
-
用计算着色器进行剔除与处理:
- 启动一个 Compute Shader。
- 在 Shader 内部加载 Meshlet,进行视锥剔除、遮挡剔除等。
- 如果 Meshlet 未被剔除,则在 Shader 内进行顶点变换,并将存活的三角形索引写入一个新的索引 Buffer。
- 最后,CPU/GPU 发起一个间接绘制指令 (Draw Indirect),让 GPU 使用这个新生成的 Buffer 走一遍完整的传统几何管线。
该方案的优劣分析
- 优势: 在剔除率高的情况下,能节省大量被剔除几何体的固定管线开销(如PD、顶点属性获取),性能提升显著。
- 劣势:
- 高昂的固定开销: 如果剔除率不高,Compute Shader 本身的启动、寄存器占用和数据读写开销会得不偿失。
- 资源浪费: 即使整个 Meshlet 将被剔除,也必须为其分配完整的寄存器资源。
- 数据往返开销: 数据流为
Buffer -> CS 读取 -> CS 写回新 Buffer -> VS 再读取,这种数据来回读写本身就是性能浪费。 - 根本问题未解决: 该方案最终仍需将数据送回传统管线,PD 的两大原罪(重复工作和顶点复用率瓶颈)依然存在。Meshlet 预组织的好意被浪费了。
硬件解决方案: Mesh Shader 与 Task Shader
Mesh Shader 是对上述 GPU-Driven 思想的硬件化、优雅实现。
Mesh Shader: 一步到位
Mesh Shader 是一个直接联通光栅化器的、统一的着色器阶段。
- 替代关系: 它一个Shader就取代了
Vertex Shader+Tessellation Shader+Geometry Shader+Primitive Distributor。 - 编程模型:
- 与计算着色器类似,是协作式编程模型。一个线程组(Workgroup)共同协作,输出一整个 Meshlet 的数据。
- 程序员可以自由决定线程组内每个线程的工作,而不是像传统顶点着色器那样“一个线程处理一个顶点”。
- 核心输出:
- 顶点数据数组 (
gl_MeshVerticesNV[]):包含裁剪空间位置等顶点属性。 - 图元索引数组 (
gl_PrimitiveIndicesNV[]):局部索引,索引到上面输出的顶点数组,通常只需8位。 - 图元数量 (
gl_PrimitivesCountNV)。
- 顶点数据数组 (
本质区别:传统管线是“一个线程输出一个顶点/图元”,而 Mesh Shader 是“一个线程组输出一个 Meshlet 的所有数据”,自由度和效率更高。
Task Shader: 更高效的调度器
Task Shader 是在 Mesh Shader 之前执行的一个可选阶段,其作用是调度和启动 Mesh Shader 线程组。
- 解决的核心痛点: 避免了 GPU-Driven 方案中“无论是否剔除都要启动完整计算任务”的资源浪费。
- 核心功能:
- 高效剔除: Task Shader 可以先对一个 Meshlet 的包围体等信息进行剔除判断。如果被剔除,就根本不会启动对应的 Mesh Shader 线程组,从源头节省了资源。
- LOD 选择: Task Shader 可以根据距离等因素,决定使用哪个 LOD 级别的 Meshlet,并启动相应数量和配置的 Mesh Shader 任务。
- 几何体放大 (Amplification): 可以实现比传统 Tessellation/Geometry Shader 更自由的顶点/图元增删、细分和变形,因为它能动态决定要启动多少 Mesh Shader 工作。
类比: Task Shader 就像是 GPU 内置的、更高级的
Dispatch指令,让 GPU 渲染摆脱了对 CPU 的依赖,实现了更深层次的自我驱动。
未来展望: 超越 Mesh 渲染
Mesh Shader 管线的潜力不止于渲染传统的三角形网格(Mesh)。
- 作为通用计算:
- 可以关闭光栅化阶段,不输出用于渲染的 Meshlet 数据。
- 此时,Task Shader + Mesh Shader 的组合本质上就是一个强大的两级计算着色器。
- 优于传统计算着色器:
- 可以轻松实现计算树算法(一个 Task Shader 任务分发多个 Mesh Shader 任务)。
- 而使用传统计算着色器实现类似逻辑,则需要依赖
DispatchIndirect和管理参数 Buffer,过程更繁琐。
这套新管线为开发者提供了极高的自由度,有望在未来催生出更多创新的渲染和计算技术。
移动端与桌面端GPU架构核心差异解析
核心架构对比: IMR vs TBR
两种架构的根本区别在于对渲染流程和带宽资源的不同处理方式。
桌面端GPU: 即时模式渲染器 (Immediate Mode Renderers, IMR)
- 渲染流程:数据处理流水线非常直接,与图形API的逻辑管线高度一致。
- 顶点数据进入着色器核心(SM)进行顶点运算。
- 运算结果直接送入光栅化硬件。
- 光栅化后的片元再次进入着色器核心进行片元着色。
- 最终颜色值写入帧缓冲。
- 核心特点:追求极致速度,依赖海量专用带宽来保证数据流畅传输。整个过程中的中间数据(如深度、颜色信息)会频繁读写显存。
移动端GPU: 基于块的渲染 (Tile-Based Rendering, TBR)
- 设计哲学:由于移动设备在功耗、芯片面积、散热上存在严格限制,无法承受高带宽带来的高能耗,因此其架构设计的核心目标是最大限度地节省带宽消耗。
- 主流厂商:目前主流的移动端GPU(如 PowerVR、高通 Adreno、ARM Mali)均采用TBR架构。
- 核心特点:渲染管线被拆分,通过“延迟”执行的方式,将大量数据读写操作限制在GPU内部的高速缓存(On-Chip Cache)中,极大地减少了对主内存的访问。
TBR架构两大核心技术: 两次“延迟”
TBR通过在渲染管线的两个关键节点引入延迟,换取巨大的带宽收益。
第一次延迟: 分块 (Binning / Tiling)
这是在顶点处理之后、光栅化之前进行的一次延迟操作。
目标:将屏幕画面划分为若干个小块(Tile),并将所有图元(三角形)根据其覆盖的屏幕位置,分配到对应的块中。
主要流程:
- 顶点着色:GPU执行完顶点着色器,并将变换后的顶点数据临时存储在片内缓存。
- 分块 (Binning):专用的硬件单元(Tiling Engine)分析每个图元,确定它属于哪个或哪些Tile。
- 生成图元列表:为每个Tile创建一个图元列表(
per-tile list),记录该Tile需要渲染的所有图元信息。- PowerVR称之为
Primitive List - Adreno称之为
Visibility Stream
- PowerVR称之为
- 写入主存:将所有Tile的图元列表以及相关的着色器状态、属性等数据,打包写入主内存的一个特定区域(
Parameter Buffer)。
收益:
- 虽然此过程额外增加了一次主内存的读写,但它实现了后续渲染的基础。
- 通过分块,GPU可以将每个Tile所需的所有渲染目标(颜色缓冲、深度缓冲)完全加载到片内高速缓存中进行处理。
- 所有中间的读写操作(如深度测试、颜色混合)都在高速缓存内完成,只有当一个Tile完全渲染结束后,最终的颜色结果才会被一次性写回主存。这相较于IMR频繁读写主存的方式,极大地节省了带宽。
(a) TBR架构将读写操作限制在片内缓存;(b) IMR架构频繁读写主存
第二次延迟: 延迟片元着色 (Hidden Surface Removal, HSR)
这是在光栅化之后、片元着色之前进行的第二次延迟操作。
目标:在像素级别上消除过绘制 (Overdraw),确保计算资源只用于渲染最终在屏幕上可见的片元。
主要流程:
- GPU处理一个Tile内的所有图元,将它们光栅化成片元。
- 对所有生成的片元执行深度测试。
- 等待该Tile内所有图元的深度测试全部完成后,GPU才只对通过深度测试且离镜头最近的片元执行片元着色器。
各厂商技术名称:
- PowerVR: Hidden Surface Removal
- 高通 Adreno: Early Z Rejection
- ARM Mali: Forward Pixel Killing
与桌面端Early-Z的区别:
- TBR的此项技术无需对物体进行从前到后的排序,并且能比桌面端常见的Early-Z更精确地消除因物体交叉等复杂情况导致的Overdraw。
影响该技术的特殊情况:
- 半透明物体 (Transparency):会中断HSR。GPU会先渲染完当前所有不透明物体,然后渲染半透明物体并进行混合。优化建议是将半透明物体放在渲染队列的最后。
- Alpha Test / Discard:使用
discard的物体会被先当作不透明物体处理。如果它通过了深度测试,则会执行片元着色器。若最终被discard,硬件会回过头去更新HSR信息,让被它遮挡的像素得以渲染。
其他关键优化技术
除了TBR架构,移动端GPU还采用多种技术来节省带宽和功耗。
- MSAA优化:多重采样抗锯齿(MSAA)所需的多样本数据也存储在片内高速缓存中,在片内完成混合(Resolve)后,再将最终结果写回主存。
- 流水线并行:在当前帧进行片元着色的同时,可以并行处理下一帧的顶点着色和分块(Binning)工作,提高效率。
- 顶点着色器拆分:可将顶点着色器拆分为“位置计算”和“其他属性计算”两部分。先计算出位置用于分块,进一步优化流水线。
- 脏区检测 (Dirty Tile Detection):通过比较前后帧,对于画面没有变化的Tile,直接复用上一帧的结果,不进行重新计算和写回。这对于UI界面或静态场景较多的游戏非常有效。
- 硬件细节优化:
- 在缓存中也保持纹理的压缩格式,在使用时才解压。
- 让暂时没有任务的硬件单元进入休眠状态以降低功耗。
未来趋势: 光线追踪与架构融合
- 硬件级光线追踪:移动端GPU已开始布局光追。
- Imagination Technologies早在2016年就展示了
PowerVR GR6500光追测试板。 - 三星与AMD合作,在其
Exynos 2200GPU中集成了基于RDNA 2架构的硬件光追功能。
- Imagination Technologies早在2016年就展示了
- 架构融合与性能飞跃:
- 苹果自研的M1系列芯片,其GPU基于移动端高效的架构设计,但在性能上实现了巨大突破,并成功应用于桌面和笔记本电脑。
- 这证明了移动端GPU架构在性能上同样具备巨大潜力。
- 未来,移动端和桌面端的GPU架构将继续互相借鉴与融合,成为GPU设计的主要趋势。