Unity 渲染底层架构与管线原理笔记
渲染架构分层模型 (Layered Architecture)
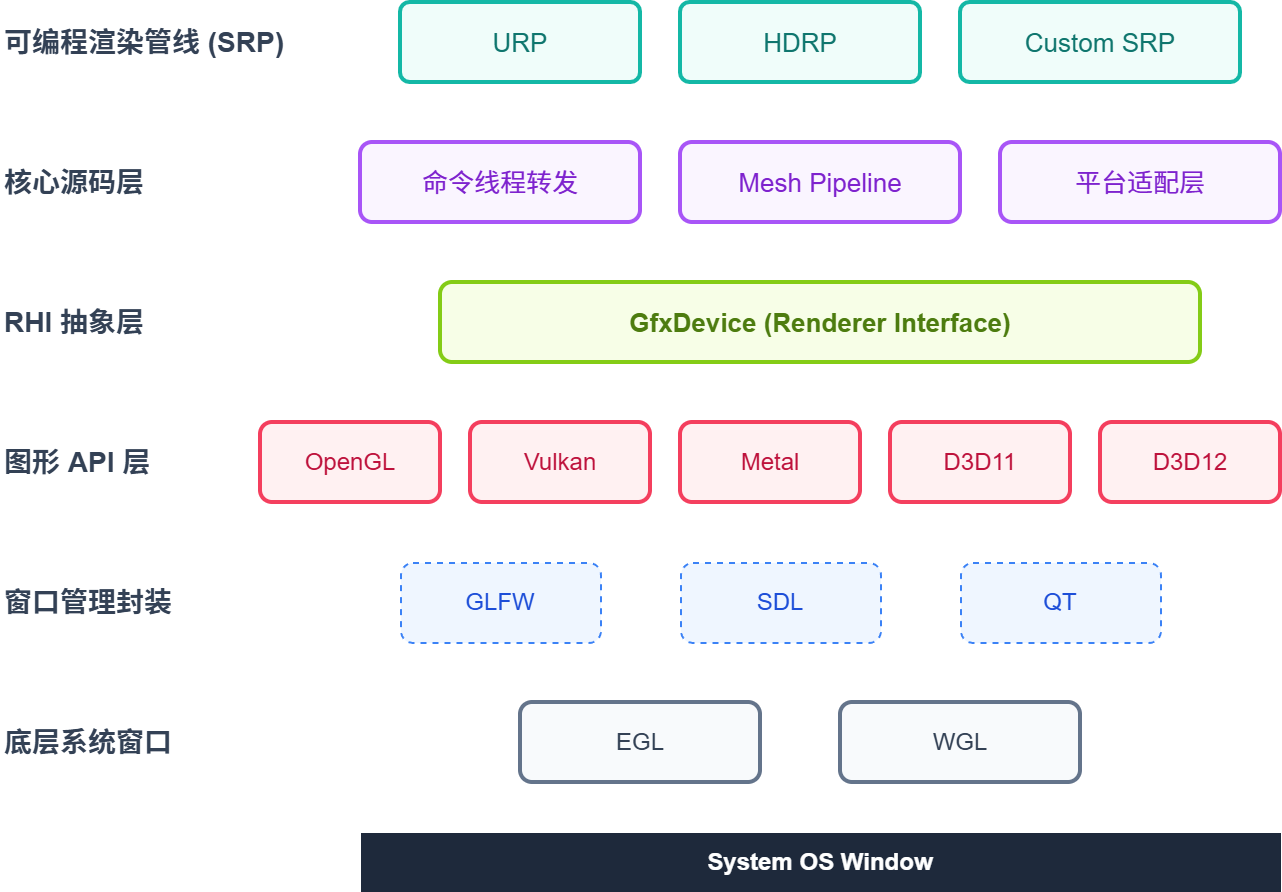
Unity 引擎的渲染架构采用了典型的分层设计,从底层操作系统到上层 C# 脚本层层封装,以实现跨平台兼容和逻辑解耦。
系统与窗口层 (System & Window)
- 最底层:系统窗口 (System Window)
- 对应操作系统原生的窗口句柄,例如 Windows 的 HWND 或 Android 的 Surface。
- 封装层:窗口管理 (Window Wrapper)
- 涉及 EGL 或 WGL 等接口,负责创建窗口上下文、管理 Surface 以及处理 Swap Buffer(交换缓冲区)。
- 商业引擎策略: 商业引擎(如 Unity)通常不直接使用 GLFW、SDL、Qt 等开源封装库,而是自行封装窗口管理类,以直接调用 EGL/WGL 从而获得更精细的控制。
图形 API 层 (Graphics API)
- 接口定义 (Headers): 由标准组织或厂商定义的规范。
- Khronos Group: OpenGL, Vulkan。
- Microsoft: Direct3D 11, Direct3D 12。
- Apple: Metal。
- 驱动实现 (Implementation): 由硬件厂商(NVIDIA, AMD, ARM/Qualcomm)提供的动态链接库(.dll/.so)。
- 关系类比:API 是头文件(Header),显卡驱动是实现文件(.cpp/impl)。
渲染硬件接口层 (RHI - Render Hardware Interface)
- 核心作用: 解决上层逻辑需要针对不同图形 API 编写多套代码的问题。通过统一的抽象接口屏蔽底层 API 差异。
- Unity 实现: 在 Unity 中,这一层被称为 GfxDevice。
- 功能: 所有的 Draw Call、资源创建等操作都通过 GfxDevice 转发,确保上层业务逻辑(如材质系统、光照系统)是通用的。
引擎渲染层 (Render Layer - C++)
- 职责: 连接 RHI 与上层脚本,处理高性能的渲染逻辑。
- 核心功能:
- Batching & Sorting: 批处理与渲染排序。
- Culling: 视锥体剔除等可见性判断。
- Platform Adaptation: 处理不同平台的特定适配逻辑。
可编程渲染管线层 (SRP - C#)
- 位置: 最上层,直接面向开发者。
- 组成:
- 官方管线:URP (Universal Render Pipeline), HDRP (High Definition Render Pipeline)。
- 自定义管线:用户基于 SRP API 开发的 Custom SRP(如二次元渲染、特殊后处理管线)。
渲染管线 (Render Pipeline) 概念辨析
语义区别
在图形开发中,"Pipeline" 一词常有两种语境,需严格区分:
- GPU Pipeline (GPU 流水线):
- 指 GPU 硬件处理单个 Draw Call 的通用流程。
- 包含阶段:Vertex Shader (顶点着色) Rasterization (光栅化) Pixel/Fragment Shader (片元着色)。
- Render Pipeline (渲染管线 - 本次重点):
- 指引擎处理 每一帧 (Frame) 的完整逻辑流程。
- 它是对一帧画面绘制任务的批量处理与组织方式。
- 可视化: 对应 RenderDoc 或 Frame Debugger 中看到的 Pass 列表(如 ShadowMap Pass G-Buffer Pass Lighting Pass)。
Built-in 管线 vs. SRP 管线
Built-in Pipeline (内置管线)
- 架构特点: 逻辑定死(Hardcoded)。
- 工作流: 引擎预定义了如 ForwardBase、ForwardAdd 等 Pass。
- 控制方式:
- 依赖 Shader 中的 Tag(如
LightMode)被动响应。 - 通过 Camera 上的开关(如是否开启 HDR、深度图)进行有限的配置。
- 局限性: 开发者无法完全控制管线的执行流,只能在预设的插槽中填空。
- 依赖 Shader 中的 Tag(如
Scriptable Render Pipeline (SRP)
- 架构特点: 起始状态为空 (Empty Canvas),完全可定制。
- 工作流:
- 由开发者在 C# 中显式定义每一帧的执行逻辑。
- 主动控制: 开发者决定是否渲染天空盒、是否渲染阴影、是否进行深度拷贝。
- 核心优势:
- 配置灵活性: 所有的渲染指令(如
DrawingSettings、FilteringSettings)都由代码构建并注入管线。 - 性能剔除: 如果某个 Pass 不需要(例如特定条件下不渲染半透明物体),在 SRP 中可以直接跳过该逻辑,而不仅仅是渲染全黑。
- 配置灵活性: 所有的渲染指令(如
SRP 极简实现流程
- 资产定义: 创建继承自
RenderPipelineAsset的可序列化资产。 - 实例创建: 资产负责创建
RenderPipeline实例。 - 渲染循环 (Render Loop):
- 在
Render(ScriptableRenderContext context, ...)方法中编写逻辑。 - Context 调用: 使用
context.DrawSkybox、context.Submit等 API 发送指令。 - 配置参数: 设置剔除参数(Culling)、绘制设置(Drawing Settings,包含 Shader Tag ID 如
UniversalForward)。
- 在
SRP 渲染流程与 CommandBuffer 机制详解
渲染对象的绘制方式:从微观到宏观
在 Scriptable Render Pipeline (SRP) 中,绘制物体主要分为两种模式:底层的单物体绘制与高层的场景批量渲染。
单物体绘制 (Low-Level approach)
类似于 OpenGL/DirectX 的 Demo 写法,适用于绘制特定的辅助几何体或简单的 Debug 图形。
- 手动流程:
- 获取当前 Camera 的数据(View/Projection 矩阵)。
- 实例化一个 Mesh(如 Cube, Capsule, Sphere)。
- 实例化一个 Material。
- 通过 CommandBuffer 下发绘制指令:指定位置 (Position)、旋转 (Rotation)、缩放 (Scale)。
- 执行 CommandBuffer。
- 结果: 屏幕上出现一个独立的网格物体。
场景批量渲染 (Production approach)
在商业引擎(如 Unity)中,不会手动逐个绘制场景物体。引擎通过 “剔除 (Culling) + 过滤 (Filtering)” 的方式来批量管理渲染。
- 核心逻辑: 开发者只需指定“规则”,引擎负责“收集与执行”。
- 关键步骤:
- Culling (剔除): 获取 CullingResults,剔除视锥体外的物体。
- Filtering (过滤): 设置 FilteringSettings,通过以下参数筛选物体:
- Render Queue Range: 渲染队列范围(如不透明、半透明)。
- Layer Mask: 层级遮罩。
- Rendering Layer Mask: 渲染层掩码。
- Drawing (绘制): 设置 DrawingSettings,指定 Shader Tag ID(如
UniversalForward)和排序模式。 - API 调用: 使用
context.DrawRenderers(cullingResults, ref drawingSettings, ref filteringSettings)。
- 优势: 引擎自动处理成百上千个物体的批处理(Batching)和状态切换。
CommandBuffer 与 Context 的底层交互
很多开发者容易混淆 CommandBuffer (命令缓冲区) 与 ScriptableRenderContext (渲染上下文) 的关系,导致渲染逻辑出错。
- CommandBuffer: 本质是一个 命令列表 (List of Commands)。
- 调用
cmd.DrawMesh或cmd.BeginSample时,只是将命令 添加 到这个列表中,并没有立即执行。
- 调用
- ScriptableRenderContext: 真正与图形驱动交互的接口。
context.ExecuteCommandBuffer(cmd)的作用是将 CommandBuffer 中的命令列表 复制 到 Context 的执行队列中。- 重要细节:
ExecuteCommandBuffer不会自动清空 cmd,通常需要紧接cmd.Clear()。
ProfilingScope 的正确用法与常见陷阱 (重点)
在 SRP 开发中,使用 ProfilingScope 配合 using 语法块可以在 Frame Debugger 中生成清晰的层级结构。但如果对底层机制理解不清,极易导致层级错乱。
核心机制
ProfilingScope 的构造函数和 Dispose 方法本质上是在操作 CommandBuffer 的 Sample 指令。
- 构造函数 (
new ProfilingScope) 调用cmd.BeginSample("Name")。 - 结束销毁 (
Dispose/End using) 调用cmd.EndSample("Name")。
正确的写法模式
必须确保 BeginSample 和 EndSample 命令都被 及时提交 到 Context 中,且包围住中间的绘制指令。
// 1. 开启 Scope,cmd 内部记录 BeginSample
using (new ProfilingScope(cmd, scopingSampler))
{
// 2. 【关键】必须先提交 cmd!
// 此时 context 队列:[...Previous, BeginSample]
context.ExecuteCommandBuffer(cmd);
cmd.Clear();
// 3. 执行具体的渲染(直接操作 context)
// 此时 context 队列:[..., BeginSample, DrawRenderers]
context.DrawRenderers(cullingResults, ref drawingSettings, ref filteringSettings);
// 4. 离开作用域,cmd 内部记录 EndSample
}
// 5. 【关键】再次提交 cmd!
// 此时 context 队列:[..., BeginSample, DrawRenderers, EndSample]
context.ExecuteCommandBuffer(cmd);
cmd.Clear();常见错误案例分析
错误 A:漏写第一个 Execute (Scope 包裹不住绘制)
- 代码逻辑:
using(Begin)context.DrawRenderersEnd using(End)Execute(cmd)。 - 实际执行流:
- Context 收到
DrawRenderers。 - Context 收到
Execute(cmd),其中包含BeginSample和EndSample。
- Context 收到
- 结果:
DrawRenderers跑到了 Sample 之外,Frame Debugger 中层级平铺,未被折叠。
错误 B:漏写最后一个 Execute (无限嵌套)
- 代码逻辑:
Execute(Begin)context.DrawRenderersEnd using(End) (无提交)。 - 实际执行流:
- Context 收到
BeginSample。 - Context 收到
DrawRenderers。 EndSample留在了 cmd 中,从未发给 GPU。
- Context 收到
- 结果: 每一帧都在压栈(Push),从未出栈(Pop)。Frame Debugger 会显示无限层级嵌套,甚至导致报错。
Note: 虽然可以直接手动写
cmd.BeginSample和cmd.EndSample而不使用using,但原理相同:必须确保 Begin → Draw → End 的指令顺序在 Context 队列中是严格线性的。
渲染硬件接口 (RHI) 简介
概念
RHI (Render Hardware Interface) 是引擎底层对不同图形 API 的抽象封装,位于 Unity 架构的 GfxDevice 层。
架构设计
- GfxDevice (基类): 定义了所有渲染所需的通用接口(如 DrawCall, CreateTexture),但只有虚函数定义,没有具体实现。
- 具体实现类 (Subclasses):
GfxDeviceD3D11/GfxDeviceD3D12(Windows/Xbox)GfxDeviceVK(Vulkan - Android/Linux)GfxDeviceMetal(iOS/macOS)GfxDeviceGLES(Old Android)
- 工作流: 上层 C# 调用 API 引擎 C++ 层转发
GfxDevice调用对应平台的原生图形 API。这使得上层逻辑(Shader, SRP)无需关心底层运行的是 DirectX 还是 Vulkan。
RHI 抽象与 CommandBuffer 执行机制深度解析
RHI (Render Hardware Interface) vs. Graphics API
虽然 RHI 基于图形 API (如 OpenGL, DirectX, Vulkan) 构建,但两者在定位与功能上存在本质区别:
核心区别
- Graphics API (DX11, Vulkan, etc.): 专注于硬件能力的直接暴露。它不知道什么是“材质 (Material)”或“全局纹理 (Global Texture)”,只认识 Buffer、Texture、Shader State 等底层资源。
- RHI (GfxDevice): 专注于引擎功能的实现。它不仅是对 API 的封装,还补全了商业引擎所需的上层概念。
- 概念补全: 引入材质系统、全局着色器变量 (Global Properties) 等 API 不具备的概念。
- 平台抹平: 对于不支持某些特性(如 DXR 光追)的后端(如 GLES),RHI 会提供空实现 (Stub) 或报错,保证上层代码的统一性。
材质 (Material) 的本质
对于底层图形 API,不存在 "Material" 类。材质是引擎层面的抽象,本质是以下数据的集合:
- Shader Code: 着色器程序。
- Shader State: 深度测试模式、混合模式等渲染状态。
- Uniform/Texture Data: 渲染所需的纹理和参数数据。
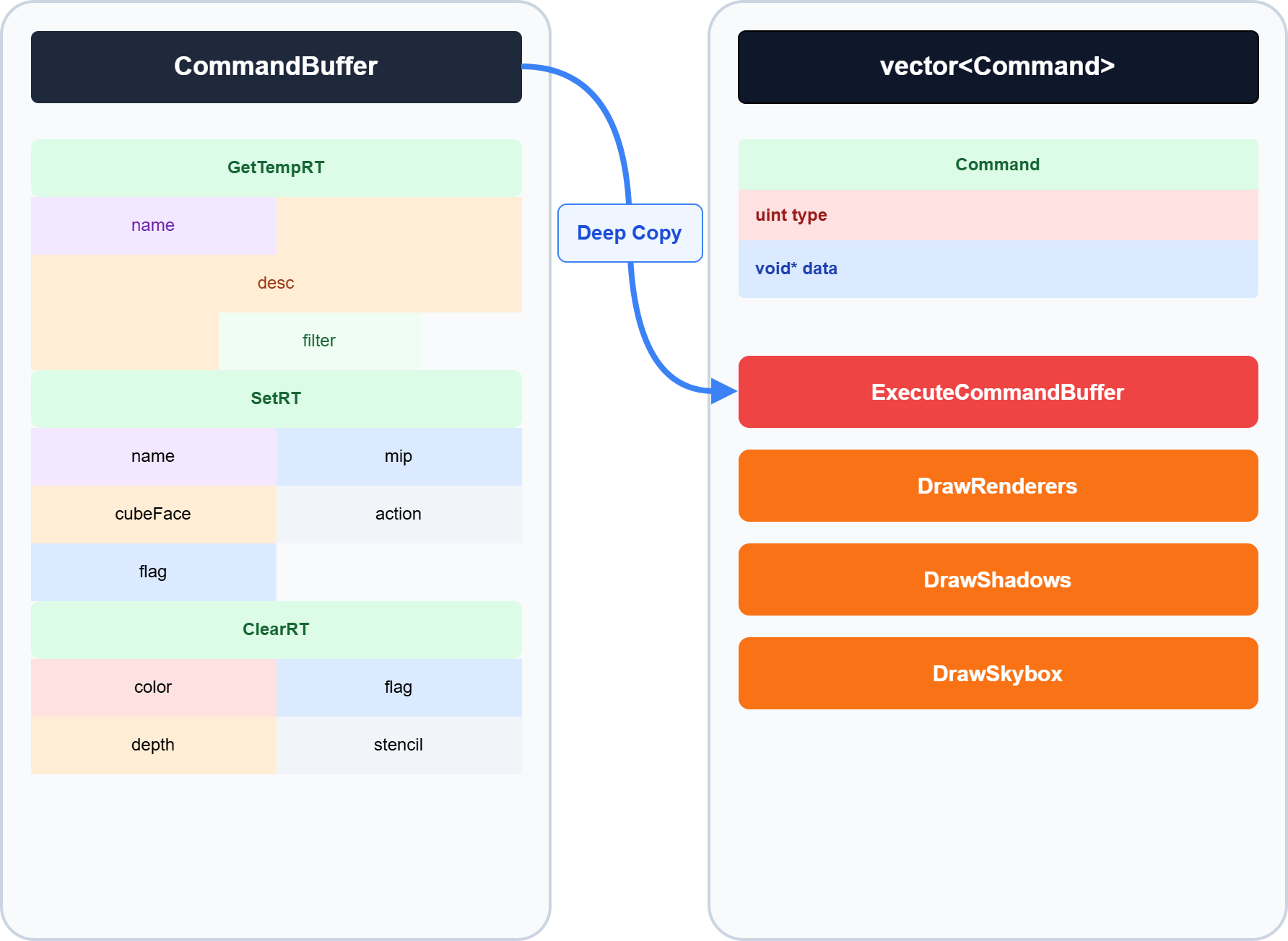
CommandBuffer 的底层数据结构
结构本质:可扩展二进制序列 (Extensible Binary Buffer)
CommandBuffer 在 C++ 底层并非存储对象列表,而是一个紧凑的纯字节数组 (Byte Vector)。
- 存储布局 (Compact Layout):
- 数据紧密排列,无空隙(或仅有内存对齐填充)。
- 格式:
[CmdType (Enum, 4 bytes)] + [Data Payload] + [CmdType] + [Data Payload] ...
- 内存特征:
- CmdType: 标识命令类型(如
SetRenderTarget,ClearRenderTarget)。 - Data Payload: 紧跟类型之后,长度不固定。
GetTemporaryRT: 可能包含 NameID (int), Desc (struct), FilterMode (enum)。SetRenderTarget: 可能包含 ColorBuffer, DepthBuffer, MipLevel 等。
- 由于数据长度可变,无法通过数组下标直接访问第 N 个命令,必须线性解析。
- CmdType: 标识命令类型(如
数据流向图解
(上图展示了 CommandBuffer 内部紧凑的二进制存储结构,对比 Context 的指针数组结构)
ScriptableRenderContext (Context) 的底层结构
结构本质:指令结构体数组 (Vector of Command Structs)
Context 在底层是一个 std::vector<CommandStruct>,与 CommandBuffer 的紧凑布局不同。
- 存储布局:
- Type: 命令类型(如
DrawRenderers,ExecuteCommandBuffer,DrawShadows)。 - Data Pointer: 指向具体数据的指针。
- Type: 命令类型(如
- 关键特性:
- ExecuteCommandBuffer 的行为: 当调用
context.ExecuteCommandBuffer(cmd)时,底层发生的是 深拷贝 (Deep Copy)。 - 数据复制: CommandBuffer 中的二进制数据被完整复制到 Context 管理的内存区域中。
- 独立性: 因此,
Execute之后立即调用cmd.Clear()是安全的,不会影响 Context 中已排队的指令。
- ExecuteCommandBuffer 的行为: 当调用
渲染指令的执行流程 (Submit & Loop)
当调用 context.Submit() 时,引擎在主线程开始执行指令队列。
上层循环 (Context Loop)
Context 因为是结构体数组,可以直接遍历:
// 伪代码逻辑
for (auto& cmd : context.commands) {
switch (cmd.type) {
case DrawRenderers:
// 执行绘制渲染列表逻辑
break;
case DrawShadows:
// 执行绘制阴影逻辑
break;
case ExecuteCommandBuffer:
// 进入 CommandBuffer 解析器
ExecuteBinaryBuffer(cmd.dataPointer);
break;
}
}内部循环 (CommandBuffer Parser)
当遇到 ExecuteCommandBuffer 类型时,进入二级解析器。由于是二进制流,必须通过指针偏移进行迭代:
// 伪代码逻辑:解析二进制流
byte* ptr = buffer.start;
while (ptr < buffer.end) {
// 1. 读取命令头 (4字节)
CmdType type = *(CmdType*)ptr;
ptr += 4;
// 2. 根据类型读取数据并执行
switch (type) {
case SetRenderTarget:
// 假设 SetRT 数据结构大小为 64 字节
auto data = *(SetRenderTargetData*)ptr;
GfxDevice->SetRenderTarget(data); // 转发给 RHI
ptr += 64; // 指针后移
break;
case ClearRenderTarget:
// 假设 ClearRT 数据结构大小为 32 字节
auto data = *(ClearRenderTargetData*)ptr;
GfxDevice->Clear(data);
ptr += 32;
break;
}
}RHI 的具体调用 (Dispatcher)
解析出的命令最终会调用 GfxDevice 接口,并分发到具体平台的实现。
- 接口层:
GfxDevice::Clear(...) - 实现层 (虚函数多态):
- 如果是 DirectX 11: 调用
GfxDeviceD3D11::ClearID3D11DeviceContext::ClearRenderTargetView。 - 如果是 Vulkan: 调用
GfxDeviceVK::ClearvkCmdClearAttachments。
- 如果是 DirectX 11: 调用
线程模型 (Thread Model)
- 上述解析与调用通常发生在 主线程 (Main Thread)。
- 如果在 Project Settings 中开启了 Multithreaded Rendering,则主线程仅负责生成中间指令(GfxCmd),实际的图形 API 调用会发送到 渲染线程 (Render Thread) 执行。
总结:CommandBuffer vs. Context
| 特性 | CommandBuffer | ScriptableRenderContext |
|---|---|---|
| 底层结构 | 紧凑二进制流 (Compact Binary Stream) | 结构体数组 (Vector of Structs) |
| 存储方式 | 数据直接内联存储 (Inline Data) | 存储数据指针 (Data Pointers) |
| 访问方式 | 必须线性解析 (Linear Parsing) | 可随机访问/遍历 (Random Access) |
| 复用性 | 理论上可复用 (如果不 Clear) | 一次性 (Submit 后即清空) |
| 交互行为 | Execute = 深拷贝数据到 Context | Submit = 执行所有指令 |
Unity 多线程渲染与 Mesh Pipeline 架构
多线程渲染架构 (Multi-threaded Rendering)
Unity 的多线程渲染旨在将逻辑处理与图形 API 调用解耦,避免主线程阻塞。
开启机制
- 配置位置: Project Settings Player Other Settings Multithreaded Rendering。
- 生效原理:
- 该选项并非运行时动态切换,而是构建(Build)时写入 boot.config 配置文件。
- 应用启动时读取配置,决定是否初始化渲染线程。
架构实现:生产者-消费者模型
- 设计模式: 标准的 Producer-Consumer (生产者-消费者) 模型。
- 核心组件:
- Main Thread (生产者): 持有一个 Proxy GfxDevice(代理设备,通常称为
ClientGfxDevice)。- 它的方法(如
Clear,Draw)不直接调用图形 API,而是将命令序列化并写入 Command Queue (命令队列)。
- 它的方法(如
- Render Thread (消费者): 这是一个与程序生命周期绑定的死循环线程。
- 不断从队列中读取命令包。
- 解析命令类型(Switch Case)。
- 调用 Real GfxDevice (如
GfxDeviceD3D11,GfxDeviceVK) 执行真正的底层 API(如ID3D11DeviceContext::ClearRenderTargetView)。
- Main Thread (生产者): 持有一个 Proxy GfxDevice(代理设备,通常称为
Key: 这种架构使得主线程无需等待 GPU 或驱动层面的同步,只需负责“发号施令”。
Mesh Pipeline (网格管线) 抽象
商业引擎 vs. 原生开发
- 原生开发 (Raw API): 开发者需要手动管理每一个 Draw Call,手动绑定 VBO/IBO,手动处理状态切换。
- 引擎抽象 (Mesh Pipeline):
- 引擎不再关注单个“三角形”或“顶点”,而是管理 Renderer 组件(
MeshRenderer,SkinnedMeshRenderer,Terrain等)。 - 职责下放: 开发者只需指定“渲染范围”和“规则”,引擎负责底层的剔除、排序、合批(Batching)和状态切换(SetPass)。
- 引擎不再关注单个“三角形”或“顶点”,而是管理 Renderer 组件(
SRP 中的渲染流程控制
在 Scriptable Render Pipeline 中,渲染流程被标准化为 Cull (剔除) Filter (过滤) Sort (排序) Draw (绘制)。
视锥体剔除 (Culling)
- API:
context.Cull(ref cullingParameters) - CullingResults:
- 返回值
CullingResults本质上是一个 Handle (句柄) 或指针。 - 异步特性: 实际的剔除计算可能在工作线程(Worker Threads)并行执行,C# 层拿到的只是结果的引用。
- 返回值
- 内部逻辑:
- 引擎底层维护了一个包含所有 Renderer 的空间索引结构。
- 遍历结构,判断物体包围盒(AABB)是否与相机视锥体(Frustum)相交。
- 输出结果:可见物体的索引列表(例如:Index List
[2, 5, 8])。
过滤与收集 (Filtering & Gathering)
即使物体可见,也不一定在当前 Pass 渲染,需通过 FilteringSettings 进行二次筛选:
- Render Queue Range: 指定渲染队列范围(如
[2000, 2500]仅渲染不透明物体)。 - Layer Mask: 游戏对象的 Layer(如
Default,Water)。 - Rendering Layer Mask: SRP 特有的高级掩码(可用于实现类似贴花或特定光照组的功能)。
绘制设置与排列组合 (Drawing & Permutations)
- API:
context.DrawRenderers(cullingResults, ref drawingSettings, ref filteringSettings) - Shader Tag ID: 指定渲染哪个 Pass(如
UniversalForward或SRPDefaultUnlit)。- 多 Pass 机制 (Multi-Pass expansion):
如果一个材质定义了多个 Pass 且 Tag ID 都匹配(例如同时通过
drawingSettings.SetShaderPassName添加了多个 Tag),同一个 Mesh 会被绘制多次。
- 多 Pass 机制 (Multi-Pass expansion):
如果一个材质定义了多个 Pass 且 Tag ID 都匹配(例如同时通过
- 排列组合 (Explosion):
最终提交给 GPU 的绘制列表是由以下维度展开的:
- 即:一个物体如果有 2 个材质,每个材质的 Shader 有 2 个匹配的 Pass,该物体将产生 个 Draw Calls(在未合批前)。
渲染排序 (Sorting)
- 目的:
- Opaque (不透明): 只有 Front-to-Back (从近到远) 排序能利用 Early-Z 优化减少 Overdraw。
- Transparent (半透明): 必须 Back-to-Front (从远到近) 排序以保证正确的混合(Blending)结果。
- State Change: 尽可能减少 Shader/Material 的切换。
- SortingCriteria: 在
DrawingSettings中指定排序策略。
Mesh Pipeline 的执行细节与 Job System 优化
渲染排列组合 (Permutation) 与合批 (Batching)
在进行实际的 Draw Call 之前,引擎需要对“哪个物体、用哪个材质、画哪个 Pass”进行排列组合,并尝试合并可合并的渲染任务。
排列组合 (Permutation)
一个 MeshRenderer 不等于一个 Draw Call。最终的绘制列表是基于以下逻辑生成的:
- LightMode: SRP 指定绘制带有特定
LightMode(如 "UniversalForward") 的 Pass。 - Permutation: 遍历物体的所有材质 遍历材质的所有 Pass 匹配 LightMode。
- 如果一个材质有两个 Pass 匹配当前
LightMode(例如描边效果可能通过两个 Pass 实现),该物体会被绘制两次。
- 如果一个材质有两个 Pass 匹配当前
合批 (Batching) 逻辑
引擎将 256 个 Render Node(渲染节点)划分为一个 Job (工作单元) 进行并行处理。在每个 Job 内部,引擎会尝试合并 Draw Call:
- 条件:
- 相同的 Mesh (如果启用了 GPU Instancing)。
- 相同的 Material。
- 相同的 Shader Pass。
- 相同的 Shader Keywords / Render State。
- 结果: 如果相邻的两个物体共享材质和 Pass,它们可能被合并(SRP Batcher 或 GPU Instancing)。
渲染数据的多线程准备 (Preparation)
context.DrawRenderers 这一行代码在 C# 端几乎没有开销(Zero Cost),因为它只是向底层发送了一个“请求”。真正的繁重工作发生在 context.Submit 之后的多线程准备阶段。
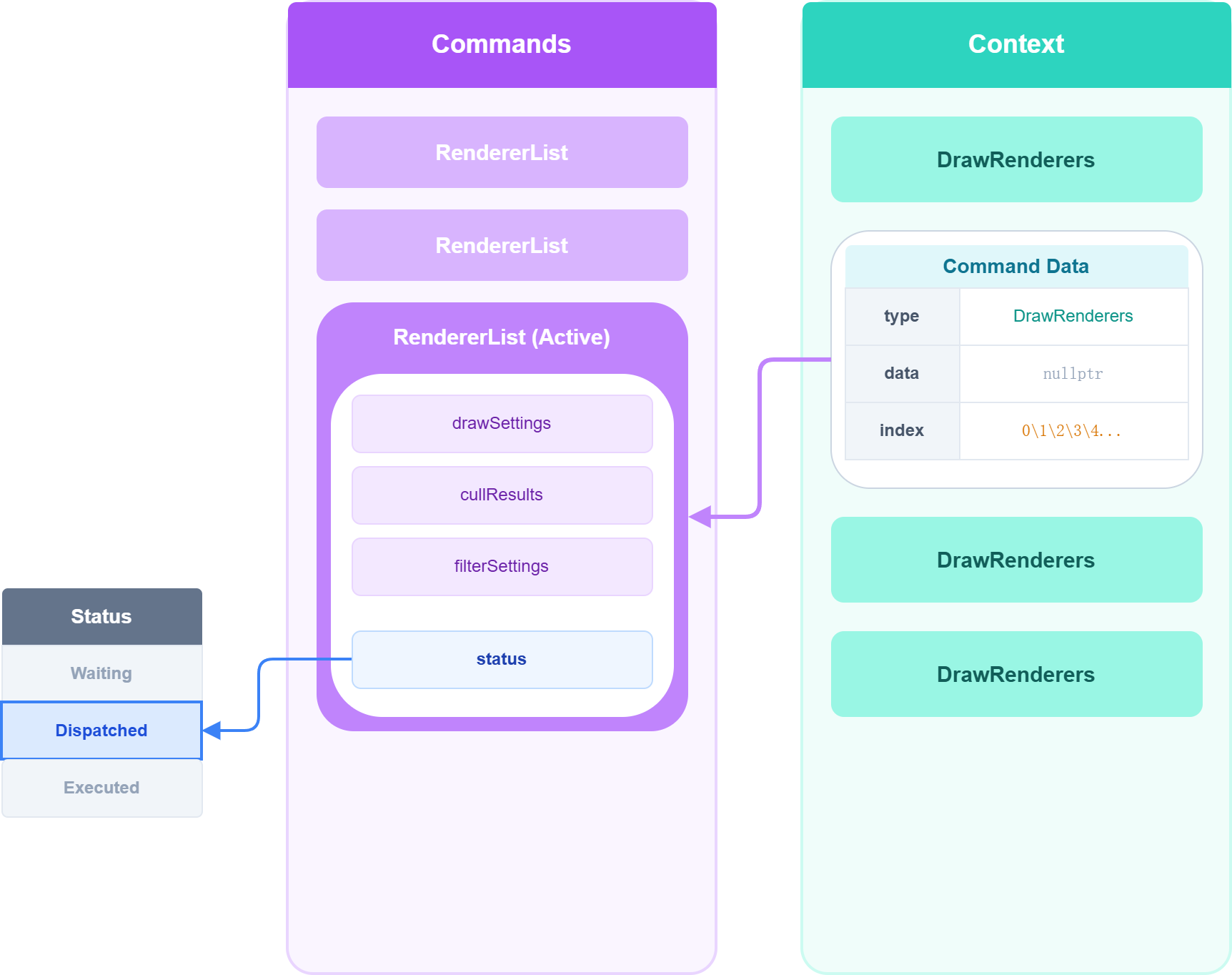
DrawRenderers 的底层行为
- 指令入队: 往底层 Command List 中添加一个类型为
DrawRenderers的指令。 - 数据存储: 具体的配置(Culling, Filtering, Sorting Settings)被存储在一个独立的 List 中。
- Index 指向: Command List 中的指令仅存储一个指向该 List 的
Index,避免大对象拷贝。 - 初始状态: 该任务的状态标记为
Waiting。
Submit 后的多线程处理 (Dispatch)
当调用 context.Submit() 时,主线程遍历指令列表,发现 DrawRenderers 指令处于 Waiting 状态,触发 Dispatch (派遣) 逻辑:
- 任务划分 (Job Splitting):
- 根据 CPU 核心数(大核/小核)计算线程数。
- 将所有可见物体(Render Nodes)按 256 个一组 划分为多个 Job。
- 并行过滤 (Parallel Filtering):
- 每个 Job 遍历其负责的 256 个物体。
- Layer Mask & Render Queue: 检查是否符合过滤条件,不符合直接 Continue。
- Material & Pass: 检查材质是否有效,Pass 是否启用 (Enabled)。
- 结果收集: 将有效的
(Object, Material, Pass)组合加入局部列表。
- 并行排序 (Parallel Sorting):
- 多线程对收集到的列表进行排序(Opaque: Front-to-Back, Transparent: Back-to-Front)。
- 任务分组 (Grouping):
- 基于排序结果,将相邻且状态一致的渲染项分组,为合批做准备。
- 依赖管理: 分组 Job 依赖于排序 Job,排序 Job 依赖于过滤 Job。通过 Job Handle (Fence) 进行同步。
Job System 与性能分析 (Profiling)
Job System 的核心思想
Unity (和 Unreal) 使用 Job System 来充分利用多核 CPU。
- 抽象: 将独立的逻辑(如剔除、排序、粒子更新)封装为 Job。
- 依赖 (Dependency): 定义 Job 之间的先后顺序(例如:必须先排序,才能分组)。
- Steal: 空闲线程可以“窃取”其他线程的任务,保证负载均衡。
Profiler 视图解读
- 蓝色 (Scripting): C# 脚本层的调用消耗。
- 绿色 (Engine): C++ 引擎底层的执行消耗。
- Culling (剔除):
- 主线程 (
CullResults.Cull) 只做少量准备。 - 大量工作被分发到 Worker Threads (绿色条块散落在各个线程)。
- 主线程 (
- DrawRenderers (准备):
- 在
Submit之后,你会看到多个 Worker Thread 同时在处理DrawRenderers的准备工作(过滤、排序)。
- 在
- 同步点 (Sync Point):
- 当真正要执行 GPU 命令时(Render Job),主线程必须等待 (Wait) 所有相关的准备 Job 完成。
- 如果 Profiler 中主线程出现长时间的
WaitForJobGroupId,说明渲染线程或 Worker 线程压力过大,主线程在空转等待。
总结:Mesh Pipeline 执行流
- C# 调用:
context.DrawRenderers(仅仅是记录命令,极快)。 - Submit 触发:
context.Submit开始执行命令列表。 - 预处理 (多线程):
- 发现
DrawRenderers指令。 - 启动 Job System。
- Worker Threads: 并行执行 Culling Filtering Sorting Batching。
- 发现
- 同步: 主线程等待上述 Job 完成。
- 渲染 (Render Job):
- 主线程(或渲染线程)生成最终的 GfxCmd。
- 调用 RHI (DirectX/Vulkan) 发送 Draw Call 给 GPU。
Render Job 执行与合批提交 (Batching & Submission)
Render Job 的执行环境 (Threading Model)
Render Job 是实际处理渲染逻辑(合批、数据准备)的工作单元。它的执行线程取决于平台和配置。
基本模式 (OpenGLES / DX11)
- 执行线程: 通常在 Main Thread (主线程)。
- 流程:
- 主线程执行 Job (For-loop)。
- 准备数据、合批。
- 通过
GfxDevice接口提交给 Render Thread (渲染线程)。 - 渲染线程调用底层图形 API (如
ID3D11DeviceContext::Draw).
多线程渲染模式 (Graphics Jobs Mode)
- 开关: Project Settings Graphics Jobs (注意与 Multithreaded Rendering 区分)。
- 执行线程: Worker Threads (工作线程)。
- 流程:
- 渲染任务被分发到多个 Worker 线程并行执行。
- 每个 Worker 线程计算完毕后,将结果提交给 Render Thread。
现代 API 模式 (Vulkan / DX12 / Metal)
现代 API 支持多线程命令录制 (Multi-threaded Command Recording),这彻底改变了渲染流程。
- 主要区别:
- DX11/GLES: 只能单线程录制命令。即使在 Worker 线程准备数据,最终必须汇聚到一个线程提交 API 调用。
- DX12/Vulkan: 支持多个 Command List 并行录制。
- 优化流程:
- Render Job (Worker Thread): 不仅准备数据,还直接调用图形 API 录制命令 (如
vkCmdDraw). - 提交: 每个 Job 生成一个独立的 Command List。最终只需在 Render Thread 将这些 Command List 提交给 Command Queue 即可。
- Render Job (Worker Thread): 不仅准备数据,还直接调用图形 API 录制命令 (如
合批器 (Batcher) 的工作原理
合批的核心是在 Render Job 内部遍历物体,尽可能将它们合并为一个 Batch。
预筛选 (Pre-filtering)
- SRP Batcher Compatibility:
- 在开始合批逻辑前,首先快速扫描 Render Nodes。
- 检查物体是否兼容 SRP Batcher(例如 shader 是否支持)。
- 如果当前物体不支持,直接作为单独的 Draw Call 提交,跳过合批逻辑。
合批状态机 (State Machine)
合批器维护当前 Batch 的状态(Shader, Keywords, Render State 等)。
- 输入: 待渲染的物体列表 (Iterating Objects)。
- 比较器 (Comparator): 比较
CurrentObject.StatevsLastBatch.State。- Case A: 状态相同 (Same State)
- 结果:
No Flush(Reason == null)。 - 操作: 将物体加入当前 Batch。
- 结果:
- Case B: 状态不同 (Diff State)
- 结果:
Flush Needed(Reason != null,例如 "Variant Changed")。 - 操作:
- Flush: 提交当前累计的 Batch 到渲染队列。
- Clear: 清空 Batcher。
- Add: 将当前物体加入新的 Batch。
- 结果:
- Case C: 循环结束
- 操作: 强制 Flush 剩余的所有物体。
- Case A: 状态相同 (Same State)
数据提交与内存管理 (Flush & Memory)
批量提交 (Batch Submission)
Render Job 不会每处理一个物体就调一次 GfxDevice(那样会有巨大的锁开销和函数调用开销)。
- 策略: 将整个 Batch(包含多个物体)作为一个数据包 (Packet) 提交给 Render Thread。
- 渲染线程行为: Render Thread 拿到这个 Batch Packet 后,再进行内部循环,逐个执行 SetPass 和 DrawCall。
内存预分配 (Pre-allocation)
为了避免频繁的 new/malloc 导致的性能劣化(GC 或 堆碎片):
- Pre-allocate: 提交前,根据 Batch 中的物体数量预估所需内存大小,预留指针。
- Commit: 实际写入数据时才通过
Commit锁定并使用内存块。 - 增量更新 (Delta Update):
- 在构建提交数据时,检查每个物体的属性(如 Mesh, Texture)。
- 如果 Texture 与上一个物体相同 不写入 SetTexture 指令。
- 如果 Texture 不同 写入 新的 SetTexture 指令。
- 这种“只发送变化量”的策略进一步减少了数据传输带宽。
渲染数据提交与常量缓冲区 (Constant Buffer) 优化
Native Graphics Jobs 与命令录制
当使用现代图形 API(DX12, Vulkan, Metal)并开启 Native Graphics Jobs 时,渲染流程发生了根本性变化。
传统模式 (Main/Render Thread)
- Flush 操作: 在 Render Job 中仅准备数据(数据包)。
- Submit: 将数据包发送到渲染线程。
- Record: 渲染线程单线程调用 API 进行命令录制。
Native Graphics Jobs 模式
- Flush 操作: 直接在 Worker Thread (工作线程) 中调用底层的命令录制函数(如
GfxDevice::RecordCommand)。 - 并行化: 多个 Job 并行录制 Command List。
- Submit: 主线程或渲染线程仅负责最终的
ExecuteCommandLists提交,极大降低了渲染线程的瓶颈。
调试技巧 (Profile Graphics Jobs)
默认情况下,Unity Editor 为了稳定性隐藏了 Graphics Jobs 的 Profiler 数据。若要强制查看:
- 找到项目目录下的
ProjectSettings/Boot.config(如果不存在则新建)。 - 添加配置行:
gfx-job-worker-count=4 (示例) gfx-enable-native-gfx-jobs=1 - 注意: 每次重启 Editor 该文件可能被重置,建议备份或在真机(Android/iOS Build)上调试。
UnityPerDraw 常量缓冲区 (Constant Buffer) 机制
UnityPerDraw 是 Unity shader 中最常用的 CBUFFER,存储每个物体特有的数据(如 MVP 矩阵、光照探针数据)。
数据准备 (Data Preparation)
- 反射 (Reflection): Shader 编译时,引擎通过反射分析出该 Shader 需要哪些 PerDraw 数据。
- 引用
unity_ObjectToWorld开启 Transform Feature。 - 引用
unity_SHAr开启 SH Lighting Feature。
- 引用
- Feature Mask: 运行时,Render Job 根据 Feature Mask 计算出每个物体所需的 CBUFFER 大小(按 16 字节对齐)。
- 批量分配:
- 假设一个 Batch 有 10 个物体。
- CPU 端分配内存:
Size = SingleObjectSize * 10。 - 循环填充:遍历 10 个物体,根据 Mask 将矩阵、SH 系数等写入内存。
数据上传与绑定 (Upload & Bind)
RHI 层对 CBUFFER 的更新进行了深度优化,隐藏了底层 API 的差异。
策略 A: 环形缓冲区 (Ring Buffer) + 偏移 (Offset)
- 适用 API: DX11.1+, DX12, Vulkan, Metal, Modern GL.
- 原理:
- 一次上传: 将 10 个物体的数据一次性
Map/Unmap拷贝到一个大的 GPU Buffer (Ring Buffer) 中。 - 多次绑定:
- Draw Object 1:
SetConstantBuffer(Buffer, Offset = 0, Size = 256) - Draw Object 2:
SetConstantBuffer(Buffer, Offset = 256, Size = 256)
- Draw Object 1:
- 一次上传: 将 10 个物体的数据一次性
- 优势: 极少的 CPU-GPU 数据传输次数 (PCIe 传输),极高的性能。
策略 B: 独立上传 (Individual Upload)
- 适用 API: DX9, Old DX11 (Win7), Legacy GL.
- 原理: 硬件不支持绑定 Buffer 的即时偏移 (Offset)。
- Draw Object 1:
Map小 Buffer Copy Data 1Draw。 - Draw Object 2:
Map小 Buffer Copy Data 2Draw。
- Draw Object 1:
- 劣势: 频繁的 Lock/Unlock 和 PCIe 传输,性能较差。
动态池化 (Dynamic Pooling)
Unity 底层维护了一个 CBUFFER 池,通常按 2 的幂次分级(256B, 512B, ... 128KB)。
- 如果 Batch 数据量超过 128KB (DX11 限制),引擎会自动拆分 Batch,分多次 Track 上传。
总结:从 Job 到 GPU 的数据流
- Render Job (Worker):
- 计算 Feature Mask。
- 在 CPU 端分配并填充
UnityPerDraw数据块(包含 N 个物体)。
- RHI Layer:
- 检查 API 能力(是否支持 Offset)。
- Modern: 拷贝整块数据到 GPU Ring Buffer。
- Legacy: 拆分为单次更新。
- Command Record:
- 写入
SetConstantBuffer(Offset)指令。 - 写入
DrawIndexed指令。
- 写入
- GPU 执行: 顶点着色器根据绑定的 CBUFFER 读取当前的 MVP 矩阵进行变换。
Material 数据管理与合批 (Batching) 优化策略
Material Constant Buffer (UnityPerMaterial) 的底层机制
与 UnityPerDraw(每物体数据,高频更新)不同,UnityPerMaterial 存储的是材质属性(如 BaseColor, Smoothness),其更新频率较低,且所有权归材质对象所有。
数据结构与存储
- CPU 端: 每个 Material 对象在 CPU 内存中持有一个 Buffer。
- 数据映射:
- 引擎维护一个 Property Map,记录 Shader 中属性名(如
_BaseColor)对应的偏移量(Offset)。 - 当调用
material.SetFloat/SetColor时,引擎根据 Offset 直接修改 CPU Buffer 中的数据。
- 引擎维护一个 Property Map,记录 Shader 中属性名(如
- Dirty Flag: 修改数据会将材质标记为“脏 (Dirty)”。
数据上传 (CPU to GPU)
- 时机: 在渲染准备阶段(Culling 后),如果检测到 Material 标脏。
- 流程:
- Check Size: 检查材质属性大小是否发生变化(例如 Shader 变体切换导致 Buffer 变大)。
- Allocation:
- 如果大小变了,释放旧 Buffer,从底层池 (GPU Buffer Pool) 中申请新的
TemporaryBuffer。 - 如果没变且未脏,直接跳过上传。
- 如果大小变了,释放旧 Buffer,从底层池 (GPU Buffer Pool) 中申请新的
- Update: 调用
GfxDevice.UpdateBuffer,将 CPU 数据拷贝到 GPU。 - Persistent: 与 PerDraw 不同,PerMaterial 的 GPU Buffer 是持久化的,直到材质销毁或 Shader 变更,不会每帧销毁。
Key Performance Tip: 避免每帧调用
material.SetFloat,除非数值真的在变。因为这会触发每帧的 PCIe 数据传输带宽消耗。
三种合批技术的对比与原理
在 Unity 中,减少 DrawCall 的核心目的是减少 Render State Change (渲染状态切换),尤其是 SetPass Call。
Static Batching (静态合批)
- 原理: 将多个使用相同材质的静态物体(Static Flag)合并成一个巨大的 Mesh。
- 限制:
- 严格同材质: 必须完全相同的 Material 实例。
- 内存代价: 合并后的 Mesh 会导致包体和内存占用显著增加(重复的顶点数据)。
- 不可移动: 物体必须是静态的。
- 评价: 牺牲内存换 CPU,现代项目中用得越来越谨慎。
Dynamic Batching (动态合批)
- 原理: 每一帧在 CPU 端实时变换顶点,将小网格合并。
- 限制:
- 严格同材质。
- 顶点数限制: 只能合并非常小的网格(通常 < 300 顶点)。
- CPU 开销: 每帧的 CPU 变换和数据上传开销可能超过 DrawCall 节省的开销。
- 评价: 在现代 CPU/GPU 架构下,通常收益甚微,甚至负优化。
SRP Batcher (SRP 合批) - 现代标准
- 原理: 不合并 DrawCall,而是合并 SetPass Call。
- 多个 DrawCall 如果使用相同的 Shader Variant(即使 Material 实例不同),只需设置一次 Shader State (
SetPass)。 - 每个物体的 Transform 和 Material 数据分别绑定到 CBUFFER (
UnityPerDraw,UnityPerMaterial)。
- 多个 DrawCall 如果使用相同的 Shader Variant(即使 Material 实例不同),只需设置一次 Shader State (
- 流程:
SetPass(Shader Variant A)Bind CBUFFER(Material A)Draw(Object A)Bind CBUFFER(Material B)Draw(Object B)
- 优势:
- 无网格合并: 节省内存。
- 支持动态物体: 只要 Shader 变体一致。
- 低带宽: 材质数据持久化在 GPU,无需每帧上传。
- 限制: Shader 必须兼容 SRP Batcher(数据布局需对齐)。
Draw Call vs. SetPass Call
我们常说的“减少 Draw Call”其实是不准确的,真正的性能杀手是 SetPass Call。
- Draw Call (命令开销): 仅仅是向 Command Buffer 添加一条
DrawIndexed指令,开销极小。 - SetPass Call (状态切换): 切换 GPU 的渲染状态(Blend Mode, Depth Test, Shader Program)。这是昂贵的操作,可能导致流水线停顿(Pipeline Stall)。
SRP Batcher 的核心逻辑: 即使有 1000 个 Draw Call,只要它们共享同一个 Shader Variant,就只有 1 次 SetPass Call。这比传统的合批更高效且灵活。
优化建议:如何利用好 SRP Batcher
- Shader 兼容性: 确保自定义 Shader 支持 SRP Batcher(在 Inspector 中查看兼容性提示)。
- 减少 Shader Variant (变体):
- 核心矛盾: 不同的变体 = 不同的 Shader Program = 必须切换 SetPass = 打断合批。
- 优化策略:
- 避免滥用
shader_feature(静态分支),这会生成不同变体。 - 权衡:对于由于贴图采样(如 NormalMap)导致的变体,可以考虑统一开启(Force Enable)。虽然增加了一点 GPU 采样开销(采样默认的平坦法线),但消除了 SetPass 切换,通常整体性能更优。
- 避免滥用
- 避免频繁 SetFloat:
- 脚本中如非必要,不要每帧设置材质属性。
- 即使是过渡效果(如溶解),数值到达 0 或 1 后应停止 Set 操作,避免触发持续的 GPU 数据上传。
- API 验证: 在 Editor 中测试合批时,务必将 Graphics API 切换为与目标平台一致(如 Android 选 OpenGLES/Vulkan),因为不同 API 的 Uniform Buffer 布局规则可能影响合批结果。
Shader 加载机制与变体 (Variant) 管理优化
Shader 的生命周期与内存管理
Unity 中 Shader 的加载过程涉及多次数据转换与内存操作,理解这一过程对于优化内存和启动时间至关重要。
初始化与解压 (Initialization & Decompression)
- Bundle Data: 打包后的 AssetBundle 中存储的是压缩的 Shader 数据 (LZ4/LZMA)。
- Awake:
- Deserialization: 将 Bundle 中的数据反序列化到内存。
- Decompression: 解压为
Track数据,随后销毁原始 Bundle 数据。 - SubPrograms Creation: 创建
SubProgram对象列表(对应底层的 VS/PS 代码片段)。 - Binary Data: 此时,Shader 代码仍以平台相关的二进制数据 (Binary Data) 形式存在于 CPU 内存中(如 DXBC, GLSL Binary, SPIR-V),尚未上传 GPU。
- Metadata Cleanup: 创建完 SubPrograms 后,销毁中间层的 Metadata。
GPU 程序创建 (GPU Program Creation)
- 触发时机:
- 首次使用 (First Use): 渲染时遇到了某个变体。
- 预热 (Warmup): 主动调用
Shader.WarmupAllShaders或ShaderVariantCollection.Warmup。
- 流程:
- 从 CPU 内存中的
Binary Data读取对应变体的数据。 - 调用图形 API 创建实际的 GPU Program (如
glCreateProgram,ID3D11Device::CreateVertexShader)。 - 销毁 CPU 数据 (Crucial): 一旦上传成功,该变体对应的 CPU Binary Data 会被销毁,释放系统内存。
- 从 CPU 内存中的
- API 差异:
- OpenGL/Metal:
glLinkProgram/newLibraryWithSource。如果是第二次加载(有缓存),可能直接加载 Binary/Cache。 - DX11:
CreateVertexShader。 - DX12/Vulkan: 不需要创建传统的 Program 对象,而是将 ByteCode 缓存起来,用于后续创建 Pipeline State Object (PSO)。
- OpenGL/Metal:
内存优化的启示
- 变体剔除 (Variant Stripping):
- 问题: 如果一个变体永远未被用到(也未预热),其 CPU Binary Data 会一直驻留在内存中。
- 后果: 造成“死内存”浪费。
- 对策: 严格剔除无用变体(使用
IPreprocessShaders)。
- 主动预热 (Active Warmup):
- 现象: 游戏运行一段时间后,ShaderLab 内存占用反而下降。
- 原因: 随着变体被用到,CPU Binary Data 被上传并销毁。
- 策略: 在 Loading 阶段主动预热常用变体,不仅消除运行时卡顿(Shader 编译/上传耗时),还能更早释放 CPU 内存。
- 分级预热:
- 对于极少进入的场景(如隐藏关卡),不要在游戏启动时预热其 Shader,而是推迟到该场景加载时,避免占用宝贵的启动内存。
变体匹配机制 (Variant Matching)
当渲染请求一个变体(例如 Keywords: A B),但该变体未被打包时,引擎如何处理?
打分算法 (Scoring)
引擎会遍历所有已打包的变体,计算一个“匹配分数”,选择分数最高的那个(通常是 Fallback)。
- 位掩码 (Bitmask): 变体关键字被映射为 Bitmask。
- 算法逻辑:
- Match (匹配项):
(Request & Candidate)计算重合的关键字数量(1 的个数)。 - Mismatch (不匹配项):
(~Request & Candidate)计算多余的关键字数量。 - Score:
Score = MatchCount - (MismatchCount * 16)。
- Match (匹配项):
- 结论: 惩罚因子 (16) 很大,意味着宁可少一个关键字(功能缺失),也不要多一个无关关键字(功能错误)。如果完全无法匹配,可能会渲染成粉色 (Pink) 或使用极其基础的 Fallback。
渲染状态优化与底层 API
批量资源绑定 (Batch Resource Binding)
- 现状: 有时 RenderDoc 中会看到连续的 API 调用:
SetTexture(0, TexA); SetTexture(1, TexB); SetTexture(2, TexC); - 优化方向 (需修改引擎/使用 SRP):
- 现代 API (DX12/Vulkan) 支持 Descriptor Tables 或 Bindless。
- 即使是 DX11/GL,也支持
PSSetShaderResources(StartSlot, Count, Views)。 - 理想情况是一次调用设置多个纹理。
Material Buffer 内存类型优化
- 问题:
UnityPerMaterial使用的是 Host Memory (CPU 内存),通过 PCIe 总线映射给 GPU。- 每次 GPU 读取(渲染)都要走 PCIe 总线。
- 优化思路 (ReBAR / Dedicated Heap):
- 如果材质数据很少变化,应该将其上传到 Device Local Memory (显存)。虽然更新慢(需要 Staging Buffer),但 GPU 读取极快。
- Unity 默认策略是为了适应“材质可能频繁变动”的通用情况,但在特定项目中可能非最优。
总结:Shader 优化的核心原则
- Strip Hard: 狠心剔除。没用的变体就是内存泄漏。
- Warmup Smart: 聪明预热。为了不卡顿,也为了省内存。
- Batch Bind: 批量绑定。减少 API 调用次数。
材质内存优化与 GPU Driven 渲染架构
材质系统内存优化策略
在通用引擎架构中,材质数据的更新往往是性能瓶颈。针对 UnityPerMaterial(低频更新数据),可以通过优化内存驻留策略来减少 PCIe 带宽消耗。
显存驻留优化 (Staging Buffer 机制)
- 常规模式 (Host Memory):
- Unity 默认通常申请 CPU/GPU Shared Buffer (Host Visible)。
- 缺点: 每次 GPU 读取数据(渲染每一帧)都需要跨越 PCIe 总线访问系统内存,或触发每帧的上传操作。
- 优化模式 (Device Local Memory):
- 双 Buffer 策略: 申请一份 Staging Buffer (CPU 可写) 和一份 Device Local Buffer (仅 GPU 显存)。
- 更新流程:
- CPU 写入 Staging Buffer。
- 执行一次 Copy 操作 (Staging Device)。
- 后续帧渲染时,GPU 直接从显存读取数据 (Device Local)。
- 收益: 极大减少了每帧渲染时的 PCIe 传输耗时,因为数据就在 GPU 芯片旁。
动态更新策略 (Heuristic Update)
针对材质更新频率的不同,可以设计自适应的底层机制:
- 高频更新: 如果材质每帧都在变(如动态特效),直接使用 Host Memory,避免双重拷贝的开销。
- 低频更新: 引入 “老化”计数器 (Aging Counter)。
- 如果某材质连续 帧(如 60 帧)未发生数据变更。
- 自动卸载 CPU 端 Buffer,重新申请并上传到 GPU Device Local Memory。
- 收益: 在不改变上层业务代码的前提下,自动优化静态物体的渲染性能。
渲染管线架构深度优化
Profiler 分析显示,渲染的主要开销往往集中在两块:
- Culling: 视锥体剔除计算。
- Render Job: 渲染数据的准备与序列化(将数据 IO 写入到多线程 Buffer 中)。
通用架构 vs. 专用架构
- 通用引擎的负担: Unity 为了兼容所有情况(通用剔除、排序、各种 Filter),带来了巨大的维护开销和数据结构冗余。
- 定制化优化 (Domain Specific):
- 案例: 渲染百万根草。
- 通用方案: 引擎对每根草做剔除、排序、合批 CPU 爆炸。
- 优化方案: 利用 Domain Knowledge (领域知识)。草不需要精确排序,也不需要逐根剔除。可以将 1000 根草打包为一个 Chunk 进行粗粒度剔除。
GPU Driven Rendering (GPU 驱动渲染)
为了彻底消除 CPU 端的 Culling 和 Data Preparation 开销,可以将管线逻辑移至 GPU。
- 流程:
- Compute Shader 剔除: 在 GPU 上对所有实例进行视锥体/遮挡剔除。
- AppendBuffer / Counter: 将可见的实例 ID 写入一个
AppendStructuredBuffer,GPU 会自动维护一个 Counter (计数器,如可见数量 136)。 - Indirect Draw: 使用
DrawMeshInstancedIndirect(或DrawProceduralIndirect)。- CPU 不知道也不关心有多少物体可见。
- CPU 仅提交一个“间接绘制指令”,GPU 读取 buffer 中的 Counter 进行绘制。
- 收益:
- (仅需极少的 Dispatch 和 Indirect Draw 调用)。
- 消除了 CPU 到 worker threads 的数据序列化开销。
Native Plugin 原生渲染插件开发
当 Unity 内置功能无法满足需求(如接入特定版本的 DLSS、专有抗锯齿库、视频编解码 AVPro)或需要极致性能时,需要开发 Native Plugin 直接操作底层图形 API。
核心工作流
- C++ 端: 编写动态链接库 (.dll / .so),实现具体的图形逻辑(如 DX12, Vulkan 调用)。
- C# 端:
- Import: 使用
[DllImport]加载插件。 - Event: 定义
IssuePluginEvent接口。 - Submit: 通过
CommandBuffer.IssuePluginEvent(callback, eventID)在渲染管线的特定时机触发 C++ 回调。
- Import: 使用
资源句柄映射 (Resource Interop)
Unity 提供了接口将上层对象转换为底层 API 的原生指针 (Native Handle)。
- RenderTexture (RT):
- 关键点: 必须先调用
rt.Create()确保底层资源已分配。 - API:
rt.colorBuffer.GetNativeRenderBufferPtr()或rt.depthBuffer.GetNativeRenderBufferPtr()。
- 关键点: 必须先调用
- Texture:
texture.GetNativeTexturePtr()。 - Mesh: 可以获取顶点和索引缓冲区的指针
mesh.GetNativeVertexBufferPtr()。 - ComputeBuffer:
buffer.GetNativeBufferPtr()。
代码示例逻辑
// 1. 创建 RT 并确保硬件资源已分配
RenderTexture rt = new RenderTexture(...);
rt.Create();
// 2. 获取底层指针 (如 DX12 Resource Pointer)
IntPtr nativePtr = rt.colorBuffer.GetNativeRenderBufferPtr();
// 3. 传递给 C++ 插件
MyNativePlugin.SetTextureFromUnity(nativePtr);
// 4. 在渲染管线中调度
cmd.IssuePluginEvent(GetRenderEventFunc(), eventID);注意: 不同图形 API (DX11 vs DX12 vs Vulkan) 返回的
IntPtr含义不同,C++ 端需要根据平台宏进行相应的转换(如强转为ID3D12Resource*)。
Native Plugin 外部资源创建与 Bindless 架构
外部资源的创建与共享 (External Resources)
在 Native Plugin 中使用 DirectX/Vulkan 创建资源,并让 Unity “视如己出”地使用它们,是高级插件开发的核心能力。
资源句柄传递 (Handle Passing)
不同图形 API 的资源句柄含义不同,在 C++ 和 C# 之间传递时需注意:
- OpenGL:
GLuint(Texture ID)。 - DirectX 11:
ID3D11ShaderResourceView*。 - DirectX 12:
ID3D12Resource*。 - Vulkan:
VkImage。 - Metal:
id<MTLTexture>。
创建外部纹理 (CreateExternalTexture)
Unity 提供了 Texture2D.CreateExternalTexture 方法来包装底层的原生指针。
// C# Side
IntPtr nativePtr = MyPlugin.GetTexturePointer(); // 从插件获取 C++ 创建的纹理指针
Texture2D tex = Texture2D.CreateExternalTexture(width, height, format, ..., nativePtr);
// 现在可以将 tex 赋值给 Material,Unity 会直接使用底层的那个资源,零拷贝
material.mainTexture = tex; - 应用场景: 视频播放器 (AVPro Video) 解码出的纹理直接在 Unity 中渲染,无需 CPU 回读。
插件生命周期 (Plugin Lifecycle)
Native Plugin 必须遵循特定的初始化与销毁流程,以确保与 Unity 渲染线程的安全交互。
- UnityPluginLoad: 插件加载时调用,获取
IUnityInterfaces。 - UnityPluginUnload: 插件卸载时清理。
- OnRenderEvent: 核心回调,响应
GL.IssuePluginEvent。
状态追踪与恢复 (State Tracking)
Unity 引擎底层维护了一套复杂的渲染状态(Render State),如果 Native Plugin 擅自修改了这些状态(如修改了 RootSignature, PipelineState),会导致 Unity 后续的渲染出错。
状态失效标志 (State Invalidation Flags)
在调用 IssuePluginEvent 时,可以通过 flags 告知引擎插件修改了哪些状态,让 Unity 在回调结束后自动恢复。
- kUnityRenderingExtEventSetStereoTarget: 修改了 VR 目标。
- kUnityRenderingExtEventUpdateTexture: 仅更新纹理,不改变状态。
- 无 Flag: 默认情况下,Unity 会假设插件修改了所有状态,因此在回调结束后会执行一次开销较大的 Full State Reset。
高级案例:Shader Complexity View (复杂度视图)
这是一个通过 Native Plugin 实现 Unity 缺失功能的经典案例(类似 UE 的 Shader Complexity)。
实现原理 (Hook & Override)
- Hook Creation: 在 C++ 层拦截 Pixel Shader (PS) 的创建。
- Instruction Counting: 分析 DXBC/DXIL 字节码,统计每个 PS 的指令数 (Instruction Count)。
- Hook DrawCall: 拦截 DrawCall。
- Override State:
- 临时切换 Render Target 到一个累积缓冲区 (Heatmap RT)。
- 开启 Additive Blending (叠加混合)。
- 替换 PS 为一个输出固定颜色的 Shader(颜色值 = 指令数权重)。
- Restore: 绘制完成后,恢复原始状态,让 Unity 继续正常的渲染流程。
Bindless (无绑定) 架构与 Unity
Bindless 是现代图形 API (DX12/Vulkan) 的一项重要特性,允许 Shader 访问几乎无限数量的资源,而无需频繁绑定 Descriptor Table。
传统绑定 vs. Bindless
- 传统 (Bound):
- Shader:
Texture2D _MainTex : register(t0); - CPU:
SetTexture(0, ptrA); - 限制: Slot 数量有限 (DX11 只有 128 个),每次切换材质都要重新绑定。
- Shader:
- Bindless:
- Shader:
Texture2D Textures[] : register(t0, space1); - Shader Access:
Textures[materialIndex].Sample(...) - CPU: 一次性将所有纹理上传到一个巨大的 Descriptor Heap。
- 优势: DrawCall 之间无需切换纹理绑定,只需传递一个整数索引 (Index)。
- Shader:
Unity 的支持现状
- Unity 现状: 默认不支持 Bindless(因为要兼容老旧平台)。
- Native Plugin 实现:
- 可以通过插件接管资源的 Descriptor Heap 管理。
- 在 C++ 层构建 Bindless Table。
- 通过
ConstantBuffer传递索引给 Shader。 - 这使得 Unity 也能享受到 Bindless 带来的 DrawCall 极大优化(尤其是大量不同纹理物体的渲染)。
Bindless 渲染架构与平台适配底层原理
Bindless Rendering (无绑定渲染) 与 Visibility Buffer
随着光线追踪(Ray Tracing)和现代 GPU 架构的发展,传统的“绑定槽位(Slot-based Binding)”模式已成为瓶颈。Bindless 技术通过全局堆访问彻底改变了资源管理方式。
核心理念
- 传统模式的局限:
- 每个 Draw Call 必须显式绑定纹理到特定槽位(如
t0,t1)。 - 槽位限制: DX11 仅支持 128 个纹理,且受限于 Root Signature 的大小。
- Texture Arrays 限制: 要求数组内所有纹理尺寸、格式一致,灵活性差。
- 每个 Draw Call 必须显式绑定纹理到特定槽位(如
- Bindless 模式:
- 全局堆 (Global Heap): 所有纹理资源驻留在一个巨大的描述符堆 (Descriptor Heap) 中。
- 指针化访问: 资源不再绑定到槽位,而是通过 索引 (Index) 或 GPU 虚拟地址 (Pointer) 直接访问。
- 类型化资源: 在 Shader 代码中,将资源地址视为一种“类型”,例如:
// 伪代码:通过地址将其“认证”为 Texture2D Texture2D<float4> myTex = ResourceDescriptorHeap[materialData.textureIndex]; float4 color = myTex.Sample(sampler, uv);
Visibility Buffer (V-Buffer) 架构
Bindless 是实现 Visibility Buffer 的基础技术:
- G-Buffer 瘦身: 屏幕空间不再存储 Albedo/Normal/Roughness 等重数据,而是仅存储 Material ID 和 Triangle ID (或 Primitive ID)。
- 延迟解析:
- 读取当前像素的
Material ID。 - 从全局材质数据缓冲区 (StructuredBuffer) 获取该材质的数据(包含纹理的 Heap Address)。
- 利用 Bindless 技术,直接根据地址从全局堆中采样纹理。
- 读取当前像素的
- 优势: 极大地降低了带宽消耗,解决了“贴图过多导致 G-Buffer 膨胀”的问题,同时天然支持 虚拟纹理 (Virtual Texturing)。
在 Unity 中 Hack 实现 Bindless (Native Plugin)
由于 Unity 的 RHI 层(尤其是在旧版本或兼容模式下)默认不支持 Bindless,可以通过 Native Plugin 对底层 DX12 进行 Hook 来强行实现。
实现原理 (Hooking DX12)
插件通过拦截 Unity 底层的 D3D12 调用来注入 Bindless 所需的逻辑:
- Hook Root Signature:
- 拦截管线状态对象 (PSO) 或 Root Signature 的创建过程。
- 注入 Flag: 强制添加
D3D12_ROOT_SIGNATURE_FLAG_CBV_SRV_UAV_HEAP_DIRECTLY_INDEXED等标志,开启 Bindless 支持。
- Hook Descriptor Heap:
- 获取 Unity 创建的主 SRV Descriptor Heap 的 基地址 (Base Address) 和 容量 (Capacity)。
- 通常 Unity 会分配一个巨大的堆(例如 200,000 个描述符)。
内存布局策略 (Collision Avoidance)
- Unity 的行为: 作为一个“黑盒”,Unity 通常采用线性分配器 (Linear Allocator),每一帧从堆的 头部 (Front) 开始向后分配资源。
- 插件的策略: 为了不与 Unity 冲突,插件通常从堆的 尾部 (Back) 向前分配 Bindless 资源。
- C# 接口: 暴露 API 让上层脚本指定索引,在堆的末端创建 SRV。
- 风险 (Risk):
- 这依赖于对 Unity 底层行为的经验性假设(Assume 它是每帧重置的线性分配)。
- 如果 Unity 未来版本改为 Ring Buffer (环形缓冲区) 或其他复杂的分配策略,这种 Hack 方式会立即失效导致冲突。
新平台适配 (New Platform Porting)
当需要将引擎移植到一个全新的操作系统或硬件平台时,核心工作在于 窗口系统 (Window System) 与 图形上下文 (Graphics Context) 的对接。
适配分层策略
- 标准图形接口 (EGL/WGL):
- 如果新平台支持标准的 EGL(嵌入式图形库),适配工作量较小。
- 核心任务: 获取原生窗口句柄 传递给 EGL 创建 OpenGL/Vulkan Context。
- 自定义图形接口:
- 如果平台使用私有 API(如 PS4/PS5 GNM, Switch NVN),则需要重写整个 RHI (GfxDevice) 层。
案例:Android 平台适配流程
- Java 层 (SDK):
- Android Activity 管理生命周期。
SurfaceView创建并持有一个 Surface 对象。
- JNI 层 (C++ Bridge):
- Java 通过 JNI 将
Surface对象传递给 C++ 层。 - C++ 调用
ANativeWindow_fromSurface将 Surface 转换为原生窗口句柄 ANativeWindow。
- Java 通过 JNI 将
- 渲染层 (EGL):
- 将
ANativeWindow句柄传递给eglCreateWindowSurface。 - 此时 EGL 建立了 GPU 与 Android 窗口系统的连接,后续即可进行
eglSwapBuffers。
- 将
总结: 平台适配的本质是打通 OS Window Manager 和 Graphics Driver 之间的桥梁,通常最终归结为传递一个
void*类型的窗口句柄。