Lumen: Real-time Global Illumination in Unreal Engine 5
SIGGRAPH 2022 Advances in Real-Time Rendering in Games course
Lumen Real-time Global Illumination in Unreal Engine 5
Part 1: Introduction to Lumen and Screen Tracing
核心目标与愿景
- 关键系统: Lumen,是 Unreal Engine 5 中内置的 实时全局光照 (Real-time Global Illumination) 系统。
- 最终愿景: 实现 完全动态的间接光照 (Fully Dynamic Indirect Lighting),彻底改变游戏世界的光照交互方式。
对比传统烘焙光照 (Baked Lighting) 的革命性意义
- 传统方法的局限性: 烘焙光照 (Baked Lighting) 本质上是静态的,它极大地限制了游戏世界的动态交互性。
- 痛点举例:
- 开门/关门: 无法实时反映门内外光线的变化。
- 墙体破坏: 被破坏的墙体无法让外部光线自然地照射进来。
- Lumen 的价值: 通过实时计算动态的间接光,Lumen 解锁了这些过去难以实现的交互,允许光照实时响应场景的任何变化,为游戏设计和玩家体验带来了前所未有的可能性。
转向实时全局光照的动机与挑战
本节内容深入探讨了为什么业界(特别是 Epic Games)决心从传统的烘焙光照方案转向完全实时的动态全局光照(Dynamic Global Illumination),以及实现这一目标所面临的根本性技术挑战。
一、 核心动机:为什么要抛弃烘焙光照?
从根本上说,转向实时GI是为了打破 静态烘焙光照(Baked Lighting) 带来的诸多限制,从而在游戏世界的交互性、美术工作流和最终质量上实现质的飞跃。
-
1. 赋能动态世界与交互 (Enabling Dynamic Worlds & Interactions)
- 核心观点: 烘焙光照是静态的,它严重制约了世界的动态性。任何对场景几何体或光源的改动(如开门、破坏墙壁)都会破坏预先计算好的光照,导致视觉失真。
- 愿景: 如果光照能够完全实时响应,开发者将能够创造出更复杂、更具沉浸感的交互式体验,而不仅仅是简单的物件破坏。
-
2. 革新美术工作流 (Revolutionizing the Artist Workflow)
- 核心观点: 传统的 光照构建(Lighting Build) 流程极其耗时,美术师修改光照后需要等待数分钟甚至数小时才能看到最终效果,这极大地扼杀了创造力和迭代效率。
- 愿景: 实现所见即所得。美术师可以实时调整光照并立刻看到最终品质的结果,这将极大提升迭代速度,从而有更多时间去打磨和提升光照的艺术品质。
-
3. 应对大规模开放世界与团队协作 (Addressing Large-Scale Worlds & Team Collaboration)
- 核心观点: 对于巨大的开放世界来说,完整的烘焙是不现实的。同时,在大型团队中,每天都有数百人修改关卡,导致烘焙数据频繁过期,永远无法与最新的场景状态保持同步。
- 愿景: 一套完全动态的系统可以从根本上解决这些规模化和协同工作带来的问题。
-
4. 设定极高的质量标杆 (Setting an Extremely High Quality Bar)
- 核心观点: 目标不仅仅是实现一个“能用”的动态GI方案,而是要达到甚至超越烘焙光照的质量。
- 关键质量指标: 必须能够还原所有精细的 间接光照细节(Indirect Lighting Details) 和 间接阴影(Indirect Shadows),这些是烘焙光照的核心优势。
二、 核心挑战:为什么实时GI如此困难?
将需要数小时计算的烘焙光照质量压缩到每帧十几毫秒内完成,面临着几个根本性的难题。
-
1. 巨大的性能鸿沟 (The Immense Performance Gap)
- 核心观点: 离线的光照构建过程与实时渲染之间存在着巨大的算力预算差异。
- 量化对比: 离线构建拥有的处理时间可能是实时渲染(例如,16毫秒/帧)的 100,000倍 以上。要在如此悬殊的性能差距下达到同等质量,需要算法上的根本性突破。
-
2. 算法与硬件的根本性冲突 (Fundamental Mismatch between Algorithm & Hardware)
- 核心观点: 全局光照的物理过程在本质上是 非相干的(Incoherent),而现代GPU的设计却是为 相干性(Coherency) 执行和内存访问而优化的。
- 技术解释: GI中的光线会向四面八方反弹,导致计算和内存访问模式非常离散和随机。而GPU的SIMD/SIMT架构在处理整齐划一、访问连续内存的数据时效率最高。这种根本性的不匹配使得在GPU上高效求解光线传输成为一个巨大的挑战。
-
3. 广阔且复杂的解空间 (A Vast and Complex Solution Space)
- 核心观点: 实现实时GI的技术路径繁多,整个问题是一个巨大的研究领域。
- 挑战: 存在无数种可能的算法和技术组合,仅仅是探索和判断哪些路径可行、哪些是死胡同,本身就是一项艰巨的研发挑战。
Lumen 核心算法概览: 射线追踪的挑战与方案抉择
实时全局光照的核心挑战:微妙的平衡
实时全局光照(Real-Time GI)的开发面临着一个核心的困境:性能与质量的平衡。其成功的容错空间(margins for success)极小,开发者如同站在一道狭窄的山脊上,任何微小的变动都可能导致性能或质量的急剧下降。
- 核心观点: 在实时GI领域,同时满足高性能和高质量的要求极为困难,需要精妙的算法设计和权衡。
Lumen 的首要问题:如何在场景中高效追踪光线?
要实现动态的实时间接光照,首要解决的问题就是如何高效地在复杂的虚拟世界中追踪光线。虽然硬件光线追踪是未来的趋势,但当前阶段仍存在诸多限制,因此必须探索软硬件光追路径并存的解决方案。
为何需要软件光线追踪 (Software Ray Tracing)?
尽管硬件光线追踪(Hardware Ray Tracing)功能强大,但 Lumen 仍投入资源开发了一套独立的软件光线追踪系统,其主要动机是解决硬件光追的几大局限性:
- 硬件普及度与可伸缩性 (Scalability): PC 市场仍有大量不支持硬件光追的显卡,软件方案可以覆盖更广泛的用户群体。
- 主机硬件性能限制 (Console Performance): 主机平台上的硬件光追性能并非无限,不足以支撑复杂GI的全部开销。
- 特定场景类型的性能瓶颈:
- 对于包含大量 重叠网格 (overlapping meshes) 的复杂场景(如 Nanite 场景),硬件光追依赖的 两级加速结构 (two-level acceleration structure, e.g., BVH) 会变得效率低下。
- 软件光线追踪 路径的开发,正是为了弥补这些短板,提供一个更具弹性和适应性的光追方案。
早期的探索:基于卡片 (Cards) 的高度场光追方案
在 Lumen 开发初期,团队尝试了一种基于 2D 表面表示的软件光追方案,但最终被放弃。了解这个方案的优劣有助于理解 Lumen 最终选择的技术路径。
-
核心概念: Cards (卡片) / 高度场 (Height Fields) 方法
- 实现原理:
- 通过一系列 正交摄像机 (orthographic cameras) 从不同角度捕捉场景。
- 将捕捉到的深度信息等数据生成一系列我们称之为“卡片”的平面图像。
- 这些“卡片”本质上是场景表面的高度场表示。
- 软件光追系统转而在这个 2D 的高度场集合中进行追踪。当光线命中时,再从卡片上采样光照信息。
- 实现原理:
-
该方案的优势:
- 高空间分辨率: 相较于 体素 (voxels) 等 3D 场景表示方法,2D 的高度场能够以更低的成本提供更高的表面细节分辨率。
- 快速的软件追踪: 可以借鉴类似 视差遮蔽映射 (Parallax Occlusion Mapping, POM) 的技术,利用高度场的特性实现非常快速的光线步进和求交。
-
该方案的致命缺陷:
- 无法完整覆盖场景: 使用有限的“卡片”来拼接和表示整个三维世界,几乎不可能做到无死角的完整覆盖。
- 漏光 (Leaking): 在卡片未能覆盖的区域或卡片之间的接缝处,光线会直接“穿透”,导致严重的漏光现象,这是该方案最终被放弃的核心原因。
Lumen 的核心光追技术选型与管线
几何体表示:从高度场到网格符号距离场 (Mesh SDF)
讲座的前一部分提到了基于高度场(Height Fields)的方案,但该方案存在一个致命缺陷。
-
核心问题: 使用高度场无法完整覆盖所有场景几何体,未被覆盖的区域会导致 漏光 (Leaking) 现象,这是一个严重的视觉瑕疵。
-
解决方案: 转而采用 网格符号距离场 (Mesh Signed Distance Fields, Mesh SDF) 作为软件光线追踪的几何体表示。
- 优势 1 - 可靠的遮挡: Mesh SDF 可以覆盖所有几何表面,从根本上解决了漏光问题,提供了 可靠的遮挡 (Reliable Occlusion)。
- 优势 2 - 高效追踪: 依然可以利用 球体追踪 (Sphere Tracing) 算法在空白空间中进行快速步进,保持了软件光追的高效率。
光照查询:表面缓存 (Surface Cache) 的引入
虽然 Mesh SDF 解决了几何求交的问题,但它本身也带来了新的挑战。
-
SDF 的局限性: 与 Mesh SDF 的求交只能得到 命中位置 (Hit Position) 和 法线 (Normal),无法直接获取材质、光照等表面属性。
-
解决方案 - 表面缓存 (Surface Cache):
- 核心观点: 将场景表面的光照和材质信息预先计算并存储在一系列代理几何(讲座中称为 Cards)上,形成一个 表面缓存 (Surface Cache)。
- 当光线命中 SDF 表面时,我们利用命中点的位置,从周围的 Cards 中插值获取最终的光照结果。
- 优势: 这种方法将几何遮挡和光照解耦。即使场景中某些区域的 Surface Cache 未能覆盖,其后果也只是 能量损失 (Lost Energy),而非之前高度场方案中更扎眼的漏光。这是一种更优雅的降级方案。
-
Surface Cache 的额外优点:
- 复用材质计算: 多条光线可以共享和复用同一区域的材质计算结果。
- 显式控制更新: 开发者可以直接控制 Surface Cache 的更新时机与频率。
- 硬件光追加速: 为后续将要介绍的 硬件光线追踪提供了快速路径 (Fast Paths)。
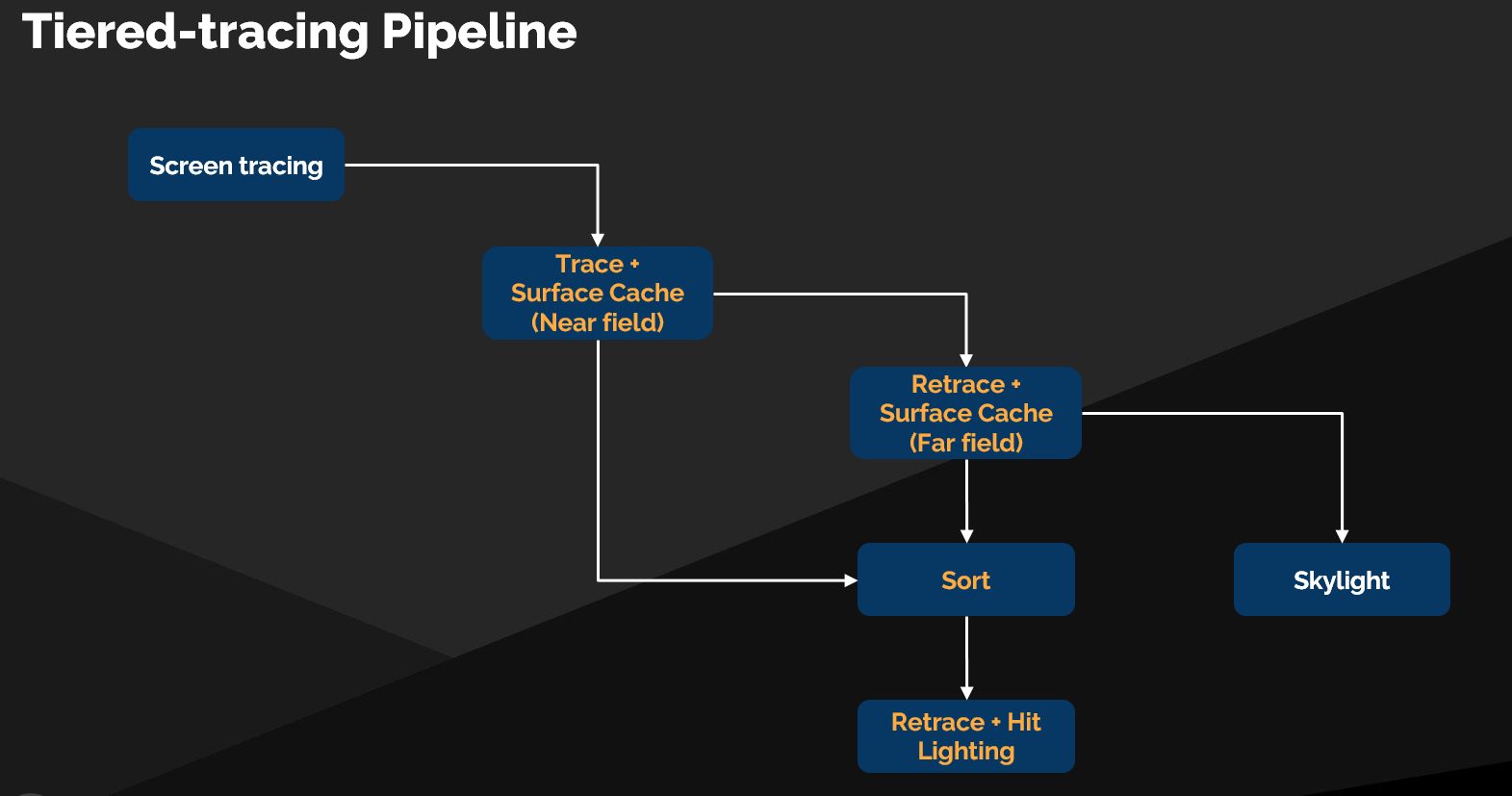
Lumen 的混合光线追踪管线 (Ray Tracing Pipeline)
Lumen 采用了一个分阶段、混合式的光线追踪管线,以平衡性能与效果。
-
屏幕空间追踪 (Screen Tracing)
- 优先执行: 作为管线的第一步,因为它在靠近光线起点的区域最为精确。
-
软件/硬件光线追踪 (Software/Hardware Ray Tracing)
- 第二阶段: 当屏幕空间追踪失败(光线移出屏幕或被遮挡)后,根据配置启用软件光追(基于 Mesh SDF)或硬件光追。
-
天光采样 (Skylight Sampling)
- 最终回退: 如果光线错过了所有场景几何体,则最后对 天光 (Skylight) 进行采样作为最终结果。
挑战:多弹反全局光照 与 Final Gather
解决了单次反射后,下一个核心问题是实现完整的间接光照路径。
-
核心挑战: 实时 GI 系统不能只满足于一次光线反弹。要达到逼真的效果,必须解决 多弹反漫反射 (Multibounce Diffuse) (尤其在室内场景)以及 反射中看到的全局光照 (GI seen in Reflections)。
-
解决策略 - 分而治之:
- 第一次反弹 (First Bounce): 由于其对最终效果的贡献最大,因此将其分离出来,使用专门的技术来求解。
- Final Gather: 对于漫反射的第一次反弹,Lumen 采用了一种称为 Final Gather 的专用技术来处理。
Lumen GI: 核心问题拆解与降噪策略
本次讲座内容聚焦于实时全局光照(GI)所面临的几个核心挑战,并阐述了Lumen系统为解决这些问题所采取的策略,特别是如何处理不同类型的光线反弹和高频噪声。
光线反弹的处理策略:分层解耦
Lumen将间接光照的计算拆分为两个主要部分:首次反弹和后续反弹,并针对各自的特性使用专门的技术进行处理。
-
首次反弹 (First Bounce): 分而治之
- 漫反射 (Diffuse): 使用一种称为 Final Gather 的技术来专门求解。这是解决室内场景高质量漫反射GI的关键。
- 高光/反射 (Specular): 使用专门的 反射降噪 (Reflection Denoising) 技术来处理。
-
后续反弹 (Subsequent Bounces): 依赖反馈机制
- 所有首次反弹之后的光线交互都通过 表面缓存 (Surface Cache) 来解决。
- 这是一个 反馈循环 (Feedback Loop):系统从表面缓存中进行采样(Gather),读取上一帧的照明结果,然后将新的照明结果写回。每一次更新迭代,都相当于传播了一次额外的间接光反弹。
核心问题:光线传输中的噪声 (Noise in Light Transfer)
实时GI面临的最大挑战之一,是在极其有限的光线预算下(甚至低于每像素一条光线)如何获得高质量、无噪声的图像。
- Final Gather 技术详解
- 核心挑战: 高质量的室内场景可能需要数百个有效样本才能收敛,而实时渲染的预算极低。
- 解决方案: 组合运用多种技术来最大化每条光线的利用效率。
- 自适应降采样 (Adaptive Downsampling): 在平坦区域使用更少的光线,在细节复杂的区域使用更多,从而以最少的光线总数获得可接受的初始结果。
- 时空复用 (Spatial and Temporal Reuse): 在空间上(利用相邻像素信息)和时间上(复用前几帧信息)聚合光线追踪的结果,有效增加等效样本数。
- 乘积重要性采样 (Product Importance Sampling): 智能地将光线投射到对最终结果贡献最大的方向,提高采样效率。
Final Gather 技术的应用扩展
Final Gather并非只用于不透明物体,Lumen将其扩展到了更复杂的场景元素,但需要在不同的计算域(Domain)中进行。
- 不透明物体 (Opaque): 在 2D 屏幕空间 (2D Domain) 进行计算。
- 体积雾 (Fog): 需要为整个 可见视锥体 (Visible Frustum) 内的所有点求解,这是一个 3D 体积问题。
- 表面缓存 (Surface Cache): 其采样和更新发生在 纹理空间 (Texture Space Domain)。

反射降噪策略 (Reflection Denoising Strategy)
对于高光反射中的噪声,Lumen采用了与漫反射类似的思路,但有其特殊优化:
- 核心方法: 同样依赖 时空复用 (Spatial and Temporal Reuse) 来聚合样本。
- 关键优化: 尽可能复用漫反射光线 (Reuse Diffuse Rays)。这意味着为漫反射追踪的光线可以被重新用于辅助高光反射的计算,进一步节省性能开销。
Lumen 系统能力总结
通过上述技术的整合,Lumen实现了强大的实时GI效果,并且对美术师的工作流非常友好。
- 核心功能:
- 多弹反弹间接光照 (Multi-bounce Indirect Lighting)
- 天空光遮蔽 (Sky Shadowing)
- 自发光照明 (Emissive Lighting)
- 美术便利性: 无需美术师手动放置补光灯或光照探针。
- 当前限制: 对于自发光区域的大小和亮度存在一定限制。过小或过亮的自发光源可能无法被系统稳定地处理。
Lumen 功能总览与技术深入路线图
这部分内容首先对 Lumen 的核心能力进行了概括,并预告了后续深入探讨的技术模块。
-
核心功能概览:
- GI 覆盖范围: Lumen 不仅能处理常规表面的全局光照,还支持 体积雾 (Volumetric Fog) 和 半透明材质 (Transparency) 的 GI 计算。
- 反射系统: Lumen 提供了完整的动态 反射 (Reflections) 解决方案。
- 核心优化: 这一切高效运行的关键在于其 表面缓存 (Surface Caching) 机制。
- 技术灵活性: 可根据项目需求和硬件能力,选择使用 软件光线追踪 (Software Ray Tracing) 或 硬件光线追踪 (Hardware Ray Tracing)。
-
技术深入路线图:
- 光线追踪管线 (Ray Tracing Pipeline)
- 最终收集 (Final Gather)
- 反射 (Reflections)
- 性能与可伸缩性 (Performance and Scalability)
Lumen 的混合光线追踪管线 (Hybrid Ray Tracing Pipeline)
Lumen 并不依赖单一的光线追踪技术,而是采用了一种分阶段、可组合的混合管线。
-
核心观点: Lumen 的管线是一种 “接力式” 或 “分段式” 的追踪机制,允许多种技术(如屏幕空间追踪、软件光追、硬件光追)协同工作。
-
工作机制:
- 管线中的每一种追踪方法按顺序执行(例如,屏幕空间追踪先行)。
- 前一阶段的方法完成后,会输出两个关键信息:
- 光线已经行进了多远 (
t_max)。 - 是否找到了命中点 (Hit/Miss)。
- 光线已经行进了多远 (
- 后一阶段的方法会接收这些信息,并从前一阶段中断的地方继续追踪光线,而非从头开始,极大地提升了效率。
第一阶段:屏幕空间追踪 (Screen Traces) 的核心作用
在整个混合管线中,屏幕空间追踪作为第一道防线,其作用至关重要,主要解决了其他追踪方法难以处理的近场精度问题。
-
核心观点: 屏幕空间追踪 (Screen Traces) 擅长处理近距离的细节和精度问题,为后续的软件/硬件光追扫清障碍,弥补其固有缺陷。
-
主要解决的问题:
-
处理渲染表示不匹配 (Representation Mismatches)
- 问题根源: 基于光栅化的 G-Buffer 与用于软件/硬件光追的场景表示(如 Mesh Distance Fields 或 BVH)之间存在精度和拓扑上的不一致。
- 导致的瑕疵:
- 自相交 (Self-Intersection): 当光线起点因不匹配而落入其几何体的光追表示内部时,会立即与自身相交,产生错误遮挡。
- 漏光 (Leaking): 光线可能因为表示不一致而穿过本应被阻挡的薄表面。
- 解决方案: 屏幕空间追踪直接利用高精度的 G-Buffer 数据,能完美处理这些近摄像机的瑕疵。
-
处理不支持的几何体类型 (Unsupported Geometry)
- 应用场景: Lumen 的主要追踪方法(尤其是软件光追)可能不支持所有类型的几何体。一个典型的例子是 蒙皮网格 (Skinned Meshes),如角色模型。
- 解决方案: 屏幕空间追踪可以有效地为这些对象计算间接光照和遮蔽,例如,一个第三人称角色可以在场景中投射出柔和的 间接阴影 (Indirect Shadows),即使其本身未被软件光追系统完全支持。
-
-
其他优势:
- 尺度无关性 (Works at any scale): 屏幕空间追踪的精度与屏幕分辨率相关,因此无论摄像机离表面多近,都能提供精细的 GI 细节。
屏幕空间追踪优化与射线压缩
本节内容聚焦于屏幕空间追踪(Screen Traces)在全局光照(GI)中的应用、其固有的问题、改进方法,以及在混合追踪管线中至关重要的性能优化步骤——射线压缩(Ray Compaction)。
屏幕空间追踪 (Screen Traces) 的改进
屏幕空间追踪是获取高频细节 GI 的利器,但传统的实现方式存在明显缺陷,需要进行针对性优化。
核心观点
- 优点: 屏幕空间追踪能够不受缩放尺度影响,为场景提供非常精细的 GI 细节。
- 挑战: 传统的 线性步进(Linear Steps) 方法在处理薄物体(如栏杆、走道)时,容易因步长过大而“跨越”过去,导致 漏光(Leaking) 现象。
关键技术与优化
-
HZB 遍历 (HZB Traversal)
- 核心思想: 放弃线性步进,转而采用一种基于 层级深度缓冲(Hierarchical Z-Buffer, HZB) 的遍历方法。
- 实现方式: 这是一种 无堆栈(stackless) 的遍历算法,它沿着射线方向在 最近(closest) 的 HZB mipmap 层级中进行步进。这种方法可以更精确、更高效地找到射线与屏幕空间深度之间的交点,有效解决了薄物体的漏光问题。
- 可视化: 讲座中的动画(每 5 步一帧)展示了 HZB 遍历的过程。

-
特殊情况处理与性能优化
- 掠射角射线(Grazing Angle Rays): 对于几乎与表面平行的射线(例如平行于墙壁的射线),会限制其迭代次数,防止无效的长时间追踪。
- 半分辨率追踪: 为了提升性能,漫反射射线(Diffuse Rays)的追踪在半分辨率下进行。
-
与后续追踪方法的交接 (Hand-off)
- 问题: 当屏幕空间追踪结束(射线移出屏幕、或射入某个表面后方),需要将追踪任务交给下一个方法(如硬件光追)时,必须确保交接点的准确性,否则同样会引发漏光。
- 解决方案: 在交接时,将射线的起点 回退(step back)到最后一个未被遮挡的位置。这保证了后续的追踪方法能从一个有效、可见的位置开始,从而维持了整个追踪过程的鲁棒性。
整体收益
- 质量提升: 尽管屏幕空间追踪失败时会很显眼,但总体上它是一个 净质量增益(net quality win)。
- 性能提升: 在与硬件光线追踪结合的管线中,屏幕空间追踪能处理掉大量与复杂表面几何体的求交,让硬件光追单元只需处理剩下的“硬骨头”,从而带来轻微的性能增益。
射线压缩 (Ray Compaction)
在屏幕空间追踪阶段后,一部分射线已经找到了交点(solved),而另一部分则需要继续追踪。为了避免在后续更昂贵的追踪阶段中浪费计算资源处理这些“已完成”的射线,需要进行压缩。
核心观点
- 动机: 在混合追踪管线中,不同阶段会解析掉一部分射线。将剩余的 有效射线(active rays) 紧凑地排列在一起,可以极大提升后续阶段的执行效率和硬件利用率,带来 显著的速度提升(significant speed up)。
两种压缩方法对比
-
方法一:基于原子操作的简单压缩 (Local Atomics)
- 实现: 使用局部原子操作(local atomics)来为有效的射线分配新的、紧凑的索引。
- 缺点: 打乱射线顺序(Scrambling the rays)。原本在同一个计算波(Wave/Warp)中空间位置相近的射线,在压缩后会被随机分散到不同的波中。这破坏了 数据局部性(Coherence),导致后续的内存访问和计算效率降低。
-
方法二:保序压缩 (Order-Preserving Compaction)
- 核心思想: 在压缩的同时,保持射线在原始数据中的相对顺序,维持其空间局部性。
- 实现: 在一个更大的线程组(Thread Group)内,通过高效的并行算法—— 前缀和(Prefix Sum) 来计算每个有效射线的新索引。
- 优势: 解决了射线顺序被打乱的问题,保证了后续追踪阶段的计算和访存效率,是更优的实现方式。

Part 2: Software Ray Tracing in Lumen
这部分内容核心是阐述在硬件光线追踪(如 DXR)已经可用的情况下,Lumen 为什么依然需要并实现了一套软件光线追踪方案,并介绍了其核心的加速结构与图元。
软件光线追踪
软件光线追踪的动机 (Motivation for Software Ray Tracing)
为什么在有硬件光追时仍要开发软件光追?
虽然硬件光线追踪性能强大,但软件方案提供了硬件方案无法比拟的灵活性和兼容性,这是 Lumen 设计中的重要考量。
-
平台兼容性与可伸缩性 (Platform Compatibility & Scalability):
- 核心目标是让 Lumen 能够在 不支持 DXR (DirectX Raytracing) 的硬件 上运行。
- 提供 向下扩展 (scale down) 的能力,以适应更广泛的硬件性能范围。
-
完全的控制权与自定义权衡 (Full Control & Custom Trade-offs):
- 硬件光追虽然快,但其加速结构和追踪流程是固化的,开发者无法干预。
- 软件方案让开发团队可以 完全控制追踪循环 (tracing loop),从而根据需求进行不同的性能与质量权衡。
-
解决硬件加速结构的局限 (Overcoming Hardware Acceleration Structure Limitations):
- 一个具体的例子是,在硬件 BVH 中,当 多个实例(Instances)发生重叠 时,光线为了找到最近的命中点,必须遍历每一个重叠的实例,这会带来性能开销。
- 软件方案则可以设计不同的加速结构或追踪策略来规避或优化这类特定问题。
Lumen 软件光追的加速结构 (Lumen's Software RT Acceleration Structure)
Lumen 的软件光追没有使用传统的 BVH,而是采用了一种为距离场和高度场优化的两级结构。
-
核心设计:两级结构 (A Two-Level Structure)
- 底层 (Bottom Level) - 图元 (Primitives):
- 网格距离场 (Mesh Distance Field): 针对普通静态网格的核心表示方法。
- 地貌高度场 (Landscape Height Field): 针对大面积的地形组件的优化表示。
- 顶层 (Top Level) - 实例描述符 (Instance Descriptors):
- 一个 扁平的实例描述符数组 (flat instance descriptor array),用于管理场景中所有底层图元的实例。
- 底层 (Bottom Level) - 图元 (Primitives):
-
该结构的优势 (Advantages of this Structure)
- 高效利用实例化 (Leverages Instancing): 能够复用底层图元数据,极大降低存储开销。
- 降低内存占用 (Reduces Memory Usage): 这对于像距离场这样的 体积表示 (volumetric representation) 尤其重要。
网格距离场 (Mesh Distance Fields)
网格距离场(Mesh DF)是 Lumen 软件光追的核心图元之一,它并非全新技术,但为了 Lumen 进行了特定的开发和优化。
-
生成与存储 (Generation and Storage):
- 生成时机: 在网格被导入引擎时(during mesh import)预计算生成。
- 存储方式: 与网格的其他数据(如顶点、索引等)一同存储。
-
生成技术 (Generation Technique):
- 为了高效地计算空间中某点到模型表面的最近距离,Lumen 使用了 Intel Embree 库。
- 具体来说,是利用 Embree 的点查询 (point query) 功能,它可以非常快速地找到任意点到三角形网格的最近点,从而得到距离值。
网格距离场(Mesh Distance Field)的生成、存储与追踪
本节内容详细阐述了一套完整的网格距离场(Mesh Distance Field, MDF)技术管线,涵盖了从离线生成、运行时存储管理到实时光线追踪(Ray Marching)加速的各个环节。
距离场的生成 (Generation)
这是为静态网格物体预计算距离场数据的离线步骤。
-
核心观点: 生成过程分为两步:首先计算到表面的最短距离,然后判断点在物体内外以确定距离场的符号。
-
距离计算:
- 使用 Intel 的 Embree 库提供的 点查询(Point Query) 功能,来高效地计算每个体素(Voxel)中心到最近三角形的精确距离。
-
符号确定 (Inside/Outside Test):
- 为了确定体素是在几何体内部还是外部(从而决定距离值的正负号),从每个体素中心向周围发射 64 条随机方向的光线。
- 通过统计光线与几何体 背面(Backfaced) 的相交次数来判断。
存储与运行时管理 (Storage & Runtime Management)
由于完整的体积数据内存开销巨大,必须采用高效的存储和动态加载策略。
-
核心观点: 采用基于 Mipmap 的虚拟体积纹理来存储稀疏的窄带距离场,并根据视距动态流式加载,同时使用线性分配器管理内存以避免碎片。
-
关键技术与术语:
- 窄带距离场 (Narrow Band Distance Field): 考虑到性能和内存,系统只存储靠近模型表面的一层薄壳(窄带)内的距离场数据,而非整个包围盒。
- Mipmap 化的虚拟体积纹理 (Mipmapped Virtual Volume Texture): 这是核心的数据结构。
- Mip 0 对应最高分辨率,其大小根据原始网格尺寸和导入设置决定。
- 更高层级的 Mip (Mip 1, Mip 2, ...) 分辨率逐级减半,但其能够表示的 最大物体空间距离(Max Object Space Distance)则逐级翻倍。这使得 Mipmap 不仅用于纹理过滤,更成为一种空间层次结构(Hierarchical Level of Detail)。
- 运行时 Mipmap 流式加载 (Streaming):
- 需求计算: 每一帧,通过一个 Compute Shader 遍历所有场景中的物体实例。
- Mip 等级选择: 根据物体与摄像机的距离,为每个距离场资源计算出当前最适合的 Mip 等级。
- 数据请求与调度: 将这些 Mip 等级请求从 GPU 下载到 CPU。CPU 的流式处理系统会负责异步加载所需的距离场数据块(Bricks),并卸载不再需要的 Mip 数据。
- 内存池管理:
- 所有距离场数据块都存储在一个 固定大小的内存池 (Fixed Size Pool) 中。
- 通过一个简单的 线性分配器 (Linear Allocator) 来管理这个池,这种方法可以 有效避免复杂的可变尺寸 3D 内存分配 以及随之而来的内存碎片问题。
距离场的追踪与应用 (Tracing & Application)
在运行时,利用预计算好的距离场数据结构来高效地进行光线步进(Ray Marching)。
-
核心观点: 利用距离场的 Mipmap 结构来动态调整步进距离,实现对空间的快速遍历和对表面的精确逼近,同时设定迭代上限以保证性能。
-
关键技术与算法:
- 分层加速光线步进 (Hierarchical Ray Marching Acceleration):
- 当光线远离表面时(距离场值较大),查询 低分辨率的 Mipmap,这允许我们以更大的步长安全地穿越空旷空间。
- 当光线接近表面时(距离场值较小),切换到 高分辨率的 Mipmap,进行 更小、更精确的步进,以准确找到交点。
- 这种思想与 Sebastian Aaltonen 在游戏 Claybook 中使用的技术相似。
- 性能保障措施:
- 将单次光线步进的 最大迭代次数硬性限制为 64 次。
- 如果达到迭代上限仍未找到精确交点,则直接将当前光线位置作为命中点返回。这是一种性能与精度的权衡,可以有效防止GPU因复杂场景而卡死。
- 法线计算 (Normal Computation):
- 在光线步进找到命中点后,需要计算该点的法线信息以进行后续着色。
- 通过在命中点周围进行 6 次额外采样,并运用 中心差分 (Central Differencing) 方法来估算距离场的梯度(Gradient),这个梯度方向即为该点的 几何法线 (Geometry Normal)。
- 分层加速光线步进 (Hierarchical Ray Marching Acceleration):
特殊几何体追踪与全局加速结构的挑战
Landscape (Heightfield) 的光线追踪方案
本节深入探讨了针对 Landscape 这种特殊几何类型的光线追踪实现细节,它采用了一种独特的两级(Top-Level / Bottom-Level)处理方式,而非直接使用 3D SDF。
核心观点
为了高效地追踪广阔的 Landscape,系统将其视为由多个组件(Component)构成的集合。顶层加速结构将其作为普通实例处理,而底层则采用专门的 2D Heightfield 光线步进(Ray Marching) 算法,以兼顾性能与内存效率。
1.1 顶层加速结构 (Top-Level)
- 实例处理: 在顶层结构中,每一个 Landscape 组件的实例(Heightfield Instance)被当作标准的 网格距离场实例(Mesh Distance Field Instance) 来处理。
- 代码复用: 这种抽象方式的巨大优势在于可以 复用与标准网格体相同的剔除(Culling)和遍历(Traversal)代码,简化了引擎架构。
1.2 底层求交 (Bottom-Level)
当光线追踪进入一个具体的 Landscape 组件实例后,处理流程与标准 3D SDF 不同,转而采用专门的 2D 高度场求交算法:
-
光线步进 (Ray Marching):
- 系统沿光线方向在 2D 高度场 上进行步进,而非在 3D 体素空间中。
- 目标是找到一个 零交点 (Zero Crossing),即光线的当前高度与该位置的高度场采样值相等的位置。
-
精确命中点计算:
- 通过光线步进找到一前一后两个采样点,其中一个点在高度场上方,另一个在下方。
- 通过在这两个点之间进行 线性插值 (Linearly Interpolate),来近似计算出最终的精确命中点。
-
命中有效性验证 (Opacity Test):
- 在计算出命中点后,需要从 Surface Cache 中查询该点的 不透明度 (Opacity)。
- 接受命中: 如果该点是不透明的,则命中有效。
- 跳过命中: 如果该点是透明的(例如,在地形的镂空区域),则忽略此次命中,光线继续向高度场下方追踪。
-
表面着色:
- 一旦命中被接受,系统会再次在命中点对 Surface Cache 进行采样,获取计算光线贡献(Ray Radiance)所需的所有材质和光照信息。
- 为了计算着色所需的法线,系统采用 中心差分法 (Central Differencing),通过对周围 6 个点 进行采样来计算几何法线。
场景全局追踪的加速结构选型挑战
在解决了单个实例的追踪问题后,讲座讨论了如何高效追踪整个复杂场景,并阐述了在选型全局加速结构时遇到的困难和放弃某些方案的原因。
核心观点
对于包含大量实例且光线路径 长而杂乱 (Long Incoherent Rays) 的场景,一些常见的加速结构(如 Grids)表现不佳。尤其是在处理 实例重叠 (Overlapping Instances) 的情况时,开销会变得非常大。
2.1 尝试过的方案与遇到的问题
-
Deviation Grids:
- 优点: 这是一种优秀的加速结构,可以 每帧构建一次并在多个 Pass 中复用。
- 缺点: 对于 长距离、非相干光线 的追踪性能不尽人意。这表明该方案可能更适合短距离、方向较为一致的光线(如 AO)。
-
软件 BVH (Software BVH):
- 缺点: BVH 的遍历逻辑,尤其是在着色器中实现时,会产生一个 非常复杂的 Kernel,可能影响性能和维护性。
-
通用网格 (Grids) 的问题:
- 复杂性: 处理 横跨多个网格单元 (Cell) 的物体 时,逻辑会变得非常复杂。
- 重叠实例问题: 这是最关键的性能瓶颈。当场景中存在实例重叠时,光线进入一个网格单元后,必须对该单元内所有可能相交的实例都进行一次光线步进,以确保找到最近的命中点。这极大地增加了计算开销,削弱了加速结构的优势。
远距离光线追踪的场景表示与优化
本节内容聚焦于解决远距离光线追踪(Ray Tracing for long distances)中遇到的性能瓶颈,并详细阐述了从多种方案探索到最终选定 全局距离场(Global Distance Field) 作为解决方案的演进过程。
长光线追踪的挑战与核心思想
1.1. 核心挑战
当场景中存在大量 重叠实例(overlapping instances) 时,追踪一根长光线需要对路径上的每一个实例都进行求交测试(Ray Marching),以找到最近的交点,这带来了巨大的计算开销。
1.2. 核心思想:分段式追踪策略
为了解决上述问题,一个关键的认知是:我们并不需要对整条光线路径都使用同一种高精度的表示。
- 短光线 (Short Rays): 对于光线初始的一小段,我们需要 精确的场景表示(precise scene representation) 来获得准确的相交结果。
- 长光线 (Long Rays): 当光线的足迹(footprint)随着距离变大而展宽时,我们可以切换到一种 粗糙的场景表示(coarse scene representation) 进行追踪。
这个思想允许我们将整个场景合并成一个简化的 全局表示(global representation),用于处理光线的远距离部分,从而解决了对象重叠带来的性能问题。
全局场景表示方案的探索历程
为了构建这个“粗糙的全局表示”,团队尝试了多种方法,每种方法都有其优缺点:
-
离线场景合并 (Offline Scene Merging):
- 方法: 在场景构建阶段(build step)将所有静态几何体合并。
- 缺点: 流程非常受限,不支持动态对象,无法满足现代游戏引擎的需求。
-
运行时体素化与体素锥追踪 (Runtime Voxelization & Voxel Cone Tracing):
- 方法: 在运行时将场景几何体素化(Voxelize)成一个体积,然后使用体素锥进行追踪。
- 缺点: 将几何属性合并到体素中会造成 信息损失和光照泄露(loss of leaking),尤其是在较低的 Mipmap 等级中问题更为严重。
-
体素位砖块 (Voxel Bit Bricks):
- 方法: 为每个体素(Voxel)分配一个比特(bit),用于标记该位置是否存在几何体。
- 缺点: 对这种数据结构进行简单的光线步进(Ray Marching)出乎意料地慢。虽然之后尝试为其添加 邻近图(Proximity Map) 进行加速,但最终促使团队转向了更优的方案。
最终方案:全局距离场 (Global Distance Field)
经过上述探索,团队最终确定使用 全局距离场(Global Distance Field, GDF) 作为远距离光线追踪的场景表示。
3.1. 基本概念
全局距离场是将场景中所有独立的 网格距离场(Mesh Distance Fields) 和 高度场(Height Fields) 合并到一个统一的数据结构中。这个结构由一组以摄像机为中心的 裁剪贴图(Clip Maps) 构成。
- 核心优势: 网格距离场和高度场这类表示形式,非常易于在运行时进行合并和实现LOD(Level of Detail),完美契合动态场景的需求。
3.2. 实现细节
- 数据结构: 默认使用 四层稀疏裁剪贴图(four sparse clip maps) 来组织GDF。
- 底层技术: 这些裁剪贴图通过 虚拟体积纹理(Virtual Volume Textures) 来实现,以高效管理内存。
- 层级组织:
- 每个 裁剪贴图(Clip Map) 存储了一系列的 距离场砖块(Distance Field Bricks)。
- 每个 砖块(Brick) 内部则存储了一个 窄带距离场(Narrow Band Distance Field),只在物体表面附近存储精确的距离值,进一步节约了存储空间。
全局距离场的高效管理与更新
全局距离场的层级结构 (Hierarchical Structure)
本节介绍了一种用于管理整个场景的全局距离场(Global Distance Field)的数据结构。其核心思想是效率与可扩展性。
-
核心数据结构:Clipmap of Bricks
- 整个场景的距离场并非一整块数据,而是由一个 层级裁剪图(Clipmap Hierarchy) 构成。
- 这个 Clipmap 管理着许多 距离场砖块(Distance Field Bricks),每个砖块负责存储场景中一小片区域的距离信息。
- 每个砖块内部存储着一个 窄带距离场(Narrow Band Distance Field)。
-
Clipmap vs. Mipmap
- 这种结构类似于网格距离场(Mesh Distance Fields)中的 Mipmap 层级。
- 但这里采用 Clipmap 是因为它更适合根据与摄像机的距离来简化场景,远处的 Clipmap 层级可以表示得更粗糙,从而实现高效的 Level of Detail (LOD)。
性能优化:应对高昂的合并成本 (Performance Optimization)
将场景中所有物体的距离场信息合并成一个全局距离场,计算开销极大。因此,必须采用激进的优化策略。
-
1. 缓存与增量更新 (Caching & Incremental Updates)
- 核心观点:绝大部分场景内容是静态的。因此,我们 积极地缓存(Aggressively Cache) 计算好的距离场砖块,并且在每一帧只更新发生变化的部分。
-
2. 时间切片更新 (Time-Sliced Updates)
- 核心观点:距离摄像机越远的区域,其更新频率可以越低。
- 通过 时间切片(Time Splicing),我们将更新预算分散到多个帧上,距离更远的 Clipmap 层级会以更低的频率进行更新,有效平滑了单帧的性能开销。
-
3. 分级的 LOD (Per-Clipmap LOD)
- 核心观点:在远处的 Clipmap 层级中,可以忽略体积较小的物体。
- 每个 Clipmap 层级都有独立的 LOD 设置,允许我们在远处剔除掉小物体。这极大地减少了远处(也是最大的)Clipmap 层级需要合并的实例数量,显著提升了更新性能。
-
4. 动静分离缓存 (Splitting Caches for Dynamic/Static)
- 核心观点:将场景中的物体分为动态和静态两类,并将其距离场信息存储在不同的砖块中。
- 通过将缓存分离为 动态砖块(Dynamic Bricks) 和 静态砖块(Static Bricks),当一个动态物体(如汽车)移动时,我们只需要更新它所影响的动态砖块,而无需重新计算其周围庞大的静态环境(如建筑)。
增量更新的 GPU 工作流程 (The Incremental Update GPU Pipeline)
为了实现高效的增量更新,整个流程被设计在 GPU 上执行。
-
追踪修改 (Track Modifications)
- 首先,系统追踪所有场景中的修改(物体移动、增删等),在 GPU 上生成一个 “已修改砖块”列表(List of Modified Bricks)。
-
两阶段剔除 (Two-Phase Culling)
- 阶段一 (Coarse Culling):将场景中的所有物体与当前的 Clipmap 进行剔除。
- 阶段二 (Fine-grained Culling):将上一阶段筛选出的物体列表,与“已修改砖块”列表再次进行剔除。
- 关键优化:在第二阶段,为了获得更精确的剔除结果,系统会 采样物体的网格距离场(Mesh Distance Fields),而不是仅仅使用简单的包围盒(Analytical Bounds)进行判断。
-
生成更新列表 (Generate Update Lists)
- 经过剔除后,得到最终需要更新的 “已修改砖块”列表,以及一个与每个砖块相关联的物体列表。
-
资源管理与更新 (Resource Management & Update)
- 根据最终列表, 分配或释放持久化的砖块内存(Persistent Bricks)。
- 开始更新砖块:遍历影响该砖块的物体列表,为砖块中的每个体素(Voxel)计算 最小距离值(min distance)。
遗留挑战:非均匀缩放 (A Lingering Challenge: Non-Uniform Scale)
在更新单个砖块的流程中,一个核心问题浮现:
- 问题描述:游戏引擎中的模型实例(Instances)经常带有 非均匀缩放(Non-uniform Scale)。
- 技术难点:存储在网格距离场(Mesh Distance Field)中的距离值,其有效性是建立在 均匀缩放(Uniform Scale) 的前提下的。当物体被非均匀拉伸或压缩时,预计算的距离值会变得不准确,这是一个在合并距离场时必须解决的棘手问题。
全局距离场:技术挑战与追踪流程
本节深入探讨了全局距离场(Global Distance Field)在实际应用中遇到的几个关键技术挑战及其解决方案,并详细阐述了其光线追踪的具体流程。
处理非均匀缩放(Non-Uniform Scale)
-
核心问题: 标准的 距离场(Distance Field) 中存储的距离值仅在 均匀缩放(Uniform Scale) 下是准确的。当物体被非均匀缩放时,距离场的度量会失效,导致追踪错误。
-
失败的尝试: 团队曾尝试通过 分析法梯度(Analytical Gradient) 来寻找表面上的最近点,并重新计算距离。但由于距离场本身分辨率有限,这种方法在实践中效果不佳。
-
有效的解决方案: 最终采用的策略是,使用 物体的分析边界(Analytical Object Bounds) 来对距离场的值进行约束(bounding)。
- 实践优势: 这种方法之所以有效,是因为大多数进行非均匀缩放的物体都是简单的几何形状(如墙壁、地板),其分析边界(如OBB)的计算和距离检测都非常高效。
动态与静态距离场的合成
- 核心任务: 当更新 动态砖块(Dynamic Bricks) 的数据时,需要将其与空间上重叠的 静态砖块(Static Bricks) 进行合成(Composite)。
- 目标: 将动态和静态两种缓存(Caches)合并,生成一个最终的、统一的距离场,以供光线追踪使用。
加速结构:粗糙映射(Coarse Map)
-
定义: Coarse Map 是一个 低分辨率(四分之一分辨率)、非稀疏(Non-Sparse) 的距离场体积。它覆盖整个场景,作为一级加速结构。
-
核心用途: 主要用于 加速空旷空间跳跃(Empty Space Skipping)。
-
设计原因: 相比于逐级遍历 Clipmap 的不同LOD,使用 Coarse Map 更加鲁棒。因为在高层级的 Clipmap LOD 中,某些较小的物体可能会被剔除或不存在,直接遍历会导致漏掉这些物体。而 Coarse Map 始终包含场景的完整(尽管是低精度)表示。
-
更新流程:
- 通过 采样全局距离场(Global Distance Field) 来完全重建整个 Coarse Map 体积。
- 执行数次 Eikonal 传播迭代(Eikonal Propagation Iterations) 来扩展距离值,确保即使在低分辨率下也能正确覆盖薄表面。
全局距离场的光线追踪(Ray Tracing)流程
-
追踪策略:
- 光线追踪从 最小(最精细)的 Clipmap 级别开始循环。
- 在当前 Clipmap 级别内进行 光线步进(Raymarch)。
- 如果没有命中,则进入下一个更大的 Clipmap 级别,继续步进,直到找到命中点。
-
单步(Per-Step)逻辑 - 两级采样:
- 粗略采样: 首先采样 连续的粗糙映射(Continuous Coarse Map) (可能是其Mipmap),进行一次大的、安全的步进。
- 精确采样: 如果粗略采样的结果表明光线已接近某个表面,则进一步采样 稀疏砖块(Sparse Bricks) 以获得精确的距离值。
-
命中后处理:
- 当光线命中表面后,通过 六次采样(Six-Tap Sampling) (即中心差分法)计算 表面梯度(Surface Gradient),从而得到法线。
- 采样 表面缓存(Surface Cache) 以获取光照所需材质属性(如Albedo、Roughness等)。
对网格距离场(Mesh DF)追踪的意义
- 关联性: 上述建立的全局距离场追踪系统,可以作为 远距离追踪的回退方案(Far-field Trace Fallback Method)。
- 带来的简化: 正因为有了这个强大的远场追踪方案,我们可以做出一个重要假设: 网格距离场(Mesh DF)追踪仅需处理短距离的光线。
- 最终结论: 在此假设下,为 Mesh DF 构建复杂的全局加速结构,如 BVH 或世界空间网格(World-Space Grids),就不再是必需的了,从而大大简化了 Mesh DF 的实现和开销。
高级软件光追管线:基于网格的加速结构
本节内容探讨了一种不依赖传统 BVH 或世界空间网格的软件光线追踪加速方案。其核心思想是根据光线类型和追踪距离,采用不同的、高度优化的网格数据结构来加速求交运算,尤其适用于短距离追踪场景。
一、 核心思想:针对短距离追踪的优化
- 核心假设: 大部分的GI或反射光线追踪距离非常短。
- 颠覆传统: 基于这个假设,我们可以放弃构建和遍历复杂的全局加速结构(如 BVH),因为它们的开销对于短光线来说得不偿失。
- 解决方案: 引入一种 影响网格 (Influence Grid)。
- 原理: 这是一种空间网格,每个单元格(Cell)内存储一个列表,该列表包含了所有“可能”与从该单元格出发的光线相交的物体。
- 优势: 在追踪时,只需加载当前位置对应单元格的物体列表,然后仅对列表中的少量物体进行求交测试,极大地简化了追踪核(Tracing Kernel)的复杂度和数据访问模式,使其非常 连贯(Coherent)。
二、 GI/反射光线追踪流程 (短距离)
针对 GI 和反射这类短距离光线,系统采用一种基于视锥体素(Fruxels)的影响网格。
网格构建流程
- 粗略视锥剔除 (Frustum Culling): 首先对场景中的所有物体进行初步的视锥剔除。
- 标记活动单元格 (Marking Active Fruxels): 识别出那些实际包含几何体的网格单元(讲座中称为 Fruxels),以避免在追踪过程中处理完全空的区域。
- 精确对象剔除 (Precise Object Culling): 将物体精确地“装箱”到它们影响的网格单元中。
- 第一步: 进行一次快速的包围盒测试(Rough Bounds Test)。
- 第二步: 对通过测试的物体,进行一次更精确的 网格距离场采样 (Mesh Distance Field Sample),以实现更紧密的剔除。
- 列表压缩 (List Compaction): 将所有单元格中的对象列表压缩到一个连续的数组中,以优化内存访问效率和GPU缓存命中率。
追踪流程
- 从某个像素开始追踪时,根据光线起点加载对应的网格单元。
- 遍历该单元格内的对象列表。
- 依次对列表中的每个物体进行 光线步进 (Raymarching),直到找到最近的交点。
三、 定向阴影光线追踪流程 (长距离)
定向光的阴影光线是相互平行的,不具备透视光线的“锥形足迹”(Cone Footprint)会随距离变宽的特性,因此必须进行全距离追踪。
关键挑战与方案
- 挑战: 短距离追踪的“影响网格”不再适用。
- 解决方案: 构建一个专门用于平行光的 光源空间3D网格 (Light Space 3D Grid)。
网格构建流程
- 空间变换: 将所有相关物体转换到光源空间。
- 对象散布 (Object Scattering): 通过光栅化物体在光源空间下的 定向包围盒 (Oriented Bounds),来确定每个物体会影响哪些3D网格单元,从而将物体ID写入这些单元格的列表中。
- 精细剔除 (Fine Culling): 在光栅化的像素着色器(Pixel Shader)阶段,通过采样 网格距离场 (Mesh Distance Field) 来进行一次额外的精细剔除,进一步减少每个单元格中的对象数量。
- 列表压缩 (List Compaction): 与GI流程类似,将最终的对象列表压缩。
追踪流程
- 从待着色的点开始,沿光线方向进行追踪。
- 加载光线路径上对应单元格的对象列表。
- 对列表中的物体进行 光线步进 (Raymarching),直到找到任意一个交点(Any-hit),即可确认该点处于阴影中并提前退出。
四、 完整追踪管线整合
整个软件光线追踪管线是一个分阶段的混合流程:
- 阶段一:屏幕空间追踪 (Screen Space Traces): 作为管线的起始,首先利用屏幕空间信息进行快速、低成本的追踪。
- 阶段二:网格SDF追踪 (Mesh SDF Traces): 当屏幕空间追踪失效(如光线移出屏幕)或需要更高精度时,启动基于上述短距离网格距离场追踪的方案来解析光线与场景的最终交点。
距离场光线追踪:实践中的问题与解决方案
本次笔记聚焦于一个混合光线追踪流程,并深入探讨了在实际应用有符号距离场(SDF)时遇到的两个关键问题及其解决方案: 开放网格(Unclosed Meshes) 和 薄片表面(Thin Surfaces) 的处理。
混合光线追踪的降级策略 (Hybrid Ray Tracing Fallback Strategy)
为了平衡性能与质量,系统采用了一种分阶段、逐级降级的策略来解析光线。光线会依次尝试以下几种追踪方式,直到命中或最终失败:
- 屏幕空间追踪 (Screen Space Traces): 首先利用屏幕空间信息进行最高效的追踪。
- 网格距离场追踪 (Mesh Distance Field Traces): 若屏幕空间未命中,则使用高精度的 网格距离场(Mesh DF) 进行短距离追踪。
- 全局距离场追踪 (Global Distance Field Traces): 若网格距离场依然未命中(例如光线超出了单个网格的DF范围),则使用覆盖整个场景的 全局距离场(Global DF) 进行更长距离的追踪。
- 天光采样 (Skylight Sampling): 如果所有追踪阶段都失败,意味着光线射向了天空或无限远处,此时会采样 天光(Skylight) 作为最终结果。
这种由高到低、由精到粗的策略是现代实时光追系统中常见的优化方法。
距离场实践中的挑战与解决方案
将理论上的距离场技术应用于实际生产环境时,会遇到由美术资产不完美导致的问题。以下是两个典型挑战及其工程解决方案。
问题一:开放网格 (Unclosed Meshes)
-
核心问题: 许多游戏资源(如扫描资产、或为单面渲染优化的模型)并非 水密(Watertight) 或封闭的。对于标准光栅化渲染,这通常不是问题。但在生成距离场时,开放的边界会导致其内部产生一个延伸到无穷远的 负距离区域 (Negative Distance Region)。这个错误的负区域会像一个巨大的“凸起”从几何体中伸出,严重干扰光线追踪的正确性。
-
解决方案:包裹负距离 (Wrapping Negative Distance)
- 在距离场生成阶段,对负距离进行限制。当一个点在表面内部的距离超过一个预设阈值时(例如 4个体素 的距离),系统会在此处 插入一个虚拟表面 (Virtual Surface)。
- 这相当于“包裹”或“钳制”了负距离的无限延伸,防止其污染周围空间。
- 权衡: 这并非完美方案。它虽然解决了大部分问题,但这个虚拟表面与光栅化渲染的实际几何体并不完全匹配,可能会在特定角度下导致光线步进(Ray Marching)与光栅化结果的 轻微不匹配 (Mismatch)。尽管如此,这远比一个巨大的错误负区域要好。
问题二:薄片表面 (Thin Surfaces) 的漏光
-
核心问题: 距离场是 离散体素化 (Discrete Voxelization) 的表示,其精度受限于体素分辨率。如果一个非常薄的表面(如一面墙、一张纸)恰好位于两个体素采样点的正中间,那么这两个采样点的距离场值都可能为正。
- 后果:
- 光线步进时,永远无法采样到零或负值,导致光线直接穿透表面,无法检测到碰撞。
- 表面的距离场 梯度 (Gradient) 在该区域接近于零,法线计算会出错。
- 严重影响: 在室内外光照对比强烈的场景中(如明亮的室外和黑暗的室内),即使只有一缕光线穿透墙壁,也会造成灾难性的 漏光 (Light Leaks)。
- 后果:
-
解决方案:扩展距离场 (Expanding the Distance Field)
- 为了确保即使是最薄的表面也能在离散的距离场中被“捕捉”到,需要人为地将其“加厚”。
- 具体做法是在距离场生成时,将所有表面的距离场向外 扩展半个体素对角线的距离 (Expand by a half a voxel diagonal)。
- 这个操作保证了任何几何体(无论多薄)都会对至少一个体素的距离场值产生显著影响,从而确保光线步进能够 可靠地命中 (Reliably Hit) 这些表面,有效杜绝了因精度问题导致的漏光。
Distance Field 光线追踪的鲁棒性优化:Surface Expand 技术
本节课深入探讨了在使用距离场(Distance Field)进行光线追踪(尤其是在阴影和反射中)时,为解决 薄表面(thin surfaces)漏光 和 自相交(self-intersection) 问题而采用的一系列被称为 "Surface Expand" 的启发式优化技术。
基础问题与朴素解决方案
1.1. 核心问题:漏光与采样不准
- 漏光 (Leaking): 在进行光线步进(Ray Marching)时,光线可能会因为步长过大而“跳过”或“穿透”非常薄的物体,导致错误的无遮挡结果,即漏光。
- 梯度计算不准 (Inaccurate Gradient): 在靠近物体表面的地方,距离场的值可能变化剧烈或不够精确,导致计算出的表面法线(梯度)不准确。
1.2. 朴素解决方案:恒定的 Surface Expand
为了解决上述问题,引入了一个简单的修复方法: 表面扩张 (Surface Expand)。
- 核心思想: 在光线步进的每一步,从采样到的距离场值中减去一个小的常数(例如,半个体素对角线长度)。这相当于人为地将场景中所有物体的表面都“加厚”了。
- 实现方式:
- 这是一个 运行时 (runtime) 操作,意味着它不会修改原始的距离场数据,具有很好的灵活性。
- 优点:
- 可靠命中: 加厚后的表面更容易被光线步进“捕获”,有效解决了薄表面的漏光问题。
- 修正梯度: 由于我们在离真实表面稍远的地方进行采样和判断,这里的距离场值更可靠,计算出的梯度也更稳定。
- 致命缺点:
- 过度遮挡 (Over-occlusion): 整体加厚表面会导致不必要的遮挡,使场景变暗。
- 破坏接触阴影 (Breaks Contact Shadows): 为了避免光线出发时立即与自身“加厚”后的表面相交,必须设置一个很大的 表面偏移 (Surface Bias)。这个偏移导致光线直接跳过了最开始的一段距离,从而完全丢失了物体与表面接触点处的精细阴影。
改进方案 1:针对阴影的动态 Surface Expand
为了在解决漏光问题的同时保留接触阴影,我们对 Surface Expand 进行动态调整。
-
核心思想: 让 Expand 的大小不再是常数,而是随着光线行进的距离动态变化。
-
算法描述:
- 起点: 在光线起始点(即被着色的表面),Expand 值设为 0。这保证了我们可以追踪光线离开表面的初始片段,从而保留接触阴影。
- 中段: 随着光线远离起点, 线性增加 (linearly increase) Expand 的值,以确保能命中远处的薄物体。
- 终点: 当光线接近其最大追踪距离(例如,快要到达光源时),再将 Expand 的值 线性减小回 0。这可以防止光线错误地与光源所在的表面相交。
-
新的问题:
- 掠射角下的自相交 (Self-intersection at Glancing Angles): 当光线以非常小的角度(掠射角)离开表面时,Expand 值增加得过快。这会导致光线的步进安全区(Sphere Tracing 的球体)反过来与它刚刚离开的表面再次相交,造成错误的自遮挡。
- 适用场景: 这种瑕疵对于 全局光照 (GI) 或 漫反射 (Diffuse Rays) 影响较小,但在 清晰反射 (Reflections) 中会产生非常明显的错误遮挡瑕疵。
改进方案 2:针对反射的自适应 Surface Expand
为了解决掠射角下的自相交问题,特别是在反射场景下,引入了第二种启发式方法。
-
核心思想: Expand 的大小不再仅仅依赖于沿光线的行进距离,而是根据每一步光线位置与表面的当前距离自适应调整。
-
算法描述:
- 在光线步进的 每一步 (every step),根据当前步进点到最近表面的距离,计算出 当前可能的最大 Expand 值。
- 这个值的选择原则是:既要足够大以避免漏光,又要足够小以确保下一步不会发生自相交。
- 本质: 这确保了光线总能成功“逃离”起始表面,因为它在最危险的、离表面最近的阶段,Expand 值是经过仔细计算的。
-
权衡与效果:
- 这种方法在处理反射时,宁愿接受 轻微的漏光 (a bit of leaking),也要避免 过度遮挡 (over-occluding) 带来的严重视觉瑕疵。
最终效果总结
通过结合使用这些先进的 Surface Expand 技术,最终实现了一个鲁棒的光线追踪系统,它:
- 成功保留了接触阴影。
- 能够可靠地命中薄物体表面,避免了漏光。
- 有效处理了反射中的自相交问题,提供了高质量的视觉效果。
Distance Field Ray Tracing 的进阶技术与优化
本节内容主要探讨了在使用距离场(Distance Field, DF)进行光线追踪时,如何处理两个棘手的特殊情况: 植被(Foliage) 和 动画。同时,也总结了该技术的核心优势与适用场景。
解决薄表面与植被的难题:Coverage(覆盖度)
传统的 Distance Field Expand (距离场扩展)技术,通过在步进时人为地“加厚”表面,能有效防止光线穿过薄墙等固体几何体,保证接触阴影的正确性。但这种方法对于植被等半透明集合体则会产生问题,因为它会错误地将叶片间的缝隙完全堵死,阻止所有光线穿过。
为了解决这个问题,引入了一种新的启发式技术—— Coverage(覆盖度)。
-
核心思想: Coverage 是一种用于区分固体薄表面(应完全挡光)和具有部分透明度的表面(如叶片,应允许部分光线穿过)的机制。
-
实现方式:
- 标记实例: 首先,根据材质属性(例如,是否为 two-sided material)来标记几何体实例。
- 生成通道: 将这些标记信息重新采样(resample),并存入一个 独立的全局距离场通道(a separate global distance field channel) 中。这个通道就代表了场景中各处的“覆盖度”或“通透度”。
-
在光线步进(Ray Marching)中的应用: 在光线步进的每一步,都会采样
Coverage值,并根据该值动态调整追踪策略:- 调整步进参数: 根据
Coverage值,动态地 增减光线步进步长(step size) 和 Expand 参数。例如,在一个区域Coverage很低(代表这里更通透,如树叶之间),就可以安全地增大大步长,并减小 Expand 的影响,让光线更容易穿过。 - 随机透明度(Stochastic Transparency): 当光线与表面发生碰撞(hit)时,会利用
Coverage值进行一次随机判断:- 接受命中: 认定光线被该表面阻挡。
- 继续追踪: 忽略本次命中,让光线继续向前传播,模拟光线从叶片间隙穿过的效果。
- 调整步进参数: 根据
通过引入 Coverage,树木不再是完全阻挡光线的实体,光线可以在树叶间穿梭和反弹,极大地提升了植被场景的真实感。
处理动画植被
距离场技术的一大限制是它基于 预计算(precomputed) 数据,因此原生不支持动画。当植被(如随风摇曳的树木)发生动画时,静态的距离场与实际模型位置不匹配,会导致严重的 自遮挡(self-shadowing) 问题。
- 解决方案:
针对标记为植被的物体(可以复用
Coverage通道的信息),在光线命中时施加一个 额外的表面偏移(extra surface bias)。这个偏移会将着色点稍微推离表面,有效避免了因动画错位而导致的错误自阴影。
Distance Field 技术的优势与适用场景
尽管存在上述挑战并需要特殊处理,Distance Field Ray Tracing 仍然是一项非常有价值的技术。
-
光照效果与质量:
- 对于 镜面反射(mirror reflections),效果并不完美,因为距离场本身是场景的低精度近似。
- 但对于 全局光照(Global Illumination, GI) 和 粗糙反射(rough reflections),其表现非常出色。它能够精确地解析出由间接光照产生的细微阴影细节(例如台灯或电视在墙上投射的间接阴影),且成本可控。
-
硬件与平台兼容性:
- 这是该技术最核心的优势之一:它不需要任何特殊硬件支持(如光线追踪核心 RT Core)。
- 因此,它可以在所有平台上运行,具备极佳的跨平台兼容性,使其成为一种普适性很强的渲染解决方案。
距离场追踪的挑战与表面参数化需求
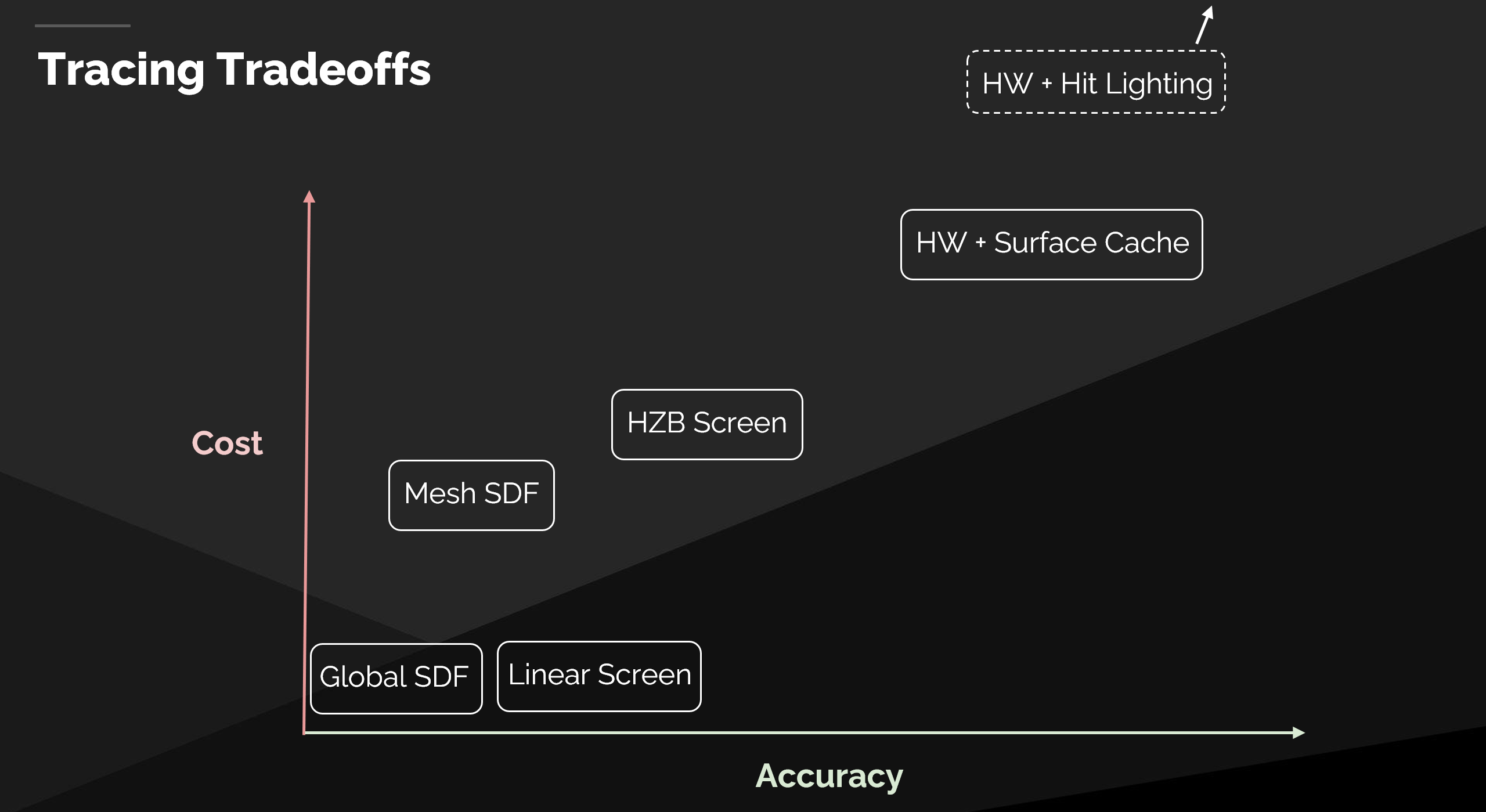
距离场(Distance Fields)的核心优势回顾
在深入探讨 Lumen 面临的技术挑战之前,讲座首先总结了选择距离场作为核心追踪结构的原因。
-
硬件无关性 (Hardware Agnostic):
- 核心观点: 距离场追踪无需特殊的硬件光追单元(如 RT Cores),使其能够在所有支持 Shader Model 5 的平台上运行,具备出色的跨平台兼容性。
-
引擎通用性 (Engine Versatility):
- 核心观点: 距离场并非仅为 Lumen 服务,它是一种通用的引擎级功能。
- 关键术语: 引擎功能复用 (Engine Utility)。场景的距离场构建工作可以被多个系统共享,例如粒子碰撞、物理模拟等,从而分摊了预计算的成本。
-
高度可伸缩性 (High Scalability):
- 核心观点: 距离场能够高效处理极其复杂的场景。
- 关键术语: 通过在运行时将场景中所有对象的距离场 合并(Merge) 成一个 全局距离场(Global Distance Field),Lumen 可以有效处理包含大量重叠实例(Instance Overlap)的复杂情况。
核心难题:如何为距离场命中点着色?
这里引出了一个关键问题,即所谓的“房间里的大象” (elephant in the room):距离场本身只提供了几何信息,我们如何获取其表面的材质和光照信息?
-
问题的根源:数据缺失
- 核心观点: 距离场是一种隐式表面表示,它不包含任何顶点属性(如 UV 坐标、顶点颜色等)。
- 通过距离场追踪,我们能获取的信息仅限于: 命中点位置 (Position) 、 法线 (Normal) 和 网格实例数据 (Mesh Instance Data)。
- 这意味着我们 无法直接在其上运行常规的材质着色器 (Material Shaders)。
-
性能瓶颈:递归追踪的昂贵代价
- 核心观点: 在每次光线命中时,都完整地重新计算材质和光照是不可行的,尤其是在多弹射(Multi-bounce)全局光照中。
- 材质评估成本: 现代游戏中的 材质图(Material graphs) 可能非常复杂且评估成本高昂。
- 光照评估成本: 带有多个投射阴影光源的直接光照计算同样非常耗时。
- 递归成本: 对于多弹射GI,每次命中后都需要递归地追踪更多光线,这种计算开销会呈指数级增长,Lumen 无法承受。
理想解决方案:对表面参数化(Surface Parameterization)的要求
为了解决上述问题,Lumen 需要一种新的、不依赖传统顶点属性的表面信息表示方法。这种方法被称为表面参数化,并且必须满足以下严苛要求:
-
1. 无需 UV 的表面表示 (UV-less Surface Representation):
- 核心观点: 必须设计一种不依赖 UV 贴图就能获取表面属性(如反照率 Albedo)的机制。
-
2. 支持计算结果的缓存 (Caching):
- 核心观点: 该表示方法必须能作为缓存载体,用于存储预计算的材质和光照信息。这是避免昂贵的实时递归计算、实现多弹射 GI 的关键。
-
3. 基于表面空间 (Surface-Space Based):
- 核心观点: 参数化方案应基于表面空间,而不是体积空间(Volumetric)。
- 原因: 基于体积的方案(如 Voxel)在处理 薄壁结构(Thin Walls) 时表现不佳,容易导致 漏光(Light Leaks) 问题。
-
4. 强大的可伸缩性 (Scalability):
- 场景复杂度伸缩: 必须能够高效参数化包含 海量实例(Huge number of instances) 的复杂场景。
- 质量伸缩: 方案需要支持 分辨率的动态提升(Scale up in resolution),以满足高质量渲染的需求,例如在渲染 反射(Reflections) 时提供更精细的细节。
Lumen 的表面参数化方案:Projected Cards
背景与目标
为了在 Lumen 中实现高质量的GI和反射,需要一种能够动态扩展分辨率的表面参数化(Surface Parameterization)方法。这种方法需要将复杂的网格表面信息(如材质、光照)存储在一种易于查询的数据结构中。
传统方案的局限性
在选择最终方案前,团队评估了多种常见的表面参数化技术,但都因不满足 Lumen 的需求而被否决。
-
UV 贴图 (UVs)
- 核心问题:对于复杂模型,会产生大量零碎的 UV Chart,整合(merge)这些 Chart 非常困难且不稳定。
- 技术限制:依赖于顶点属性(Vertex Attributes),而 Lumen 的管线在某些阶段无法访问这些数据。
-
体积 UV (Volumetric UVs)
- 核心问题:无法精确表示 薄壁(thin walls) 结构,例如一片叶子或一张纸。
- 技术限制:在处理远距离 LOD(Level of Detail)时,如何正确地进行降采样和过渡,方案并不明确。
-
体素颜色 / Surfels (Voxel Colors / Surfels)
- 核心问题:分辨率受限,难以满足高质量反射等需要精细细节的场景。
Lumen 的解决方案:Projected Cards
Lumen 最终采用了一种称为 Projected Cards 的方案。该方案可以被理解为由 "面元(surfels)" 组成的、均匀的、矩形的簇。
核心优势
- 无需顶点属性:Cards 是基于 投影(Projection-based) 生成的,完全不依赖网格的顶点属性。
- 快速查找:拥有 规整的结构(regular structure),因此查找和采样效率非常高。
- 运行时捕获与动态缩放:可以在 运行时(runtime) 动态生成,无需任何预烘焙(baking),并且可以根据需求扩展到任意分辨率。
- 支持薄壁结构:能够有效表示双面薄壁的几何体。
生成流程
Cards 的生成是一个在 网格导入(mesh import) 时进行的 预计算(Precomputation) 步骤。
-
设计决策:轴对齐
- 所有的 Cards 都被设计为 轴对齐(Axis-Aligned) 的。
- 原因:团队曾尝试过自由朝向(freely oriented)的 Cards,但发现其生成过程非常复杂,而带来的灵活性提升并不足以弥补其复杂性成本。轴对齐简化了生成和查找过程。
-
具体生成步骤
-
体素化简化(Voxelization):
- 将输入的三角网格数据进行体素化,转换成一组轴对齐的表面。
- 目的:通过移除微小的几何细节来简化网格,为后续处理提供更规整的数据。
-
聚类(Clustering):
- 使用一种受 K-Means 启发的聚类算法,将上一步生成的离散surfels聚合成簇。
-
生成 Cards:
- 将聚类后的结果转换为最终的 Projected Cards。
-
-
回退机制 (Fallback Mechanism)
- 如果生成过程中出现问题(例如,网格结构过于复杂难以展开,或网格本身太小),系统会 回退到一种类似立方体贴图的六面投影方案(six-sided cube map like projection),以保证鲁棒性。
网格面元化与初始聚类生成
本节核心内容是讲解如何将一个传统的三角网格(Triangle Mesh)转换为一种更易于处理的、基于面元(Surfel)的离散化表示,并在此基础上生成初始的几何簇(Cluster)。
第一阶段: 从三角网格到面元的转换与属性计算
这个阶段的目标是将连续的三角网格表面,转换成一系列离散的、带有丰富属性信息的面元(Surfel),为后续的聚类操作做数据准备。
1. 网格体素化与面元生成 (Voxelization & Surfel Generation)
- 核心观点: 通过在二维网格上进行光线投射,将三维模型离散化为一组位于体素单元(3D Cell)中的 面元 (Surfel)。
- 实现方法:
- 在一个二维平面网格(2D Cell)上, 每个单元格投射 64 条光线 穿过目标模型。
- 统计每条光线在三维体素单元内的 命中次数 (Ray Hits)。
- 如果一个体素单元内的命中次数超过预设阈值,就在该位置生成一个面元。
2. 计算面元的核心属性
为每个生成的面元计算并存储一系列属性,这些属性将在后续的剔除和聚类步骤中作为决策依据。
-
表面覆盖率 (Surface Coverage):
- 定义: 直接使用光线命中次数作为该面元的覆盖率值。
- 用途: 用于后续评估一个聚类(Cluster)的有效性或重要性。覆盖率高的区域通常代表着更坚实、更重要的几何表面。
-
可见性信息 (Visibility Information):
- 定义: 存储光线 上一次命中的位置 (Previous Ray Hit Position)。
- 用途: 用于后续判断该面元是否能从其所属聚类的 近平面 (Near Plane) 被看到,是聚类过程中一个重要的可见性测试依据。
3. 无效面元的过滤与剔除 (Filtering & Pruning)
生成初步的面元集合后,需要剔除掉无效或不重要的部分,例如模型内部的面元。
-
内外剔除 (Inside/Outside Test):
- 核心观点: 通过分析光线与三角面片的朝向关系,判断面元是位于模型表面还是内部。
- 实现方法: 从每个面元的位置再次投射 64 条光线,并统计与三角面片 背面 (Back Face) 的命中次数。
- 剔除规则: 如果大部分命中都是背面,则认为该面元位于几何体内部,应予以丢弃。
-
遮挡计算 (Occlusion Calculation):
- 核心观点: 计算一个面元的被遮挡程度,作为其重要性的度量。
- 实现方法: 遮挡值基于光线命中点到面元的 平均距离 (Average Distance to Hits) 来计算。距离越远,通常意味着越开阔,遮挡越少。
- 用途: 遮挡值将在后续聚类时,用来决定优先聚合哪些面元。通常,遮挡较少的面元更重要。
第二阶段: 初始聚类的生成 (Initial Cluster Generation)
在获得了带有丰富属性的面元集合后,此阶段的目标是将它们分组,形成覆盖整个网格表面的初始聚类。
1. 聚类生成算法概述
- 核心观点: 这是一个 贪心算法 (Greedy Algorithm),通过“选取种子、迭代式增长”的方式来构建每个聚类。
- 基本流程:
- 选取一个尚未被分配的 面元作为种子 (Seed),开始一个新的聚类。
- 以该种子为中心,迭代式地向聚类中添加最合适的邻近面元。
- 当一个聚类生长完成,再选取下一个未分配的面元作为新种子,重复此过程,直到所有面元都被分配。
2. 聚类生长过程中的加权评估 (Weighting Heuristics)
在迭代增长阶段,算法需要决定下一个“最佳”的待添加面元。这是通过一个加权评分系统实现的,综合考虑多个因素:
- 距离权重: 优先选择距离当前聚类边界最近的面元。
- 重要性权重: 优先选择 遮挡最少(最重要) 的面元。
- 形状权重: 优先选择能使聚类形状更接近正方形的面元(通过
Cluster Ratio进行评估)。 - 可见性检查: 候选面元必须能从聚类的近平面被看到(使用第一阶段存储的可见性信息)。
3. 聚类的迭代与优化
- 生长循环: 不断根据上述加权评估,添加最佳的候选面元,直到找不到合适的候选者为止。
- 质心优化 (Centroid Refinement):
- 当一轮生长停止后,计算当前聚类的 质心 (Centroid)。
- 以新的质心为中心,重新开始一轮生长。这个过程被称为“Regrow”。
- 重复“Regrow”过程,直到达到预设的迭代次数上限,或者聚类不再发生变化。
- 最终结果: 将稳定下来的聚类添加到最终列表中。
4. 阶段性总结与局限性
- 覆盖性: 经过上述步骤,整个网格表面会被一系列初始聚类完全覆盖。
- 局限性: 这种贪心算法生成的聚类只是局部最优的, 不一定是全局最优解 (Globally Optimal)。这意味着后续可能还需要进行全局优化步骤来改善聚类的质量。
阶段三:全局优化与场景管理
在前一阶段,我们通过局部生长生成了覆盖整个网格的簇 (clusters)。但这些簇的布局可能并非全局最优。本节将介绍如何通过全局优化来改善簇的质量,并讨论如何在整个场景中高效地管理最终生成的几何卡片 (Cards)。
一、 全局优化 (Global Optimization)
这一步的目标是对局部生长生成的簇进行最终的调整和筛选,以获得更理想的布局和性能。
核心观点
通过并行的、迭代的生长过程,从现有簇的中心点出发重新划分区域,以达到全局更优的覆盖效果。
关键步骤
-
并行生长 (Parallel Growing)
- 方法:以当前所有簇的 质心 (centroids) 为种子点,并行地重新“生长”所有簇。
- 目的:打破局部优化的限制,让簇的边界在全局范围内重新竞争和分配,从而找到更好的整体布局。
-
迭代与收敛 (Iteration & Convergence)
- 这个并行生长的过程会迭代数次,直到簇的布局不再发生显著变化或达到预设的迭代次数上限为止。
-
清理与填充 (Cleanup & Fill)
- 并行生长可能会产生一些副作用,比如出现 过小的簇 (two small clusters) 或 未被覆盖的空白区域 (empty space)。
- 因此,在每次迭代后,需要执行一个清理步骤:
- 移除那些面积过小的、无效的簇。
- 在产生的空白区域中尝试插入新的簇。
-
最终筛选与转换 (Final Selection & Conversion)
- 优化完成后,根据每个簇的 覆盖范围 (Coverage) 进行排序。
- 选择覆盖范围最大的、最重要的前 N 个簇(N 由用户指定),将它们最终转换为用于渲染的 几何卡片 (Cards)。
二、 场景中的卡片管理 (Card Management in the Scene)
生成了单个物体的卡片后,我们需要一个系统来管理整个场景中成千上万的卡片。这里的核心挑战在于如何满足两种截然不同且相互冲突的渲染需求。
核心观点
渲染全局光照 (GI) 和高质量反射 (Reflections) 对卡片的要求截然相反。GI需要广泛、低精度的覆盖,而反射需要局部、高精度的细节。
两种冲突的需求 (Conflicting Needs)
-
全局光照 (Global Illumination - GI)
- 需求: 大量、小型、低分辨率 的卡片。
- 原因:GI 是一个低频效果,主要处理光线的多次反弹,不需要极高的细节。更重要的是保证场景表面被持续且无缝地覆盖,以捕捉间接光照。
- 关键: 一致的覆盖率 (Consistent Coverage)。
-
反射 (Reflections)
- 需求: 少量、大型、高分辨率 的卡片。
- 原因:对于镜面反射等高频效果,卡片上的内容需要足够清晰,其分辨率甚至需要 匹配屏幕像素密度 (match screen pixel density),才能避免反射内容模糊不清。
- 关键: 特定表面的高细节 (High Detail on Selected Surfaces)。
解决方案:虚拟表面缓存 (Virtual Surface Cache)
为了同时满足这两种需求,系统引入了 虚拟表面缓存 (Virtual Surface Cache) 的概念,对不同用途的卡片采用不同的管理策略。
-
针对 GI 的管理策略
- 技术:使用 低分辨率、常驻内存的页面 (low-resolution, always-resident pages)。
- 实现:
- 这些页面始终存在于内存中,围绕摄像机根据距离进行分配。
- 系统还包含一个 LOD 方案,例如在远处移除过小的卡片,以优化性能。
-
针对反射的管理策略
- 技术:使用 稀疏、按需加载的页面 (sparse and optional on-demand pages)。
- 实现:
- 高分辨率的卡片数据平时不占用内存,只有当需要它们的反射表面进入视野或变得重要时,才按需加载。
- 这种方式极大地节约了显存和带宽,使得在需要时提供高质量反射成为可能。
表面缓存的动态内存管理
本节深入探讨了用于实时反射的表面缓存(Surface Cache)所采用的一套高效、动态的内存管理机制。其核心思想是避免静态预分配,转而采用基于光线追踪反馈的按需分配与回收策略,并结合多种优化手段来最大化内存利用率和查询效率。
动态页面管理:稀疏与按需分配
这是整个系统的基石,旨在确保内存资源只分配给当前视锥内实际需要渲染的表面。
- 核心观点: 表面缓存的内存不被预先全部保留,而是以 稀疏页面(Sparse Pages) 的形式存在。只有当反射光线实际命中某个表面时,系统才会为其 按需(On-demand) 分配物理内存页面。
- 生命周期管理:
- 分配(Allocation): 基于 反射光线命中(reflection ray hits) 的结果,动态分配新的页面。
- 回收(Deallocation): 当一个页面在一段时间内 不再被使用(no longer in use) 时,系统会将其回收,释放内存资源。
GPU端反馈与请求压缩
为了让CPU能够做出明智的页面调度决策,GPU在渲染过程中会持续收集反馈信息,并进行高效的预处理。
- 核心观点: 在每次光线命中时,GPU会生成 表面缓存反馈(Surface Cache Feedback),该反馈包含了页面的重要性信息,并通过一个高效的压缩流程来减少CPU的负担。
- 关键步骤:
- 随机选择(Stochastic Selection): 一次光线采样可能会混合多个页面的数据。为了生成精确的反馈,系统会 随机选择(stochastically select) 其中最重要的一个页面进行反馈。
- 写入反馈信息: 对于被选中的页面,系统会更新其 最后使用时间(last use time),并将当前渲染所需的 MIP层级(requested MIP level) 写入一个临时的 反馈缓冲区(Feedback Buffer)。
- GPU端压缩(GPU Compaction):
- 去重: 将反馈缓冲区中的所有请求插入到一个 GPU哈希表(GPU Hash Table) 中,利用哈希表的特性自然地去除重复的页面请求。
- 紧凑化: 将哈希表中的唯一请求及其附加信息(如命中次数)压缩成一个紧凑的 请求数组(Request Array)。
CPU端页面调度
CPU接收到GPU处理好的紧凑请求列表后,执行最终的内存管理决策。
- 核心观点: CPU负责最终的页面 映射(map) 和 解映射(unmap) 操作。
- 工作流程:
- 数据下载: GPU上生成的紧凑请求数组被下载到CPU内存。
- 决策制定: CPU对该数组进行 排序(sort) (例如,可以根据命中次数、请求的MIP级别等),然后决定哪些新页面需要映射,哪些旧页面需要解映射。并进行映射和解映射。
物理页面分配策略:子分配与拆分
为了在不浪费内存的前提下支持不同尺寸的缓存需求,系统采用了一种灵活的分配策略。这里的 "卡片(Card)" 可以理解为逻辑上的缓存单元。
- 核心观点: 通过 子分配(Sub-allocation) 和 拆分(Splitting) 机制,系统既能高效利用大尺寸物理页面,又能精确支持小尺寸的缓存请求,从而最小化内存碎片和浪费。
- 两种情况:
- 大尺寸卡片(> 页面大小): 将该卡片 拆分(split) 成多个物理页面,并为每个部分单独分配。
- 小尺寸卡片(< 页面大小):
- 系统会先映射一个完整的物理页面。
- 然后使用一个2D分配器(2D allocator) 在这个物理页面内部为多个小尺寸卡片划分空间。
- 优势: 这种方法允许系统使用较大的物理页面尺寸(减少管理开销),同时又不会因为微小的缓存需求而浪费整个页面的内存。
查询优化:扁平化查找与回退机制
为了保证渲染的稳定性和性能,即使请求的数据尚未加载,也必须能快速返回一个有效的数据。
- 核心观点: 通过构建一个扁平化的页表(Flattened Page Table),实现单次查询即可获得有效数据,避免了递归或多步查找的开销。
- 实现机制:
- 当着色器请求一个当前缺失的高分辨率页面(missing high-res page) 时,页表中的条目会自动指向一个始终驻留的低分辨率回退页面(always resident low-resolution fallback page)。
- 优势: 这种设计使得表面缓存的采样操作始终是一次查找(a single lookup) 即可完成,极大地提升了查询效率,并能优雅地处理数据还未流式加载完成的情况。
数据填充
最后,分配好的内存页面需要被填充上实际的几何与材质信息。
- 核心观点: 成功分配并映射的卡片(Cards)需要被填充网格(mesh) 和材质(material) 数据,这些数据后续将在渲染时被投影到对应的表面上。
Surface Cache 的运行时填充与优化
这部分内容详细阐述了 Lumen 系统中一个被称为 "Card" 或 "Surface Cache" 的核心组件是如何在运行时被动态填充和管理的。其核心思想是为场景中的物体创建一个代理(Proxy)几何的纹理化表示,以便进行高效的光线追踪。
一、 Card Capture 的核心概念
-
核心观点: Card Capture 是一个在运行时将场景中静态网格(Static Meshes)的材质和几何信息“烘焙”到二维纹理(即 "Cards")上的过程。这些 Cards 稍后将作为光线追踪的代理几何体,被投射回场景表面。
-
关键优势:
- 动态性与灵活性: 在运行时进行捕获,意味着可以动态调整缓存的分辨率,并且完美支持运行时的材质变更(例如,材质实例参数的修改),无需任何预计算数据的管理负担。
- 无需预计算: 整个过程是实时的,省去了漫长的预计算步骤和大量预计算数据的存储。
二、 运行时捕获流程 (Runtime Capture Process)
-
捕获机制:
- 使用一个正交相机(Ortho Camera) 来渲染目标网格。
- 将表面的核心属性,如反照率(Albedo) 和法线(Normals),写入到 Card 贴图中。
-
更新策略:基于预算的缓存管理
- 请求收集: 每一帧,系统会收集需要更新的 Card 页面(Pages)的请求。
- 优先级排序: 对这些请求进行排序,主要依据两个标准:
- 与主摄像机的距离: 距离越近,优先级越高。
- 上次使用时间: 最近使用过的,优先级越高。
- 预算执行: 根据一个固定的预算(Fixed Budget),每帧只挑选并更新一小部分最重要(优先级最高)的 Card 页面。
- 支持动画材质: 为了处理材质动画(例如,水面、闪烁的灯光),系统会额外更新一小部分最旧(Oldest) 的页面,确保缓存不会因时间过长而失效。
三、 Nanite 加速与性能优化
-
传统方法的痛点: 传统上,渲染大量小型网格到许多小型渲染目标(Render Targets)上是非常缓慢的,主要瓶颈在于:
- 复杂的 LOD(Level of Detail) 管理。
- 大量的、开销高昂的绘制调用(Draw Calls)。
-
Nanite 的解决方案:
- 单一绘制调用: 借助 Nanite,可以将场景中所有相关的几何体合并到一个单一的绘制调用中进行渲染,极大地降低了 CPU 开销。
- 连续 LOD: Nanite 提供了连续的细节级别(Continuous LOD),可以平滑地、高效地将复杂的网格简化到适合渲染到微小 Card 目标上的程度。
-
最终效果: Nanite 极大地提升了 Card Capture 的渲染速度,使得系统可以更频繁地更新 Surface Cache,提高了缓存的时效性和质量。
四、 捕获数据的结构与处理
-
类 G-Buffer 结构:
- Card Capture 的过程类似于生成一个视图无关(View-Independent) 的 G-Buffer。它将材质和几何数据重新组织成一种固定的、标准化的数据结构,便于后续统一处理。
-
材质属性近似:
- 为了简化数据,系统会近似处理高光(Specular)和次表面散射(Subsurface Scattering) 的能量损失。这是通过修改 Albedo 来实现的,将这部分损失的能量计入 Albedo 中,从而在简化的数据结构中保留部分光照响应的真实性。
-
数据有效性标记:
- 系统会标记无效的纹素(Invalid Texels)。这非常重要,因为它让后续的采样过程能够知道哪些区域不包含有效的表面数据,从而避免采样错误。
-
Alpha Masking 的特殊处理:
- 在捕获阶段,系统会禁用 Alpha Masking(透明遮罩)。
- 目的: 这是为了明确区分 “该区域没有表面(Lack of Surface)” 和 “该区域是透明的(Alpha Masked)” 这两种情况。
- 好处: 这种区分使得后续运行任何命中着色器(Hit Shader) 时,Sample Opacity 来处理相关的逻辑。
-
数据压缩:
- 最后,所有捕获到的 Surface Cache 数据都会在运行时进行压缩,以最小化其在显存中的占用。
Card Merging
本节深入探讨了在准备好 Surface Cache 数据之后,如何进行高效的采样以获取表面属性,并介绍了一种针对大量小型实例聚合场景的关键优化技术——卡片合并(Card Merging)。
Surface Cache 采样流程
在填充并压缩完 Surface Cache 后,我们需要在运行时对其进行采样,以获取任意光线命中点的表面属性。这是一个多步骤、经过精心设计的流程。
- 核心前提: 为了最小化内存开销,Surface Cache 的数据在运行时是实时压缩的。
采样步骤分解
-
网格索引查找: 根据光线命中的网格索引(mesh index),首先在全局数据结构中找到对应的卡片网格(card grid)。
-
单元格定位: 在该网格中,根据命中点的世界坐标定位到具体的单元格(cell),获取该单元格关联的六张卡片(six cards)。这六张卡片从六个正交方向(类似Cubemap)描述了该空间区域的几何与材质信息。
-
卡片筛选: 根据着色点的表面法线(surface normal),从六张卡片中选取投影效果最好的三张进行后续采样。
-
三卡片采样与加权: 对选出的三张卡片分别进行采样,并对结果进行一系列加权处理,以保证最终结果的鲁棒性和准确性。
- 手动双线性滤波: 为每个采样点,从 Surface Cache 中抓取四个深度值,以手动执行双线性滤波(manual bilinear filtering),获得更平滑的深度插值。
- 遮挡剔除加权: 通过比较 光线命中深度 与 Surface Cache中存储的深度 之间的差值(delta),对采样结果进行加权。这个权重可以有效剔除或减弱被遮挡的样本对最终结果的贡献。
- 投影拉伸校正: 使用卡片投影法线对采样结果进行加权,以防止因投影角度过大导致的拉伸(stretching) 瑕疵。
- 无效数据剔除: 舍弃那些在生成阶段被标记为无效(invalid) 的纹素(texel)。
-
最终混合: 将所有经过筛选和加权的有效采样结果混合(blend) 在一起,计算出光线命中点的最终 Surface Cache 属性(如材质、辐照度等)。
针对密集实例的优化:卡片合并(Card Merging)
在处理特定类型的内容时,传统方法会遇到性能瓶颈。
问题背景
当场景中存在大量微小实例(small instances) 聚合形成一个宏观大物体时(例如,一栋由许多小砖块、窗框等独立模型组成的建筑),会产生以下问题:
- 卡片数量爆炸: 为每一个小实例都生成卡片会产生海量的卡片,造成严重的性能和内存负担。
- 信息丢失: 如果因为卡片尺寸限制而无法为这些小实例生成卡片,就会导致这个宏观物体完全丢失 GI 信息。
解决方案:运行时卡片合并
为了解决此问题,系统采用了一种在运行时合并卡片(Merge Cards at Runtime) 的策略。
-
核心机制:
- 实例分组: 通过以下两种方式之一将小实例聚合成分组:
- 自动分组: 算法自动寻找空间上重叠的小型实例并将其归为一组。
- 手动标签: 由美术或开发者提供分组标签(group tags) 来指定哪些实例属于同一组。
- 立方体式捕捉: 为每一个实例组分配六张卡片,像立方体贴图(Cube Map) 一样,从六个正交方向(上、下、左、右、前、后)捕捉整个组的宏观几何与材质信息。
- 高效捕捉: 在生成卡片时,将整个实例组作为一个整体渲染到每一张卡片中。得益于 Nanite 的高效率,即使是复杂的聚合体,这个渲染过程也依然非常快速。
- 实例分组: 通过以下两种方式之一将小实例聚合成分组:
-
关键假设: 这种方法是一个非常有效的近似,其前提是观察者位于聚合体的外部。对于像建筑这样的物体,这个假设在绝大多数情况下都是成立的。
承上启下:从材质到光照
通过上述的采样和优化流程,我们已经能够高效、准确地在任意命中点查询到场景的材质数据。
- 下一步: 接下来的挑战是,如何利用这些已经缓存好的材质和几何信息,来计算最终的光照结果。这为讲座的下一部分内容——光照计算,埋下了伏笔。
利用 Surface Cache 计算和缓存光照
本节聚焦于如何利用已经构建好的 Surface Cache 来解决昂贵的多 bounces 光照计算问题,并引入了一套增量式的缓存更新策略来优化性能。
核心思想:将 Surface Cache 作为动态光照贴图 (Light Map)
讲座的核心思路是将光照计算与 Surface Cache 深度绑定,从而避免每次都进行昂贵的光线追踪。
- 动机:
- 传统的 多 bounces 光线追踪(例如,带有多条阴影光线的直接光照或递归追踪的间接光照)对于实时渲染来说开销极大。
- 在许多场景中,如果缺少间接光照,场景会显得极不真实,例如大面积的纯黑区域和消失的反射。
- 解决方案:
- 既然 Surface Cache 已经包含了场景的几何与材质信息,我们可以将光照计算结果也缓存到其中。
- 这种方法本质上是将 Surface Cache 变成了一种动态的、按需生成和更新的 Light Map,所有的光照信息都可以理想地从这个缓存中采样得到。
类似 Light Mapping 的挑战与解决方案
将 Surface Cache 用作光照贴图时,会遇到与传统烘焙 Light Map 类似的经典问题。
-
问题 1: 光线起点与自相交 (Self-Intersection)
- 当从缓存的 texel 发出光线进行光照计算时,光线起点可能恰好在表面上或非常接近表面,导致光线立即与自身所在的三角形相交。
- 解决方案: 需要根据表面法线 (Surface Normal) 和光线方向 (Ray Direction) 应用一个合适的偏移 (Bias),确保光线能成功“逃离”表面。
-
问题 2: 光照泄露 (Light Leaking)
- 由于缓存的 texel 物理上可能位于几何体内部,或是在边缘进行双线性插值 (Bilinear Filtering) 时,采样到了几何体另一侧的 texel,从而导致光线穿墙,造成光照泄露。
- 解决方案: 采用一种有效的剔除策略:丢弃那些击中了三角形背面 (Back Faces) 的光线。这样做可以确保几何体内部的 texels 变为黑色,从而在物理上阻止了光照的泄露。
性能优化:增量式更新与缓存策略 (Incremental Updates)
由于每帧重新计算所有可见区域的光照是不可行的,因此必须采用一种智能的缓存更新机制。
-
核心原则: 每帧只更新 Surface Cache 的一个子集。通过时间上的分摊 (Amortization) 来平衡性能开销与画面质量。
-
页面更新选择策略:
- 为了决定每帧应该更新哪些缓存页面 (Pages),系统会追踪两个核心属性:
- Last Used (最后使用时间): 记录该页面最后一次被光线击中的帧号。这是通过 GPU Feedback 机制实现的,每次光线命中时,在 GPU 端直接写入当前的帧编号。这个值反映了页面的重要性或可见性。
- Last Updated (最后更新时间): 记录该页面光照信息最后一次被更新时的帧号。这个值反映了页面数据的陈旧程度。
- 区分直接光与间接光:
- 直接光照和间接光照的更新频率是分开管理的。
- 通常,直接光照 (Direct Lighting) 计算成本更低,对场景变化的响应也需要更及时(如动态阴影),因此其更新频率远高于成本高昂的间接光照 (Indirect Lighting)。
- 为了决定每帧应该更新哪些缓存页面 (Pages),系统会追踪两个核心属性:
-
优先级选择算法:
- 为了在给定的预算内(例如每帧更新 N 个页面)选出最重要的页面进行更新,系统会使用一种基于直方图的策略。
- 构建直方图 (Histogram): 根据
Last Used和Last Updated等指标对所有页面进行评估,并放入不同的桶 (bucket) 中。 - 按需选择: 从最高优先级的桶开始,依次选择页面进行更新,直到耗尽当帧的计算预算。
-
动态管理:
- 该系统还需要处理缓存页面的新增 (Map a new page) 和尺寸调整 (Resize) 等动态管理任务。
- 为了在动态场景中(如虚拟纹理页面调整或新增时)维持高性能,系统会优先复用已有的光照计算结果,而不是从头开始计算。
- 关键术语:光照重采样 (Resampling Previous Lighting)
- 当一个虚拟纹理页面(Card)被重新缩放或一个新页面被映射时,系统不会丢弃之前昂贵的光照计算。
- 相反,它会尝试从旧的或邻近的页面中重采样光照数据,并应用到新的页面上,这是一种高效的资源复用策略。
直接光照与阴影处理流程
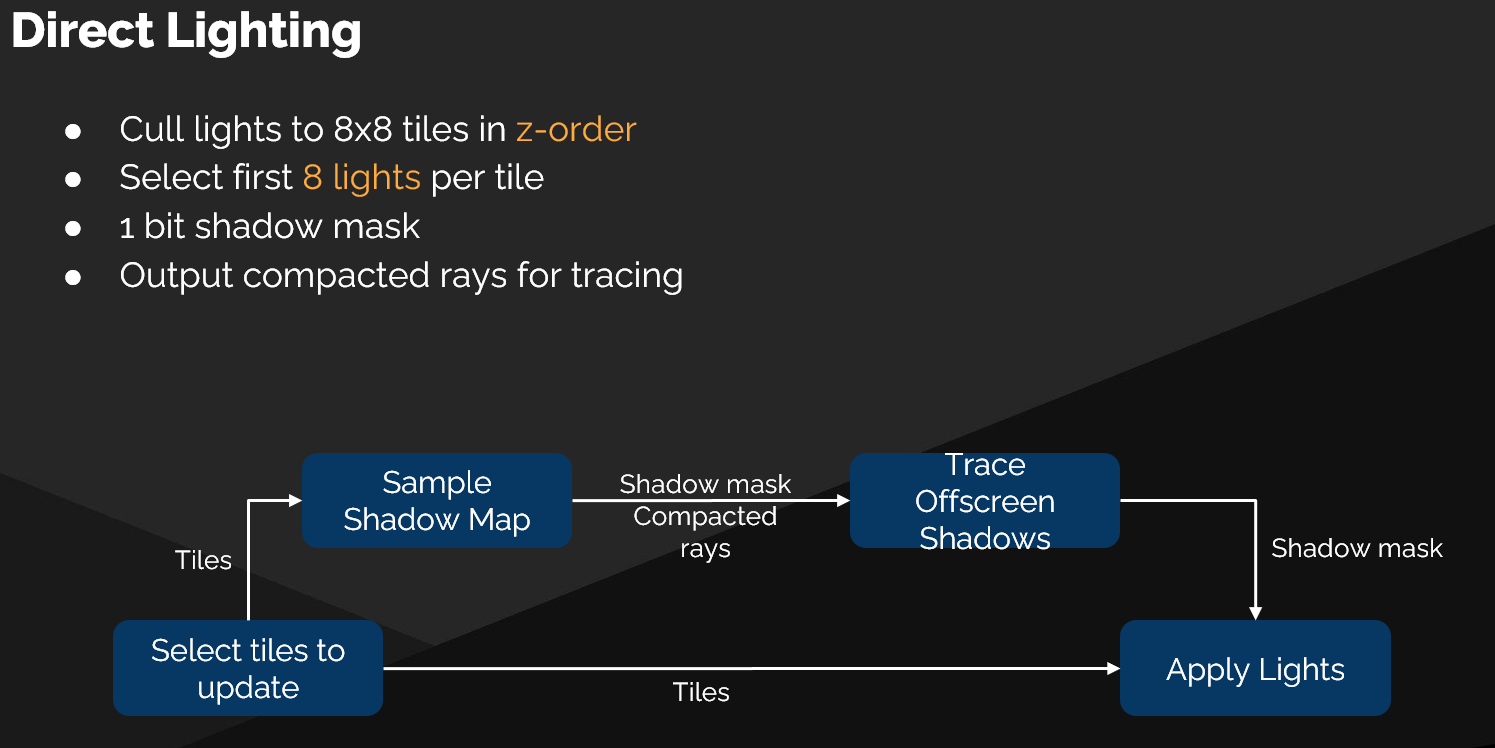
核心观点
直接光照的计算被分解为一系列高度优化的步骤,其核心是采用结合了传统阴影图和光线追踪的混合渲染方法,并通过一个紧凑的阴影遮罩(Shadow Mask) 来高效整合结果。
任务分解与调度 (Tiling & Scheduling)
- 分块处理:需要更新的页面(Pages)会被切分成更小的 8x8 像素的图块(Tiles)。
- Z阶排序 (Z-order):这些图块以 Z 阶曲线顺序进行处理,这种空间填充曲线可以最大化光线追踪的相干性 (Trace Coherency),提升缓存命中率和执行效率。
- 光源选择:
- 每个图块会选取最多 8 个光源进行计算。
- 当前实现采用了简单的策略(如选择最先出现的 8 个),但未来计划引入更智能的光源选择算法。
混合阴影生成 (Hybrid Shadowing)
该系统不依赖单一的阴影技术,而是通过一个多阶段流程来生成一个最终的阴影遮罩。
-
关键术语:阴影遮罩 (Shadow Mask)
- 这是一个8-bit 的位掩码,每一位对应一个被选中的光源。
1代表可见,0代表处于阴影中。这个遮罩最终用于光照计算阶段。
- 这是一个8-bit 的位掩码,每一位对应一个被选中的光源。
-
混合阴影生成步骤:
- 阶段一:利用阴影图 (Shadow Maps)
- 首先,系统会尝试使用已有的、渲染好的阴影图来填充阴影遮罩。这是快速、高效的第一道防线。
- 阶段二:生成光追任务
- 对于那些无法被阴影图覆盖或解析的纹素(Texel),例如位于摄像机背后的区域,系统会将其整理成一个紧凑的阴影光线列表 (Compacted list of shadow rays)。
- 阶段三:光线追踪补全
- 接着,系统会追踪(Trace) 这个列表中的阴影光线,以确定这些纹素对于各光源的可见性,并用结果完成阴影遮罩的剩余部分。
- 阶段四:最终光照计算
- 最后,运行光照着色器(Lighting Pass),利用这个完整的阴影遮罩来计算最终的直接光照效果。
- 阶段一:利用阴影图 (Shadow Maps)
间接光照处理流程
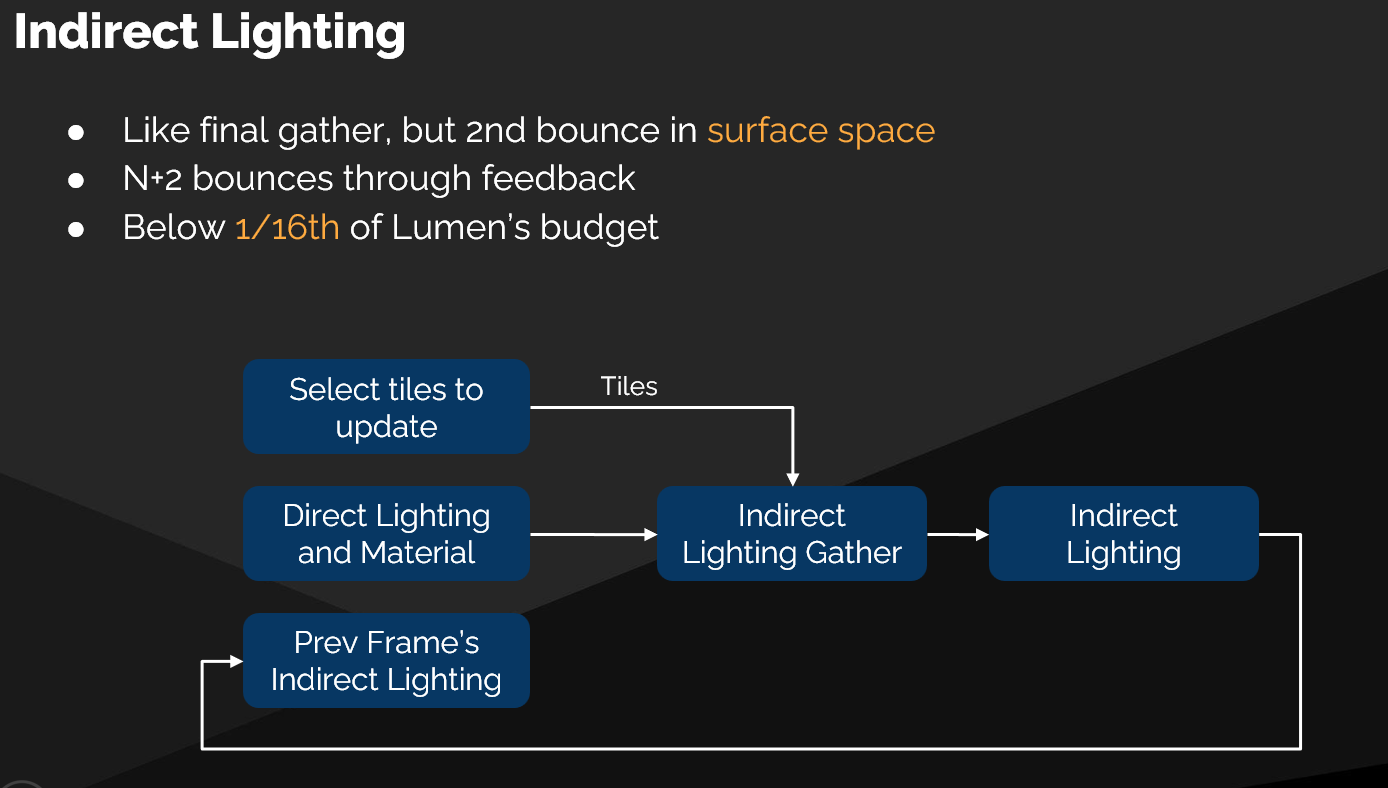
核心观点
间接光照的计算更具挑战性,系统采用了一种基于时间反馈 (Temporal Feedback) 的近似方法来模拟多级反弹,以在有限的性能预算内实现可信的效果。
- 关键术语:表面空间最终聚集 (Final Gather in Surface Space)
- 间接光照被视为在虚拟纹理的表面空间上进行的一次最终聚集计算,用于求解二次反弹 (Secondary Bounce) 的光照。
多级反弹的近似算法 (Multi-bounce Approximation)
为了支持多次反弹,系统在处理每一次间接光线命中时,会采样两种不同的光照信息:
- 采样当前帧的直接光照。
- 采样上一帧的间接光照结果。
这个机制形成了一个时间反馈循环:
- 每一帧:计算出新的直接光照和一次间接反弹。
- 后续反弹效果:通过不断累积和复用前一帧的结果来近似模拟。
性能与质量的权衡
整个间接光照系统都构建在极其有限的性能预算之上,这意味着必须在质量和性能之间做出取舍。
- 有限的页面更新:每帧只选择少量页面进行光照更新。
- 有限的光线预算 (Ray Budget):严格限制每帧可以追踪的间接光线的数量。
Secondary Bounce Calculation
这部分内容专注于如何在有限的性能预算内,为 Surface Cache 高效地计算间接光照(即二级光线反弹)。由于为缓存中的每个纹素(texel)追踪大量光线是不可行的,因此采用了一套基于探针(Probe)的降采样、插值和时域累积的优化方案。
一、 性能瓶颈与核心挑战
- 核心观点: 在理想情况下,为 Surface Cache 中的每个 texel 追踪足够多的光线(例如 64 条)来计算精确的间接光照,其计算成本是无法承受的。
- 关键术语:
- 光线预算 (Ray Budget): 指在单帧内可用于追踪光线的计算资源总量,这是一个非常有限的资源。
二、 降采样光线追踪策略
为了在严格的光线预算下工作,系统没有为每个 texel 进行追踪,而是采用了一种降采样策略。
- 核心观点: 通过在 texel 网格上稀疏地放置半球探针 (Hemispherical Probe),并仅从这些探针位置进行光线追踪,从而实现降采样追踪 (Downsample Tracing)。
- 实施细节:
- 探针布局: 在一个 4x4 的 texel tile 上放置一个半球探针。
- 追踪主体: 光线仅从这些探针化的 texel (probe texels) 位置发射,而不是从 tile 内的所有 16 个 texel 发射。
- 优势: 这种方法在大幅降低追踪成本的同时,依然能够利用该 tile 内 texel 的表面法线细节 (surface normal detail)。
- 噪声抑制: 为了缓解因采样率不足导致的噪声,探针的位置和光线追踪方向会根据存储在 Surface Cache Page 中的帧索引 (Frame Index) 每帧进行抖动或变化。
三、 探针插值与漏光抑制 (Probe Interpolation & Leakage Suppression)
追踪完成后,原始的探针结果非常噪,需要通过空间和时间上的复用(reuse)来清理。
- 核心观点: 通过插值最近的多个探针结果来重建每个 texel 的间接光照,并采用两种关键的启发式算法 (Heuristics) 来抑制光线泄漏 (Leaking)。
- 插值流程:
- 对于 Surface Cache 中的任意一个 texel,找到其最近的四个探针 (four closest probes)。
- 对这四个探针的计算结果进行插值,得到该 texel 的间接光照。
- 漏光抑制 (Leakage Suppression) 算法:
- 启发式算法 1 (基于平面): 每个半球探针都关联一个平面 (plane)。在插值时,根据 texel 相对于该平面的位置对探针进行加权。如果 texel 位于平面的后方(意味着可能被墙等物体阻挡),则该探针的贡献会被大幅降低甚至忽略,有效防止光线穿墙。
- 启发式算法 2 (基于深度): 利用探针自身存储的深度图 (depth map) 来检查探针与当前被着色的 texel 之间的可见性 (visibility)。如果两者之间有遮挡,则该探针不参与贡献。
四、 结果存储与时域累积 (Result Storage & Temporal Accumulation)
经过插值和漏光矫正后的结果需要被稳定地存储下来。
- 核心观点: 将计算出的间接光照结果通过时域混合 (Temporal Blending) 的方式,逐步累积到最终的间接光照图集 (Indirect Lighting Atlas) 中,以平滑噪声,但必须限制累积帧数以避免鬼影。
- 实施细节:
- 系统维护一个间接光照图集 (Indirect Lighting Atlas) 用于存储最终结果。
- 同时,系统会追踪图集中每个 texel 已累积的帧数 (number of accumulated frames)。
- 由于 Surface Cache 的更新频率本身较低,为了最大程度地避免鬼影 (Ghosting),总累积帧数被严格限制在 4 帧以内。
五、 质量评估与应用场景
- 核心观点: 这种为 Surface Cache 计算的二级反弹光照,在质量上虽然低于逐像素执行的 Final Gather,但作为一种高效的性能近似方案,其结果在绝大多数场景下是完全可以接受的。
- 质量对比: 其效果能够大致匹配 (roughly matches) 逐像素收集的结果。
- 适用范围:
- 对于漫反射多次反弹 (diffuse multibounce) 和粗糙表面反射 (rough reflections),其质量水平完全足够。
- 在大多数情况下,对于镜面反射 (mirror reflections) 的效果也表现良好。
全局光照缓存的采样与更新策略
本节深入探讨了如何解决从全局距离场(GDF)追踪到获取具体表面光照信息的难题,并详细介绍了一套高效的、基于缓存的更新与着色管线。
核心问题:从全局追踪到局部表面数据
-
核心观点: 全局距离场(Global Distance Field, GDF) 的光线追踪提供的是场景的合并几何信息,当光线命中时,我们无法直接得知具体命中了哪个网格实例(Mesh Instance)。这就导致我们无法直接从 GDF 的追踪结果中采样 表面缓存(Surface Cache) 中的详细光照与材质信息。
-
解决方案:全局裁剪贴图(Global Clip Maps)
- 数据结构:将所有独立的表面缓存“卡片(Cards)”合并到一个以摄像机为中心的 全局裁剪贴图 集合中。这是一种分层级的、基于体素(Voxel)的结构。
- 数据内容:每个 体素(Voxel) 存储沿多个轴对齐方向的辐射度(Radiance)信息。
- 采样方式:进行采样时,会在不同的方向和相邻的体素之间进行插值,以获得平滑的查询结果。
-
关键技术:投影权重(Projection Weight)
- 核心观点:在体素的 Alpha 通道中存储一个权重值,用于量化当前体素中存储的光照数据的“可信度”或“有效性”。
- 主要作用:
- 弥补数据缺失:解决因某些表面缓存卡片未能成功生成或合并而导致的数据空洞问题。
- 修正重投影误差:补偿将表面缓存数据重投影到固定的世界空间体素网格时产生的精度损失。
性能优化:增量式缓存更新
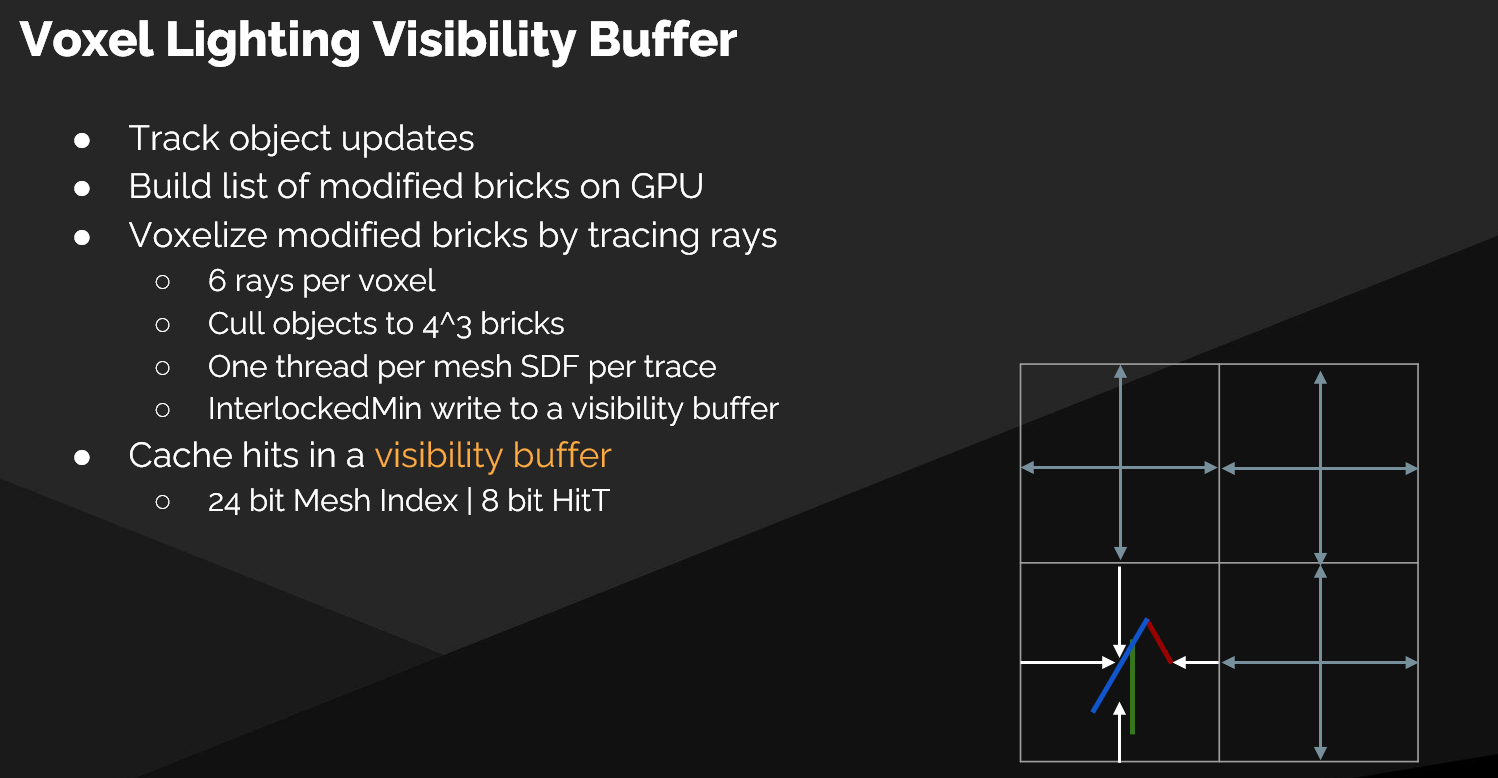
-
核心观点:每帧更新整个全局光照体积的开销巨大,必须采用缓存策略,只更新发生变化的部分。
-
更新流程:
- 变更追踪:与 GDF 的更新机制类似,系统会追踪场景中的几何体修改(如物体移动),并将受影响的体素块(Bricks)标记为“脏”(Dirty)。
- 对象列表构建:对每一个“脏”的体素块,构建一个包含其内部所有对象的列表。
- 可见性追踪:启动一个光线追踪 Pass,每个线程追踪一条光线,用于确定体素块内的可见性信息。
- 写入可见性缓冲:追踪结果使用 原子最小值操作(Atomic Min) 写入一个 可见性缓冲(Visibility Buffer)。这确保了在并行环境下,只有最近的命中点能被正确写入,避免了竞态条件。
核心设计决策:缓存几何信息而非光照
- 核心观点:该系统选择缓存 几何可见性信息(即从某点能看到哪个物体),而不是最终的光照结果。
- 原因分析:
- 几何相对静态:场景中的几何体位置变化频率通常远低于光照变化。
- 光照高度动态:光源移动、强度变化等可能每帧都在发生,追踪光照变化的成本远高于追踪几何变化。
- 解耦优势:将几何与光照解耦,使得我们可以在几何信息保持缓存的情况下,每帧根据最新的光照信息快速重新计算着色,兼顾了性能与动态性。
着色管线:从可见性到着色结果
-
核心观点:可见性信息被缓存后,每帧都会执行一个高效的着色流程来计算最终的光照。
-
着色流程步骤:
- 缓冲紧凑化(Compaction):可见性缓冲通常是 稀疏的(Sparse),即大部分空间是无效的未命中数据。为了提高后续处理效率,首先需要将其中的有效条目压缩到一个密集的列表中。
- 采样与着色:遍历紧凑化后的可见性缓冲。对于每一个有效的命中条目,从 Surface Cache 中采样对应的表面属性(材质、光照等),计算出最终的光照值。
- 权重计算与存储:在着色过程中,同时计算出之前提到的 投影权重。
- 写入全局体积:将计算出的最终光照(RGB)和投影权重(Alpha)一起写入到全局的体素化光照体积(即全局裁剪贴图)中,供后续渲染步骤使用。
Surface Cache 的收尾、局限与优势
这部分内容首先补充了 Surface Cache 的一个实现细节,然后系统地总结了其作为一种光线追踪加速结构的优缺点,并为接下来引入硬件光线追踪做了铺垫。
Voxel Lighting Volume 集成
- 核心观点: Surface Cache 的计算结果最终会服务于场景的体素化光照。
- 关键术语:
- Projection Weights (投影权重): 这些权重被计算出来,用于将 Surface Cache 上的光照信息投影或贡献到最终的体素光照体积中。
- Voxel Lighting Volume (体素光照体积): 这是场景中存储间接光照信息的 3D 数据结构。其 Alpha 通道被用来存储上述的投影权重。
Surface Cache 的局限性 (Limitations)
-
体素光照质量受限 (Limited Voxel Lighting Quality): 由于 Surface Cache 的体素化表示非常粗糙(仅用了两个 "Card"),其提供的光照信息质量存在上限。这是未来需要改进的主要方向。
-
静态布局,不支持动画 (Static Layout, No Animation Support):
- Card 的放置是在网格导入时预处理完成的,这意味着它无法响应运行时的网格动画(例如角色的骨骼动画)。
- 有一个变通方案 (Workaround):通过在植被(Foliage)上增加 Depth Weight Bias (深度权重偏移),可以容忍一些微小的形变(如风吹动的树叶),但这对角色等大幅度形变的物体完全无效。
-
复杂网格展开困难 (Difficulty with Complex Meshes):
- 对于具有大量几何层级的复杂网格(如茂密的树),很难用合理数量的 Card 将其有效“展开”和参数化。
- 造成的影响: 这会导致能量丢失,在反射 (Reflections) 中可能比较明显,但对于漫反射光线 (Diffuse Rays) 来说影响较小,只会造成轻微的能量缺失。
Surface Cache 的优势 (Advantages)
尽管存在局限性,Surface Cache 仍然是一个非常有价值的系统。
-
启用距离场追踪 (Enables Distance Field Tracing): 它是 Lumen 软件光线追踪(基于距离场)的基础。
-
缓存昂贵计算的通用工具 (A Great Utility for Caching):
- 它的核心价值在于可以缓存各种昂贵的计算结果,尤其是材质和光照的求值。
- 这不仅对距离场追踪有用,对于硬件光线追踪 (Hardware Ray Tracing) 同样有益。当硬件光追命中物体时,可以直接从 Surface Cache 中读取预计算好的着色信息,从而跳过昂贵的材质和光照求值步骤。
-
实现高质量多次反弹 (Enables High-quality Multiple Bounces): 通过缓存光照信息,它使得计算高质量的多次反弹 GI 和反射成为可能,这对于实现可信的全局光照效果至关重要。
Part 3: Hardware Ray Tracing in Lumen
引入硬件光追的初始动机 (Initial Motivations)
-
精确的求交 (Precise Intersection):
- 硬件光追可以直接与原始的三角形数据 (Raw Triangle Data) 进行求交计算。
- 这与依赖于近似表示(如距离场)的软件光追相比,能够获得几何上完全精确的相交结果。
-
动态着色与清晰反射 (Dynamic Shading & Sharp Reflections):
- 硬件光追可以在光线命中点实时进行动态的材质和光照求值 (Dynamic Material and Lighting Evaluation)。
- 这一能力是实现锐利的屏幕外反射 (Sharp Offscreen Reflections) 的关键。这是许多基于屏幕空间或缓存技术的方案难以解决的痛点,而硬件光追则可以完美处理。
Lumen 中的硬件光线追踪:从实验到实践
本节内容概述了 Lumen 在集成硬件光线追踪(Hardware Ray Tracing)时所做的初步尝试、遇到的核心问题,并为后续将要展开的技术细节铺设了路线图。
硬件光线追踪的核心优势与背景
- 核心观点: 在 Lumen 中引入硬件光线追踪,主要为了解决软件光追难以处理的特定场景,尤其是高质量的反射效果。
- 关键优势:
- 动态评估能力: 硬件光追能够对动态的材质和光照进行实时评估,这是实现清晰的离屏反射 (sharp offscreen reflections) 的关键。
- 硬件普及: 现代游戏主机已原生支持硬件光线追踪,使得这项技术不再是高端 PC 的专属,具备了大规模应用的潜力。
技术探索路线图 (Talk Roadmap)
讲座将围绕以下几个方面,循序渐进地介绍 Lumen 的硬件光追管线:
- 初始实验: 从集成 UE4 的光追模型开始,并分析其缺陷。
- 替代方案: 提出一种基于 Surface Cache 的新模型,以最小化运行时开销。
- 混合方案: 探讨如何混合两种模型以获得质量上的优势,并最终形成 Lumen 支持的两种评估模式。
- 实践挑战:
- 透明度 (Opacity) 的表示与处理。
- 在 GPU 驱动的管线下如何调用硬件光追。
- 处理 Nanite 回退网格 (fallback meshes) 和远场追踪 (far field tracing) 等复杂遍历问题。
- 最终成果: 展示 UE5 中发布的完整硬件光追管线。
初步尝试:集成 UE4 光追反射模型
-
核心观点: Lumen 的硬件光追实践始于反射 (Reflections) 的实现。团队没有从零开始,而是选择集成了 UE4 中已有的光追反射模型作为起点。
-
初步成果:
- 这种集成方式提供了一个快速的解决方案,成功实现了对动态材质和光照的评估。
-
遇到的核心问题:缺乏正确的高光遮蔽
- 关键术语: 高光遮蔽 (Specular Occlusion)
- 问题描述: 在集成了 UE4 的反射模型后,团队遇到的最显著问题是缺乏正确的高光遮蔽。这意味着反射可能会出现在本应被遮挡的区域,导致视觉上不真实的效果(例如,墙角或物体缝隙中出现错误的反射漏光),这是该模型必须被改进或替换的核心原因。
Lumen光线追踪的优化:表面缓存管线 (Surface Cache Pipeline)
待解决的问题:不正确的镜面反射遮蔽 (Specular Occlusion)
在部署UE4的反射模型时,一个显著的视觉问题是缺乏正确的镜面反射遮蔽(Specular Occlusion)。
- 具体表现: 在Lumen的Lyra示例中,一个完全处于室内的镜面球,其反射中会错误地包含来自天空光(Skylight)的贡献,导致反射表面呈现出不自然的蓝色调。
- 根本原因: 这是因为光线追踪在计算镜面反射时,没有充分考虑遮挡物,导致被遮挡的光源(如天空光)错误地影响了最终的反射颜色。
解决方案:完全依赖表面缓存的“快速路径”
为了解决上述问题并探索性能优化的可能性,团队设计了一条新的渲染管线,其核心思想是完全放弃在光追过程中进行动态的材质和光照评估,转而完全依赖于表面缓存(Surface Cache)。
这条新管线被设计为Lumen硬件光线追踪的快速路径(fast path),为此引入了以下关键设计和限制:
-
核心架构: 表面缓存管线 (Surface Cache Pipeline)。
-
强制不透明与简化着色器:
- 移除 Any-Hit Shader: 为了极致简化,该管线移除了 Any-Hit Shader,并强制场景BVH中的所有对象都为不透明(Opaque)。这避免了处理半透明材质的复杂性。
- 单一的 Closest-Hit Shader: 替代了原先大量依赖于不同材质的
Closest-Hit Shader(CHS),新管线使用一个单一、通用的CHS。
-
职责划分的转变:
- CHS 的新职责: 这个简化的CHS职责非常单一,仅负责提取几何信息,包括几何法线(geometric normal) 和用于查询表面缓存的参数化坐标(surface cache parameterization)。它本身不执行任何光照计算。
- Ray-Gen Shader 的职责: 真正的光照应用被移回到了光线生成着色器(Ray Generation Shader, RGS) 中。RGS接收到CHS返回的命中信息后,执行一次法线加权的表面缓存查询(normal weighted surface cache evaluation),直接从缓存中获取预计算好的光照结果。
优势与进一步优化
-
效果优势:
- 修正视觉问题: 该管线通过查询包含了正确遮蔽信息的表面缓存,完美解决了之前提到的镜面反射遮蔽和天光泄漏问题。
- 效率极高: 仅通过一次表面缓存的查询(single evaluation),就能同时获得直接光和间接光(Direct and Indirect Lighting),大幅提升了效率。
-
带宽优化:Payload结构:
- 为了进一步压榨性能,团队针对这条管线设计了全新的Payload结构以最小化带宽压力(minimize bandwidth pressure)。
- 对比:
- UE4高质量模型 (旧): 其Payload结构类似于G-Buffer,需要 64字节 来存储Base Color, Normal, Roughness, Specular等完整的材质参数,用于动态光照计算。
- 表面缓存管线 (新): 由于光照已预计算在Surface Cache中,Payload不再需要携带完整的材质信息,只需传递少量用于查询缓存的指针或坐标即可,极大地减小了数据传输量。
Surface Cache Payload 与混合渲染策略
Surface Cache Payload:一种轻量级的数据结构
与传统的 G-Buffer 需要存储大量材质参数(如 Base Color, Normal, Roughness, Opacity, Specular 等)不同,Surface Cache 采用了一种高度优化的数据结构。
- 核心观点: Surface Cache Payload 是一种紧凑的数据结构,旨在存储光照查找所需的最少信息,从而显著降低内存占用。
- 关键数据:
- 传统 G-Buffer:需要为每个像素存储完整的材质属性。
- Surface Cache Payload:仅需 20 字节 即可存储一次光照查找所需的全部参数。
- 补充说明: Payload 中包含一些为材质保留的比特位,其用途将在后续内容中解释,但它们对于 Surface Cache 的光照管线本身不是必需的。

对 Shader Binding Table (SBT) 的构建优化
采用 Surface Cache 的新模型,极大地简化了光线追踪中着色器绑定表(SBT)的构建过程,带来了显著的 CPU 性能提升。
- 核心观点: 通过减少对材质依赖资源的查找和绑定,新的数据模型显著降低了构建 SBT 的 CPU 开销。
- 传统模型的瓶颈:
- 在构建 SBT 时,需要一个 绑定循环 (binding loop)。
- 这个循环需要为大量实例(instances)获取各自依赖的材质资源(纹理、常量等),这是一个非常耗时的 CPU 操作。
- 新模型的优势:
- 由于光照所需信息已烘焙在 Surface Cache 中,SBT 的构建不再需要复杂的材质资源绑定。
- 结果是显著的 CPU 时间节省。
- 无法完全消除的绑定:
- 尽管大大简化,绑定循环无法被完全消除。
- 因为在 DXR (DirectX Raytracing) 中,仍然需要绑定顶点和索引缓冲区 (vertex and index buffers) 来重建表面法线。
- 该讲座指出,UE5 当时未使用 bindless resources,如果使用了该技术,则可以进一步简化甚至消除这个绑定步骤。
混合策略:结合动态求值与静态缓存
为了在性能和质量之间提供灵活的控制,开发团队探索了一种将 Surface Cache 与传统动态求值相结合的混合渲染策略。
- 核心观点: 通过有条件地选择使用缓存数据(如 Albedo, Direct/Indirect Lighting)还是进行实时动态计算,可以实现一种自然的 性能与质量的权衡控制 (performance vs. quality trade-off)。
- 实现机制:
- 系统可以根据所需的动态效果级别,有条件地分离 (conditionally separating) Surface Cache 中的各个分量。
- 例如,可以选择使用缓存的 GI,但实时动态计算直接光照和材质。
- 解决特定问题:
- 这种混合方法提供了一个有效的机制,将 Surface Cache 的间接光照与 UE4 模型的动态求值结合起来。
- 这从根本上解决了传统方法中 无阴影天光 (unshadowed skylight) 的一个老大难问题。
实践中的发现与最终方案
尽管混合策略在理论上提供了细粒度的控制,但在实践中发现,其性能表现并不如预期。
- 核心发现: 团队经过测试发现,部分动态求值 (partial dynamic evaluation) 的开销几乎与完全动态求值 (full dynamic evaluation) 一样昂贵。
- 最终决策:
- 基于这一发现,为艺术家提供过于复杂的、多维度的控制选项并无实际性能优势。
- 因此,最终只向艺术家暴露了两种光照配置选项,简化了工作流程,避免了无效的性能优化选项。
混合渲染管线:Surface Cache 与 Hit Lighting 模式
本节重点介绍了一种混合渲染策略,它为美术师提供了两种渲染模式:一种是基于表面缓存(Surface Cache) 的快速路径,另一种是更为精确但开销更高的命中光照(Hit Lighting) 路径。这两种模式共享部分管线,实现了性能与质量的灵活平衡,并有效解决了动态对象(如骨骼动画网格体)在光线追踪中的渲染难题。
面向美术师的两种渲染模式
为了在性能和质量之间取得平衡,系统向美术师暴露了两种核心的光照配置模式。
-
1. 表面缓存模式 (Surface Cache Mode)
- 核心观点: 这是主要的、高性能的渲染路径,直接利用之前章节描述的预计算表面缓存数据来获取间接光照。
- 关键特性: 速度极快,但为了性能做了一些妥协,例如它将场景中的所有几何体都显式地视为完全不透明(fully opaque),以避免昂贵的 any-hit-shading 调用。
-
2. 命中光照模式 (Hit Lighting Mode)
- 核心观点: 这是对UE4原有模型的改进版,是一种更精确的动态光线追踪渲染路径,目前主要用于反射(Reflections) 效果。
- 关键特性:
- 它能够计算出精确的直接光照和阴影。
- 它依然会从表面缓存中获取间接光照,实现了两种技术的结合。
- 它能够处理表面缓存无法覆盖的特殊情况。
Hit Lighting 模式的技术实现与管线
Hit Lighting 模式并非一个全新的系统,而是巧妙地构建在现有技术之上。
-
技术基础:排序延迟追踪 (Sorted Deferred Tracing)
- 核心观点: Hit Lighting 模式是先前已发表的排序延迟追踪管线的一个修改版。
- 管线流程:
- 初始追踪: 首先执行与 Surface Cache 模式相同的初始追踪过程。
- 排序 (Sorting): 根据材质ID等信息对光线命中结果进行排序,以优化着色效率。
- 重追踪/着色 (Retracing/Shading): 对排序后的命中点进行必要的动态着色计算。
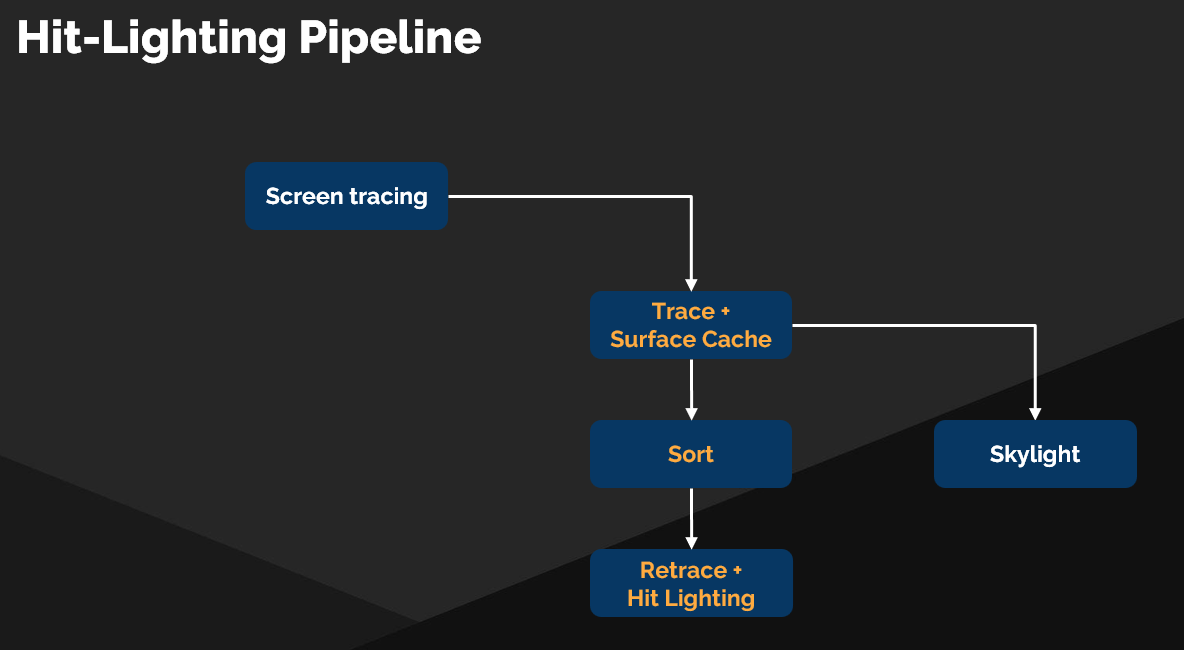
-
数据协同:表面缓存载荷 (Surface Cache Payload)
- 核心观点: 表面缓存的数据载荷中之所以包含材质ID (Material ID),其关键目的就是为了支持 Hit Lighting 模式中的排序延迟追踪优化。
- 这体现了系统设计的精妙之处:一个数据字段服务于两种不同的渲染管线。
两种模式的协同与灵活性
该系统最大的优势在于将两种模式无缝整合,形成一个灵活高效的混合管线。
-
统一的追踪前端
- 核心观点: Hit Lighting 管线复用了 Surface Cache 的追踪阶段作为其先决条件。这意味着系统无需维护两套独立的BVH追踪逻辑,大大提升了效率和代码复用率。
-
按需动态评估 (Per-Ray Dynamic Evaluation)
- 核心观点: 系统拥有极高的灵活性,可以基于单条光线(per-ray basis) 来决定是采用廉价的表面缓存查询,还是调用开销更高的 Hit Lighting 动态评估。
-
解决特定渲染难题:以骨骼网格体为例
- 问题: 像骨骼网格体(Skeletal Meshes) 这类动态变形的对象,无法生成静态的表面缓存参数化(Surface Cache Parameterization)。
- 解决方案: 在渲染这类对象的反射时,系统可以自动切换到 Hit Lighting 模式。
- 效果: 镜面球体中反射出的骨骼网格体能够正确接收到直接光照,这个效果只有通过 Hit Lighting 才能实现。
挑战与局限:半透明几何体
尽管该混合系统非常强大,但在处理半透明物体时,Surface Cache 模式存在明确的局限性。
- 核心问题: Surface Cache 模型将所有几何体视为完全不透明。
- 原因: 这是为了性能做出的权衡。处理半透明需要调用Any-Hit Shading,这会带来显著的运行时性能开销,设计者希望在主路径中避免这种情况。这暗示着处理半透明物体可能需要依赖 Hit Lighting 路径或其他特殊处理。
光线追踪性能优化与调度机制
这部分内容深入探讨了 Lumen 在处理半透明和 Alpha Masked 材质时的光线追踪性能优化策略,以及其独特的 GPU 驱动调度机制,特别是对 DXR 1.1 新特性的运用。
Traversal Optimization for Transparent & Masked Materials
为了实现高性能的光线追踪,Lumen 极力避免在光线遍历(Traversal)阶段产生高昂的性能开销,特别是针对非不透明物体。
-
核心痛点: 在光线追踪管线中,调用 AnyHit Shader (任意命中着色器) 会带来显著的运行时性能损失。对于需要处理透明、半透明效果的场景,频繁触发 AnyHit Shader 是不可接受的。
-
核心策略:跳过 AnyHit Shader,在 Ray Generation Shader 中手动迭代 Lumen 的解决方案是完全不使用 AnyHit Shader。作为替代,它在光线生成着色器 (Ray Generation Shader) 中实现了一个手动的迭代循环,当光线遇到“可能”透明的表面时,继续向前追踪,直到找到不透明表面或达到迭代上限。
-
针对不同材质的优化方案:
-
半透明材质 (Translucent Materials):
- 策略: 完全跳过。在加速结构(BVH)遍历过程中,直接忽略与半透明材质网格的相交。
- 效果: 这是最激进但最高效的方式,直接避免了与这类材质的任何交互开销。
-
Alpha Masked 材质 (Alpha Test Materials):
- 策略: 基于 Surface Cache 的不透明度进行判断。
- 在遍历过程中,当光线命中一个 Alpha Masked 表面时,系统会查询预先计算好的 Surface Cache 来获取该命中点的不透明度。
- 如果该区域的不透明度低于 50% 的阈值,则认为该次命中无效,光线继续向前传播。
- 本质: 这相当于在遍历阶段,利用缓存数据动态地重建了物体的 Alpha Mask,从而决定是否“穿透”该表面。
-
-
关键参数:
max translucent skip count: 这是一个在 Shader 中设定的参数,用于控制手动迭代遍历的最大次数。它防止了光线在多个半透明物体之间无限穿透,保证了算法的收敛和性能。
GPU-Driven Dispatch and DXR 1.1 Utilization
Lumen 的管线是高度 GPU 驱动的,其工作单元并非传统的屏幕像素,而是更加抽象的实体,如探针(Probes)、表面缓存纹素(Surface Cache Texels)和屏幕图块(Screen Tiles)。这种架构对任务调度提出了新的要求。
-
核心需求: 需要一个比传统
Dispatch(width, height, 1)更灵活的调度机制,因为工作负载是动态且不规则的。此外,硬件光线追踪在 Lumen 中常作为备用或辅助技术 (Fallback Technique),需要与计算着色器(Compute Shader)等更紧密地结合。 -
解决方案:间接调度 (Indirect Dispatch)
- Lumen 优先采用间接调度。这种方式允许 GPU 根据自身计算的结果(例如,需要更新的 Probe 数量)来决定启动多少个线程组,而无需 CPU 的介入。这完美契合了 Lumen 动态、数据驱动的工作模式。
-
对 DXR 1.1 的偏好与运用:
-
为了更好地支持其复杂的调度和集成需求,Lumen 在 PC 平台上优先选择 DXR 1.1。其核心在于利用了 Inline Ray Tracing (内联光线追踪),也称为 RayQuery。
-
RayQuery 带来的核心优势:
-
简化管线与开发:
- 它避免了传统 DXR 1.0 中复杂的 Shader Binding Table (SBT) 的设置。开发者无需再管理和绑定 RayGen, Miss, Hit, AnyHit 等一系列独立的 Shader。
-
无缝集成与高度灵活性:
- RayQuery 允许在标准的 Compute Shader 或 Pixel Shader 中直接发起硬件加速的光线遍历请求。这意味着可以将光线追踪像一次纹理采样一样,无缝地嵌入到现有的复杂计算逻辑中,极大地增强了算法设计的灵活性。
-
巨大的编译器优化潜力:
- 将光线追踪逻辑“内联”到调用方 Shader 中,为着色器编译器提供了非常广阔的优化空间。编译器可以更好地理解数据流和上下文,从而生成更高效的机器码,提升最终性能。
-
-
Inline Ray Tracing
这部分内容重点探讨了两种光线追踪实现方式的性能差异,特别是在PC和主机平台上的不同表现,并以《黑客帝国觉醒》Demo为例,阐述了在主机上进行大规模光线追踪所面临的挑战与解决思路。
优势
与传统的光线生成着色器(Ray Generation Shader)和TraceRay调用相比,内联光线追踪 (Inline Ray Tracing),也称为光线查询 (Ray Queries),为编译器提供了更大的优化空间,能显著提升性能。
- 编译器优化:内联方式允许编译器在更广阔的上下文(整个着色器代码)中进行优化。它可以自动最小化跨越光线追踪调用的“活跃状态”(Live State),即需要保存和恢复的寄存器与变量。
- 对开发者的要求:
- 在使用传统的
TraceRay调用时,开发者需要手动优化,尽量减少调用前后需要保持活跃的变量,以降低性能开销。 - 使用内联光线追踪,这个优化过程很大程度上可以由编译器自动完成,减轻了开发者的负担。
- 在使用传统的
平台差异:PC vs. 主机
在特定应用场景(如Surface Cache)中,主机平台的底层API特性使其能更好地利用内联光线追踪,而PC则面临限制。
-
PC 平台的限制:
- 为了在命中组着色器(Hit Group Shader)中获取插值后的顶点属性(如法线、UV),通常需要手动提供顶点和索引缓冲区。
- 这种对辅助缓冲区的依赖使得在PC上为 Surface Cache 这类管线实现高效的内联光线追踪变得复杂。
-
主机平台的优势 (Xbox Series X/S, PS5):
- 主机平台的光线追踪硬件原生指令(Intrinsics) 更为强大和灵活。
- 它们可以在光线追踪的命中结构体(Hit Structure)中直接返回几何法线(Geometric Normal) 等关键信息。
- 由于无需手动访问和解析顶点/索引缓冲区来获取基础几何信息,主机平台可以无缝地利用内联光线追踪,并因此在特定平台上获得显著的性能提升。
《黑客帝国觉醒》Demo 的光追挑战
《黑客帝国觉醒》Demo对光线追踪技术提出了极限要求,尤其是在主机这样一个计算资源相对受限的平台上。这迫使团队必须充分利用主机API的灵活性来应对挑战。
-
面临的主要技术挑战:
- 海量实例 (High Instance Count):开放世界场景包含大量物体实例,对顶层加速结构(TLAS)的重建造成巨大压力,容易成为性能瓶颈。
- 大量动态物体 (Dynamic Objects):世界中存在大量的动态汽车和行人,需要频繁地对底层加速结构(BLAS)进行动态重建或更新(Refit)。
- 高质量反射 (High-Quality Reflections):为了真实地渲染车漆和玻璃等材质,必须实现高质量的镜面反射,这对光线追踪的性能和效果都提出了高要求。
-
主机平台的机遇与限制:
- 性能限制:目标平台(Xbox Series X/S, PS5)虽然拥有原生光追硬件,但其整体计算能力和光线遍历速度仍低于高端PC。
- API 灵活性:主机平台的图形API在光线追踪管线上提供了更大的灵活性。开发团队可以利用这一点来设计更具针对性的优化方案,绕过硬件的性能限制,从而在主机上实现要求极高的渲染效果。
光追管线的实践挑战:复杂材质与 Nanite
光线追踪管线的灵活性与优化
现代图形API为光线追踪管线提供了更高的灵活性,允许开发者进行更深度的优化,例如将静态物体的加速结构构建过程预处理并流式加载,从而显著降低运行时的帧耗时。
- 关键优化: 针对静态网格体,其加速结构 (Acceleration Structures),特别是底层加速结构 (BLAS),可以被预构建 (pre-built) 并通过流式加载 (streamed) 的方式送入显存。
- 优势: 这种方法避免了在每一帧或每次场景加载时都重新构建或拟合(refitting)这部分数据,极大地减少了用于构建 BVH 的时间开销,将更多性能预算留给动态物体和光线追踪本身。
- 主机平台特定优化: 讲座提及,关于主机平台(如 PS5)的更详细优化,可以参考 Alexander 和 Thiago 的演讲。
Hit Lighting 模型的性能困境
尽管 Hit Lighting(在光线命中点动态执行完整材质和光照计算)在理论上能提供更精确的结果,但在《黑客帝国:觉醒》这样的复杂场景中,由于材质本身的高度复杂性,导致其性能开销过高,最终被放弃。
-
性能瓶瓶颈:
- 高指令数: 项目中使用的“主材质”(Master Materials)包含极其复杂的着色器逻辑。
- 大量的虚拟纹理获取: 单次材质评估就需要调用数十次虚拟纹理获取 (Virtual Texture Fetches)。
- 结论: 在光线命中后动态评估如此复杂的材质和光照,性能完全无法接受。即使最初希望对动态物体启用该模型,也因性能预算耗尽而作罢。
-
PS5 性能报告:
- 计时报告显示,在 PS5 上使用复杂材质调用 Hit Lighting 的评估成本是“惊人的 (staggering)”。
-
视觉质量收益甚微:
- 一个出乎意料的发现是,即便不考虑性能问题,Hit Lighting 在该 Demo 中也未能带来显著的视觉质量提升。
- 根本原因: 场景的视觉表现严重依赖于天光 (Skylight)。而在最终的管线中,无论是标准路径还是 Hit Lighting 路径,天光项的贡献都已经通过从 表面缓存 (Surface Cache) 中采样来高效获取。因此,两个路径在最关键的光照部分表现趋同,使得 Hit Lighting 带来的额外计算价值不大。
Nanite 与硬件光线追踪的集成挑战
在广泛使用 Nanite 的场景中,硬件光线追踪面临一个根本性难题:当前的加速结构无法直接支持 Nanite 原生的微多边形几何精度。因此,必须采用近似的几何表示作为折衷方案。
-
背景: 《黑客帝国:觉醒》中绝大多数资产都由 Nanite 渲染。
-
核心矛盾:
- 硬件光追依赖于明确的、离散的三角形列表来构建加速结构 (Acceleration Structures, 如 BVH)。
- Nanite 的几何体是虚拟化的、按需流式传输的微多边形集群,其全部细节无法也无需在内存中实例化为传统网格。
-
技术挑战:
- 让硬件光追原生支持 Nanite 级别的几何分辨率,在技术上极其复杂,目前仍是一个活跃的研究领域 (active area of research)。
- 直接用 Nanite 的全部细节构建 BVH 会导致内存爆炸和构建时间的失控。
-
当前解决方案:
- 做出妥协 (make some concessions),不使用 Nanite 的完整几何细节进行光线追踪。
- 采用一种近似的几何表示 (approximate geometric representations) 来构建光线追踪所需的加速结构。这意味着用于光线追踪的几何体是 Nanite 模型的简化代理。
在追求高性能的全局光照时,Lumen无法直接对 Nanite 产生的高精度几何体进行光线追踪。本节内容深入探讨了因使用简化几何模型而引发的自相交(Self-Intersection) 问题,并提出了一种实用且高效的解决方案。
问题的根源:高低精度几何体之间的不匹配
为了在可接受的性能预算内实现光线追踪,Lumen 采用了一套独立的、简化的场景表示。
-
核心观点: Lumen 的光线追踪场景并非使用原始的高精度 Nanite 网格,而是采用了Nanite 后备网格(Nanite Fallback Meshes) 作为其几何体的近似表示,并将其存储在底层的加速结构(BLAS)中。
-
引发的挑战:
- 几何失配 (Geometric Mismatch): 从 G-Buffer(由高精度光栅化几何生成)发出的光线,其起始点与光线追踪场景中的低精度 Fallback Mesh 表面并不完全吻合。
- 自相交瑕疵 (Self-Intersection Artifacts): 由于这种不匹配,光线起点可能位于近似几何体的“内部”或与其非常接近,导致光线一出发就击中了它本应离开的那个三角形的背面。
- 传统方法失效: 常规的光线偏移(Ray Bias) 技术不足以解决这种由宏观几何差异引起的严重自相交问题。
解决方案:两步式光线投射算法
面对这个问题,团队并未采用2004年学术论文中提出的那种计算成本高昂的精确解法,而是设计了一种巧妙且性能开销更低的修改版遍历算法。
-
核心观点: 该算法通过一个 “先推后追” 的两步过程,强制将光线“推离”起始的近似表面,从而有效避免自相交。
-
算法步骤:
-
第一步:短距离“推开”光线 (Push-off Ray)
- 从光线原始起点,首先投射一束 固定 ε (epsilon) 距离的短光线。
- 关键特性: 在这个阶段,算法会 忽略所有遇到的背面(Ignore back faces)。这确保了即使起点在近似几何体内部,这束短光线也能成功地“穿出”表面,而不是立即与背面碰撞。
-
第二步:长距离场景追踪 (Main Scene-Tracing Ray)
- 只有当第一步的短光线成功行进了 ε 距离后,算法才会从这个新的、被“推开”的终点开始,投射真正的长距离追踪光线。
- 关键特性: 这束长光线 不附带任何面剔除属性(no sidedness properties),可以正常地与场景中的任何表面(无论是正面还是背面)进行相交测试。
-
-
效果: 这种简单的两步法成功地消除了之前普遍存在的自相交瑕疵,使得光线追踪结果变得干净和正确。
补充方法:屏幕空间追踪 (Screen Traces)
除了上述针对光追场景的修改外,Lumen的另一核心组件也天然地规避了此问题。
- 核心观点: 屏幕空间追踪(Screen Traces) 本身也是克服自相交问题的一种有效手段。
- 工作原理: 屏幕空间追踪可以利用 G-Buffer 的深度信息,为硬件光线追踪提供一个 起始的 t 值(即沿光线方向的距离)。这个起始 t 值已经将光线的起点有效地设置在了 视图包围盒(Bounding View Frustum) 之外,从而自然地跳过了紧邻起始表面的自相交风险区域。
大规模场景下光线追踪的性能挑战与 HLOD 解决方案
在处理包含海量实例的超大规模场景(如 The Matrix Awakens Demo)时,硬件光线追踪面临着巨大的性能压力。本节内容探讨了由此引发的性能瓶颈、为解决瓶颈而采用的初步方案,以及该方案带来的新问题与最终的解决思路。
硬件光线追踪的性能瓶颈
当场景中的实例数量达到数十万甚至上百万级别时,主要面临两大性能瓶颈:
-
加速结构(AS)的构建与遍历成本
- 核心观点: 随着实例数量的急剧增加,硬件光追模型的负担也随之剧增。在Demo的开发过程中,活跃实例数从最初预计的10万,逐步接近50万,并计划达到100万。
- TLAS重建开销: 系统需要 每帧重建顶层加速结构 (Top-Level Acceleration Structure, TLAS)。实例数量的爆炸式增长使得这一步骤的开销变得无法承受。
- 光线遍历开销: 巨大的实例总数和与之关联的海量三角形,导致 光线遍历 (Ray Traversal) 过程本身也变得极其昂贵和耗时。
-
初步优化方案:限制最大追踪距离
- 核心观点: 为了将性能控制在预算范围内,最直接有效的方法是“少做工作”,即限制光线的追踪距离。
- 具体措施: 团队将 最大追踪距离 (Maximum Trace Distance) 与 光线追踪网格的剔除距离 (Ray Tracing Mesh Culling Distance) 进行对齐。
- 最终妥协: 为了达到性能目标,最终不得不将最大追踪距离严格限制在 200米。
限制追踪距离引发的视觉问题
虽然限制追踪距离解决了性能问题,但却带来了无法接受的视觉质量下降,主要体现在两个方面:
-
反射内容缺失
- 问题描述: 车辆等光滑表面的反射无法再捕捉到200米以外的物体。最明显的例子是,反射中完全 丢失了远方的天际线 (skyline),使得场景真实感大打折扣。
-
全局光照(GI)错误
- 问题描述: 这个问题更为严重。由于光线无法追踪到远处的建筑物,全局光照解算器(GI Solver)无法获得正确的 天空遮挡 (Sky Occlusion) 信息。
- 具体影响: 这会导致天空光从本应被远处建筑遮挡的地方“泄漏”进来,完全破坏了场景的光照氛围和可信度。
解决方案:引入 HLOD 作为远距离光追代理
为了在保持性能的同时,解决远距离视觉信息的丢失问题,团队决定利用引擎现有的系统来“填补”远距离的光追数据。
- 核心思路: 利用 世界分区 (World Partition) 系统及其生成的 HLOD (Hierarchical Level of Detail) 来作为远距离物体的光线追踪代理。
- 关键术语:HLOD
- 定义: HLOD 系统是一种常见的优化技术,它将远处的多个独立网格进行 简化 (simplified) 和 合并 (merged)。
- 目的: 为远处的复杂几何体集合创建一个低成本的 聚合体 (amalgamations)。
- 传统用途: 在传统的光栅化渲染管线中,HLOD 主要用作远处高精度几何体的 直接替代品 (direct replacements),以减少 Draw Call 和顶点处理的开销。
- 新的应用: 在这里,HLOD 的概念被创新性地引入光线追踪管线,用于为超过200米范围的区域提供一个虽然不精确但“足够好”的几何信息,以解决反射和天空遮挡的问题。
光线追踪中 HLOD 的集成与管理
本节探讨了在光线追踪管线中集成 层级细节级别 (Hierarchical Level of Detail, HLOD) 时遇到的一个核心挑战,并提出了一套完整的解决方案。这套方案主要用于处理近距离高精度模型与远距离 HLOD 模型在加速结构中并存的问题。
一、核心挑战:光追与光栅化 HLOD 切换距离不匹配
在传统的光栅化渲染中,HLOD 通常在物体远离摄像机到一定距离后,用于直接替换高精度几何体。但在光线追踪中,情况变得复杂。
- 问题根源:光线追踪的 有效追踪距离 (Performant Trace Distance) 限制,导致我们需要 比光栅化更早地引入 HLOD。
- 直接后果:在某个距离范围内,高精度模型和其对应的 HLOD 模型 会同时存在并占据相同的空间。如果将这两种表示都提交到 顶层加速结构 (Top-Level Acceleration Structure, TLAS) 中,会产生数据不一致性,导致光线可能与两个版本的模型都相交,引发渲染错误。
二、解决方案:利用 Ray Mask 实现互斥与分阶段遍历
为了解决上述问题,讲座中提出了一种精巧的策略,其核心是让两种几何体在 TLAS 中共存,但通过技术手段确保它们 互相排斥 (Mutual Exclusion)。
1. 定义与标记
首先,对两种几何体进行分类和标记:
- 近场几何 (Nearfield Geometry):指代原始的高精度模型。
- 远场几何 (Farfield Geometry):指代 HLOD 模型。
在提交到 TLAS 时,虽然两者都存在,但通过 光线掩码 (Ray Mask) 对远场几何(HLOD)进行特殊标记。这样,在遍历时,可以控制单次光线追踪操作只与其中一类几何体求交。
2. 分阶段光线遍历策略 (Staged Ray Traversal Strategy)
光线遍历被设计成一个包含近场和远场几何的 并集操作 (union of traversal operations),但具体执行顺序根据光线类型有所不同。
-
有序遍历 (Ordered Traversal) - 例如:主摄像机光线 (Primary Rays)
- 目标:需要找到最近的交点,顺序至关重要。
- 步骤 1: 首先,只针对 近场几何 进行光线追踪,追踪距离限制在一个与网格剔除距离对齐的阈值内。
- 步骤 2: 对于在第一步中 未命中 (miss) 的光线,将它们 重新排队 (re-queued),然后仅针对 远场几何 进行第二次追踪。
-
无序遍历 (Unordered Traversal) - 例如:阴影光线 (Shadow Rays)
- 目标:只需要知道是否存在遮挡物,最近交点的位置不重要。
- 步骤 1: 反转操作顺序,首先针对 远场几何 进行追踪。
- 性能考量: 这样做是因为 远场几何包含的实例和三角形数量远少于近场,因此遍历速度更快。对于阴影测试,如果光线在远场追踪阶段就命中了物体,就可以立即确定该点处于阴影中,无需再进行昂贵的近场追踪,这是一个重要的性能优化。
三、管线实现:Compaction 与 Indirect Dispatch
为了在硬件渲染管线中高效实现上述的分阶段遍历策略,引入了新的管线阶段:
-
中继压缩步骤 (Intermediary Compaction Step):
- 在第一阶段的近场追踪完成后,此步骤会收集所有未命中的光线。
- 它将这些“幸存”的光线 压缩整理 (collating/compaction) 成新的 光线瓦片 (Ray Tiles)。
-
间接派发 (Indirect Dispatch):
- 随后,通过一次 间接绘制/派发调用,启动针对远场几何的第二次光线追踪任务,处理这些新生成的光线瓦片。
通过这种方式,整个过程可以高效地在 GPU 上执行,避免了 CPU 的介入和不必要的同步开销。
四、可视化与总结
讲座中的可视化清晰地展示了 近场几何 和 远场几何 的划分界限。同时,还高亮了那些没有对应 表面缓存条目 (Surface Cache Entry) 的几何体。
核心观点总结:通过 Ray Mask 实现逻辑上的互斥,并根据光线类型(有序/无序)设计 分阶段的遍历策略,最后通过 Compaction 和 Indirect Dispatch 在硬件管线中高效执行,是解决光线追踪中 HLOD 与原始模型共存问题的关键。

远景几何体光线追踪:加速结构(AS)的挑战与实践
混合近景与远景几何体带来的性能问题
当我们将 近景几何体 (near-field geometry) 和 远景几何体 (far-field geometry) 同时提交到同一个 顶层加速结构 (Top Level Acceleration Structure, TLAS) 中时,会引发严重的性能问题。
-
核心问题:几何重叠 (Geometric Overlap)
- 将空间上相距甚远的近景和远景物体放入同一个TLAS,会导致其顶层包围盒(Top-level Bounding Box)异常巨大,内部空间利用率极低。
- 这会严重破坏TLAS的结构和效率,导致光线遍历(Traversal)性能下降。
-
性能惩罚:
- 早期实验表明,简单地将远景几何体叠加到主TLAS中,会导致所有近景物体的光线遍历成本 增加高达 44%,这是一个“毁灭性”的性能打击。
-
光线掩码 (Ray Mask) 的局限性:
- 虽然可以使用光线掩码来指示光线在遍历时跳过远景或近景物体,但这仅仅是“运行时”的优化。
- 它无法弥补因几何重叠对 TLAS构建本身造成的巨大损害。TLAS的质量在构建时就已经被拉低了。
加速结构(AS)的优化策略
为了解决上述问题,团队评估了两种方案:理想方案与现实中采用的折衷方案。
理想方案:多套顶层加速结构 (Multiple TLAS)
- 核心思想: 为近景和远景几何体分别构建和维护独立的TLAS。
- 优点:
- 从根本上消除了几何重叠问题。
- 不再需要使用光线掩码来区分几何体。
- 是架构上最“正确”和高效的解决方案。
- 未采用原因:
- 这是一个重大的 架构级变更 (architectural change)。
- 在项目中期,面对紧张的开发周期,进行如此大的改动风险过高,因此被搁置。
实际方案:全局平移偏移 (Global Translational Offset)
- 核心思想: 一种巧妙的“Hack”方法,在不改变核心架构的前提下,缓解TLAS的性能问题。
- 实现方式:
- 在将远景几何体提交到TLAS之前,对其应用一个巨大的全局平移偏移。
- 这相当于在逻辑上将远景“推”到一个与近景世界完全不相交的遥远坐标空间。
- 效果:
- 通过在空间上“分离”近景和远景的实例(Instances),极大地减少了TLAS顶层节点的重叠。
- 虽然仍会因为使用单一TLAS而存在一些性能损失,但这种方法 显著降低了(significantly reduces) 与之相关的性能开销,使其变得可以接受。
应用效果与视觉提升
这项远景追踪技术被应用于所有的 Lumen 光照处理流程 (Lumen passes) 中,带来了显著的画质改善。
- 最显著的影响: 反射遮蔽 (Reflection Occlusion)。远处的物体现在可以正确地遮挡反射,使反射效果更加真实。
- 其他影响: 改善了远景区域的 全局光照 (Global Illumination) 贡献,使得远处的场景光照更加准确和丰富。
总结:构建分层遍历管线 (Tiered Traversal Pipeline)
这一部分所讨论的近景与远景处理策略,是构建最终的 分层遍历管线 (tiered traversal pipeline) 的关键组成部分之一。整个系统为美术师提供了两种不同的着色模型,以应对不同距离和复杂度的渲染需求。
光线追踪管线回顾与性能对比
一、 分层遍历管线 (Tiered Traversal Pipeline) 核心思想回顾
这部分内容是对前面所介绍的、经过精心设计的 Lumen 光线追踪管线进行总结,其核心在于通过分层和级联的思想,在性能和质量之间取得极致的平衡。
1. 双重着色模型 (Dual Shading Models)
为了兼顾不同场景下的性能与质量需求,Lumen 为艺术家提供了两种着色模型:
- Surface Cache 模型: 核心是速度。它是一种性能优先的模型,用于快速获取间接光照信息。
- Hit Lighting 模型: 核心是质量。当 Surface Cache 无法提供足够信息或需要更高精度时,会采用这种模型进行更精确的光照计算,但开销也更高。
2. 近场与远场的几何表示 (Near/Far-Field Geometry)
为了应对大规模场景中海量的几何体,Lumen 采用了两种不同的几何数据表示,并设计了平滑的过渡机制:
- 近场 (Near-field): 使用高精度的原始几何体(例如 Nanite 网格)进行追踪,保证近处细节的准确性。
- 远场 (Far-field): 使用低精度但性能极高的几何体表示(例如 Mesh SDF)进行追踪,用于处理远处的物体。
- 平滑级联 (Graceful Cascade): 系统能够在这两种几何表示之间平滑地过渡,确保视觉上没有明显的跳变。
3. 优化的执行流程与调度 (Optimized Execution Flow)
为了最大化性能并最小化 GPU 的 调度开销 (Dispatch Costs),管线被精心设计为多阶段级联:
- 优先解析 Surface Cache: 首先,在近场和远场几何体上进行光线追踪, 优先处理所有能够命中 Surface Cache 的光线。这是管线中最高效的路径。
- 打包与二次入队 (Compact & Re-queue): 对于未能命中 Surface Cache 但成功命中几何体的光线(Hits),系统会将其 打包(Compact),然后 选择性地重新入队(Re-queue),送入下一步进行开销更高的 Hit Lighting 计算。
- 处理未命中 (Misses): 对于完全没有命中任何几何体的光线(Misses),它们会继续 级联(Cascade) 到最后的阶段,进行 天光(Skylight) 的计算。
二、 Lumen 光追管线核心优势总结
相较于 UE4 原始的硬件光追模型,这套新的管线架构展现了显著的进步:
- 性能导向的遍历方案: 通过深度整合 Surface Cache,构建了一套 为性能而生的极简遍历方案 (Minimalistic Traversal Scheme)。
- 处理海量几何体: 引入远场几何表示,成功解决了现代游戏场景中 几何实例复杂度过高 (Overwhelming Geometric Instance Complexity) 的难题,并同时显著扩展了有效的光线追踪距离。
- 解决LOD不匹配问题: 针对引入 Nanite 这类复杂几何资源时固有的 几何LOD不匹配 (Geometric LOD Mismatches) 问题,提供了有效的解决方案。
三、 光线追踪方法的性能与精度权衡
在深入探讨更多细节之前,讲座首先从宏观上对几种不同的追踪方法进行了性能和精度的对比。
-
全局距离场追踪 (Global Distance Field Tracing)
- 成本: 速度最快。
- 精度: 最低,通常只能提供一个大致的遮挡信息。
- 结论: 由于其精度限制,它无法单独作为高质量的 GI 解决方案,必须依赖其他更精确的方法进行补充和修正。
-
补充方法 (Complementary Methods)
- 为了弥补 Global SDF 的精度不足,通常会结合以下技术:
- 屏幕空间追踪 (Screen Traces)
- 网格距离场追踪 (Mesh SDF Tracing)
- 为了弥补 Global SDF 的精度不足,通常会结合以下技术:
Lumen 的光线追踪策略:软件追踪 vs. 硬件追踪
Lumen 为了在不同场景和硬件上实现动态全局光照,提供了两种核心的远场光线追踪(Far-field Tracing)方案: 软件光线追踪 (Software Ray Tracing - SRT) 和 硬件光线追踪 (Hardware Ray Tracing - HRT)。开发者需要根据项目需求在性能和质量之间做出权衡。
两种追踪方法的核心特性
硬件光线追踪 (Hardware Ray Tracing)
- 核心观点: 追求极致的视觉精度,但性能开销巨大且难以缩放。
- 优点:
- 极高的准确性: 能够提供几何体级别精确的光线求交结果。
- 支持高级效果: 是实现某些高级视觉效果的唯一选择,例如:
- 清晰的镜面反射 (Mirror Reflections)。
- 蒙皮网格体 (Skinned Meshes) 对间接光照的精确贡献。
- 缺点:
- 成本高昂: 性能开销非常大,尤其是开启 命中光照 (Hit Lighting) 时,其成本甚至会高到无法在性能图表中正常展示。
- 扩展性差: 缺乏有效的降级方案,难以在保证帧率的情况下适应性能较低的平台。
软件光线追踪 (Software Ray Tracing)
- 核心观点: 为性能而生,通过在合并后的场景表示(Mesh SDF)上追踪,极大地优化了复杂几何场景的性能。
- 优点:
- 极致的性能: 是目前 Lumen 中最快的追踪方法,是实现次世代主机 60 FPS 等高性能目标的首选。
- 高效处理重叠几何体: 对于使用 Kitbashing 等技术构建的、含有大量重叠网格体的场景,性能优势极为明显。它在一个 快速的合并版本(fast merged version) 上进行追踪,避免了硬件光追需要遍历每一个独立网格体的巨大开销。
如何选择:应用场景与决策依据
项目的具体需求决定了应采用哪种追踪方法。
应当选择软件光追 (SRT) 的场景:
- 性能优先: 项目对帧率有严格要求,例如追求次世代主机上的 60 FPS 体验。
- 复杂重叠场景: 场景使用 Kitbashing 技法构建,包含大量重叠的网格体。
- 典型案例: 技术Demo《Lumen in the Land of Nanite》、《Valley of the Ancients》。
应当选择硬件光追 (HRT) 的场景:
- 质量优先: 项目追求绝对顶级的视觉质量,对性能预算较为宽裕。
- 典型案例: 建筑可视化 (Architectural Visualization)。
- 特定效果需求: 项目必须实现硬件光追才能支持的高级效果。
- 典型案例: 《黑客帝国觉醒 (The Matrix Awakens)》中的镜面反射,或角色皮肤等蒙皮网格体需要对周围环境产生精确的间接光照影响。
性能案例研究:《Lumen in the Land of Nanite》
这个技术 Demo 是一个绝佳的例子,展示了在特定内容下两种追踪方法的巨大性能差异。
-
场景特点:
- 这是一个为 Nanite 设计的压力测试场景。
- 洞穴表面由海量网格体堆叠而成,场景中 任意一点都大约有 100 个网格体相互重叠。
-
性能表现对比:
- 硬件光追 (HRT): 对于每一条光线,GPU 都必须遍历并测试所有 100个重叠的网格体,导致追踪成本高到无法接受。Epic Games 明确表示,如果使用硬件光追,这个 Demo 根本无法发布。
- 软件光追 (SRT): 在预生成的 Mesh SDF 这种合并后的加速结构上进行追踪。光线追踪的开销与重叠的原始网格体数量无关,因此性能表现非常出色。
-
结论: 在几何体极其复杂的重叠场景下,软件光追的性能优势是压倒性的。然而,在如《Lyra 射击游戏》这类场景结构不同的项目中,情况又会有所变化。
硬件光追 vs. 软件光追:场景依赖性分析
本节首先对硬件光线追踪和 Lumen 的软件光线追踪(基于 SDF)在不同场景下的表现进行了对比,得出的结论是最佳选择高度依赖于具体的场景内容。
-
核心观点:不存在一种“万能”的光线追踪方案,开发者需要根据游戏场景的几何特性(如遮挡、重叠复杂性)、性能预算和质量要求来权衡使用硬件光追还是软件光追。
-
案例分析:
- 《Lyra》示例项目 (Lyra U5 Sample Game):
- 场景特点: 几何体之间重叠较少,结构相对开放。
- 性能表现: 在这种场景下, 硬件光线追踪 (Hardware Ray Tracing) 的性能很不错。
- 成本与质量: 两种技术的最终渲染成本和质量差异不大。
- 结论: 选择哪种技术取决于目标硬件的支持情况。
- 《黑客帝国觉醒》技术演示 (The Matrix Awakens Tech Demo):
- 场景特点: 极度复杂的城市环境,包含大量细节和巨大的视距。
- 性能表现: 两种追踪方法的成本几乎相同。
- 质量表现: 硬件光线追踪能提供更高质量的反射,并且结合 Lumen 的远场(Far Field)技术,能够支持超大视距下的全局光照。
- 结论: 在此场景下,硬件光线追踪是更优的选择。
- 《Lyra》示例项目 (Lyra U5 Sample Game):
Part 4: Final Gather
Lumen 的 Final Gather:解决光线传输中的噪声问题
在解决了光线追踪之后,Lumen 需要处理实时全局光照的第三个基本问题: 光线传输中的噪声(Noise in the light transfer)。
- 核心问题:在极低的采样率下(每像素甚至无法负担一条完整光线),如何获得平滑、无噪声的间接光照结果。
- 挑战与目标:
- 预算限制: 实时渲染的预算极低,无法像离线渲染那样为每个像素投射大量光线。讲座中展示的单光线/像素(1 ray/pixel)的结果充满了噪点。
- 质量目标: 要达到高质量的室内全局光照效果,需要等效于数百个样本的光照信息。
全局光照(GI)中漫反射间接光照的求解探索
本节内容回顾了两种历史方案——锥形追踪(Cone Tracing)和辐照度场(Irradiance Fields)的优缺点,并引出了后续将要讨论的、基于蒙特卡洛积分的主流现代方法。
解决方案探索:预过滤锥形追踪 (Pre-filtered Cone Tracing)
为了解决噪声问题,Lumen 团队早期探索了一种名为预过滤锥形追踪的技术,其核心思想是通过一次追踪操作来采集更大范围内的光照信息,从而在源头上抑制噪声。
-
核心思想:
- 用“锥体”代替“光线”:追踪一个 锥体(Cone) 的效果等同于追踪许多条发散的光线。
- 高效降噪:单次锥形追踪可以一次性得到多条光线聚合后的结果,这使得最终着色(Final Gather)阶段的降噪工作变得非常简单。
-
实现细节:基于 SDF 的锥形追踪
-
该技术是针对 网格有向距离场 (Mesh Signed Distance Fields, SDFs) 实现的。SDF 的特性为锥形追踪提供了便利。
-
情况 1:锥体与表面相交 (Cone Intersection)
- 当追踪的锥体与场景表面相交时,系统会根据锥体与表面的相交区域大小来动态计算一个合适的 MIP Level。
- 然后使用这个 MIP Level 去采样 表面缓存 (Surface Cache),从而直接获得被 预过滤(pre-filtered) 过的光照信息。这类似于纹理贴图中的 Mipmapping,用更模糊的低分辨率版本来代表大范围区域的平均值。
-
情况 2:锥体与表面近乎错过 (Near Miss)
- 当锥体只是从一个表面旁边掠过,并未完全命中时,这个表面仍然会对锥体内的光路产生部分遮挡。
- 这个问题被建模为一个 透明度问题 (Transparency Problem)。
- 利用 SDF 可以高效查询点到最近表面的距离这一特性,系统可以估算出锥体轴心到表面的距离,并以此来近似计算锥体被遮挡的比例,从而实现半透明遮挡的效果。
-
锥形追踪(Cone Tracing)及其局限
这是一种早期的、旨在解决漫反射间接光照中噪点问题的技术。
-
核心思想:
- 从着色点向外发射一个圆锥体(而不是单根光线)来收集光照信息。
- 圆锥的遮挡程度是基于 距离场(Distance Field) 计算得出的——通过查询表面点到圆锥中心轴的距离来估算。
- 这种方法天然地对结果进行了模糊,因此没有会导致噪点的硬边,在抑制噪点方面非常有效。
-
技术挑战与解决方案:
- 处理多层半透明/遮挡: 当多个物体部分遮挡圆锥时,会产生多个乱序的“部分命中”(partial hits)。此问题通过 加权混合顺序无关透明度(Weighted Blended OIT) 技术来组合这些贡献。
-
无法解决的根本性缺陷:
- 漏光(Leaking)与过度遮蔽(Over Occlusion)的权衡:
- 对于大范围的直接光线,OIT 方案会导致严重的漏光。
- 虽然在小范围的间接光照下漏光问题有所缓解,但始终无法在漏光和过度遮蔽之间找到一个完美的平衡点。
- 远距离小光源问题: 无法精确解析来自远处微小窗口等高频光照细节。
- 平台局限性: 该技术仅适用于软件光线追踪,无法利用现代硬件光追的优势。
- 漏光(Leaking)与过度遮蔽(Over Occlusion)的权衡:
拥抱蒙特卡洛积分(Monte Carlo Integration)
由于锥形追踪的固有缺陷,开发团队决定转向一种更具可扩展性和通用性的方法。
- 核心决策: 放弃锥形追踪,采用蒙特卡洛积分方法来求解光照。
- 主要优势:
- 质量可扩展性: 能够平滑地扩展到最高质量的渲染效果,满足不同硬件层次的需求。
- 通用性: 支持任何类型的光线追踪实现,包括现代的硬件光追。
- 新的挑战: 这种方法并没有“解决”噪点,而是将问题转移了。噪点问题集中体现在 最终的收集(Final Gather)阶段,需要后续处理(如降噪)来解决。
业界流行方案分析:辐照度场(Irradiance Fields)
这是一种基于探针(Probe)的经典体积光照技术,被广泛用于解决漫反射光照问题。
-
工作流程:
- 在场景体积中放置 光照探针(Probes)。
- 在预计算阶段,从每个探针位置追踪光线, 预积分(Pre-integrate) 周围环境的辐射度(Radiance),计算出该点的辐照度(Irradiance)。
- 在运行时,屏幕上的像素通过插值其周围探针的预计算结果来获取间接光照。
-
核心问题:
- 位置不匹配: 辐照度是在 探针位置(Probe Location) 计算的,而非 像素位置(Pixel Location)。这是该技术所有缺点的根源。
- 漏光与过度遮蔽: 由于上述位置不匹配,当像素的几何环境与附近探针差异较大时,极易产生漏光和过度遮蔽。
- 探针布局困难: 为了缓解上述问题,探针的摆放变得非常棘手和耗时。
- 低空间分辨率: 这是一种 体积表示(Volumetric Representation),出于性能和内存考虑,探针密度通常很低,导致GI效果 看起来很平(flat),缺乏细节。
另一极端:从像素出发的光线追踪
与基于探针的辐照度场相反,另一种方法是直接从渲染的像素出发。
- 核心思想:
- 直接从 屏幕上的实际像素(Actual Pixels) 发出光线来收集间接光照信息。
- 主要挑战:
- 这种方法会产生大量的噪点。
- 解决方案是在光线追踪之后,通过一个 屏幕空间降噪器(Screen Space Denoiser) 来处理噪点。
- 引出后续: 讲座暗示,这种“先追踪再降噪”的方案同样有其自身的一系列问题,将在后续内容中展开。
Lumen中的最终收集:屏幕空间辐射缓存(Screen Space Radiance Caching)
本节内容承接前文,首先指出了传统屏幕空间降噪方案在处理光线追踪噪声时的固有缺陷,然后引出了 Lumen 为解决这些问题而设计的核心技术之一:屏幕空间辐射缓存,并以其在不透明物体上的应用 Opaque Final Gather 为例进行了阐述。
传统屏幕空间降噪器(Screen Space Denoiser)的局限性
在光线追踪中,为了解决噪声问题,一种常见的方法是在渲染完成后,应用一个 屏幕空间的降噪器(Screen Space Denoiser)。然而,这种“事后处理”的方式本身会带来一系列新的问题:
-
性能开销高昂:
- 非相干光线追踪(Incoherent Ray Tracing): 为了获得对半球环境的完整覆盖,降噪器需要一组 解相关的光线(Decorrelated Rays)。这种光线分布模式导致了访问内存的 非相干性(Incoherent),从而使得光线追踪过程变得缓慢。
- 无法降采样(No Downsampling): 降噪操作完全在屏幕空间进行,失去了利用降采样进行优化的机会,计算成本非常高。
-
视觉瑕疵:
- 遮挡剔除问题(Disocclusion): 在场景中新显露的区域(例如,一个角色移动后露出的背景),由于缺乏足够的历史样本进行收敛,降噪器常常会产生明显的视觉瑕疵。
Lumen的解决方案:屏幕空间辐射缓存(Screen Space Radiance Caching)
为了在追踪精度和性能开销之间找到一个更优的平衡点,Lumen 提出了一种创新的方法。
-
核心思想: 屏幕空间辐射缓存(Screen Space Radiance Caching)
- 这是一种 自适应降采样(Adaptive Downsampling) 技术。
- 它不在每个像素上都进行光线追踪,而是在屏幕上选择性地放置 探针(Probes),这些探针被称为 屏幕探针(Screen Probes)。
- 探针的放置密度是自适应的:在几何细节丰富的区域放置更多探针,在平坦区域则放置较少。
-
工作流程:
- 放置探针 (Probe Placement): 在屏幕像素上根据几何复杂度自适应地放置探针。
- 光线追踪 (Ray Tracing): 仅从这些探针的位置发射光线来计算入射光照(Radiance)。
- 插值 (Interpolation): 将探针追踪到的光照结果插值到周围的其他像素上。
- 关键优化 - 限制光照泄漏 (Limiting Leaking): 插值过程被严格限制在 同一平面(Same Plane) 的像素之间。这个约束极大地减少了因插值导致的光照从一个表面泄漏到另一个不相关表面的问题,这种瑕疵在视觉上非常难以察觉。
- 时域累积 (Temporal Accumulation):
- 为了在不增加单帧探针数量的情况下获得完整的覆盖率,探针的放置网格在 每一帧都会进行抖动(Jitter)。
- 通过 时域累积(Temporally Accumulated) 多帧抖动后的结果,最终实现高质量、高覆盖率的渲染效果。
-
在Lumen中的应用与演进:
- 这项技术在 Lumen 中被称为 不透明物体最终收集(Opaque Final Gather)。
- 它已经在《黑客帝国觉醒:虚幻引擎5体验》技术演示中得到了充分的压力测试和验证。
- 更重要的是, Opaque Final Gather 的设计理念成为了一个 原型(Archetype),后续被成功扩展到了其他领域,例如 Volumetric Final Gather - GI on translucency 和 Texture space Gather - multibounce Surface Cache。
Opaque Final Gather: 一种分层的光照缓存方案
本节讲座深入探讨了用于不透明物体的 Final Gather 技术,其核心思想是通过 多层次、多分辨率的辐射缓存(Radiance Cache) 来高效地计算间接光照,并在不同尺度上捕捉光照细节。
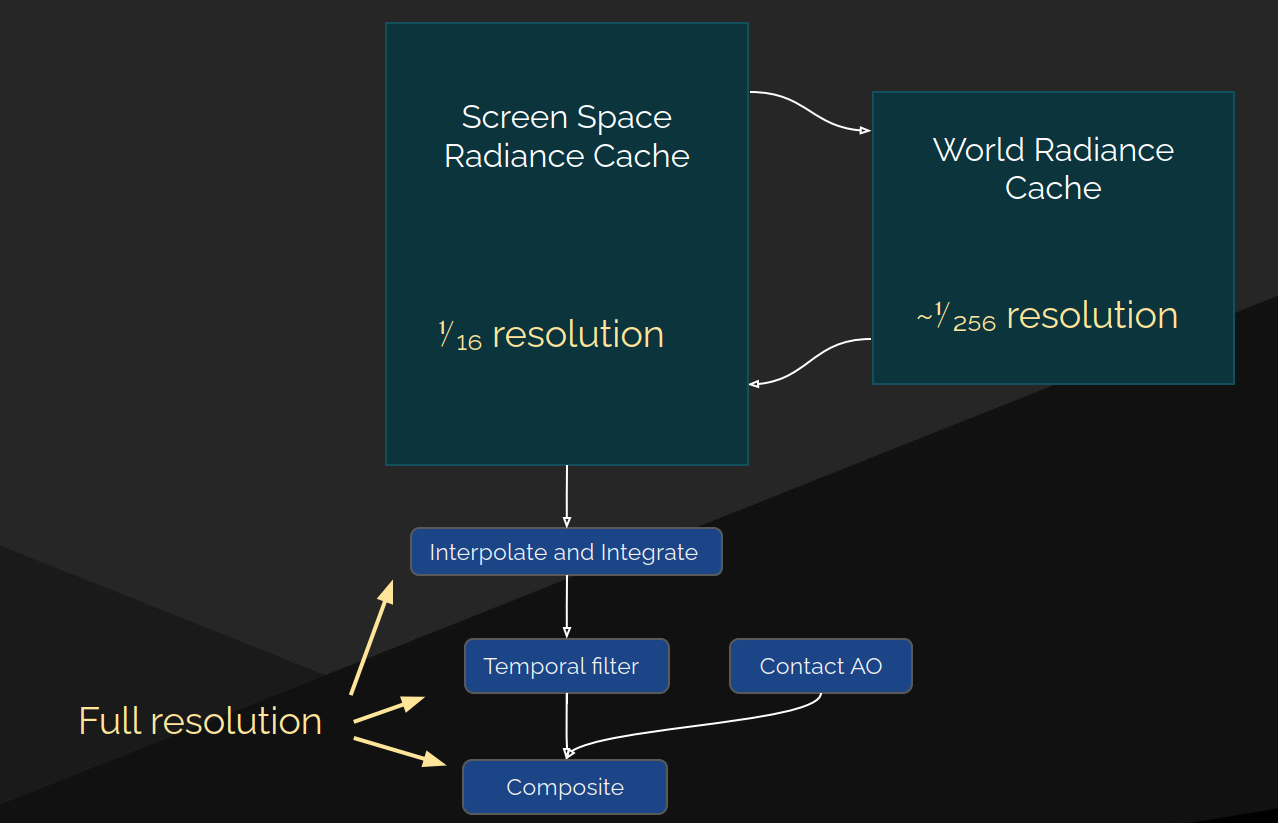
系统核心组件与分层结构
该 Final Gather 系统主要由三个关键部分构成,形成一个从远到近、从粗到精的光照计算层次:
-
世界空间辐射缓存 (World Space Radiance Cache - WSRC)
- 核心观点: 处理远距离的、低频的间接光照。
- 关键特性:
- 作为屏幕空间缓存的 “后备(Backup)”,处理超出屏幕空间缓存范围的光照。
- 以一个非常低的分辨率运行,例如处理超过 2 米距离的光照信息。
- 潜在问题: 由于其稀疏性和低分辨率特性,探针可能会“看穿”薄墙,导致漏光。但在示例中,它能准确地捕捉到远处窗户对墙壁的照明。
-
屏幕空间辐射缓存 (Screen Space Radiance Cache - SSRC)
- 核心观点: 处理近距离的、中高频的间接光照。
- 关键特性:
- 在降采样的屏幕空间中运行,例如在每个维度上以 1/16 的分辨率 (总共 1/256 的像素数)进行操作。
- 主要负责捕捉 附近的间接阴影 (Indirect Shadows) 和光线反弹。
- 探针布局 (Probe Placement): 采用自适应策略,在大部分区域均匀放置探针,但在几何细节丰富的区域,会细分网格以放置更多探针,从而提高局部精度。
-
全分辨率处理 (Full-Resolution Pass)
- 核心观点: 整合缓存数据并补全高频细节。
- 关键组件:
- 插值与积分 (Interpolation and Integration): 在全分辨率下,对来自 SSRC 和 WSRC 的光照数据进行插值和积分,应用到最终像素上。
- 时间滤波 (Temporal Filter): 用于平滑和稳定结果。
- 接触环境光遮蔽 (Contact AO): 这是一个至关重要的补充步骤,用于 恢复因 SSRC 降采样而丢失的高频接触阴影细节。
光照贡献的逐层叠加效果
系统通过逐层叠加不同组件的贡献,最终形成完整的光照效果:
- 基础层: 从 天光 (Skylight) 开始,提供场景的基础环境光。
- 远场层 (+ WSRC): 叠加世界空间辐射缓存,为场景加入远距离的间接光照。例如,远处窗户投射到墙壁上的明亮区域。
- 近场层 (+ SSRC): 叠加屏幕空间辐射缓存,引入所有近场的间接光照和遮蔽,此时可以看到柔和的间接阴影,但由于是在低分辨率空间计算,阴影边缘会比较模糊或呈块状。
- 细节层 (+ Contact AO): 最后应用接触 AO,锐化和增强物体接触部分的阴影,弥补了 SSRC 丢失的细节,使场景更具真实感。
屏幕空间辐射缓存 (SSRC) 的核心优势
SSRC 最重要的一个洞见在于它提供了一种极其廉价的大范围空间滤波方法。
-
核心观点: 通过在 低分辨率的缓存空间(Probe Space) 而非高分辨率的屏幕空间进行滤波,可以用极小的计算开销实现巨大的滤波效果。
-
关键对比:
- 在 SSRC 的探针空间中进行一次 小范围的 3x3 滤波
- 其效果等同于在全分辨率屏幕空间中进行一次 超大范围的 48x48 滤波。
这个等效关系源于 SSRC 的 1/16 分辨率:
这种方法极大地提升了降噪和模糊处理的效率,是该技术性能表现的关键。
基于探针的高级光照与实时重要性采样
在探针空间(Probe Space)中操作的核心优势
通过将计算从屏幕空间转移到降采样的探针空间,可以用极低的成本实现媲美巨大屏幕空间滤波器的降噪效果,并大幅减少数据加载带宽。
- 高效降噪: 在探针空间中进行处理,其降噪效果等同于一个 48x48 像素的超大屏幕空间卷积核(Kernel),但计算开销完全不在一个量级。
- 数据带宽优势: 系统无需加载屏幕上每个像素的位置(Position)和法线(Normal)等信息,而仅需加载探针的位置数据。这极大地降低了内存和带宽的压力,使得复杂的计算成为可能。
对入射光照进行重要性采样
利用上一帧的辐射缓存(Radiance Cache)进行时间重投影(Temporal Reprojection),为当前帧的重要性采样提供了极其精确的引导信息(Importance Estimate),从而显著提升采样效率和渲染质量。
- 采样质量基础: 重要性采样的效果好坏,完全取决于 重要性估计(Importance Estimate) 的准确度。
- 获取高质量估计:
- 主要来源: 将 上一帧的屏幕空间辐射缓存(Screen Space Radiance Cache) 重投影到当前帧。这为当前帧的入射光分布提供了一个非常精确的预测。
- 高效查找: 由于辐射缓存是按位置和方向进行索引的,可以非常高效地找到上一帧的所有光线信息。
- 鲁棒性与回退机制:
- 问题: 在屏幕边缘或发生遮挡变化(Disocclusion)的区域,重投影会失效。
- 解决方案: 在重投影失败时,系统会 回退到使用世界空间辐射缓存(World Space Radiance Cache)。虽然精度可能略低于屏幕空间缓存,但它仍然能提供有效的重要性采样信息,保证了算法的鲁棒性。
实现实时的乘积重要性采样(Product Importance Sampling)

得益于在降采样探针空间中操作所节省的计算资源,可以为每个探针分配一个完整的线程组(Thread Group),从而在实时渲染中实现了通常只有离线渲染才能使用的“乘积重要性采样”,这比单独采样BRDF或光照,甚至比多重重要性采样(MIS)更为高效。
-
实现前提: 在降采样的探针空间进行计算,使得我们可以为每个探针启动一个完整的计算着色器线程组,从而有充足的算力来执行复杂的采样算法。
-
关键技术:乘积重要性采样 (Product Importance Sampling)
- 这是一种将 BRDF 分布 和入射光照分布相乘,从而生成一个更优采样分布的先进技术。
- 它将采样方向集中在那些对最终结果贡献最大的区域,即 BRDF 和光照值都很高 的方向。
-
与其他采样方法的对比:
- 优于单一采样: 比单独对 BRDF 或光照进行重要性采样的效果更好。
- 优于多重重要性采样 (MIS): MIS 会根据多个分布(如BRDF和光照)生成候选样本,但如果一个根据BRDF生成的样本方向上并没有很强的光照,那么这次光线追踪的开销就被浪费了(权重很低)。乘积重要性采样在生成样本之前就结合了两种分布的信息,从源头上避免了这种浪费。
-
直观解释:
- BRDF 分布: 对于墙上的一个探针,其 BRDF 可能是一个半球,定义了哪些方向的光线可能被反射。
- 光照分布: 从上一帧重投影得到的信息告诉我们,光主要从两个特定方向射入。
- 乘积与优化: 算法将原本会均匀分布在整个半球的“无效”光线(即射向没有光照区域的光线), 重新分配(Reassign) 到那两个光照最强的方向上进行 超采样(Super Sample),从而用同样的光线数量,获得远超传统方法的积分精度和更低的噪声。
Lumen 核心技术解析:世界空间辐射缓存 (World Space Radiance Cache)
在 Lumen 的光照系统中,除了屏幕空间的探针,还存在一个更为宏观和稳定的光照缓存机制—— 世界空间辐射缓存 (World-Space Radiance Cache, WSRC)。它与屏幕空间缓存互为补充,专门解决特定但棘手的光照难题。
核心思想:处理远距离光照
WSRC 的设计目标非常明确: 以较低的空间分辨率,换取更高的方向分辨率,从而精确捕捉远距离光照。
- 解决的问题: 想象一个场景,房间的主要光源是一个很小的、远处的窗户。如果仅依赖数量有限的光线进行采样(如屏幕探针),这些光线很可能完全错过这个窗户,导致整个房间一片漆黑。
- 核心权衡 (Trade-off):
- 高方向分辨率 (Higher Directional Resolution): 缓存能够精确记录来自特定方向(如小窗户)的光线信息,不会因为角度太小而丢失。
- 低空间分辨率 (Lower Spatial Resolution): 探针在世界空间中分布得比较稀疏。这是合理的,因为远距离光照在局部空间内变化通常比较平缓,不需要逐像素的精度。
- 引申概念: 在上一部分提到的“重要方向超采样”技术,其本质也是为了在不增加光线总数的情况下,将计算力集中用于捕捉这类关键的、高能量的微小光源。
缓存的整合与回退机制 (Integration & Fallback)
WSRC 并非独立运作,而是作为对屏幕空间探针系统的补充和 回退 (Fallback) 方案。
- 整合流程:
- 首先,系统会发射一根 被缩短的屏幕空间探针光线 (shortened screen probe ray)。
- 如果该光线在较短的距离内击中了场景物体,则使用高精度的屏幕空间缓存结果。
- 如果光线未击中任何物体(即飞向了远方),系统判定此处需要远距离光照信息,此时会从 WSRC 中 插值获取 (interpolate) 光照数据。
- 关键优势:稳定的误差 (Stable Error)
- 由于 WSRC 的探针位置在世界空间中是稳定的,不会像屏幕探针那样随着摄像机的移动而每帧变化。
- 这使得因插值产生的任何潜在瑕疵(误差)也是稳定且不易察觉的,更容易在后期处理中被隐藏,避免了闪烁等恼人的视觉问题。
探针布局与管理 (Probe Layout & Management)
WSRC 的性能和效果在很大程度上取决于其探针的有效管理。
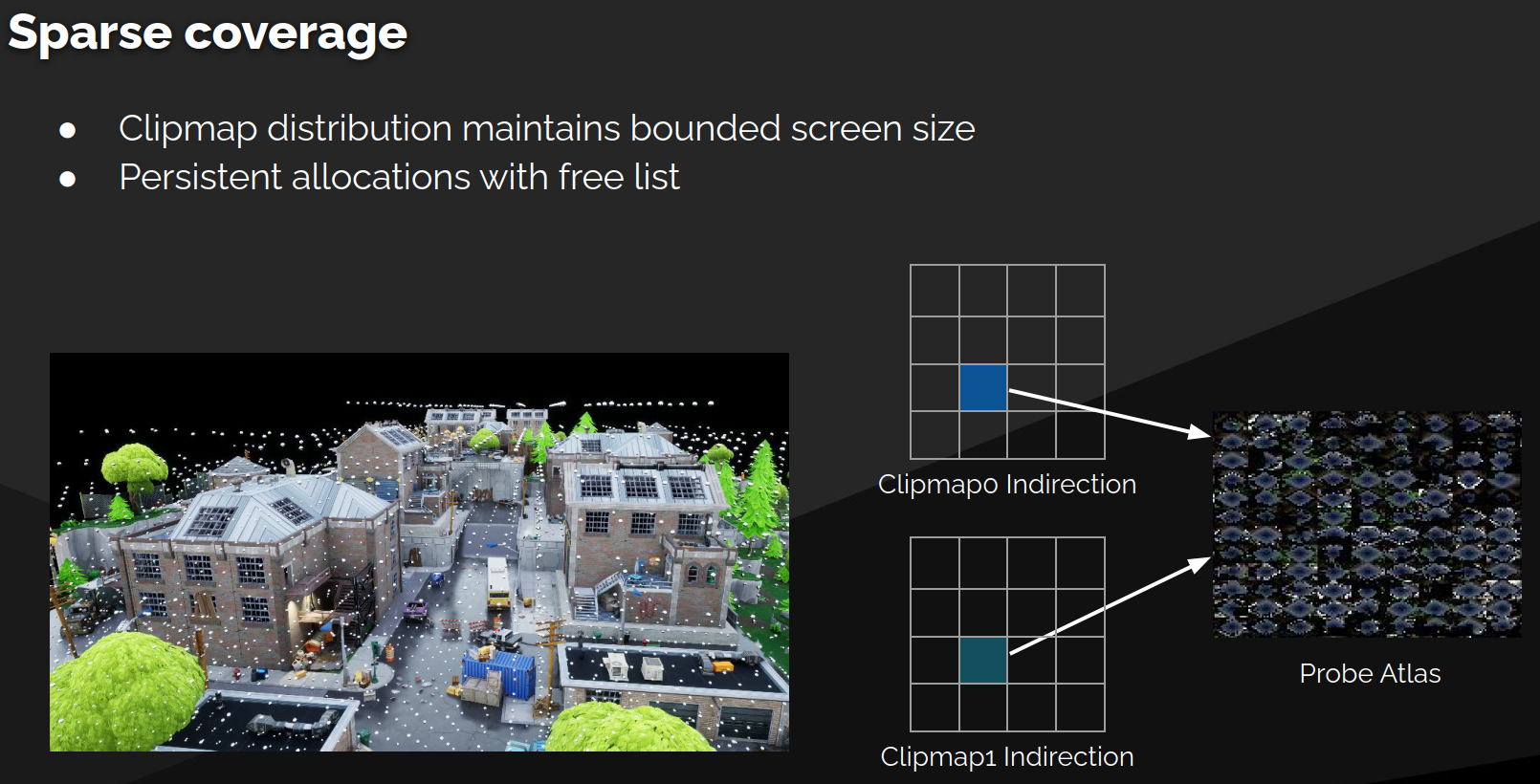
-
空间分布:Clipmap 结构
- 探针在世界空间中是 稀疏覆盖 (sparse coverage) 的。
- 为了在不同距离下都保持高效的采样率,系统采用了 Clipmap 分布。这种布局可以确保无论探针距离摄像机多远,其在屏幕上的投影间距都维持在一个 有界的尺寸 (bounded screen size) 内。
- 目的: 避免在远处过度采样(浪费性能),或在近处采样不足(导致瑕疵)。
-
时间管理:持久化与增量更新
- 持久化分配 (Persistent Allocations): 探针的内存是持久化的,可以 跨帧复用 (survive across frames),避免了每帧重新创建的巨大开销。
- 缓存策略:
- 复用: 前一帧的探针如果在新的一帧中仍然有效,则直接继承使用。
- 新增: 因摄像机或场景物体移动而新暴露出来的区域,会追踪新的探针来填充。
- 传播: 每帧会选择一小部分现有探针进行重算(retrace),以便让光照变化(如开关灯)能够在整个世界中逐步传播开来。
-
更新优化:GPU 优先队列
- 为了实现稳定的性能预算,系统引入了一项重要改进:使用 GPU 优先队列 (GPU priority queue)。
- 该队列每帧会根据重要性(如距离、上次更新时间等)选择固定数量的探针进行更新。
- 核心收益: 实现了对整个缓存的 固定的更新开销 (fixed update cost)。无论场景如何变化,每帧用于更新 WSRC 的性能消耗都是可预测和可控的。
应用案例:《黑客帝国:觉醒》夜间模式
- 场景特征: 在《黑客帝国:觉醒》的实验性夜间模式中,整个场景 完全由自发光网格 (emissive meshes) 提供照明。
- 挑战: 绝大部分光源是那些微小而明亮的灯泡网格。
- WSRC 的价值: 这种场景完美地体现了 WSRC 的优势。它能够以高方向分辨率精确捕捉到这些小光源的贡献,为整个宏大场景提供真实可信的间接光照,而这是传统屏幕空间方法难以企及的。
处理自发光网格 (Emissive Meshes) 的挑战
本节探讨了在GI(全局光照)系统中处理小型、高亮度自发光体(如灯泡)时遇到的问题,并提出了一种更优的解决方案。
-
核心观点: 基于探针(Probe-based)的GI系统在处理小型、高亮度的自发光体时存在固有困难。因为这类系统通常不进行显式的光源采样(explicitly sampling the light sources),导致难以精确捕捉到这些微小但能量巨大的光源所贡献的直接光。
-
更优的解决方案: 世界空间辐射缓存 (World Space Radiance Cache)。
- 优势:
- 更高的方向分辨率 (Higher Directional Resolution): 能够更精确地捕捉来自小光源的直接光照方向和强度。
- 时间上稳定 (Temporally Stable): 相比于随机采样的GI方法,它能提供没有闪烁和噪声的稳定结果。
- 结果更精确 (More Accurate): 专门处理直接光照,效果远胜于依赖GI探针偶然捕捉到的间接光照。
- 优势:
Temporal Filter
时间滤波是现代实时渲染管线中平滑噪声、稳定画面的关键步骤。本节深入探讨了其设计选择、优缺点以及优化策略。
-
核心目标: 其主要目的是为了平滑和稳定因探针位置和方向抖动(Jittering)而产生的噪点,从而在多个帧之间累积信息,生成高质量的GI结果。
-
稳定性与鬼影的权衡 (The Stability vs. Ghosting Trade-off)
- 实现方式: 为了获得极致的 稳定性(Stability),该方案 不使用邻域钳制(Neighborhood Clamp)。而是通过比较当前帧与历史帧的 深度(Depth)和法线(Normal)差异 来决定是否拒绝(Reject)历史数据。
- 带来的问题: 这种追求稳定性的策略,会导致对光照变化的响应变慢,从而在移动物体后方产生明显的 鬼影(Ghosting)。
-
鬼影问题的缓解策略
- 动态调整滤波速度:
- 关键技术: 系统会检测光线追踪是否击中了快速移动的物体。
- 优化逻辑: 如果一个像素的大部分光照贡献来自于这些快速移动的物体,系统会动态加速该像素时间滤波的收敛速度,使其更快地适应新的光照环境,从而减少鬼影。
- 分离不同频率的光照效果:
- 最短距离遮蔽 (Shortest Range Occlusion): 为了避免延迟,这个效果是在时间滤波之后再应用的。这确保了近距离的遮蔽效果(如角色脚下的阴影)能够 实时响应,无延迟(lag-free)。
- 最短距离遮蔽 (Shortest Range Occlusion): 为了避免延迟,这个效果是在时间滤波之后再应用的。这确保了近距离的遮蔽效果(如角色脚下的阴影)能够 实时响应,无延迟(lag-free)。
- 动态调整滤波速度:
-
架构设计洞察:利用不同光照的延迟容忍度
- 核心思想: 不同距离和类型的光照传播,可以容忍不同的更新延迟。
- 近距离间接光 (Shortest range indirect lighting): 必须低延迟,需要即时响应场景变化。
- 远距离光照/天光 (Distant lighting / Skylight): 可以容忍较高的延迟,缓慢更新不会对视觉产生太大影响。
- 架构的契合性: 讲座中提到的渲染系统架构具有前瞻性。其 最终收集(Final Gather) 阶段已经将辐射度(Radiance)按距离范围(Distant Ranges)进行了分离,并使用不同的技术来求解。这种设计天然地契合了不同光照成分对延迟的不同容忍度,为性能优化和效果权衡提供了极大的便利。
- 核心思想: 不同距离和类型的光照传播,可以容忍不同的更新延迟。
半透明与体积雾的 GI 挑战
本节主要探讨了在性能预算极其有限的情况下,如何为 半透明材质(Translucency) 和 体积雾(Volumetric Fog) 实现高质量的全局光照(GI)。其核心思想是采用一种名为 “体积最终收集”(Volumetric Final Gather) 的快速技术来处理局部光照,同时复用一个独立的 世界空间辐射缓存(World-Space Radiance Cache) 来处理高质量的远距离光照,形成一种混合解决方案。
为非不透明物体提供全局光照,面临着与不透明表面截然不同的挑战,尤其是在性能方面。
-
半透明材质 (Translucency):
- 多层复杂性: 需要支持多层半透明介质的堆叠,例如浓密的灰尘颗粒。
- 阴影至关重要: 如果没有正确地为天光(Skylight)等环境光提供阴影,半透明粒子会显得格格不入,缺乏体积感。
-
体积雾 (Volumetric Fog):
- 无处不在的计算: 需要在相机可见的所有深度范围内,为空间中的每一个点求解 GI,而不仅仅是物体表面。
- 全球面光照: 与不透明表面基于法线的半球面积分不同,体积中的一个点需要接收来自 整个球面(Sphere) 的入射光。
- 极端性能预算: 可用的计算预算非常低,大约只有不透明表面最终收集(Final Gather)的 1/8。
解决方案:体积最终收集 (Volumetric Final Gather)

为了应对上述挑战,讲座提出了一种专为体积效果设计的、极其快速的 GI 技术。
-
核心思想: 在视锥体(View Frustum)内构建一个探测器网格,通过追踪、降噪和预计算,为半透明和体积雾渲染提供高效的间接光照。
-
关键步骤与技术细节:
-
数据结构 - 视锥体探测器网格 (Frustum Probe Volume):
- 在相机的视锥体内创建一个与视锥体对齐的三维网格(Frustum-aligned Grid,常被称为 Froxel Grid)。每个格子内放置一个光照探测器(Probe)。
-
光线追踪与优化:
- 八面体探测器 (Octahedral Probes): 在每个探测器位置,向周围追踪光线以收集入射光。使用八面体映射来参数化球面方向。
- 可见性剔除: 通过 HZB (Hierarchical Z-Buffer) 测试 来预先判断哪些探测器位于场景几何体内或被完全遮挡,从而跳过对这些不可见探测器的追踪,大幅提升性能。
-
降噪处理 (Denoising):
- 由于追踪的光线数量很少,原始结果会充满噪声。因此需要进行积极的降噪处理。
- 空间滤波 (Spatial Filter): 对相邻探测器的辐射度(Radiance)结果进行模糊处理。
- 时间累积 (Temporal Accumulation): 复用前几帧的结果,在时间维度上平滑噪声。
-
数据存储与使用:
- 球谐光照预积分 (Pre-integration into Spherical Harmonics): 将降噪后的辐射度数据 预积分并编码为球谐函数(SH) 系数,这是一种紧凑、高效地存储低频光照信息的方式。
- 插值使用: 在最终的渲染阶段, 前向半透明渲染通道 (Forward Translucency Pass) 或 体积雾渲染通道 (Volumetric Fog Pass),只需在探测器网格中进行三线性插值,即可廉价地获取当前位置的间接光照信息。
-
处理远距离光照的局限性与对策
Volumetric Final Gather 虽然速度快,但由于其低采样率和空间/时间滤波,无法精确解析高频的远距离光照。
-
问题场景:
- 一个典型的例子是洞穴场景:整个洞穴主要由从一个很小的洞口射入的天光照亮。这种单一、高对比度的远距离光源对于低分辨率的探测器系统来说,会产生严重的噪声和不稳定性。
-
混合解决方案:
- 再次引入一个独立的 世界空间辐射缓存 (World-Space Radiance Cache),专门用于处理远距离光照。
- 该缓存具有更高的方向分辨率,能够精确捕捉和存储像小洞口透进来的天光这类高频细节。
- 最终,通过结合 Volumetric Final Gather 提供的局部环境光和 World-Space Radiance Cache 提供的稳定且精细的远距离光照,实现了完整且高质量的体积光照效果。
半透明与远距离光照缓存 (Translucency and Distant Lighting Cache)

为了给场景中的远距离物体提供稳定且具有高方向性分辨率的光照,Lumen 采用了一套专门的辐射度缓存系统。该系统与处理不透明物体的主世界辐射度缓存(Opaque World Radiance Cache)并行工作。
核心流程与技术要点:
-
探针布局 (Probe Placement):
- 在摄像机可见的网格(Visible Grid)周围,系统会 密集地放置探针 (Probes),作为捕获远距离光照信息的采样点。
-
辐射度捕获与预过滤 (Radiance Capture & Pre-filtering):
- 光线追踪: 从每个探针向场景中发射光线,以采样入射光(Radiance)。
- Mipmap 预过滤: 将追踪到的辐射度信息 预先过滤并存储到 Mipmap 中。这是一个关键步骤,因为远距离探针发射的光线数量远多于近处(原文提到是16倍),通过 Mipmap 可以有效 减少采样带来的锯齿 (Aliasing)。
- 追踪优化: 为了提高效率,光线追踪的 距离被缩短 (Shorten Traces)。如果光线在设定的距离内没有命中任何物体(Miss),系统会 从全局的世界探针 (World Probes) 中进行插值,以获取一个合理的背景光照值。
-
性能优化:调度技巧 (Performance Optimization: Scheduling Trick)
- 核心观点: 这套新的半透明/远距离辐射度缓存的计算并非独立执行,而是与现有的不透明物体辐射度缓存(Opaque World Radiance Cache) 在调度上进行重叠 (Overlap)。
- 其计算任务(Dispatches)被精心安排,以 填补主缓存计算过程中的“空隙”。
- 通过这种方式,这部分新增的计算开销 几乎可以忽略不计 (Almost Free)。
Part 5: Reflections
Lumen 的反射实现基于 随机积分 (Stochastic Integration),并结合了一套强大的 屏幕空间降噪管线 (Screen Space Denoising Pipeline) 来处理随机采样带来的噪点。
- 该方法主要借鉴了 Tomasz Stachowiak 在相关演讲中提出的优秀思想。
- 通过多阶段的降噪处理,将充满噪点的原始光追结果逐步净化为稳定、高质量的反射图像。
反射渲染管线 (Reflection Rendering Pipeline)
以下是 Lumen 反射管线的完整步骤,通过一个逐步降噪的过程来生成最终效果:
-
光线生成 (Ray Generation):
- 关键技术: 基于可见的 GGX 波瓣(Visible GGX Lobe)进行重要性采样 (Importance Sampling)。
- 目的: 不再是均匀发射光线,而是根据材质的粗糙度和视角,优先向反射贡献最大的方向发射光线,从源头上提高采样效率。
-
光线追踪 (Ray Tracing):
- 使用 Lumen 内置的光线追踪管线,对生成的光线进行追踪并获取命中点的光照信息。此阶段的原始输出是带有大量噪点的。
-
空间复用 (Spatial Reuse Pass):
- 核心观点: 在屏幕空间分析当前像素的 相邻像素 (Neighbors)。
- 根据相邻像素的 BRDF (双向反射分布函数) 相似性、深度、法线等信息,对其追踪结果进行 重新加权 (Reweight) 并复用。
- 效果: 显著减少噪点,但图像中仍可能残留部分噪点。
-
时间累积 (Temporal Accumulation):
- 将当前帧的结果与历史帧的结果进行混合。
- 效果: 极大地抑制了随机采样产生的 “火花”或亮斑 (Fireflies),使反射效果在时间上趋于稳定。
-
双边滤波 (Bilateral Filter):
- 定位: 这是降噪管线的 最后一道防线 (Last Stitch Effort)。
- 目的: 当上述基于物理的复用方法(空间/时间)仍然不足以完全消除噪点时(尤其是在非常明亮的高光区域),双边滤波器会介入,对剩余的顽固噪点进行平滑处理。
-
最终合成 (Final Composition):
- 经过双边滤波后,图像会再经过一次 全帧的时间抗锯齿 (Temporal Anti-Aliasing, TAA),进一步净化和稳定最终画面。
高级反射渲染技术:降噪与性能优化
一、 最后的防线:双边滤波 (Bilateral Filter)
这是在所有基于物理的复用技术(如时域和空域复用)都处理完后,作为最后一道降噪工序的手段。

-
核心观点: 双边滤波是一个 目标明确的、有针对性的降噪器,用于处理其他方法无法解决的顽固噪点。
-
激活条件:
- 高方差区域: 在空间复用(Spatial Reuse)处理后,方差(variance)依然很高的区域。这通常意味着该区域的噪点非常明显。
- 新揭示区域 (Disocclusion): 由于物体移动或视角变化而新出现在屏幕上的区域。这些像素 没有任何历史(时域)数据 可以复用,因此噪点会特别严重。在这些区域,会施加双倍强度的双边滤波。
-
关键技术:色调映射加权 (Tone Mapped Weighting)
- 目的: 专门用于 消除萤火虫 (fireflies) ——那些异常明亮的噪点像素。
- 工作原理: 通过色调映射来计算滤波权重,可以有效压制高光区域的异常亮点。
- 重要权衡: 这种方法不能在之前的空间复用阶段使用,因为它会过度压缩高光部分的细节("crush our highlights")。但作为最后的清理步骤,它在不破坏整体画质的前提下能完美地去除萤火虫。
二、 粗糙/光泽反射的性能优化
处理反射时的一大性能瓶颈是追踪 非相干光线 (incoherent rays) 的缓慢过程。
-
核心观点: 材质越粗糙,其反射波瓣(Lobe)越宽,反射光线的方向越发散(非相干),追踪成本越高。我们可以根据不同的粗糙度范围,采用分级的优化策略来复用已有数据,从而避免昂贵的光线追踪。
-
问题根源:
- 当材质的 粗糙度 (roughness) 接近 1 时,其 GGX 微表面分布 函数产生的反射波瓣会非常宽,接近于漫反射(diffuse)。
- 这导致光线方向极为发散,访问的内存和纹理不连续,极大地破坏了GPU的执行效率。
- 这类高粗糙度的反射往往覆盖屏幕的大部分区域,因此是主要的性能优化目标。
1. 针对最粗糙反射 (Roughest Reflections) 的优化
-
核心策略: 完全复用为漫反射GI计算好的数据,彻底跳过该区域的光线追踪。
-
具体实现:
- 数据来源: 使用 屏幕空间辐射缓存 (Screen Space Radiance Cache)。这个为漫反射GI构建的缓存,其方向分辨率对于宽广的高光波瓣来说已经足够。
- 采样过程:
- 首先,根据材质的 GGX 波瓣进行重要性采样 (Importance Sampling),得到一个符合其物理分布的反射方向。
- 然后,使用这个方向去查询和插值 屏幕探针 (screen probes) 中的辐射度数据。
- 性能收益: 在大多数场景中,这种方法能将反射的计算成本 降低 50% 到 70%。
2. 针对中等光泽反射 (Glossy Reflections) 的优化
-
核心策略: 采用混合方案。不完全替代光线追踪,而是将其作为光线追踪未命中时的低成本回退(fallback)方案。
-
面临的挑战: 对于中等光泽的反射,其反射波瓣比最粗糙的反射要窄,需要更高的方向分辨率。此时,屏幕空间辐射缓存的方向精度不足。
-
具体实现:
- 数据来源: 使用 世界空间辐射缓存 (World Space Radiance Cache),它提供了比屏幕空间缓存更高的方向分辨率。
- 混合追踪与插值:
- 发射一根 缩短了长度的反射光线 (shorten the reflection ray)。
- 如果光线未命中 (on miss):即在缩短的距离内没有碰到任何物体,则从世界空间辐射缓存中插值获取反射颜色。
- 如果光线命中: 则正常计算命中点的着色。
高级反射优化技术:性能与管线设计
本次讲座内容聚焦于两种关键的反射优化策略:通过缩短光线和缓存复用来降低追踪成本,以及设计高效的 基于Tile的反射管线 并解决其实现中的潜在问题。
缩短反射光线与缓存复用
这是一种旨在从根本上降低光线追踪成本和复杂度的核心优化技术。
传统的反射需要追踪长距离光线,这会导致光线方向发散(Directional Divergence),增加追踪的非相干性,从而需要 光线分箱(Ray Binning)和排序 等昂贵的预处理步骤。通过缩短反射光线,可以有效解决此问题。
具体实现:
- 缩短光线追踪距离: 我们不再追踪完整的反射光线,而是追踪一个较短的版本。
- 缓存查询(On Miss):
- 如果缩短后的光线命中了场景中的物体,则直接使用该命中结果。
- 如果未命中(Miss),则从一个名为 世界空间范围缓存(World Space Range Cache) 的数据结构中进行插值,获取一个近似的反射结果。
- 主要优势:
- 减少方向发散: 由于光线路径变短,来自相邻像素的反射光线方向会更加接近,提高了光线的相干性。
- 消除光线分箱/排序: 因为光线已经根据其起点(屏幕像素)自然有序,并且方向发散度大大降低,所以不再需要昂贵的光线分箱和排序步骤。
- 显著性能提升: 在《黑客帝国觉醒》Demo中,此技术将 路面反射的成本降低了16%。
对清漆层(Clear Coat)的优化
这种缓存复用策略对于渲染类似车漆的多层材质(如带有清漆层的光泽涂料)尤其高效。
- 底层(光泽涂料层): 可以直接复用已有的 屏幕空间辐射缓存(Screen Space Radiance Cache),该缓存可能已为GI等其他效果计算好。
- 顶层(清漆层): 仅需为顶部的透明清漆层追踪新的光线。
这种分层处理方式,极大地降低了渲染复杂PBR材质的反射成本。
基于Tile的反射管线与实现陷阱
将整个反射渲染流程构建在基于屏幕分块(Tile)的管线之上,是实现极致性能的关键。
基于Tile的管线(Tile-Based Pipeline) 允许GPU仅在屏幕上需要计算反射的区域执行工作,从而高效地跳过(Skip)无需处理的区域。
管线优势
- 高效跳过无效区域:
- 可以轻松跳过只包含天空的Tile。
- 对于那些可以完全复用漫反射光线(例如Diffuse GI结果)来近似反射的区域,也可以直接跳过,无需再次追踪。
- 灵活处理多次执行(Dispatch):
- 反射管线在单帧内可能会根据场景内容运行多次,例如分别为不透明物体、半透明物体和水面计算反射。
- 基于Tile的架构使得每一次执行(Dispatch)都能精确地只作用于对应的屏幕区域,避免了全屏处理的巨大浪费。
- 这对于包含大量Dispatch的复杂追踪管线至关重要。
实现的陷阱与解决方案(The "Gotcha")
在实现Tile-based管线时,去噪环节会遇到一个典型的问题。
-
问题描述:
- 去噪过程(尤其是 时间滤波 Temporal Filter)中的 邻域钳制(Neighborhood Clamp) 步骤,需要读取邻近像素的数据。
- 在一个Tile-based系统中,某个Tile的邻居Tile可能因为被跳过(例如是天空)而没有被处理,导致读取到无效或陈旧的数据。

-
解决方案演进:
- 方案A (清除未使用区域): 在去噪前运行一个Pass,清除所有未使用区域的纹理数据。这很直接,但可能引入额外的Pass开销。
- 方案B (着色器内分支): 在时间滤波器的Shader中使用
if语句进行判断,检查邻域数据是否有效。这会引入分支,可能影响GPU性能。 - 最终优化方案 (巧妙的边界清除):
- 让 时间滤波器之前的一个Pass 来负责清除边界。
- 这个Pass只清除 未使用Tile中的像素(Texels) 。
- 避免竞争条件(Race Condition): 只能清除未使用的图块中的纹理元素,以避免与空间重用通道的其他线程的竞争条件。
处理半透明材质的反射
Lumen 为半透明材质的反射提供了一套混合解决方案,以同时满足镜面反射(如玻璃)和多层模糊反射(如毛玻璃、有色液体)的渲染需求。
核心挑战
- 多层半透明 (Arbitrary Number of Layers): 渲染需要支持任意层数的半透明叠加,这使得直接在像素着色器中进行追踪变得不可行,需要一种更高效的外部解法。
- 镜面反射 (Mirror Reflections): 像玻璃这样的材质需要清晰、无模糊的镜面反射,这种效果无法通过探针插值等近似方法实现。
混合解决方案
Lumen 将半透明反射分为两个截然不同的路径来处理:
-
路径一:针对玻璃等镜面反射
- 核心策略: 将最前方的半透明层单独剥离出来,对其进行高质量的反射计算。
- 关键技术:
- 深度剥离 (Depth Peeling): 使用该技术精确提取出最靠前的半透明表面。
- 最小化G-Buffer (Minimal G-buffer): 为这个被剥离出的表面创建一个精简版的 G-Buffer。
- 复用反射管线 (Reuse Reflection Pipeline): 针对这个 G-Buffer 中的有效像素,重新运行一遍完整的反射管线。
- 性能优化: 在这次反射管线运行中, 禁用降噪器 (Denoiser disabled),因为镜面反射通常噪声较少,禁用降噪可以显著降低管线开销。
-
路径二:针对其余半透明层(模糊反射)
- 核心策略: 对于除镜面层之外的所有半透明层,使用一种基于探针插值的、更高效的近似方法。
- 关键技术:
- 复用世界空间辐射缓存 (World Space Radiance Cache): 直接复用用于不透明物体最终着色的辐射缓存系统。
- 动态探针放置:
- 通过 低分辨率光栅化 (low-resolution rasterization) 的方式标记出半透明表面所在的区域。
- 在这些标记区域 放置额外的探针 (place more probes),以确保半透明区域有足够的光照信息。
- 最终着色: 在渲染这些半透明层时,其像素着色器会 从辐射缓存中进行插值 (interpolates from the radiance cache),以获取最终的模糊反射(Glossy Reflections)效果。
Part 6: Performance and Scalability
Lumen 提供了不同级别的质量设置,以在不同性能目标下实现伸缩性。
性能测试基准
- 内部渲染分辨率: 1080p
- 输出分辨率: 通过 时间超分辨率 (Temporal Super Resolution, TSR) 技术,将 1080p 的内部渲染结果上采样至 4K 输出。
- 核心理念: 实践证明, “低分辨率高质量渲染 + TSR上采样” 的方案,其最终图像质量远优于 “原生4K分辨率 + 低质量渲染设置” 的方案。
质量等级划分
-
高设置 (High Settings)
- 性能目标: 60 FPS
- 核心技术:
- 光线追踪完全依赖于 全局距离场 (Global Distance Field)。
- 不使用网格SDF追踪 (No Mesh SDF Tracing),这是为了保证最高性能而采用的最快速追踪方法。
- 1/16 ray per pixel (rpp) for Final Gather
- 1/4 rpp for Reflections
-
史诗设置 (Epic Settings)
- 性能目标: 30 FPS
- 核心技术:
- 每个像素的光线数量 (Rays Per Pixel) 是“高设置”的四倍,从而获得更高的渲染质量和精度。
- 1/4 rpp for Final Gather
- 1 rpp for Reflections
Lumen 性能分析与未来展望
本节内容主要分为两部分:首先,通过几个不同复杂度和设置的实际场景,深入分析 Lumen 的性能开销;其次,探讨 Lumen 未来的发展方向和计划改进的功能。
性能基准测试 (Performance Benchmarks)
Lumen 的性能开销与场景复杂度、材质类型、追踪方式(软件/硬件)以及质量设置(高/史诗)密切相关。
Nanite 场景 (Land of Nanite Demo)
这个场景的特点是没有光滑材质,因此反射部分的计算开销极小。
- 追踪方式: 远场追踪 (Far-field tracing),这是当前最快的光线追踪方法。
- 高 (High) 设置:
- 总开销: 2.8 ms
- 评价: 能够轻松满足 60 FPS 的性能预算。
- 史诗 (Epic) 设置:
- 关键变化: 每像素光线数 (rays per pixel) 提升了 4倍。
- 总开销: 4.6 ms
- 画质提升: 带来了更精确、更稳定的 间接阴影 (indirect shadows)。
Lyra 示例游戏 (Lyra U5 Sample Game)
这个场景虽然视觉上简洁,但其干净的漫反射纹理和光滑材质对实时GI和反射的计算构成了相当大的挑战。
- 追踪方式: 软件光线追踪 (Software Ray Tracing)。
- 高 (High) 设置:
- 总开销: 4.3 ms
- 史诗 (Epic) 设置:
- 画质提升: 开启了 全分辨率反射 (full-resolution reflections),反射效果更加清晰锐利。
《黑客帝国:觉醒》 (The Matrix Awakens)
这是一个复杂度极高的场景,追踪开销也相应大幅增加。
- 追踪方式: 硬件光线追踪 (Hardware Ray Tracing) 结合 远场追踪 (Far-field)。
- 高 (High) 设置:
- 总开销: 6.4 ms
- 史诗 (Epic) 设置:
- 总开销: 11.3 ms
- 评价: 性能开销显著增加,但带来了巨大的画质提升。
建筑可视化场景 (Architectural Visualization Scene)
在 NVIDIA 2080 Ti 显卡上运行的测试。
- 史诗 (Epic) 设置:
- 总开销: 7.3 ms
- 视觉表现: 在屏幕局部放大时,仍然能观察到一些噪点。
- 质量优化技巧:
- 可以将 最终收集 (Final Gather) 的光线密度提升至 每像素1条光线 (one ray per pixel)。
- 效果: 能够获得极为平滑的间接光照,但性能开销会进一步增加。
未来工作 (Future Work)
为了进一步提升 Lumen 的质量和适用性,团队规划了以下几个重要的改进方向:
-
自发光网格采样 (Explicit Sampling of Emissive Meshes)
- 目标: 在降采样的 辐射缓存 (downsampled radiance cache) 中,实现对 自发光网格 (emissive meshes) 的显式、稳定采样,以提高间接光照的准确性。
-
表面缓存改进 (Surface Cache Improvements)
- 覆盖率: 持续提升 表面缓存 (Surface Cache) 的 覆盖率 (coverage),使其能应用于更多类型的场景和几何体。
- 皮肤网格支持: 增加对 皮肤网格 (skin meshes) 的支持,这是当前表面缓存的一个重要短板。
-
无表面缓存模式 (No Surface Cache Mode)
- 设想: 提供一种完全不依赖 表面缓存 的渲染模式。
- 特点: 这种模式的计算开销会非常昂贵,因此只适用于追求极致画质的高端硬件。
-
持续优化:团队始终致力于在 60fps 的严格预算下提升渲染技术质量,其中 植被渲染质量 (Foliage Quality) 仍然是一个持续努力优化的方向。