UE5中的开放世界光线追踪 (Ray Tracing Open Worlds in Unreal Engine 5)
SIGGRAPH 2022 Advances in Real-Time Rendering in Games course
Ray Tracing Open Worlds in Unreal Engine 5
由 Epic Games 的渲染程序员 Alexander Nettle 和 Thiago Kosa 主讲。它清晰地阐述了在UE5中改进光线追踪技术的动机、核心目标以及技术验证的实际案例。
核心目标:UE5的渲染愿景
UE5 的一个关键目标是实现前所未有的渲染效果,具体体现在两个方面:
- 渲染大规模开放世界:支持巨大且无缝的场景。
- 实现顶级品质:达到前所未有的细节水平和 高质量的全局光照 (GI)。
关键技术支撑
为了实现上述愿景,UE5 引入了一系列相互协作的新功能:
- Nanite:用于处理海量几何细节的虚拟化微多边形几何体系统。
- Lumen:全动态的全局光照和反射系统。
- World Partition:用于管理和流式加载大规模开放世界地图的系统。
光线追踪的角色与挑战
光线追踪在UE5的渲染管线中扮演着至关重要的角色,是实现最高质量渲染的基石。
- 核心依赖: 像 Lumen 这样的系统,为了获取场景的全局信息(如遮挡、间接光照等)以达到最高质量,会依赖硬件光线追踪。
- 技术驱动: 正是因为这种强依赖关系,团队必须对引擎中原有的光线追踪系统进行大规模改进和优化,以应对开放世界的规模、复杂度和动态性所带来的挑战。
技术实践案例:《黑客帝国觉醒》UE5体验
本次演讲分享的技术和经验,都是在开发 《黑客帝国觉醒:虚幻引擎5体验》 (The Matrix Awakens: An Unreal Engine 5 Experience) 这个项目中经过实践和验证的。
- 项目定位:一个在 PS5 和 Xbox Series S/X 上发布、可完全交互的 playable demo。
- 性能目标:在主机平台上稳定 30fps 运行。
- 渲染挑战:该 Demo 包含了对渲染系统极具挑战性的场景,这些场景也正是驱动光线追踪技术革新的主要动力:
- 高速追逐场景 (High-speed chase):对动态物体的加速结构更新和运动模糊提出了高要求。
- 快速镜头切换 (Fast camera cuts):考验GI和反射系统的稳定性和收敛速度。
- 可自由漫游的大型城市 (Large, free-roam city):对场景管理、数据流送以及大规模场景下的光追性能是巨大的考验。
- 交互式游戏玩法 (Interactive gameplay):要求所有渲染效果必须是实时和动态响应的。
UE5 光线追踪:在《黑客帝国:觉醒》中的应用与场景构建
核心背景:《黑客帝国:觉醒》项目 (City Sample)
《黑客帝国:觉醒》是一个技术演示项目,旨在展示虚幻引擎 5 的前沿能力。其特点是拥有大量快速的镜头切换、可交互的游戏玩法,以及一个可供玩家自由探索的庞大城市。该项目后续作为 City Sample 发布,供开发者学习和使用。
UE5 中光线追踪技术的具体应用
在《黑客帝国:觉醒》中,光线追踪技术主要应用于以下三个核心系统,以达到最高的视觉保真度。
-
Lumen:动态全局光照 (Dynamic Global Illumination)
- 核心观点: Lumen 是 UE5 的动态全局光照解决方案。为了在演示中实现最佳的GI质量,它严重依赖光线追踪来获得 精确的场景表示 (accurate scene representation)。
- 技术细节: Lumen 是一个庞大且复杂的多通道(multi-pass)系统。光线追踪是其获取高质量、精确场景信息的关键手段。
- 补充: 更多关于 Lumen 的深入细节,可以参考本课程的专题讲座。
-
阴影 (Shadows)
- 核心观点: 项目中使用了 完全基于光线追踪的技术 (fully ray trace based techniques) 来模拟真实世界的光照和阴影。
- 应用场景: 由于其高昂的性能开销,这项技术在《黑客帝国:觉醒》中 仅在过场动画 (cutscenes) 中使用,目的是在这些关键帧中实现最高的阴影质量。
-
Niagara:视觉特效系统 (VFX System)
- 核心观点: Niagara 是 UE5 的视觉特效系统,它也集成了光线追踪来增强特效的真实感。
- 主要用途:
- 粒子碰撞: 为粒子提供基于光线追踪的碰撞检测,使其能与场景进行更真实的交互。
- 实验性功能: 用于实现更前沿的 载具与世界的碰撞 (vehicle-to-world collisions)。
为光线追踪构建大规模城市场景
为了支持上述高质量的光线追踪效果,引擎需要高效地构建和管理一个极其复杂的场景。
-
挑战:超大规模的城市环境
- 场景规模: 一个面积达 16平方公里 的庞大城市。
- 总实例数: 由 850万个网格实例 (mesh instances) 构成。
- 运行时实例数: 在任意时刻,场景中约有 150万个实例 被加载,这些实例由 世界分区系统 (World Partition System) 进行动态 流式加载 (streaming)。
-
解决方案:程序化生成与模块化网格
- 高实例数的原因: 庞大的实例数量主要是由 程序化生成 (procedural generation) 系统所致。例如,城市中的所有建筑都是由多个 模块化网格 (modular meshes) 拼接而成的。
- 模块化优势:
- 核心优势: 这种以模块化网格作为“积木”来构建城市的方式,极大地降低了整体内存占用。
- 实现原理: 因为相同的几何体数据(如一扇窗、一段墙)可以在整个城市中被 高效地复用 (efficiently reused)。
大规模世界的光线追踪场景表示
大规模实例化带来的光追挑战
在使用光线追踪技术渲染大规模世界时,虽然实例化(Instancing)技术能够通过复用几何数据有效降低内存使用,但海量的实例数量会引发一系列新的、严峻的性能挑战。
全局光照的诉求
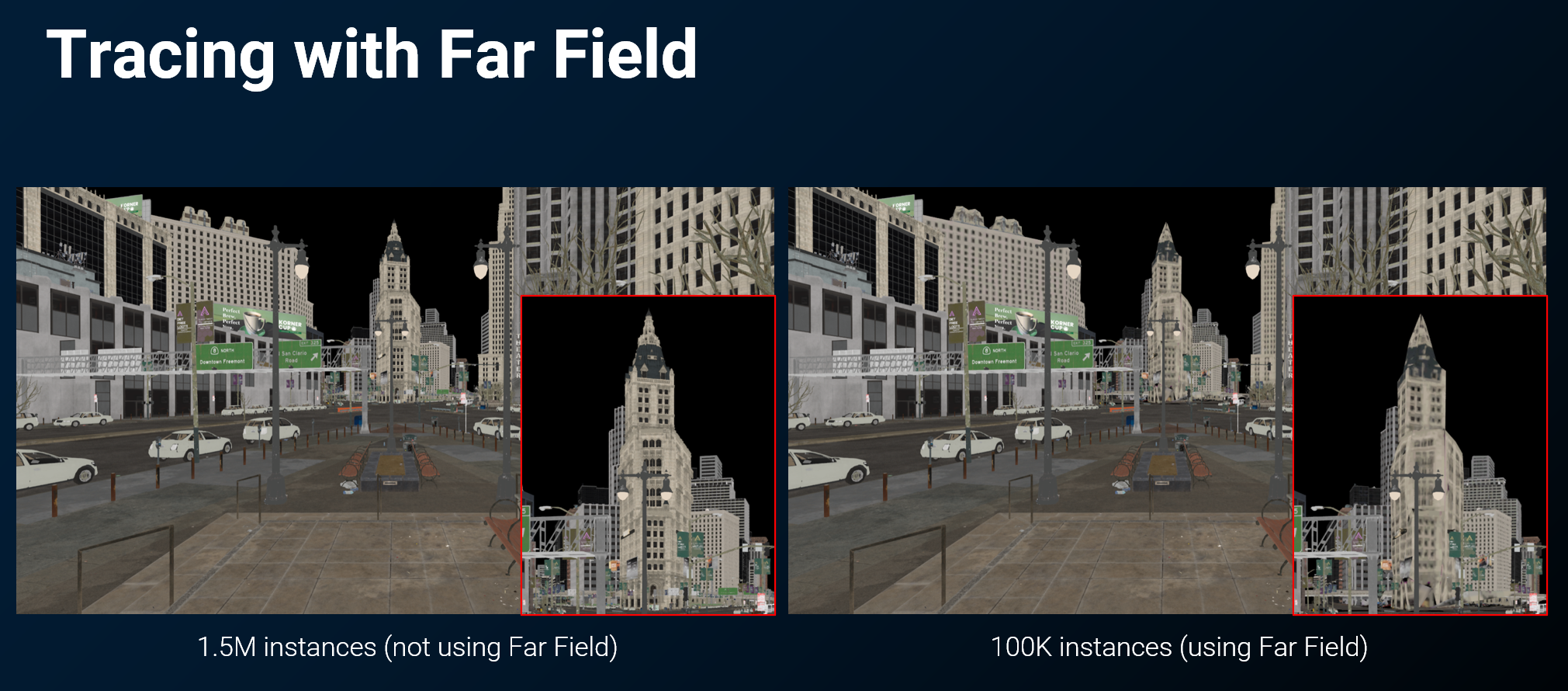
为了计算出精确的全局光照(Global Illumination),光线追踪需要一个能覆盖玩家周围大范围区域的场景表示。如果场景表示范围受限,会产生严重的视觉错误。
- 核心观点: 一个受限的、小范围的场景表示会导致GI计算错误,例如本应被遮挡的反射物错误地反射了天空,或者遗漏了近处物体的反射。
- 示例: 下图中,左侧由于场景表示范围不足,高亮建筑的反射完全丢失了周围的楼宇,直接反射了天空,而右侧拥有完整场景表示则能正确反射。

性能瓶顶
在拥有海量实例的大世界中进行光线追踪,主要面临三大挑战:
- 昂贵的TLAS重建: 实例数量巨大,导致顶层加速结构(Top-Level Acceleration Structure, TLAS)的重建或更新开销非常高昂。
- BLAS内存占用: 底层加速结构(Bottom-Level Acceleration Structure, BLAS)需要存储所有唯一的几何体数据,总体内存占用依然是一个负担。
- 追踪性能: 在庞大而复杂的加速结构中遍历光线的成本很高,直接影响整体追踪性能。
解决方案:远近场分层 (Near-Field / Far-Field) 场景
为了解决上述挑战,我们提出了一种基于细节层次(LOD)思想的场景划分策略,将光追场景分为“近场”和“远场”。
核心思想
该方法基于一个关键观察:
- 核心观点: 高频的几何细节对于远处的全局光照和反射贡献极小。因此,我们只需要在邻近玩家的区域保留高质量的场景表示。
近场 (Near-Field) 的定义与实现
近场 (Near-Field) 是围绕玩家的一个高精度区域,专门用于计算细节丰富的反射和全局光照。
- 目的: 确保玩家附近的GI效果精确、细腻。
- 范围: 以玩家为中心的 150米半径 内的区域。
- 内容:
- 高精度模型: 使用与主视图(G-Buffer渲染)相似细节层次(LOD)的网格。
- 动态与静态对象: 为了保证GI的完整性和正确性,近场表示中同时包含 静态网格(static meshes) 和 动态网格(dynamic meshes),例如蒙皮角色(skinned characters)。
大规模场景的光线追踪优化:近场与远场表示法 (Near & Far Field Representation)
在处理如《黑客帝国觉醒》这样宏大且细节丰富的开放世界场景时,如何高效地为光线追踪构建场景几何体是一个核心挑战。如果采用“蛮力法”将场景中所有物体都作为独立的实例提交,可能会产生数百万个实例,这对于加速结构(BVH)的构建和遍历是难以承受的。为此,讲座中提出了一种分层级的场景表示方法,将世界划分为 近场 (Near Field) 和 远场 (Far Field)。
一、 近场 (Near Field) 的构建
-
核心观点: 近场专注于玩家附近的区域,目标是提供最高精度的几何表示,确保近距离交互和视觉质量。
-
关键特征:
- 包含内容: 不仅包括 静态网格体 (Static Meshes),如建筑、道路等,还必须包含所有 动态网格体 (Dynamic Meshes),例如载具、NPC、以及主角的 蒙皮角色 (Skinned Characters)。
- 表示方式: 使用原始的、高精度的模型实例。
- 主要作用: 保证光线追踪在近距离的物理正确性和视觉细节,支持动态物体与场景的精确交互(如阴影、反射)。
二、 远场 (Far Field) 的构建
-
核心观点: 远场覆盖广阔的远景区域,其核心目标是在维持宏观视觉表现力的同时,极大降低几何复杂度和实例数量。
-
关键特征:
- 覆盖范围: 在《黑客帝国觉醒》Demo中,远场覆盖玩家周围约 1公里半径 的区域。
- 内容筛选: 为了优化,远场只包含静态网格体。因为远处的车辆、行人等动态物体对整体光照和反射的贡献微乎其微,可以被安全地忽略。
- 核心技术: HLOD (Hierarchical LoD)
- 这是一种Unreal Engine中已有的、用于优化传统光栅化渲染中远景物体的系统,在这里被巧妙地复用到了光线追踪场景的构建中。
- 工作原理: HLOD系统会将 多个独立的静态网格体合并(Combine) 成一个单一的、巨大的 代理网格体 (Proxy Mesh)。
- 几何简化: 在合并过程中,HLOD还能生成顶点数更少的简化几何体。
-
优化效果:
- 实例数量锐减: 从可视化对比中可以清晰地看到,一个HLOD实例就能代表原先由多栋建筑组成的区域。原本需要数千个独立网格实例的城市街区,现在可能仅由 寥寥数个HLOD实例 来表示。
- 可视化对比: 下图展示了实例的可视化效果,每个颜色块代表一个实例,它有效地概括了远景的几何轮廓。

三、 性能对比与总结
-
蛮力法 (Brute Force): 若不采用分层策略,直接将《黑客帝国觉醒》场景中的所有网格体提交给光线追踪,会产生约 150万个网格实例。这对于实时光线追踪是巨大的性能瓶颈。
-
近场/远场法: 通过这种两级表示法,光线追踪场景需要处理的几何复杂度和实例数量得到了数量级上的降低。这本质上是一种针对光线追踪场景构建的、非常高效的 LOD (Level of Detail) 策略。它在保证近处细节的同时,极大地优化了远景的性能开销,使得在超大规模世界中实现高质量的实时光线追踪成为可能。
核心主题:远近场(Near/Far Field)光线追踪的优化策略与实现
本节内容探讨了一种用于大规模场景光线追踪的性能优化技术:将场景划分为 近场(Near Field) 和 远场(Far Field) 进行分层处理。这套方法旨在以可接受的视觉质量损失为代价,大幅降低渲染开销。
一、 远近场策略的核心思想与视觉权衡
-
核心思想:分而治之
- 近场 (Near Field): 靠近摄像机的区域,使用高精度的原始模型实例。
- 远场 (Far Field): 远离摄像机的区域,使用经过大幅简化的模型,通常是 HLODs (Hierarchical Level of Detail)。
- 性能优势: 通过在远处使用简化模型,可以巨幅减少需要处理的几何实例数量。讲座中的案例表明,该方法仅用 暴力渲染方式 1/10 的实例数量 就达到了相似的宏观效果。
-
视觉质量与权衡 (Trade-offs)
- 宏观相似性: 在正常视角下,远近场结合的渲染结果与完全使用高精度模型的暴力渲染结果在视觉上非常接近。
- 细节损失: 当拉近镜头观察远景时,细节差异会变得明显,远场的几何体和纹理细节都较低。
- 潜在问题: 远场表示与主视图(近场)的渲染内容不完全匹配,可能导致一些渲染瑕疵,最典型的是 错误的自阴影 (Incorrect Self-Shadowing)。
-
应用场景与合理性
- 该策略的优势远大于其带来的问题,尤其适用于以下场景:
- 远距离的全局光照 (Distant Global Illumination)
- 反射 (Reflections)
- 在这些应用中,观察者对远景的微小几何或阴影错误不敏感,因此这种近似处理是完全可以接受的。远场几何体仅在距离摄像机较远的区域被光线命中。
- 该策略的优势远大于其带来的问题,尤其适用于以下场景:
二、 实现挑战:如何正确合并远近场加速结构
将远近场结合并非易事,一个关键的技术难点在于如何处理它们各自的加速结构。
-
问题:朴素合并的失败
- 错误的做法: 将近场和远场的几何体放入 同一个顶层加速结构 (TLAS - Top-Level Acceleration Structure) 中,然后直接进行光线追踪。
- 失败原因:
- 近场中的高精度物体,在远场的 HLOD 中也存在一个简化版本。
- 由于 HLOD 是对原始几何的粗略近似,其 简化的三角面片有时会“膨胀”到原始模型的包围盒之外。
- 这会导致在某些光线路径上,本应命中近处高精度模型的 光线,却被远场的简化模型错误地提前遮挡,产生严重的视觉错误(例如,近处物体被远处的“幽灵”几何体遮挡)。
-
解决方案:两步式光线追踪 (Two-Step Ray Tracing)
为了解决上述遮挡问题,讲座提出了一种分离式的、有序的光线追踪流程:
-
第一步:追踪近场
- 首先,只针对 近场 (Near Field) 的 TLAS 追踪光线。
-
第二步:追踪远场 (仅当近场未命中时)
- 如果第一步中的光线没有命中任何近场几何体(即光线射向了远方或天空),则从该光线未命中的终点开始, 发射一条新的延续光线 (Continuation Ray)。
- 这条新的光线只针对 远场 (Far Field) 的 TLAS 进行追踪。
-
-
性能考量
- 这种两步法会为那些最终射向远方的光线带来一些额外开销(需要追踪第二条光线)。
- 然而,与渲染一个包含所有细节、未经优化的庞大场景相比,这种分离追踪的方案在总体性能上要快得多,是一种非常高效的优化策略。
处理近场与远场光线追踪的衔接问题
本节聚焦于在混合使用近场(高精度)和远场(低精度)几何表示进行光线追踪时,所面临的两个核心挑战:几何衔接处的视觉瑕疵以及 加速结构(Acceleration Structure)的效率问题。
近场与远场几何的不匹配问题与解决方案
当一条光线从近场区域穿越到远场区域时,由于两种几何表示并非完美对齐,会引发一系列问题。
核心问题:几何不匹配 (Geometry Mismatch)
- 问题描述: 远场几何体是对近场高精度模型的简化或代理。当近场光线追踪停止,远场光线追踪开始时,远场光线的起点可能恰好位于一个简化的远场几何体内部。
- 根本原因: 近场光线可能因为精度原因“错过”了某个非常靠近边界的物体,但其后续的远场光线却从该物体简化后的模型内部开始追踪。
- 视觉表现: 这会导致在渲染画面中,近场和远场交界处出现 明显的缝隙或间断 (Gaps or Discontinuities)。
解决方案
为了解决上述视觉瑕疵,可以采用以下两种技术:
-
方案一:光线起点偏移 (Ray Start Offset)
- 核心观点: 对远场光线的起点应用一个负向偏移量,即沿着光线方向稍微向后移动一点。
- 工作原理: 讲座中提到,远场表示通常会与近场有部分重叠。通过将光线起点向后移动,可以确保光线有足够的机会击中那些在衔接处被近场光线“错过”的远场几何体表面,从而填补缝隙。
-
方案二:交叉淡化 (Cross-Fade)
- 核心观点: 当近场和远场的相交结果在视觉上依然存在明显过渡时,对两者进行平滑的交叉淡化处理。
- 应用场景: 这是一种补充性的平滑技术,用于处理偏移后可能仍然存在的细微视觉差异,使过渡更加自然。
-
拓展学习: 讲座推荐参考本课程中关于 Lumen 的演讲部分,其中 Patrick 详细介绍了 Lumen 在计算阴影和处理光线发散 (Ray Divergence) 时所使用的相关优化技术。
加速结构(TLAS)的设置与优化
为了分别追踪近场和远场,我们需要在加速结构层面进行区分。然而,一种看似直接的方法却会带来性能陷阱。
初级方法:使用实例掩码 (Instance Mask)
- 实现方式: 在顶层加速结构 (TLAS, Top-Level Acceleration Structure) 中,通过为远场实例设置一个特定的 实例掩码 (Instance Mask) 位来进行标记。在光线追踪时,可以根据需要分别追踪命中近场或远场掩码的实例。
该方法存在的问题:效率低下
- 核心问题: TLAS 构建器 (TLAS Builder) 缺乏足够的上下文信息。它不知道这些掩码是用于划分近场和远场这种特定用途的。
- 直接后果: 由于构建器无法进行针对性优化,它会在 TLAS 的节点中 将两种表示的实例(近场和远场)混合在一起。
- 性能影响: 这种混合布局导致了 显著的光线遍历开销 (Significant Traversal Overhead)。在遍历 BVH 树时,即使当前光线只关心远场,也可能需要进入并检查包含大量近场实例的节点,反之亦然。这大大降低了遍历效率,是我们希望极力避免的。
总结: 仅仅使用 Instance Mask 来分离近/远场追踪是一种功能上可行但性能不佳的方案。后续内容可能会探讨如何更高效地组织 TLAS 来解决这个问题。
处理多重场景表达的加速结构优化
本节聚焦于在渲染大规模场景时,如何高效管理和遍历针对不同距离(近场、远场)的多种几何实例表达(Multiple Representations)的加速结构。
一、 核心问题:混合表达方式带来的性能瓶颈
当我们将一个场景拆分为 近场高精度表达 (Near-Field) 和 远场低精度表达 (Far-Field) 时,如果将这两种表达的所有实例都放入一个 单一的顶层加速结构 (TLAS) 中,会引发严重性能问题。
- 核心观点: BVH 构建器 会混合处理这两种在空间上可能重叠的实例,生成一个复杂且低效的 BVH 结构。
- 根本原因: 这种混合结构导致光线在遍历(Traversal)过程中需要处理不必要的节点交叉和重叠区域,从而产生 显著的遍历开销 (significant traversal overhead),拖慢渲染速度。
二、 解决方案与优化策略
为了解决上述问题,讲座提出了两种截然不同的方案。
方案一:大空间偏移 (The Large Offset Approach)
这是一种实用且已在《黑客帝国觉醒》项目中因开发时间限制而实际应用的方案。
- 核心思想: 在构建 BVH 之前,为其中一种表达方式(例如远场表达)的所有实例施加一个 巨大的空间偏移 (large offset)。
- 实现原理:
- 通过人为地在空间上将近场实例和远场实例分离开,使得它们的包围盒完全不重叠。
- 这样一来,BVH 构建器在处理时自然会将它们归入不同的 BVH 分支,避免了节点混合。
- 优点: 能够避免大部分的遍历开销,是一个行之有效的折衷方案。
- 缺点: 本质上是一种“取巧”的方法,并非最理想的架构。
方案二:分离式顶层加速结构 (Separate TLAS Approach - 更优解)
这是讲座推荐的更优、更彻底的解决方案。
- 核心思想: 为每种表达方式(近场、远场) 分别构建一个独立的 TLAS。
- 实现原理:
- 在光线追踪时,根据光线的类型或需求, 动态选择合适的 TLAS 进行查询。例如,处理主摄像机近处阴影的光线查询近场 TLAS,处理远处反射或全局光照的光线查询远场 TLAS。
- 由于光线通常不需要同时与两种表达进行求交,这种分离是完全可行的。
- 优点:
- 完全避免遍历开销: 因为两个 TLAS 是物理隔离的,从根本上杜绝了节点混合问题。
- 独立的更新频率: 远场 TLAS 通常变化较少,可以以更低的频率重建,甚至可以在加载时构建一次后就不再变动,极大地节省了每帧的计算资源。
三、 性能对比
讲座通过数据对比,清晰地展示了不同方案的性能差异。
| 方案 | 实例数量 | 性能表现 | 覆盖范围 | 总结 |
|---|---|---|---|---|
| 暴力法 (Brute Force) | 150 万 | 性能基线(最慢) | 完整覆盖 | 效果最好,但性能无法接受。 |
| 仅近场 (Near-Field Only) | 10 万 | 显著更快 | 仅限玩家周围 150m 半径 | 速度极快,但视觉范围受限。 |
| 近场 + 远场分离方案 | 10 万 | 存在一定开销,但仍远快于暴力法 | 几乎与暴力法相当 | 实现了性能与视觉效果的最佳平衡。 |
四、 承上启下:下一步流程
在确定了将场景拆分为近场和远场的策略后,处理加载实例的第一步工作就是:
- 实例剔除 (Instance Culling): 在将实例送入 BVH 构建流程之前,先进行有效的剔除,减少不必要的计算。这是下一节将要讨论的主题。
实例处理:剔除与TLAS构建
本节核心讨论了在拥有海量实例(如《黑客帝国:觉醒》中的150万个)的场景中,如何高效地处理它们,主要分为两大步骤: 实例剔除(Instance Culling) 和 顶层加速结构(TLAS)的构建。
实例剔除 (Instance Culling)
剔除的目的是在渲染前,从海量的实例中筛选出当前帧真正需要处理的子集,以减轻后续流程的负担。
核心观点
- 面对海量实例,逐一处理是不可行的,必须采用高效的剔除策略。
- 剔除不仅要快,还要解决由模块化资产带来的视觉瑕疵。
剔除策略 (Culling Strategies)
为了筛选出可见的实例,讲座中提到了两种主要的剔除方法:
-
距离剔除 (Distance Culling):
- 基于实例到摄像机的距离进行剔除。
- 使用不同的阈值来区分 近场(near field) 和 远场(far field) 的物体,因为远处的小物体对最终画面的贡献微乎其微。
-
立体角剔除 (Solid Angle Culling):
- 进一步优化,剔除那些即使在视锥体内但对屏幕贡献仍然很小的物体。
- 具体方法是计算实例的 包围球(bounding sphere) 在屏幕上投影后所覆盖的立体角,如果该角度过小,则予以剔除。
性能优化与问题解决
直接对百万级的实例应用上述策略依然非常昂贵,因此需要更智能的方法。
-
分层剔除 (Hierarchical Culling):
- 核心问题: 对150万个实例进行逐一剔除,计算开销巨大。
- 解决方案: 采用层次结构(如八叉树、BVH等)来组织实例。通过先对上层节点进行剔除测试,可以一次性地剔除或接受大量的实例,从而极大地加速剔除过程。
-
剔除组 (Culling Groups):
- 核心问题: 使用小型模块化网格(modular meshes)拼接大型物体(如建筑)时,每个模块会被独立剔除。这可能导致在某些视角下(尤其是在反射中),建筑的某些部分消失,而另一些部分可见,造成视觉破绽。
- 解决方案: 将逻辑上属于同一个物体的所有实例(如构成一栋建筑的所有模块)分配到同一个剔除组。系统在进行剔除决策时,会使用整个组的 组合包围盒(group bounds) 进行判断。
- 效果: 确保了建筑等复杂物体能够被作为一个整体进行剔除,要么全部可见,要么全部不可见,从而避免了“墙体消失”等问题。
剔除效果量化
在《黑客帝国:觉醒》的场景中,剔除效果显著:
- 剔除前: 加载约 150万 个实例。
- 剔除后: 最终进入渲染流程的约 10万 个实例,并且绝大部分位于近场。
顶层加速结构 (TLAS) 的构建
经过剔除后,剩下的约10万个实例需要被用来构建光线追踪所需的顶层加速结构(TLAS)。
核心观点
- 由于场景的动态性,TLAS必须每帧重建,这是一个主要的性能开销点。
动态场景的挑战
- 为何需要每帧重建: 玩家在场景中移动,摄像机位置变化,更重要的是场景中的物体(如汽车)也在不停移动。这些变换导致实例的位置和状态每帧都在变化。
- 必然结果: TLAS 必须 每帧从头开始重建 (rebuild every frame) 以反映场景的最新状态。
重建流程与性能瓶颈
-
构建步骤:
- 在 CPU端 准备数据。
- 为每一个通过剔除的实例(约10万个)收集数据,生成 实例描述符 (instance descriptors)。这些描述符包含了实例的变换矩阵、指向底层加速结构(BLAS)的指针、材质信息等。
- 将这些描述符从多个数据源(游戏逻辑、物理系统等)收集起来。
- 从CPU拷贝到GPU填充一个专用的GPU缓冲区。
-
性能瓶颈:
- 为10万个实例收集数据并 拷贝到GPU 的过程非常耗时,尤其是在CPU端完成,这可能成为渲染管线中的一个显著瓶颈。
光线追踪加速结构优化:实例与几何体管理
本节聚焦于光线追踪中加速结构的构建与优化,特别是如何高效处理大量实例数据以及不同类型的几何体。核心思路是尽可能将工作负载转移到 GPU,并利用异步计算来隐藏延迟。
实例数据与顶层加速结构 (TLAS) 的构建与优化
传统的在 CPU 端准备实例数据并逐帧上传至 GPU 的方法存在显著的性能瓶颈。为了解决这个问题,讲座中介绍了一种完全在 GPU 端构建实例缓冲区的方法。
核心观点:使用 Compute Shader 在 GPU 端构建实例缓冲区
放弃在 CPU 端准备实例数据,转而利用 GPU 的并行计算能力来完成这项工作。
-
实现方式:
- 通过一个 Compute Shader,将实例数据直接写入一个 GPU 上的 结构化缓冲区(Structured Buffer) 中。
- 这个缓冲区的内存布局在 D3D12 和 Vulkan 中基本一致,提供了良好的跨 API 兼容性。
-
主要优势:
- 减少数据传输: 在现代 GPU 驱动的渲染管线(GPU-Driven Rendering) 中,大部分实例数据(如变换矩阵、材质索引等)已经存在于 GPU 上。此方法可以直接复用这些数据,避免了从 CPU 到 GPU 的重复上传。
- 避免昂贵的 GPU 回读(Readbacks): 对于完全在 GPU 上生成的物体(例如粒子系统),其变换数据也在 GPU 上。传统方法需要将这些数据回读到 CPU 再上传,非常耗时。GPU 构建方法从根本上消除了这一瓶颈。
- 实现 GPU 实例剔除(Instance Culling): 可以在构建实例缓冲区的 Compute Shader 中直接集成剔除逻辑(如视锥剔除),进一步减少需要送入 TLAS 构建的实例数量,提升效率。
核心观点:利用异步计算隐藏 TLAS 构建延迟
即使在 GPU 上,构建一个包含大量实例的 顶层加速结构(Top-Level Acceleration Structure, TLAS) 仍然相当耗时。
- 性能数据: 在讲座的案例中,Rebuild TLAS 需要大约 2 毫秒。
- 优化策略:
- 尽早启动构建: 在渲染帧的早期阶段就发起 TLAS 的重建指令。
- 利用异步计算(Async Compute): 将 TLAS 构建任务放在异步计算队列上执行,使其与其他渲染工作(如 G-Buffer Pass)并行处理,从而隐藏其大部分耗时。
- 优化效果: 通过异步计算的重叠执行,TLAS 构建对整体帧时长的实际影响从 2 毫秒 降低到了约 0.3 毫秒,效果非常显著。
几何体数据与底层加速结构 (BLAS) 的管理
在处理完实例层面的 TLAS 后,讲座开始讨论几何体层面的 底层加速结构(Bottom-Level Acceleration Structure, BLAS)。从光追的角度,场景中的几何体被分为两大类。
核心观点:为静态网格体的每个 LOD 预构建独立的 BLAS
这是针对场景中不会在运行时发生顶点形变的几何体的优化策略。
- 静态网格体(Static Meshes)
- 定义: 其顶点数据在加载后不会在运行时被修改的网格体。
- BLAS 管理策略:
- 一次性构建: 由于几何体不变,其 BLAS 只需要在资源加载时构建一次,之后无需任何更新或重建。
- 为每个 LOD 预构建 BLAS: 为模型的每一个 细节层次(Level of Detail, LOD) 都创建一个独立的、预构建好的 BLAS。
- 优势: 当物体因为距离变化需要切换 LOD 时,渲染器无需耗费时间去重建一个新的 BLAS。它仅仅需要更新 TLAS 中对应实例的描述,让其指向该 LOD 对应的预构建 BLAS 即可。这使得 LOD 切换对于光追来说几乎是零开销的。
动态几何体的光线追踪处理:BLAS 的更新与构建
本节聚焦于在光线追踪中处理 动态网格(Dynamic Meshes) 所面临的挑战和解决方案,核心在于如何管理它们的 底层加速结构(BLAS)。
一、 动态网格与静态网格的核心区别
-
静态网格 (Static Meshes):
- 顶点位置固定不变。
- 优化方式:可以通过预先为不同 LOD (Level of Detail) 等级构建多个 BLAS,在运行时根据需要选择一个,从而避免重复构建。
-
动态网格 (Dynamic Meshes):
- 顶点位置在运行时会发生变化(例如,角色动画、程序化植被)。
- 核心挑战:由于顶点数据已改变,原有的 BLAS 失效,必须在每帧或顶点变化时 更新(Update)或重建(Rebuild)BLAS。
二、 动态顶点数据的来源
为了更新或重建 BLAS,我们首先需要获取物体在当前帧的最终顶点位置。讲座中提到了两种主要的数据来源:
-
蒙皮网格 (Skinned Meshes):
- 来源: 依赖一个名为 Skin Cache 的系统。
- 工作流: 该系统会计算当前帧蒙皮动画后的最终顶点位置,并将其缓存到一个缓冲区中。这个缓冲区不仅用于常规光栅化渲染,也可以被直接用于 BLAS 的更新/重建。
-
材质驱动的顶点动画 (Vertex Animation in Materials):
- 应用场景: 常见于水面、风吹动的植被等效果。
- 工作流: 运行一个 Compute Shader,它会根据特定算法(如噪声函数、正弦波等)计算出当前帧的顶点位置,并将结果写入一个专门的顶点缓冲区。
三、 性能与内存开销的挑战与优化
处理动态网格的开销非常巨大,主要体现在 GPU 时间和显存占用两个方面。
-
核心开销点:
- 一对一关系: 每一个动态网格实例都需要一个独立的 BLAS 以及一个对应的顶点数据缓冲区。
- 显存剧增: 当场景中存在大量动态实例(如众多蒙皮角色)时,这些 BLAS 和顶点缓冲区会迅速消耗 数百兆字节(hundreds of megabytes) 的显存。
-
优化策略:
-
针对 GPU 时间开销(Time Cost):
- 异步计算 (Async Compute): 将 BLAS 的更新/重建任务放到异步计算队列上执行,使其与其他渲染任务并行,从而隐藏部分性能开销。
- 分帧更新预算 (Per-Frame Update Budget): 每帧只更新有限数量的加速结构,将总开销摊平到多个帧上,避免单帧性能尖峰。
-
针对显存开销(Memory Cost):
- 局限性: 上述的异步计算和分帧更新无法解决显存占用问题。
- 有效方案: 采用 激进的 LOD 策略 (Aggressive LODs)。这是《黑客帝国:觉醒》演示中采用的关键技术。
- 原理: 在光线追踪场景中,为动态网格使用更低精度的 LOD。更少的顶点意味着:
- 更小的顶点缓冲区,直接降低显存占用。
- 更小的 BLAS,进一步减少显存。
- 更快的 BLAS 更新/重建速度,降低了 GPU 时间开销。
-
光线追踪加速结构(BLAS)的构建策略:运行时 vs. 离线
本节内容聚焦于游戏引擎中构建底层加速结构(Bottom-Level Acceleration Structure, BLAS)的两种主流策略:PC 平台的运行时构建和主机平台的离线构建。两者在性能开销、内存管理和实现复杂度上各有取舍。
PC 平台:运行时构建 (Runtime Build) 策略
在 PC 平台上,由于硬件和驱动的多样性,通常采用在程序运行时动态构建 BLAS 的方案。这种方案虽然灵活,但带来了显著的性能挑战。
- 这是最常见的方法,尤其是在 PC 平台上。
- 关键信息: 在 PC 平台上,这是当前唯一的选择。这意味着所有 BLAS,无论是静态还是动态,都必须在程序运行时通过驱动 API 进行构建。
核心挑战与解决方案
-
核心挑战:显著的 GPU 开销
- 在运行时构建 BLAS 是一项计算密集型任务,会消耗大量 GPU 资源。
- 这个问题在 流式加载(Streaming) 新模型进入场景时尤为突出,可能会导致游戏帧率剧烈波动。
-
解决方案:基于预算的构建调度系统
- 引入构建预算(Build Budget):为避免单帧负载过高,限制每帧可以构建的 BLAS 数量。
- 采用基于三角形数量的预算:
- 问题:不同模型的复杂度千差万别,直接限制“BLAS 构建个数”会导致每帧的实际 GPU 负载非常不稳定(一个复杂的 BLAS 可能远超十个简单的 BLAS)。
- 优化:将预算单位从“BLAS 个数”改为 “三角形面片数量”(Number of Triangles)。这能更好地估算和控制每帧的构建开销,使其更加平滑和可预测。
- 构建请求优先级队列(Priority Queue):
- 允许开发者为不同的构建请求指定用户自定义的优先级,确保重要或急需的模型(如玩家视野内的)能被优先处理。
- 优先级提升机制(Priority Aging):
- 为了防止低优先级的请求被无限期延迟(Starvation),系统会 周期性地提升被跳过(Skipped)的构建请求的优先级。
运行时 BVH 紧凑化 (Runtime BVH Compaction)
为了进一步优化显存占用,引擎通常会对静态网格的 BVH 进行紧凑化处理。
目的与挑战
- 核心目的:对静态网格的 BVH 进行紧凑化,可以显著节省显存。
- 挑战 1:峰值显存占用
- 紧凑化操作本质上是 将 BVH 数据从一个 Buffer 拷贝到另一个更小的 Buffer。
- 这意味着在拷贝完成前, 原始 BVH 和紧凑后 BVH 的数据需要同时存在于显存中,导致短暂的显存占用峰值。
- 挑战 2:高延迟
- 为了知道紧凑后的 BVH 需要多大空间,必须先从 GPU 回读(Readback) 构建后生成的实际大小信息,这是一个高延迟的同步操作。
解决方案与延迟隐藏
- 限制并行命令数量:类似于 BLAS 构建,通过 限制同时进行的(In-flight)紧凑化命令数量 来控制峰值显存占用。
- 异步处理与延迟隐藏:这是一个关键的优化技巧。
- 核心思想:在紧凑化操作完成之前, 渲染时继续使用未紧凑的、较大的原始 BLAS。
- 流程:
- BLAS 构建完成。
- 立即开始使用这个(未紧凑的)BLAS 进行渲染。
- 同时,在后台发起 BVH 紧凑化命令。
- 当紧凑化完成后,再将渲染切换到使用这个新的、紧凑的 BLAS。
- 效果:通过这种方式,流式加载的延迟被有效隐藏,避免了模型因为等待紧凑化完成而无法被立即渲染的问题。
主机平台:离线构建 (Offline Build) 策略
主机平台(Consoles)由于其硬件环境统一固定,提供了更优的选项。
-
核心思路: 完全离线(Offline)预先构建好所有 BLAS。
- 在游戏打包阶段,利用强大的构建服务器将所有模型的 BLAS 计算完毕。
- 将构建好的 BLAS 作为一种普通的二进制资源(Asset) 保存下来。
-
运行时流程:
- 在游戏运行时, 像加载贴图、模型数据一样,直接将预计算好的 BLAS 数据流式加载到显存中 即可使用。
-
主要优势:
- 完全消除了运行时的 GPU 构建开销。
- 避免了所有与运行时构建相关的复杂问题,如预算控制、优先级调度、峰值内存管理和延迟隐藏等。
- 实现了更低的运行时负载和更简洁高效的流式加载管线。
BVH 构建与优化的离线与实时策略
静态几何体的离线 BVH 构建 (Offline BVH Building)
对于场景中不会改变的静态几何体,采用完全离线预计算的方式来生成其加速结构(BLAS/BVH),并在运行时像加载其他资源(如纹理、模型)一样将其流式加载到内存中。
核心观点
将 BVH 的构建从运行时转移到离线预处理阶段,可以显著提升运行时性能、BVH 质量和可控性。
主要优势
-
节省运行时 GPU 开销:
- 最直接的好处是 免除了在运行时构建和压缩 BVH 所需的 GPU 时间。
- 在游戏加载或场景流式传输(Streaming)等性能敏感时期,可以直接将预计算好的 BVH 数据拷贝到指定显存位置,而非消耗宝贵的 GPU 周期进行实时构建。
-
生成更高质量的 BVH:
- 离线构建在 CPU 上进行,对构建时间的容忍度远高于运行时。
- 这允许使用 更复杂、更先进的 BVH 构建算法 (Sophisticated BVH Builders),这些算法通常因为计算成本过高而无法在运行时使用。
- 更高质量的 BVH 会直接带来两个好处:
- 提升光线追踪性能:更优化的节点划分可以减少光线与包围盒的相交测试次数。
- 减小 BVH 体积:更紧凑的 BVH 结构占用更少的显存。
-
对 BVH 特性有更强的控制力:
- 开发者可以精细调整构建参数,以在追踪性能和 BVH 显存占用 之间进行权衡。
- 实践案例 (The Matrix Awakens):
- 在该项目中,降低显存占用的优先级高于极致的光线追踪性能。
- 团队通过调整构建算法中的 分割因子 (split factor) 等参数,找到了一个平衡点,使得离线构建的 BVH 在保持与运行时构建相当的追踪性能的同时,实现了最低的显存占用。
动态几何体的实时 BVH 优化
对于场景中需要移动、变形的动态几何体,其 BVH 必须在运行时进行更新(Update)或重建(Rebuild),这可能带来巨大的性能开销。
核心观点
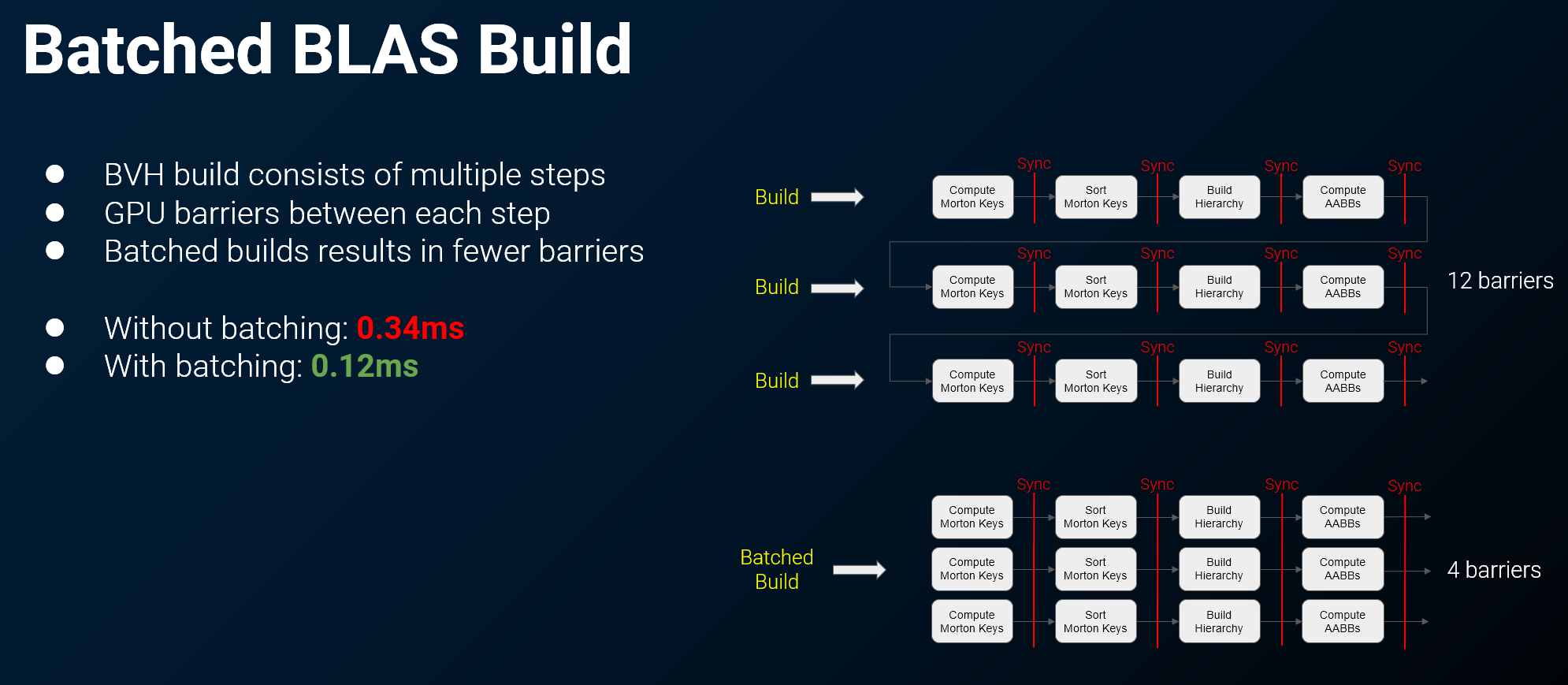
通过批处理(Batching)多个动态物体的 BVH 构建与更新请求,可以摊销 GPU 同步开销,显著提升性能,尤其是在处理大量小型动态网格体时。
技术原理与优化方法
-
问题的根源:GPU 同步开销
- 在底层,一个 BVH 的构建过程并非原子操作,而是由多个独立的计算步骤组成。
- 在这些步骤之间,需要插入 GPU 屏障 (GPU Barriers) 来确保前一步操作的计算结果对后一步可见,从而保证数据同步的正确性。
-
低效的逐一构建方式:
- 如果为每一个动态物体单独提交一个 BVH 构建请求,那么每个请求都会触发一系列带有屏障的 GPU 操作。
- 这将导致大量的 GPU 屏障,使得 GPU 在大部分时间里处于等待状态(Stall),无法被充分利用,造成严重的性能瓶颈。
-
高效的批处理方案 (Batching BAS Builds and Updates):
- 核心思想: 将多个物体的 BVH 构建/更新请求组合成一个大的批次进行提交。
- 执行流程:
- GPU 首先为批次中所有的 BVH 执行构建过程的第 1 步。
- 然后,插入一次屏障。
- 接着,为批次中所有的 BVH 执行第 2 步。
- ...依此类推。
- 通过这种方式,原本需要在每个 BVH 的每个步骤间都插入的屏障,现在变成了在整个批次的每个步骤间插入一次。屏障的成本被有效摊销,极大地减少了 GPU 的等待时间,提高了并行处理效率。
- 这种方法在有大量小型动态网格体的场景中尤其有效,是达成性能目标的关键技术。
核心议题:光线追踪加速结构与 Nanite 几何体的挑战
本节内容分为两个主要部分:首先,对上一节提到的加速结构更新流程进行性能优化总结;其次,深入探讨了在虚幻引擎5中,光线追踪其核心的 Nanite 虚拟化几何体系统所面临的巨大挑战及当前的解决方案。
加速结构更新的并行优化
这部分是对之前讨论的加速结构更新流程的一个性能补充。
-
核心观点: 通过并行处理多个 BLAS (Bottom-Level Acceleration Structure) 的更新,可以显著降低总体的更新耗时。
-
关键技术:并发更新 (Concurrent Updates)
- 传统的串行方法是逐个更新 BLAS,每次更新都需要同步等待,产生多次开销。
- 优化后的方法将多个 BLAS 的更新步骤打包在一起, 让它们可以同时在 GPU 上执行。
- 这种方法的优势在于,整个批次的更新只需要支付 一次同步屏障成本 (Barrier Cost),而不是为每个 BLAS 单独支付。
-
性能收益:
- 在《黑客帝国:觉醒》技术演示中,该优化使得更新加速结构的时间减少了近三分之一,效果非常显著。
核心挑战:光线追踪 Nanite 几何体
这是UE5中一个重大的开放性问题。直接对 Nanite 几何体进行光线追踪存在一系列根本性的技术障碍。
Nanite 技术背景
- 核心定义: Nanite 是 UE5 的 虚拟化几何体系统 (Virtualized Geometry System)。
- 核心能力: 能够以实时帧率渲染包含数万亿个三角形的超高精度场景。
光追 Nanite 的三大挑战
直接将 Nanite 的数据结构用于构建光追所需的 BLAS 是不现实的,主要原因如下:
-
挑战一:极高的顶点数量 (Extremely High Vertex Counts)
- 问题描述: Nanite 设计初衷就是为了处理海量几何数据。如果直接为这些数据构建 BLAS,将导致难以承受的内存消耗和性能问题。
- 直接后果:
- BLAS 内存占用:单个网格的 BLAS 可能就需要数百兆的显存。
- 追踪性能:在如此庞大的几何结构中进行遍历,光线追踪的效率会急剧下降。
-
挑战二:专有的高度压缩数据格式 (Proprietary Compressed Data Format)
- 问题描述: Nanite 为了效率,在内存中以一种高度压缩的自定义格式存储顶点数据,并在光栅化渲染时 即时解压 (On-the-fly Decompression)。
- 直接后果:
- 光追 BLAS 的构建需要访问原始、完整的顶点数据。这意味着必须 将 Nanite 数据完全解压 到一个独立的缓冲区中。
- 更糟糕的是,为了让 Hit Shader 能够访问和获取命中点的三角形详细信息(如纹理坐标、法线等),这个解压后的 独立缓冲区必须在 BLAS 构建完成后持续驻留在内存中,这违背了 Nanite 节省内存的初衷。
-
挑战三:动态数据流送 (Dynamic Data Streaming)
- 问题描述: Nanite 的一个核心特性是根据视点动态地 流式加载和卸载 (Stream in and out) 顶点数据。
- 直接后果:
- 几何体的拓扑结构在不断变化。这意味着每当有新的顶点数据流入或流出时,对应的 BLAS 就可能需要完全重建 (Rebuild),这会带来巨大的、持续的计算开销。
当前的临时解决方案:回退网格 (Fallback Meshes)
由于直接光追 Nanite 存在上述障碍,目前的做法是采用一种妥协方案。
-
核心思想: 在光线追踪场景中,不使用原始的 Nanite 网格,而是使用一个为其自动生成的简化版本,即 回退网格 (Fallback Meshes)。
-
工作流程:
- 为每个 Nanite 物体生成一个或多个传统格式的、面数较低的静态网格作为其在光追世界中的“替身”。
- 光线追踪相关的计算(如 BLAS 构建、光线相交测试)都发生在这个简化网格上。
-
引入的新问题:内存压力加剧
- 这种方法虽然可行,但代价是更高的内存占用。对于同一个物体,显存中现在需要同时存储:
- 用于光栅化的 原始压缩 Nanite 数据。
- 用于光追的回退网格的顶点和索引缓冲区(这部分数据在 BLAS 构建后仍需保留,供 Hit Shader 使用)。
- 由回退网格生成的 BLAS 数据结构本身。
- 这种方法虽然可行,但代价是更高的内存占用。对于同一个物体,显存中现在需要同时存储:
-
实践中的权衡:
- 为了在渲染质量和内存开销之间取得平衡,系统通常会使用 两种不同精度的回退 LOD (Fallback LODs),根据距离或其他因素选择合适的简化版本。
Lumen 光线追踪优化:几何管理与着色器管线问题
这份笔记聚焦于《黑客帝国觉醒》Demo 中 Lumen 系统为实现高性能光线追踪所采用的几何管理策略,并深入剖析了当时传统光线追踪着色器管线(Shader Pipeline)所面临的性能瓶颈。
光线追踪的几何细节管理 (LOD & Streaming)
为了在保证渲染质量的同时控制巨大的内存开销,Lumen 采用了一套专为光线追踪设计的 LOD(Level of Detail)和流式加载(Streaming)策略。
-
核心观点: 光线追踪使用的几何体 LOD 是独立的,其流式加载完全由顶层加速结构(TAS)的需求驱动,以实现内存的极致优化。
-
关键策略:两级回退LOD (Two Fallback LODs)
- LOD1: 这是一个质量较低的网格版本,始终被流式加载并保留在内存中。它的作用是确保光线总能命中一个有效的几何体,作为保底方案。
- LOD0: 这是最高精度的网格版本,根据需求动态地换入换出内存。
-
LOD0 流式加载的触发条件:
- 该网格必须被 TAS (Top-level Acceleration Structure) 所引用。这意味着它在当前的渲染场景中是可见或可能相关的。
- 加载它不会超出预设的 流式加载预算 (Streaming Budget)。
这种策略确保了只有在场景需要且内存允许的情况下,最高精度的几何体才会被加载,从而在开放世界级别的场景中有效平衡了视觉质量与内存占用。
传统光追管线的性能瓶颈
在《黑客帝国觉醒》Demo 中,Lumen 大量使用 Surface Cache 来缓存和复用复杂的材质计算结果。这使得光线追踪本身的任务被大大简化。
-
核心观点: 即便光线追踪的着色器(Hit Shader)逻辑极简,传统的管线模型也会因为“最坏情况资源分配”机制而导致性能问题,尤其是影响 GPU 的占用率(Occupancy)。
-
Lumen 的极简命中设置 (Hit Setup)
- Hit Shader 的职责: 由于材质计算由 Surface Cache 完成,命中着色器(Hit Shader)的工作变得非常简单:仅仅返回 材质ID (Material ID) 和 几何法线 (Geometry Normal)。
- 统一的命中组 (Hit Group): 场景中所有的网格都共用同一个极简的命中组。
- 理论上,这种配置应该无限接近光线追踪的 “光速” (即最快速度)。
-
发现的性能瓶颈:寄存器分配问题
- 问题根源: 驱动程序在设置光追管线时,会分析管线中所有的着色器(包括 Ray Generation, Hit, Miss 等),并根据其中 资源消耗最严重(Worst-Case) 的那个来统一分配寄存器(如 VGPR)。
- 连锁效应:
- 高 VGPR 拖累全局: 如果管线中有一个非常复杂的 光线生成着色器 (Ray Generation Shader, RGS),它会需要大量寄存器。驱动程序会为整个管线的所有阶段都预留出同样多的寄存器,这极大地浪费了资源,并直接影响到简单的 Hit Shader。
- 相互影响: 不仅 RGS 会影响 Hit Shader,反之亦然。并且,如果管线中包含多个用于不同技术的 RGS,它们之间也会相互影响。
- 降低 GPU 占用率 (Occupancy): 过高的寄存器分配意味着每个着色器核心(SM/CU)能同时驻留和执行的线程束(Warps/Wavefronts)数量减少,导致 GPU 的并行处理能力下降,即占用率降低,从而影响整体性能。
-
重要提示:
- 演讲者特别强调,这些发现是基于《黑客帝国觉醒》开发和发布时 较旧的 SDK 版本。光线追踪技术仍在快速发展,当前的情况可能已有改善。
- 关键启示: 在设计光追管线时,应避免将资源需求差异巨大的着色器(或不再使用的着色器)放在同一个管线状态对象(PSO)中,以防止性能“短板效应”。
光线追踪管线的性能陷阱与优化
Shader复杂性与GPU占用率 (Shader Complexity and GPU Occupancy)
- 核心观点: 在同一个 光线追踪管线(Ray Tracing Pipeline) 中包含未使用或功能差异巨大的着色器,会在运行时 降低GPU的占用率(Occupancy),从而影响性能。
- 占用率可以理解为GPU的硬件计算单元被有效利用的程度。当一个管线需要为多种复杂但当前并未全部使用的Shader预留资源时,能够同时在GPU上运行的线程束(Wavefronts/Warps)就会减少,导致硬件闲置。
- 关键术语:
- 占用率 (Occupancy): 衡量GPU计算资源在某一时刻被活跃线程束利用效率的指标。
- 命中组 (Hit Groups): 在光线追踪中,与特定几何体相交时需要执行的一组着色器(如Any-Hit, Closest-Hit, Intersection Shader)。
- 主机平台优化: 在主机(如Xbox)上,可以利用 编译器提示(Compiler Hints) 来指导编译器如何组织和优化命中组,以缓解上述问题。
“隐藏”的遍历着色器与VGPR压力 (The "Hidden" Traversal Shader and VGPR Pressure)
- 核心观点: BVH(层次包围盒)的遍历过程本身也是由一个特殊的 遍历着色器(Traversal Shader) 执行的,它的性能同样会受到 VGPR(向量通用寄存器) 使用量的严重影响。
- 关键术语:
- 遍历着色器 (Traversal Shader): 一个特殊的、通常由驱动或硬件实现的着色器,负责执行 BVH遍历的核心循环逻辑。它在不同的平台上可能被实现为常规的计算着色器,或被 内联(Inlined) 到主着色器中。
- VGPR (Vector General-Purpose Registers): GPU线程用于存储局部变量和计算中间值的寄存器。
- 性能瓶颈分析:
- 过高的VGPR占用 会导致GPU上能够同时运行的 波前(Wavefronts)数量减少。
- 更少的波前意味着更少的活跃线程(Lanes)能同时参与BVH遍历,最终显著拖慢整体光线追踪的速度。
针对VGPR问题的平台特定解决方案
这是一个典型的、需要根据不同硬件架构采取不同优化策略的例子。
-
Xbox的解决方案:专用状态对象 (Specialized State Objects)
- 核心思想: 将一个庞大、复杂的“大一统”光线追踪管线,根据 光线生成着色器(Ray Generation Shader)的VGPR使用情况,在内部 分解成多个小型的、特化版本的光线追踪管线。
- 运行机制: 在运行时,系统会根据当前负载动态选择与需求最匹配的那个特化管线。这避免了因为某个高VGPR需求的Shader而导致整个管线始终承担高昂的占用率损失。
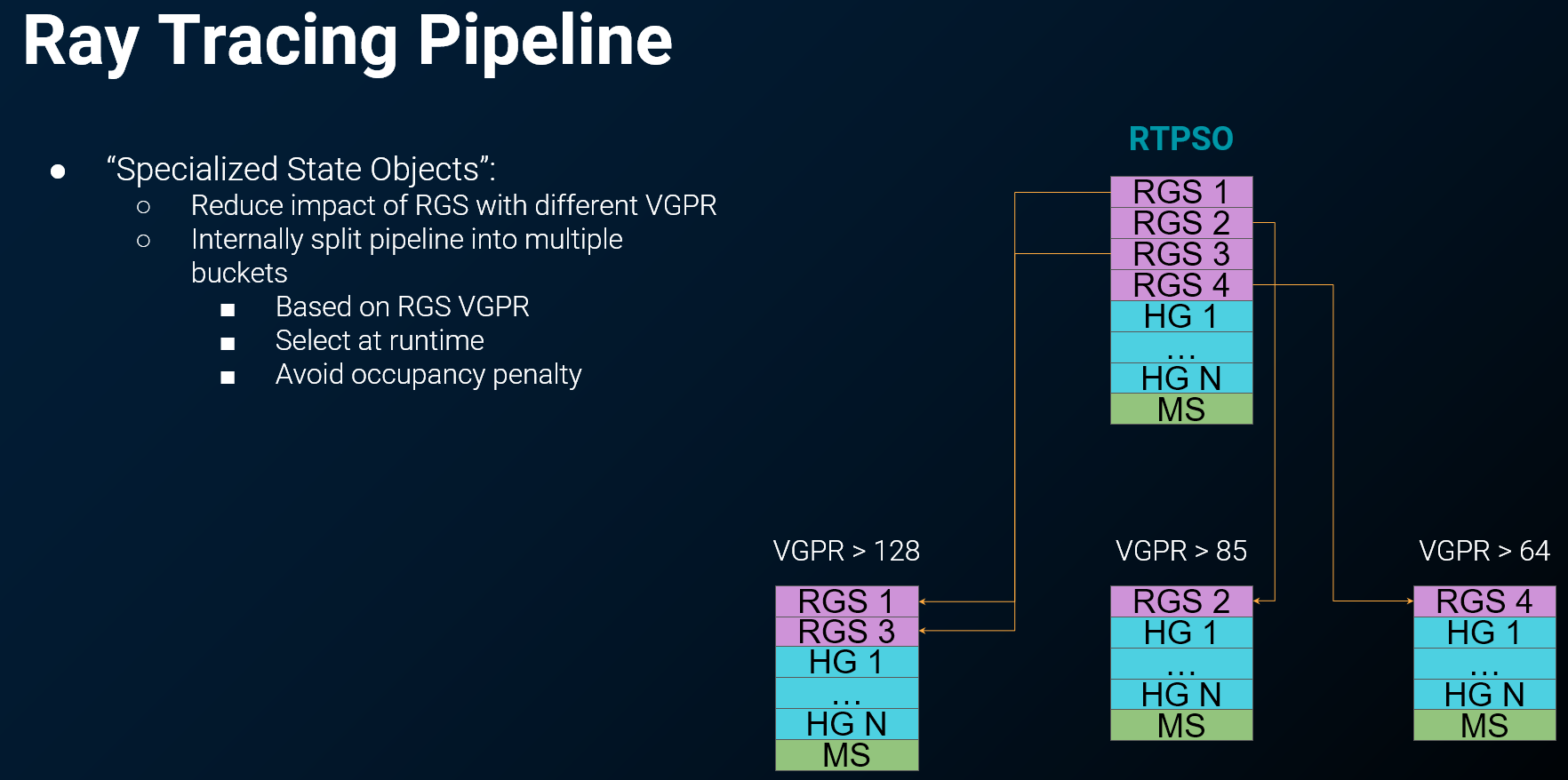
-
PS5的架构差异 (Architectural Difference on PS5)
- 核心思想: PS5上不需要这种特化方案。其架构中没有统一的“光线追踪管线”对象概念。
- 运行机制: 每个光追相关的着色器(如RayGen, Miss, Hit Shader)本质上都是一个 资源分配已知的、独立的计算着色器(Compute Shader)。这种设计从根本上避免了因在同一管线内混合不同资源需求的着色器而引发的VGPR占用率问题。
着色器调用的开销:内联的重要性 (The Overhead of Shader Calls: The Importance of Inlining)
- 核心观点: 即便管线中只有一个命中着色器(Hit Shader),如果编译器未能将其内联(Inline),系统依然会启用完整的着色器调用机制,这对性能会产生巨大的负面影响。
- 根本原因: GPU为了支持在不同着色器之间切换(例如从RayGen调用Hit Shader),需要 模拟一个函数调用栈(Function Call Stack)。这个过程会带来显著的性能开销,通常包括以下步骤:
- 保存当前着色器的执行状态(寄存器等)。
- 切换并执行被调用的着色器。
- 被调用者执行完毕后,恢复原始着色器的状态。
- 继续原始着色器的执行。
- 关键启示: 尽可能促使编译器内联光线追踪中的着色器调用是至关重要的性能优化手段。避免非必要的着色器切换可以节省大量的状态保存与恢复开销。
光线追踪中的状态管理与性能开销
本节内容深入探讨了传统 TraceRay 调用在硬件层面所带来的性能开销,即状态保存与恢复的成本,并介绍了 DXR 1.1 中引入的 内联光线追踪 (Inline Ray Tracing) 作为一种高效的替代方案。
一、 TraceRay 调用的状态保存与恢复开销
核心观点:
传统的 TraceRay 调用在GPU上并非一个简单的函数调用,它更像是一次“上下文切换”。为了执行命中组(Hit Group)中的着色器(如 Any-Hit、Closest-Hit),GPU必须中断当前着色器(如 Ray Generation Shader)的执行,保存其完整状态,执行命中逻辑,然后再恢复状态继续执行,这个过程会产生巨大的开销。
-
编译器的行为:
- 当编译器遇到
TraceRay指令时,它会将调用方的着色器(如 Raygen Shader)分割成两部分:TraceRay调用前的代码和调用后的代码。 - 为了实现这次“切换”,编译器会生成大量额外的指令,用于保存和恢复当前着色器的状态(例如,寄存器中的变量)。
- 当编译器遇到
-
不同硬件平台的状态管理:
- Xbox: 状态被保存到 暂存内存 (scratch memory) 中。
- PS5: 提供了更高的灵活性,允许开发者将状态溢出(spill)到 LDS (Local Data Share) 、 暂存内存 (scratch memory),或者继续保留在 寄存器 (registers) 中,并且可以为不同类型的存储分别指定溢出量。
- AMD: 通常将状态保存到 LDS 中。
- 其他硬件厂商的实现方式可能各不相同。
-
性能开销的量化分析:
- 这是一个简化的性能预算示例,揭示了问题的严重性:
- 假设性能目标是 10 Gigarays/s (每秒100亿条光线)。
- 假设主机(如 Xbox)的内存带宽为 500 GB/s。
- 那么每条光线平均的带宽预算为:
500 GB/s / 10 Grays/s =50 字节/光线。
- 关键问题在于,这 50字节 的微小预算必须包含所有操作:缓冲区、纹理、UAV的读写,以及光线状态的保存和加载。
- 结论:如果不加控制, 保存和恢复光线状态的开销可以轻易地主导 (dominate) 所有其他操作,成为主要的性能瓶颈。
- 这是一个简化的性能预算示例,揭示了问题的严重性:
二、 内联光线追踪 (Inline Ray Tracing) 作为解决方案
核心观点: 内联光线追踪 (Inline Ray Tracing) 是 DXR 1.1 引入的一种替代方案,它将遍历逻辑直接嵌入到调用方着色器中,避免了独立的着色器和状态切换,从而给予编译器更大的优化空间。
-
工作机制:
- 它不使用独立的着色器(如
ClosestHit等),所有的着色逻辑都由调用方着色器(Caller Shader)自己处理。 - 光线遍历的代码被 内联 (inlined) 到调用方着色器中。
- 如果需要模拟不同材质的行为(原本由不同的命中组处理),开发者需要在调用方着色器内部使用
switch语句 或类似的分支逻辑来手动实现。
- 它不使用独立的着色器(如
-
优势与权衡:
- 主要优势: 由于所有代码(遍历、求交、着色)都在一个着色器内,整个着色器代码对编译器完全可见。这为编译器提供了巨大的优化机会,例如更高效的寄存器分配和指令调度。
- 权衡: 需要开发者手动管理着色逻辑,代码结构可能比使用独立命中组更复杂。
-
适用场景 (Lumen 示例):
- 非常适合: Lumen 中对 Surface Cache 进行采样的光线追踪过程。因为这些过程通常只使用 一个命中组 (one hit group),逻辑相对简单统一,非常适合内联化以追求极致性能。
- 不太适合: 需要进行复杂 材质评估 (material evaluation) 的过程,例如 光线追踪阴影 (ray-traced shadows)。因为不同的物体材质可能需要执行截然不同的着色器代码(如处理透明、次表面散射等),使用传统的、分离的命中组着色器模式在代码管理上更为清晰和高效。
UE 光线追踪优化:内联光线追踪(Inline Ray Tracing)的实践
本节内容深入探讨了 Unreal Engine 中 Lumen 系统采用 内联光线追踪(Inline Ray Tracing / Ray Query) 替代传统光线追踪管线(Ray Tracing Pipeline)所带来的性能优势,并详细解析了其在不同平台上的实现细节与挑战。
一、 性能优势:为何选择内联光线追踪?
对于某些需要材质评估的追踪(如光线追踪阴影),传统的管线模式并非最优。内联光线追踪在此类场景下展现出明显的性能优势。
-
核心对比: 将传统的光线生成着色器(Raygen Shader)与单一命中组(Hit Group)的模式,替换为内联光线追踪。
-
性能提升:
- 所有使用内联光线追踪的渲染通道(Passes)都运行得更快,并实现了 更高的硬件占用率(Occupancy)。
- 实例数据(《黑客帝国:觉醒》Demo): 在 Xbox 平台上,采用内联光线追踪平均节省了 0.5ms 的渲染时间,在最复杂的场景中最多可节省 2ms。
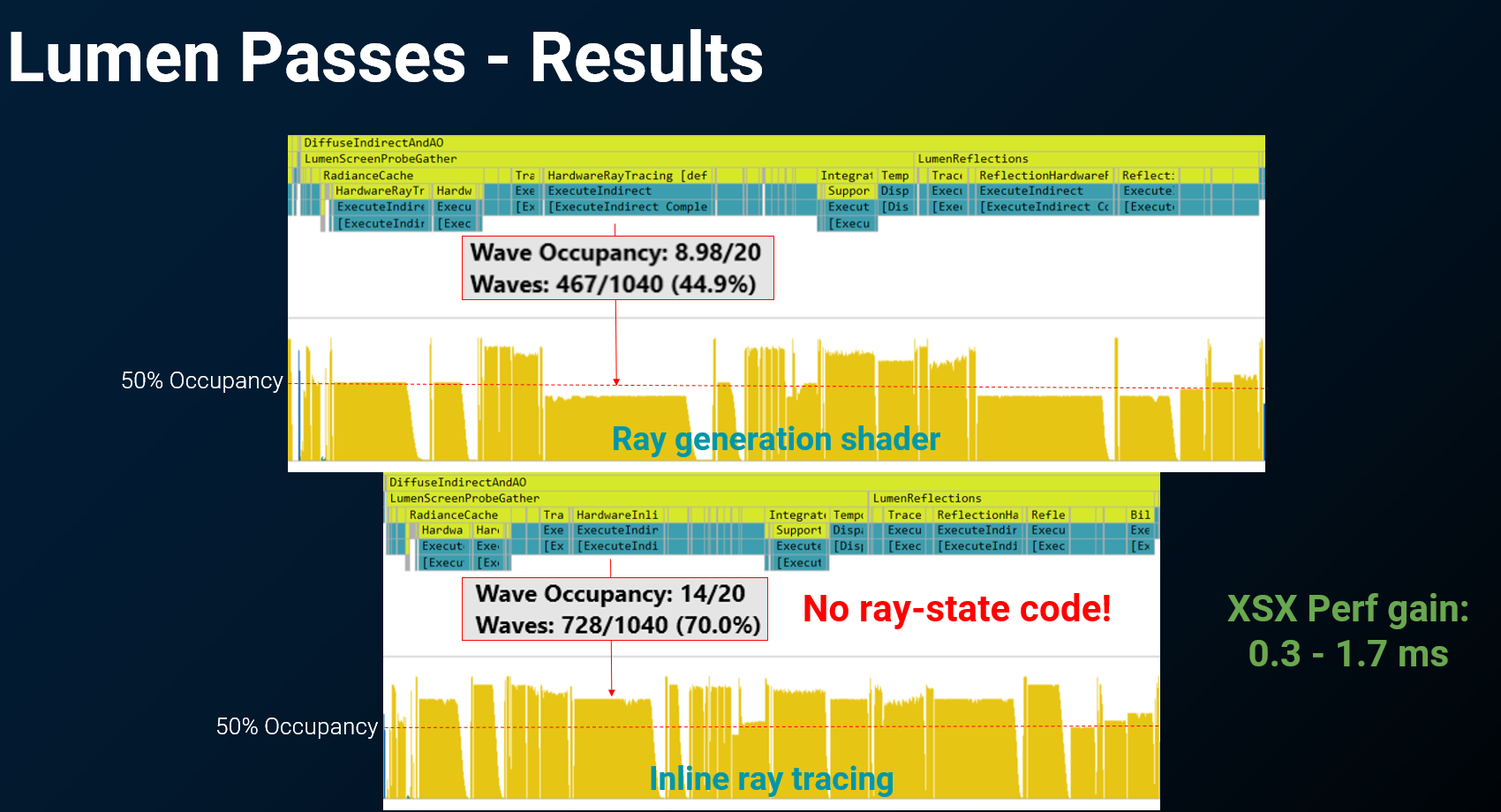
-
性能根源:
- 性能提升的主要原因是移除了传统光追管线中复杂的 状态保存与恢复(save and restore)代码。
- 这直接导致了 VGPR(向量通用寄存器)使用量的显著降低,减轻了寄存器压力,从而提高了着色器的执行效率。
二、 实现细节与平台差异
在 Unreal Engine 中,为了获取光线命中点的几何信息(尤其是法线)以用于 Surface Cache 光照计算,需要访问顶点和索引数据。不同平台采用了不同的实现策略。
-
UE 的抽象层:
- 引擎并未直接暴露底层的
RayQuery对象。 - 而是提供了一个类似于
TraceRay的通用函数,该函数直接返回 遍历结果(traversal results),其数据内容与从RayQuery对象中获取的信息相似。
- 引擎并未直接暴露底层的
-
获取几何法线的挑战与解决方案:
- 通用方法: 通过 Bindless 或 着色器绑定表(Shader Binding Tables, SBT) 绑定顶点/索引缓冲区,然后在着色器中重建法线。
- 主机(Consoles)平台:
- 优势: 无需 Bindless 或 SBT。
- 实现: 主机平台的图形 API 提供了 硬件内置函数(Intrinsics),可以直接在光线命中点查询到几何法线,极大简化了流程并提升了效率。
- PC (DXR) 平台:
- 挑战: 缺少直接获取法线的硬件内置函数,因此 必须依赖 Bindless 技术 来访问几何数据。
- 现状: 由于当时 UE 的 Bindless 支持仍在开发中,PC 上的 DXR 版本尚不支持内联光线追踪,仍然沿用传统的光线追踪管线。
- PC (Vulkan) 平台:
- 挑战: 同样面临引擎层面 Bindless 支持不完善的问题。
- 巧妙的变通方案 (Workaround):
- 将场景中所有顶点和索引缓冲区的 GPU 地址(GPU addresses) 存储到一个单独的 Buffer 中。
- 在 HLSL 着色器代码中,利用 SPIR-V 的内置函数(intrinsic),通过这些 GPU 地址直接在内存中访问所需的顶点和索引数据。
- 这个方法绕过了对完整 Bindless 资源系统的依赖,成功在 Vulkan 上实现了高性能的内联光线追踪。
高级HLSL光追特性与光线遍历的挑战
本节内容主要分为两部分:首先介绍了现代HLSL为光线追踪带来的高级特性,特别是通过模板实现的灵活回调机制;其次,深入探讨了光线遍历中的核心性能瓶颈—— 光线相干性(Ray Coherence),并分析了其在主机平台上的特殊挑战。
HLSL新标准带来的灵活性与高级用法
为了给予开发者更大的控制权和灵活性,新的HLSL标准引入了若干强大的光线追踪相关特性。
-
1. 直接GPU地址访问 (Direct GPU Address Access)
- 核心观点:开发者现在可以在HLSL中,通过特定的内部函数(intrinsics),直接使用GPU地址来访问缓冲区。
- 关键技术:这通常与
SPV_KHR_ray_query等底层扩展相关,允许对数据进行更低层次、更高效的直接操作,绕过了一些传统的资源绑定抽象。
-
2. 基于回调的Any-Hit与Intersection
- 核心观点:借助HLSL中的 模板 (Templates) 支持,
TraceRayInline函数现在可以接受任意自定义的结构体作为光线负载(Payload),极大地增强了数据传递的灵活性。 - 实现机制:
- 开发者可以定义一个自定义的结构体,其中包含任意所需的数据。
- 该结构体需要实现特定的成员函数,如
OnAnyHit()(用于处理任意命中)和OnProceduralPrimitive()(用于处理程序化几何体相交)。 - 在光线遍历过程中,当发生相应的事件(如命中半透明表面)时,系统会自动调用这些回调函数。
- 应用实例:Lumen的半透明处理
- 一个包含所有上下文数据(如材质信息、光照参数等)的
context结构体被传递给光线追踪。 - 在
OnAnyHit回调中,着色器可以获取 命中组数据 (Hit Group Data)。 - 通过检查其中的 半透明标志位 (Translucency Flag),可以快速做出 接受 (accept) 或 拒绝 (reject) 此次命中的决策,这是实现高效半透明渲染和Alpha Test的关键优化。
- 一个包含所有上下文数据(如材质信息、光照参数等)的
- 核心观点:借助HLSL中的 模板 (Templates) 支持,
光线遍历 (Ray Traversal) 的性能瓶颈与挑战
光线遍历的效率直接决定了光线追踪的性能,而其中最大的挑战来自于管理光线的内存访问模式。
-
1. 光线相干性的重要性 (The Importance of Ray Coherence)
- 核心观点:光线遍历的性能瓶颈主要是 内存延迟 (Memory Latency)。保持一组光线(如一个Wave/Warp中的光线)的路径尽可能相似,即 相干性 (Coherence),是性能优化的关键。
- 原因分析:
- 相干的光线:倾向于访问相同的 BVH节点 和三角形数据,从而极大地提高缓存命中率,减少对显存的访问次数。
- 不相干的光线 (Incoherent Rays):每条光线的路径都大相径庭,会导致缓存颠簸(Cache Thrashing),每次内存访问都可能是Cache Miss,从而受限于内存带宽和延迟,性能急剧下降。
-
2. 维持相干性的核心挑战
- 巨大的遍历迭代差异:在复杂场景中,即使是起点和方向非常接近的两条光线,也可能因为碰到不同的几何体而导致其BVH遍历的迭代次数和路径差异巨大。
- 着色器内在的不相干性:某些渲染算法(例如多次弹射的全局光照、漫反射等)会自然地生成 发散且不相干 (Divergent and Incoherent) 的光线,这是算法层面上难以避免的问题。
-
3. 主机平台(Consoles)的特殊限制
- 核心观点:在主机平台上,BVH遍历并非由一个完整的、固定的硬件单元来执行,这导致硬件无法自动优化光线相干性。
- 具体实现:
- BVH遍历的主体逻辑是作为一个 常规的计算着色器 (Compute Shader) 来实现的。
- 只有底层的 AABB相交测试 和三角形相交测试是硬件加速的。
- 关键影响:由于遍历逻辑在软件层面(Compute Shader),硬件 不会自动对光线进行重排序 (Ray Reordering) 来将路径相似的光线组合在一起执行。这意味着优化光线相干性的责任完全落在了引擎和开发者的肩上,需要通过软件算法来管理和调度光线。
核心议题:硬件光线追踪中的“长尾问题”及其优化策略
在现代硬件加速的光线追踪中,一个显著的性能瓶颈是由于线程发散(Thread Divergence)导致的“长尾效应”(Long Tail Effect)。本节深入探讨了该问题的成因,并分析了两种潜在的解决方案。
问题的根源:硬件遍历模型的内在限制
-
光线与线程的生命周期绑定
- 核心观点: 在当前的硬件加速模型中,光线一旦被某个线程创建(spawned),其整个生命周期(包括后续的遍历和着色器调用)都将绑定在该初始线程上。
- 关键术语: 非重排光线 (Non-reordered Rays)。这意味着硬件不会为了提升执行效率(Coherence)而动态地重新排序或重新分配光线到其他线程。
-
串行化的“瀑布效应”
- 核心观点: 由于光线绑定在固定线程上,对不同着色器(Shader)的调用会产生一种“瀑布效应”。编译器会基于着色器表索引(Shader Table Index)或资源访问来进行标量化(Scalarize),但本质上仍是线程内的串行执行。
问题的表现:“长尾效应”与GPU资源浪费
-
波前(Wave)执行与同步等待
- 核心观点: GPU以“波前”(Wave/Warp)为单位执行线程。在光线遍历过程中,当一个波前中的大部分线程已经完成它们的遍历任务时,它们并不能立即开始新的工作。相反,它们会进入 非激活状态(inactive),整个波前必须等待其中最慢的那个线程完成。
- 关键术语: 长尾(Long Tails)。这种现象具体表现为,整个GPU可能都在等待极少数“掉队”的、需要进行大量迭代计算的线程。
-
极端情况下的性能影响
- 在复杂场景(如《黑客帝国觉醒》)中,这种长尾问题尤为严重。由于场景的几何复杂度和尺寸,不同光线的遍历迭代次数差异巨大。
- 在极端情况下, GPU等待这些慢线程所花费的时间,可能超过了其进行有效计算的时间,导致严重的资源浪费和性能瓶颈。
- 这是一个普遍问题,存在于所有主流平台,与使用
inline还是ray generation等着色器类型无关,是当前硬件遍历机制的一种固有产物。
探索解决方案
面对这一严峻挑战,讲座中探讨了两种主要的优化思路:
-
方案一:光线排序 (Ray Sorting)
- 核心思想: 在派发光线前,根据某种预测对其进行排序,目标是让计算复杂度相近的光线被分到同一个波前中,从而让波前内所有线程的完成时间趋于一致。
- 主要挑战:
- 排序开销 (Sorting Overhead): 排序本身会引入不可忽视的计算成本。
- 不可预测性 (Unpredictability): 这是最致命的缺陷。光线的遍历迭代次数对方向等初始参数极为敏感,一个微小的方向变化可能导致遍历迭代次数的巨大差异。因此,排序无法保证能有效解决问题。
-
方案二:利用时域信息进行调度 (Scheduling Using Temporal Information)
- 核心思想: 利用前一帧的性能数据作为启发式信息(Heuristics),来指导当前帧的光线任务调度。这是一种更具潜力的实用方法。
- 具体实现:
- 光线分组 (Group Rays): 将光线划分为若干组,而不是对单个光线进行追踪。
- 追踪迭代次数 (Track Iteration Count): 在第 N 帧,记录每个光线组中最大的遍历迭代次数。这个最大值可以作为该组光线“计算成本”的代理指标。
- 异步调度 (Asynchronous Scheduling): 在第 N+1 帧, 优先派发(Launch First)那些在前一帧中迭代次数最高的“最慢”光线组。
- 优势: 这种方法的目的不是让所有任务同时完成,而是通过“抢跑”让耗时最长的任务尽早开始执行。这样,它们的执行时间可以与其他GPU工作(包括其他较快的光线组)重叠,从而有效隐藏其高延迟,提升整体的GPU利用率和吞吐量。
核心主题:处理光线追踪中的长尾性能问题:迭代限制方案
本节探讨了解决光线追踪中因复杂场景导致部分光线遍历时间过长(即“长尾”问题)的几种策略,并重点分析了最终被采纳的迭代次数限制方案及其带来的挑战与解决方案。
问题的根源与备选方案
在光线追踪的BVH(层次包围盒)遍历中,某些光线的路径可能异常复杂,导致其计算耗时远超平均水平,形成性能瓶颈。为了消除这些“长尾”现象,团队评估了多种方案。
-
方案一:基于历史数据的调度
- 思路: 记录前一帧中耗时最长的光线组(slowest groups),在当前帧中优先启动它们,给予其更长的执行时间。
- 核心缺陷: BVH 的动态变化。由于场景中物体的移动,BVH结构在帧与帧之间会发生改变。这意味着,前一帧的“慢”光线在当前帧中可能不再是慢光线,导致预测失效。
-
方案二(最终采纳):设置遍历迭代次数上限
- 思路: 为BVH遍历循环设置一个固定的最大迭代次数。一旦达到此上限,无论是否找到最终命中点,都强制终止遍历。
- 核心优势: 这是唯一能保证消除性能长尾的方案。它通过硬性截断,确保没有任何一次光线遍历会无限时地执行下去。
- 核心缺陷: 牺牲了正确性。被中断的光线可能已经找到了一个命中点,但这个点 不保证是最近的命中点 (non-closest hit)。这违背了光线追踪的基本假设,并会引发视觉错误。
迭代限制方案的实现与副作用修复
尽管存在正确性问题,但由于其对性能的绝对保障,团队最终选择了迭代限制方案,并着手解决其带来的负面影响。
-
问题表现:光线泄露 (Light Leaking)
- 在Lumen中,由于提前终止遍历导致返回了错误的(非最近的)命中信息,尤其在立交桥下等复杂遮挡区域,出现了严重的光线泄露现象。光线“穿透”了本应阻挡它的物体。
-
解决方案:扩展光线查询的返回信息
- 为了修复光线泄露,光线查询(Traversal)函数不能只返回命中结果,还必须告知调用方遍历是如何结束的。
- 关键实现:
- 返回遍历完成状态: 在光线查询的返回值中增加一个布尔值或枚举,明确指出遍历是 正常完成 (finished) 还是因达到上限而被 中断 (interrupted)。
- 对中断的光线进行特殊处理: 如果光线遍历被中断:
- 系统依然将其视为一次“命中”。
- 但是,强制返回 零辐射度 (zero radiance),即黑色。
- 效果: 这种处理方式将潜在的“光线泄露”问题转化为了“过度遮挡 (over-occlusion)”问题。虽然仍是错误,但在视觉上,一个不该出现的黑点通常比一个不该出现的光斑更容易被接受。

迭代限制参数的权衡与挑战
引入迭代次数上限后,如何设定这个“上限值”本身成了一个新的、棘手的问题。
-
限制值过低 (Limit too low):
- 优点: 性能提升非常显著,能裁剪掉大量计算。
- 缺点: 产生大量不正确的命中,导致大面积的过度遮挡,画面变暗,细节丢失。
-
限制值过高 (Limit too high):
- 优点: 结果更精确,接近无限制时的正确结果。
- 缺点: 性能增益微乎其微,只有在最极端的长尾情况下才会生效,失去了该技术的初衷。
-
核心挑战: 不存在全局最优解。
- 最佳的迭代限制值是 高度场景和内容相关的 (highly scene and content specific)。一个在开阔场景中表现良好的值,在充满复杂几何体的室内场景中可能会导致严重的图像错误。为所有情况找到一个“通用”的完美限制值极其困难。
核心要点:射线追踪性能分析与优化实践
本节内容聚焦于两个关键的射线追踪性能优化方向:一是通过设定迭代上限来进行的宏观优化,二是通过分析射线一致性与遍历统计数据来进行的微观诊断与优化。
实践经验:限制遍历迭代次数 (Iteration Capping)
这是一种直接且有效的性能优化手段,但需要在性能与质量之间做出权衡。
-
核心权衡 (The Core Trade-off)
- 为射线遍历(Ray Traversal)设置一个硬性的迭代次数上限,可以有效防止射线在复杂场景中进行无休止的遍历,从而节省计算资源。
- 然而,这个上限的设定是 高度场景和内容相关的 (scene and content specific),很难找到一个适用于所有情况的“万能值”。
-
案例:《黑客帝国:觉醒》 (Case Study: The Matrix Awakens)
- 具体实践:在项目中,最终将遍历迭代上限设为 128次 (128 iterations)。
- 性能收益:这一简单的限制在主机平台上节省了大约 0.5毫秒 的渲染时间。
- 结论:这是一个在大多数情况下表现良好的 折中方案 (good middle ground),证明了在实际项目中,一个经过精心测试的经验值可以带来显著的性能提升。
深入分析:射线一致性与遍历统计 (Ray Coherence & Traversal Statistics)
管理射线一致性是提升GPU利用率的关键。为了有效地进行优化,我们需要精确的数据来指导决策。
管理射线一致性 (Managing Ray Coherence)
-
现有技术 (Available Techniques)
- 为了提高射线的一致性(即让一个Wave中的射线方向、起点尽可能接近),业界已经有多种技术,例如:
- 射线排序 (Ray Sorting)
- 分箱 (Binning)
- 紧缩 (Compacting)
- 为了提高射线的一致性(即让一个Wave中的射线方向、起点尽可能接近),业界已经有多种技术,例如:
-
核心挑战 (The Main Challenge)
- 这些技术的有效性严重依赖于 射线的发射方式 (how the rays are launched)。
- 不同技术产生的射线分布天然不同,例如 反射射线 (reflection rays) 、 辐照度探针射线 (irradiance probe rays) 或 碰撞射线 (collision rays) 的空间分布和方向性差异巨大。
- 发散的射线 (Divergent rays) 会导致一个Wave内的线程访问完全不同的数据,从而 增加带宽需求 (increase required bandwidth),降低缓存命中率。
利用遍历统计进行性能分析 (Using Traversal Statistics for Analysis)
-
优化思路:优化的最佳途径是 可视化并持续追踪射线的行为 (visualize and keep track of what rays are doing)。
-
实现方式:通过修改底层的遍历代码(讲座中提到他们有权限访问 主机遍历代码 (console traversal code)),可以导出任意想要的统计数据。
-
可量化的统计数据 (Quantifiable Statistics)
- 每次波次和每个线程的迭代次数 (per wave and per thread number of iterations)
- 用途:用于衡量 遍历迭代发散 (traversal iterations divergence),即一个Wave内的线程完成遍历所需的迭代次数是否相近。
- 每个射线相交的三角形和内部节点数 (number of triangles and internal nodes intersected)
- 用途:用于粗略估算 内存流量 (memory traffic),了解射线遍历过程中的数据访问压力。
- 每次波次和每个线程的迭代次数 (per wave and per thread number of iterations)
关键指标:占用率 (Occupancy)
这是一个非常实用的、用于衡量Wave内线程利用率的指标。
-
定义
- 占用率 (Occupancy) 指的是在一个 Wave 中 有多少线程正在活跃地执行遍历操作 (how many threads in a wave are actively doing traversal)。
- 该值是针对 所有迭代的平均值 (average over all iterations)。
-
工作原理与解读
- 初始状态:当一个完整的 Wave 开始执行遍历时,占用率为 100%。
- 动态变化:随着部分线程因为命中物体或错过所有物体而提前完成遍历,它们会进入非活跃状态。此时,仍在继续遍历的线程比例下降,导致 占用率随之降低。
- 分析价值:平均占用率可以直观地反映出 线程发散 (thread divergence) 的严重程度。一个较低的平均占用率意味着在遍历的后期,大量线程处于闲置状态,等待Wave中最“慢”的那个线程完成工作,这是GPU计算资源的巨大浪费。
核心主题:光线追踪性能分析与调试可视化
本节内容聚焦于两个在光线追踪开发中至关重要的实践领域:一是通过 占用率(Occupancy) 等统计数据来量化和分析GPU的利用率,二是通过引擎内置的调试可视化工具来直观地发现和定位问题。
通过占用率(Occupancy)分析光线追踪性能
核心观点: 占用率(Occupancy) 是衡量GPU线程利用率的关键指标。一个持续较低的占用率通常意味着GPU并行计算能力未被充分利用,可能存在性能瓶颈。
理解占用率(Occupancy)
- 定义:在本次讲座的语境下,占用率并非指调度器满载的静态理论值,而是指 在光线追踪任务完成前,所有迭代中活跃线程的平均比例。
- 动态变化:任务开始时,占用率可能是100%。但随着各个线程完成其追踪任务,活跃线程数减少,占用率会随之下降。我们关注的是整个过程的平均占用率。
低占用率的成因与诊断
低占用率可能由以下两种典型情况导致:
- 长尾问题 (Long-tail Scenario):大部分线程很快完成了它们的追踪任务,但少数线程因为要追踪更复杂或更长的光线而持续运行,导致最后阶段只有极少数线程在工作。
- 初始占用率低 (Low Initial Occupancy):由于某些条件限制,一个波次(Wave)中只有少量线程被激活去执行光线追踪,导致从一开始GPU的执行单元就处于闲置状态。
Lumen中的实际案例与权衡
- 问题:在Lumen中,一个计算直接光照的Pass(从Surface Cache中的tile发射光线)是有条件执行的。这导致许多线程根本不发射光线,造成了初始占用率低下的问题。
- 解决方案: 光线压缩(Ray Compacting)。将来自不同tile的需要追踪的光线“打包”到同一个波次中执行,以提高活跃线程的数量,从而提升占用率。
- 权衡(Trade-off):
- 优点:显著提高了GPU的占用率。
- 缺点:牺牲了 光线相干性(Coherence)。因为现在一个波次中的光线来自场景中不同的位置(不同的tile),它们在空间上不再相近。
- 负面影响:相干性降低意味着一个波次中的线程需要访问更多、更分散的 BVH节点 和三角形数据,增加了内存访问的压力和缓存未命中率。
关键启示:拥有追踪过程的统计数据(如占用率)对于诊断这类复杂性能问题至关重要。它能帮助开发者在并行利用率和 数据局部性(相干性) 之间做出明智的权衡。
运行时的调试可视化工具
核心观点: 尽管各硬件平台提供了强大的离线分析工具,但在引擎中内建实时的调试可视化模式对于快速迭代和问题定位是不可或缺的。
几何与加速结构可视化
这类工具主要用于验证几何数据和加速结构(AS)构建的正确性。
- 三角形与实例可视化模式 (Triangle and Instance Visualization):
- 功能:用不同的颜色渲染场景中的每个三角形或实例。
- 主要用途:快速发现因 顶点/索引缓冲区损坏或配置错误 导致的加速结构构建问题。
性能可视化
这类工具将抽象的性能数据以直观的图像方式呈现在屏幕上。
- 性能模式:着色器开销热力图 (Performance Mode: Shader Cost Heatmap):
- 功能:以 热力图(Heatmap) 的形式显示屏幕上每个像素的光线追踪开销。
- 度量指标:它显示的是
TraceRay着色器的总成本 (Trace Ray Shader Cost),这是一个复合指标。 - 成本构成:
- 遍历开销 (Traversal Cost):光线在BVH中遍历所花费的时间。
- 命中着色器开销 (Hit Shader Cost):光线与物体相交后,执行Any-Hit或Closest-Hit等命中着色器的成本。
关键启示:这种热力图非常直观,能让开发者一眼看出场景中哪些区域或材质(例如复杂透明材质)导致了高昂的光线追踪成本,从而进行针对性优化。
光线追踪的调试与性能可视化
本节核心讨论了用于调试和优化光线追踪性能的多种可视化模式,并通过几个实际案例展示了这些工具如何帮助开发者定位并解决性能瓶颈。
调试可视化模式 (Debug Visualization Modes)
为了深入分析光线追踪的性能开销,开发了一系列热力图(Heat Map)可视化模式。
组合成本视图 (Combined Cost View)
- 核心观点: 这个视图展示了 光线遍历 (Traversal) 和 命中着色器 (Hit Shader) 执行 的组合成本。
- 关键用途: 能够非常直观地帮助开发者快速定位和排查光线追踪着色器中意料之外的高成本区域,从宏观上找到性能热点。
BVH 遍历与质量视图 (BVH Traversal & Quality Views)
- 核心观点: 这组视图主要模仿了业界主流图形调试工具(如 PIX)中的光追性能分析模式,专注于分析 BVH 的遍历成本 和结构质量。
- 主要热力图类型:
- 内部 BVH 节点相交 (Internal BVH node intersections): 显示光线与 BVH 中间节点的相交次数,反映了 BVH 树的遍历深度和效率。
- 三角形相交 (Triangle intersections): 显示光线与图元(三角形)的相交测试次数。
- 总相交次数 (Total number of intersections): 上述两者的总和,综合反映了每条光线的遍历开销。
实际应用案例分析 (Practical Application Case Studies)
案例一:分离的碰撞体导致的 BLAS 性能问题

- 问题描述: 游戏场景中,一辆车的保险杠发生碰撞后脱落,但在数据结构上,它的几何体仍然属于该车辆的 BLAS (Bottom-Level Acceleration Structure)。
- 性能影响:
- 由于保险杠与车体主体相距甚远,导致包含这两部分的 BLAS 的包围盒 (AABB) 被撑得异常巨大。
- 大量原本与车辆无关的光线,现在却因为会穿过这个巨大的、大部分是真空的包围盒,而触发了对这个 BLAS 的遍历,极大地增加了无效的遍历成本。
- 调试价值: 通过遍历成本热力图,可以清晰地识别出这个区域存在不正常的性能开销,从而快速定位到是这个异常巨大的 BLAS 出了问题。
案例二:利用遍历限制优化复杂场景
- 问题描述: 在一些复杂的场景中(例如角色和植被交错),某些光线会经过一条非常长且复杂的路径,最终却没有命中任何有效几何体(Miss)。
- 性能影响: 这些“迷路”的光线会消耗巨量的遍历迭代次数(例如超过 100 次迭代),但对最终成像没有任何贡献,纯粹是计算资源的浪费。
- 调试价值: 遍历迭代次数热力图会高亮这些路径极其“昂贵”的光线,直观地证明了它们的性能影响。这为引入 遍历限制 (Traversal Limit) 提供了数据支持,通过限制单条光线的最大迭代次数,来为这些无效光线的成本设置一个上限。
案例三:远景剔除策略对比 (Instance Mask vs. Separate TLAS)
-
背景: 为了优化性能,通常需要区分处理近景和远景的几何体。这里对比了两种实现远/近景光线分离的方案。
-
方案 A (Instance Mask): 使用 单个 TLAS (Top-Level Acceleration Structure),包含所有远景和近景实例。通过设置 实例掩码 (Instance Mask),让追踪近景的光线忽略远景实例,反之亦然。
-
方案 B (Separate TLAS): 为近景和远景物体分别构建 两个独立的 TLAS。追踪近景的光线只在近景 TLAS 中进行,远景同理。
-
性能对比与分析:
- 观察结果: 遍历迭代次数热力图显示, 方案 B (独立 TLAS) 的遍历开销远低于方案 A (实例掩码)。
- 原因剖析:
- 在使用实例掩码时,尽管光线最终不会与被屏蔽的实例进行相交测试,但所有实例的包围盒依然存在于同一个顶层结构中。光线在遍历 TLAS 时,依然需要对这些包围盒进行判断,遍历的范围并没有缩小。
- 而使用 独立 TLAS 时,光线从一开始就在一个更小、更紧凑的加速结构中进行遍历,需要考虑的实例总数大幅减少,从根本上降低了遍历的复杂度和成本。
-
核心观点: 使用
Instance Mask进行剔除是一种 “后置过滤” (Post-filtering) 机制,它并不能减少光线遍历和求交的开销。- 当光线追踪管线使用
Instance Mask来区分不同集合的实例时(例如,区分 近景 (near-field) 和 远景 (far-field) 物体),加速结构 (BVH/TLAS) 中实际上同时包含了所有实例。 - 光线在遍历 BVH 并找到一个潜在的相交实例后, 必须先完整执行获取实例数据 (fetching) 和进行相交测试 (intersecting) 的流程。
- 只有在完成上述高开销操作之后,系统才会检查该实例的
Instance Mask,来决定这个相交结果是否有效。如果 mask 不匹配,之前的遍历和求交计算就被浪费了。
- 当光线追踪管线使用
-
性能对比:
- 低效方式 (Instance Mask): 将近景和远景物体放在同一个 TLAS 中,用
Instance Mask加以区分。光线需要遍历一个更大的结构,并对可能被 mask 掉的物体进行不必要的求交测试。 - 高效方式 (Separate Structures): 将近景和远景物体分别构建到 独立的加速结构 (Separate Acceleration Structures) 中。这样,追踪近景光线时,只需要遍历小而紧凑的近景 BVH,从根本上避免了与远景物体相关的任何计算开销。
- 低效方式 (Instance Mask): 将近景和远景物体放在同一个 TLAS 中,用
-
关键术语:
- Instance Mask: 一个比特掩码,用于在光线和实例之间进行快速的逻辑分组与筛选。通常在光线生成时设置一个掩码,只有实例掩码与光线掩码按位与 (AND) 结果不为零时,相交才有效。