GPU Crash Debugging in Unreal Engine
GPU Crash Debugging in Unreal Engine: Tools, Techniques, and Best Practices | Unreal Fest 2023
GPU 崩溃调试导论
1. GPU 崩溃的挑战
与 CPU 崩溃相比,GPU 崩溃的调试过程通常更加困难和不透明(opaque),主要原因如下:
- 信息匮乏:通常只能获得很少的有效信息来定位问题。
- 需要专业知识:调试过程依赖于深厚的底层知识和经验,更像一门“艺术”。
2. CPU 崩溃 vs. GPU 崩溃
理解两者的差异是掌握 GPU 调试的关键。

-
CPU 崩溃
- 即时性:崩溃发生时,程序会立即中断。
- 状态可查:所有线程都会被挂起,允许开发者在崩溃的确切时刻检查程序的完整状态(如调用堆栈、内存)。

-
GPU 崩溃
- 核心问题:延迟报告
- GPU 上运行着海量的并行线程。当一个线程发生故障(fault)时,GPU 不会立即停止。
- 从 GPU 实际发生故障到操作系统报告崩溃之间,存在一个显著的时间延迟,这个延迟可能超过 2 秒。
- 延迟带来的后果
- GPU 状态不准确:由于 GPU 在故障后仍在继续执行其他任务,当我们收到崩溃报告时,GPU 的活跃任务列表可能已经发生了变化。
- 难以定位故障源:崩溃报告中显示的“活跃任务”可能并非真正导致崩溃的元凶。有些任务可能在故障后才开始执行,而真正出错的任务可能已经执行完毕。因此,仅凭报告很难确定哪个具体的 Job 引发了问题。
- 核心问题:延迟报告
3. Windows TDR (超时检测与恢复)
- 定义:TDR 是 Timeout Detection and Recovery 的缩写,是 Windows 操作系统用于处理 GPU 无响应的一种核心机制。
- 目的:当 GPU 挂起 (hung) 且长时间没有响应时,TDR 会介入以防止整个操作系统被冻结。
- 机制:
- 检测 (Detection):系统检测到 GPU 未能在指定时间内完成操作。
- 恢复 (Recovery):为了恢复系统,TDR 会尝试重置 (reset) GPU 驱动和硬件状态。
- 结果:这个重置过程通常会导致正在使用 GPU 的应用程序进程崩溃。

GPU 崩溃:超时与页错误
一、超时检测与恢复 (TDR - Timeout Detection and Recovery)
TDR (Timeout Detection and Recovery) 是一种操作系统(特别是 Windows)的机制,用于防止 GPU 因执行耗时过长的任务而导致整个系统冻结。
- 核心机制: 操作系统会监控 GPU 任务的执行时间。如果一个任务在预设的时间内(通常是几秒钟)没有完成,系统会认为 GPU 已挂起。
- 后果: 为了恢复系统的响应,操作系统会重置 GPU 驱动程序,并终止导致超时的应用程序。这对于用户来说表现为程序崩溃。
- 设计目的: 保证系统在 GPU 无响应时仍能正常运行,避免需要硬重启。对于渲染来说,任何提交给 GPU 的工作都应该是小批量且能快速完成的。
TDR 的主要原因
-
无限循环 (Infinite Loops)
- 描述: 着色器(Shader)代码中存在永远不会终止的循环,导致 GPU 核心被永久占用。
-
同步错误 (Incorrect Synchronization)
- 描述: GPU 被指令等待一个永远不会到来的信号(例如,一个
Fence被等待,但从未被Signal),导致 GPU 无限期等待。
- 描述: GPU 被指令等待一个永远不会到来的信号(例如,一个
-
耗时过长的着色器 (Very Slow Shaders)
- 描述: 某些计算量极大的着色器,如复杂的光线步进 (Raymarching) 或光线追踪 (Raytracing),即使它们最终能完成,但其执行时间也可能超过 TDR 阈值。
-
物理内存耗尽 (Out of Physical Memory)
- 描述: 当 GPU 显存或系统内存不足时,操作系统会开始进行内存交换(Swapping),将数据在内存和磁盘间来回移动。这个过程非常缓慢,会导致 GPU 操作超时。
-
驱动程序 Bug (Driver Bugs)
- 描述: 图形驱动程序自身的缺陷也可能导致 GPU 挂起并触发 TDR。
案例分析
-
案例 1: 《巫师3》次世代版同步 Bug
- 问题: 一个
Fence对象缺少了Signal操作,导致 GPU 永久等待。 - 特殊之处: 在这个案例中,TDR 机制并未被触发,导致程序完全冻结(infinite freeze),而不是崩溃。这表明 TDR 并非总是可靠的,有时需要使用自定义的 GPU 调试指令来排查问题。
- 问题: 一个
-
案例 2: 过场动画离线渲染超时
- 场景: 在 Sequencer 中渲染具有极高质量和无限视距的单帧画面,耗时可能长达数秒。
- 问题: 这种长时间的渲染任务自然会触发 TDR。
- 解决方案: 增加 TDR 延迟。
- 重要警告: 这种方法仅适用于离线渲染 (offline rendering) 场景。在实时应用(如游戏)中绝对不应这样做,因为它会掩盖潜在的性能问题或死循环 bug,使得调试更加困难。
二、页错误 (Page Faults)
随着 DirectX 12 等现代图形 API 的普及,开发者获得了对内存进行更精细管理的权限,但这也引入了新的崩溃风险。
- 核心概念: GPU 上的页错误是指 无效内存访问 (invalid memory access),其性质类似于 CPU 上的“访问冲突 (access violation)”或“空指针异常 (null pointer exception)”。
- 根本原因: 访问了一个已经被“移出” (evicted)或不再有效的资源内存地址。在现代 API 中,内存资源可以在显存和系统内存之间动态移动。如果程序试图访问一个已经被系统从显存中移出的资源,GPU 将无法找到对应数据,从而导致崩溃。
GPU 页面错误 (Page Faults) 与崩溃调试 (Crash Debugging)
1. GPU 页面错误 (Page Faults)
- 核心概念:随着现代图形 API(如 DirectX 12)引入更精确的内存管理能力,也带来了新的风险,即无效内存访问 (Invalid Memory Access)。
- 根本原因:当 GPU 尝试访问一个已经被移出 (Evicted) 显存的资源地址时,就会发生页面错误,从而导致 GPU 崩溃。
- 调试难点:从错误发生到最终报告崩溃,中间可能存在巨大的延迟,这使得定位问题的根源变得非常困难。
- 案例分析 (PS5):
- 现象:一次 GPU 崩溃被最终定位到一个使用了复杂材质的特定马克杯上。
- 线索:该材质采样了多个虚拟纹理 (Virtual Textures),并且问题出现在引擎版本升级之后。
- 结论:根本原因是引擎的虚拟纹理系统存在一个 Bug,导致了非法的内存访问。
2. GPU 崩溃调试策略
由于 GPU 崩溃的调试流程不像 CPU 那样有完善的文档和工具链,通常需要从基本排查入手。
初始健全性检查 (Sanity Checks)
在深入调试之前,首先应排除一些常见的外部因素:
- 更新驱动程序:过时或有问题的显卡驱动是常见的崩溃原因。
- 检查硬件能力:
- 确保 GPU 性能足够强大,并且拥有充足的显存 (VRAM)。
- 像光线追踪 (Ray Tracing) 这样的新功能对硬件要求很高。
- 注意,编辑器模式 (In-Editor) 下的资源消耗通常比运行时更重。
- 检查项目设置:
- 审视质量设置 (Quality Settings),避免一次性将整个世界或过多资源加载到内存中。
- 检查后台进程:
- 确认没有其他重量级后台程序(如离线渲染)在抢占 GPU 资源。
Unreal Engine 调试环境设置
UE 提供了一些内置工具来帮助定位 GPU 崩溃。
一、 命令行参数与控制台变量 (CVars)
-
GPU 崩溃调试标志 (GPU Crash Debugging Flag)
- 作用:这是一个总开关,启用后会开启所有可用的 GPU 验证和追踪工具,为调试提供额外信息。
- 代价:会带来显著的性能开销 (Performance Overhead),因此不建议在日常开发中默认开启。
Command Line argument: -gpucrashdebugging
-
d3ddebug 命令行参数
- 作用:这是一个 DirectX 特有的调试参数,用于在 API 层面验证渲染命令。
- 目标:主要用于捕捉格式错误的 D3D 命令 (Malformed D3D Commands),这些命令是导致崩溃的直接原因之一。
Command Line argument: -d3ddebug
-
d3ddebug- 核心功能:一个命令行参数,用于在 CPU 端验证 D3D 命令的格式是否正确。
- 优点:一种简单、快速的错误捕获方式。
- 局限性:由于验证完全在 CPU 上进行,无法获取完整的 GPU 信息,因此不能检测出所有类型的 GPU 错误(例如,由 Shader 逻辑或 GPU 状态引发的错误)。
-
GPU-Based Validation (GBV)
- 核心功能:通过启用一个特定的标志,它会向着色器中注入 (Instrument) 额外的检查代码,从而在 GPU 上直接进行验证。
- 能捕获的错误:可以捕获 CPU 端验证无法检测到的问题,这些问题通常是导致页面错误 (Page Faults) 的元凶。
- 不正确的描述符 (Descriptors)。
- 引用已被删除的资源。
- 描述符堆 (Descriptor Heap) 的越界索引。
Command Line argument: -gpuvalidation
-
启用额外绘制事件 (Material and Mesh Draw Events)
- 目的:精确定位导致 GPU 崩溃的具体材质或网格。
- 工作原理:为每个绘制调用 (Draw Call) 附加详细的材质和网格信息。
- 应用场景:不仅用于崩溃调试,相关信息也会显示在 GPU Profiler 中,非常适合对单个材质或网格进行性能分析。
- 代价:会带来非常大的性能开销,不应在最终发布版本中开启。
Enable extra events r.ShowMaterialDrawEvents 1 r.EmitMeshDrawEvents 1 r.Nanite.ShowMeshDrawEvents 1
-
追踪更多内存分配
- 目的:在发生页面错误时,追踪 GPU 上所有已分配的资源,而不仅仅是错误地址附近的资源。
- 使用场景:当崩溃报告中显示的“活跃资源”信息不足以定位问题时,可以启用此 CVar 以获取更全面的内存分配快照。
- 注意:核心的 GPU 崩溃调试标志已默认启用此功能,通常无需单独设置。
D3D12.TrackAllAllocations 1 or -gpucrashdebugging-
活跃资源 (Active Resources) 报告
- 机制:当发生页面错误时,引擎会报告错误地址周围一定范围(例如 16MB)内的所有活跃资源。
- 作用:这种上下文信息对于诊断资源越界访问 (Out-of-Bounds Access) 问题非常有帮助。
-
已释放资源 (Freed Resources) 报告
- 机制:引擎会追踪最近 100 帧内被释放的所有资源。
- 作用:如果页面错误地址与某个最近被释放的资源直接重叠,引擎会报告该资源。这对于捕获“使用已释放内存 (Use-After-Free)”类型的错误至关重要。
GPU 崩溃调试工具
- CPU 调用栈的局限性
- 对于 GPU 崩溃,事故发生时 CPU 的调用栈几乎没有参考价值。
- 这是因为导致崩溃的 GPU 命令是在很久之前就被 CPU 提交到命令队列中的。
- 调试的关键在于获取崩溃发生瞬间的 GPU 状态,而非 CPU 状态。
平台差异与选择
- 平台特定性: 不同平台(PC、主机)的 GPU 崩溃调试工具差异很大。
- 主机 (Console):
- 提供与平台高度绑定的专用工具。
- 崩溃时生成详细的 转储文件 (dump),可用于深入检查 GPU 状态。
- 推荐: 讲者建议,如果条件允许,优先在主机上进行调试,因为其环境固定,工具集成度高,能提供非常详尽的崩溃信息。
- Vendor specific tools
- You get a GPU crash dump
- PC:
- 工具选择范围更广,但硬件和驱动环境更复杂。
- DRED
- Breadcrumbs
- NVidia Aftermath
- Radeon GPU Detective
- 工具选择范围更广,但硬件和驱动环境更复杂。
PC 平台工具详解
1. DRED (Device Removed Extended Data)
-
DRED (Device Removed Extended Data):一种专门用于 PC 平台的工具。
-
核心功能:当发生“设备移除 (Device Removed)”这类常见的 GPU 崩溃时,DRED 能够提供大量额外的、详细的诊断数据,帮助开发者理解崩溃的根本原因。
-
核心概念: 由 Windows 系统处理的一种机制,用于在设备被移除(即 GPU 崩溃)时提供额外信息。
-
工作原理:
- 自动标记: 在每次渲染操作后自动插入标记,用户控制权较少。
- 命令列表追踪: 崩溃时,DRED 会报告已完成的 GPU 操作序列,帮助定位到可能出问题的命令列表。
- 注意: DRED 报告的最后一个完成的操作不一定是导致崩溃的真正原因。
-
特性:
- 兼容性: 支持所有兼容 DirectX 12 的硬件。
- 易用性: 集成简单,Unreal Engine 已支持。
- 轻量级 DRED (Lightweight DRED): Unreal 新增的支持选项
r.D3D12.LightweightDRED,追踪的操作更少,性能开销更低,更适合在默认情况下启用。
-
页面错误 (Page Fault) 数据:
- 这是 DRED 的一个关键功能,对于调试悬空指针或资源管理错误非常有价值。
- 报告发生页面错误的虚拟地址 (virtual address)。
- 追踪并列出在该地址范围附近最近被使用和释放的资源。
2. Radeon GPU Detective (RGD)
- 核心概念: AMD 提供的专用 GPU 调试工具,通常比 DRED/Breadcrumbs 更为精确。
- 硬件要求: 仅支持较新的 AMD 显卡(RX 6000 和 7000 系列)。
- 工作原理:
- 更严格的检测: 指示驱动程序在检测到问题时更早地崩溃,并附带更多上下文信息。
- 需要驱动开启特殊模式: 必须在驱动层面启用 Crash Analysis Mode(崩溃分析模式)才能运行。
- 特性:
- 提供比 DRED 更准确的崩溃定位。
- 同样具备在发生页面错误时的资源追踪能力。
3. NVIDIA Aftermath
- 核心概念: NVIDIA 提供的与 RGD 对等的专用 GPU 调试工具。
- 集成: Unreal Engine 已集成该工具。
- 工作原理:
- 发生 TDR (超时检测和恢复) 时,Aftermath 会生成一个转储文件 (dump)。
- 该文件包含了非常详细的 GPU 状态信息,可供事后分析。
- 核心功能:在发生 TDR (Timeout Detection and Recovery) 时,生成一个 GPU 的状态转储文件 (dump),供事后分析。
- 信息深度:
- 相比 DRED 或旧版 Breadcrumbs,它提供了更丰富的 GPU 状态信息。
- 包含 寄存器值 和 活跃的线程束 (active warps),对于调试复杂的 GPU 崩溃非常有帮助。
- 共同点:与其他工具类似,它也追踪 GPU 的虚拟地址 (virtual addresses)。
- 关键区别:与 RGD 不同,NVIDIA Aftermath 可以随游戏最终版本一起发布,方便收集玩家端的崩溃数据。
4. Unreal Engine 的 Breadcrumbs
-
核心概念: 一种功能上与 DRED 非常相似的机制,但它是由用户(开发者)自己实现的,而不是由操作系统提供。
-
基本概念:一种由用户(开发者)手动实现的 GPU 崩溃追踪系统,功能上等同于 DRED、RGD 和 Aftermath。
-
实现方式:需要开发者手动决定在何时、何处写入标记 (marker),以及在标记中存储哪些信息。
-
与 DRED 对比:DRED 的底层工作方式类似,但给用户的控制权较少。
原始 (旧版) Breadcrumbs 的局限性
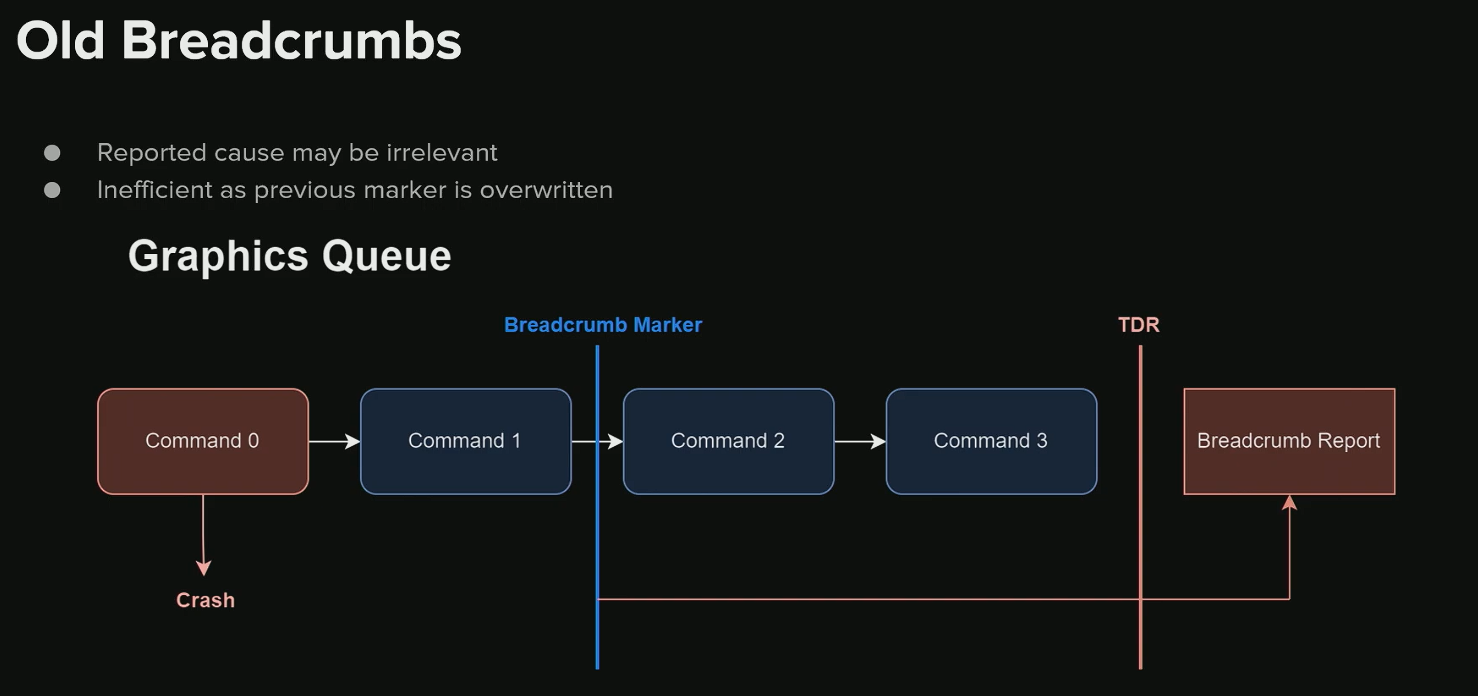
- 核心缺陷:仅报告最后一个开始或完成的标记。这不仅信息量少,有时还会产生误导。
- 误导性示例 (Red Herring):
- 假设
Command 0引发了 GPU 崩溃。 - 在系统检测到 TDR 之前,GPU 继续执行了
Command 1并留下了它的标记。 - 当 TDR 发生并生成报告时,Breadcrumbs 系统只会显示最后一个标记,即
Command 1。 - 这会导致开发者错误地认为
Command 1是崩溃的元凶,而真正的罪魁祸首Command 0则被忽略。
- 假设
新版 Breadcrumbs
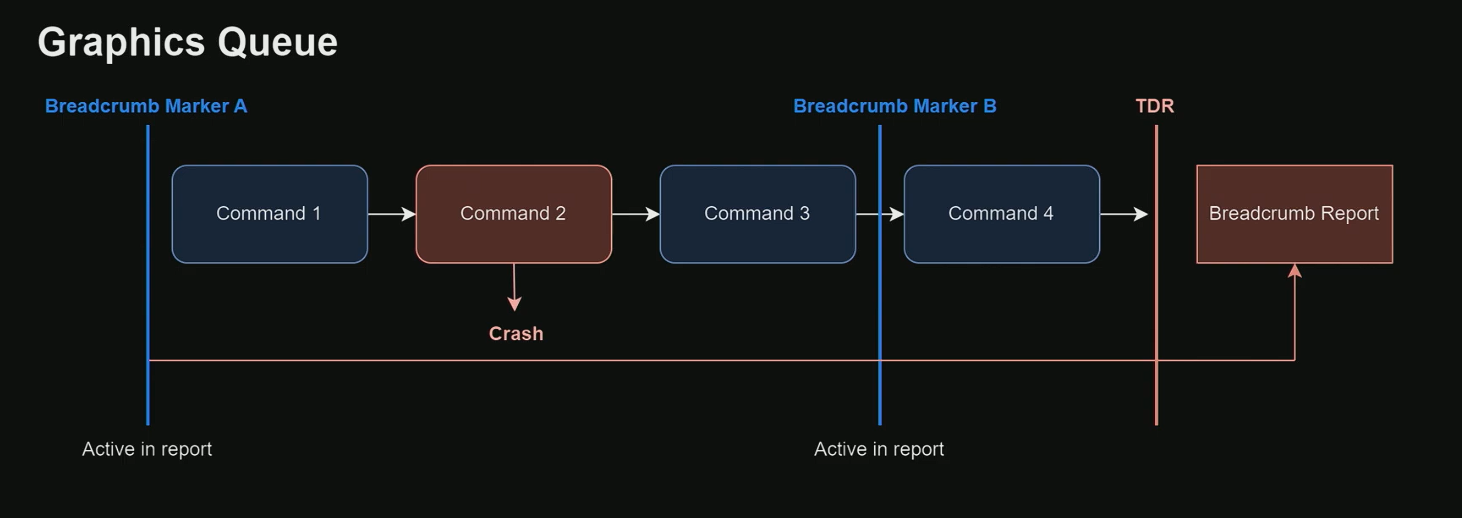
- 来源:从 CD Projekt Red 的 REDengine 移植到 Unreal Engine,并已在 GitHub 上提供。
- 核心改进:
- 使用一个更大的 GPU 缓冲区来追踪所有活跃的作用域 (scopes),而不仅仅是最后一个。
- 当 TDR 发生时,系统会返回所有活跃 Breadcrumbs 及其相关状态的完整列表。
- 报告内容:
- 提供一个清晰的层级结构,展示了 GPU 崩溃时每一个作用域 (scope) 的状态。
- 能够轻松识别出当时处于活跃状态的完整执行路径。例如,报告可能同时显示 Nanite 的硬件光栅化和软件光栅化路径都处于活跃状态,这提供了比旧版系统更全面的上下文。
- 扩展支持:不仅支持图形队列 (graphics queue),也支持计算队列 (compute queue)。
- 全面的故障定位:新的面包屑系统不仅能追踪图形管线中的问题,还能区分 Nanite 的硬件光栅化和软件光栅化路径,从而更精确地定位崩溃来源。
- 支持计算队列 (Compute Queue):除了图形队列,系统现在也监控计算队列。这意味着在 GPU 崩溃时,可以同时获取图形和计算任务的层级结构和标记,提供更完整的现场快照。
自定义面包屑 (GPU Breadcrumbs) 的实现
实现机制
- 核心思想:通过在 GPU 命令流中插入标记(Markers),来追踪 GPU 执行进度。崩溃发生时,通过读取这些标记的状态,可以确定 GPU 执行到了哪一步。
- 层级结构:标记系统采用与 GPU Profiler 相同的层级结构,使得调试信息直观且易于理解。
- 数据流:
- 应用程序通过 RHI (Rendering Hardware Interface) 的
RHIPushEvent来推送一个标记。 - RHI 将一个写入操作调度到 GPU 命令流中。
- GPU 执行到该处时,使用
WriteBufferImmediate命令,将标记的当前状态直接写入一个 CPU-GPU 共享的缓冲区。
- 应用程序通过 RHI (Rendering Hardware Interface) 的
面包屑缓冲区 (The Breadcrumb Buffer)
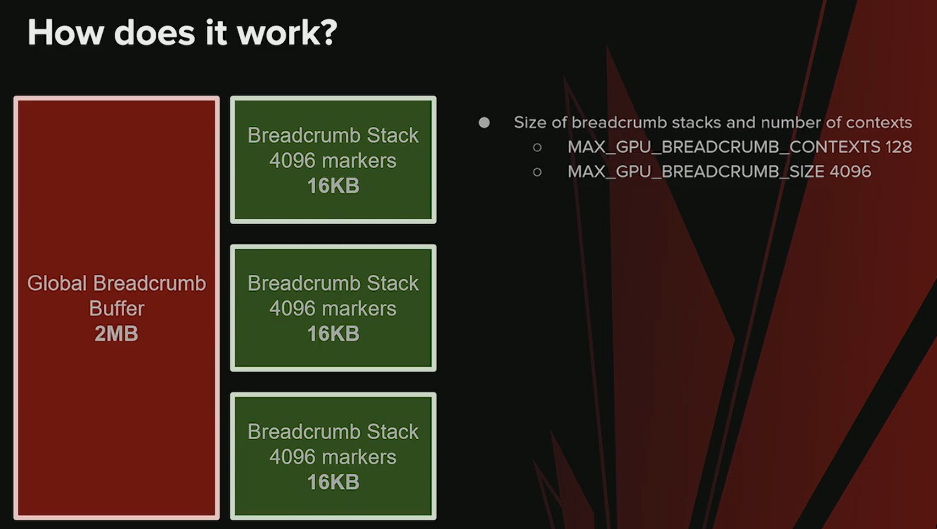
- 内存分配与属性:
- 预分配 (Pre-allocation):在应用程序启动时,会预先分配一个 2MB 大小的缓冲区。
- 共享与持久性:该缓冲区通过
open existing heap from address等方法创建,使其在 CPU 和 GPU 之间共享。最关键的是,即使在驱动程序崩溃后,这块内存依然可以从 CPU 端访问,这是实现事后调试 (Post-mortem Debugging) 的基础。
- 内部结构:
- 缓冲区作为池 (Pool):这个 2MB 的缓冲区被当作一个内存池,用于管理多个“栈”。
- 栈 (Stack):
- 每个栈代表一个完整的范围层级(hierarchy of scopes)。
- 单个栈最多可容纳 4,096 个标记。
- 可配置性:缓冲区总大小和单个栈的标记容量都可以通过修改 C++ 中的宏定义进行调整,以适应不同项目的负载需求。
写入标记 (WriteBufferImmediate)
- 写入命令:使用
WriteBufferImmediate命令将标记信息(地址、值、模式)写入共享缓冲区。 - 标记状态 (Marker States):一个标记可以处于以下几种状态之一:
Non-started (0):默认初始状态,表示任务尚未开始。Active:工作已在 GPU 上开始执行。Finished:在此标记之前的所有工作都已在 GPU 上执行完毕。Overflow:推入单个栈的标记数量超过了 4,096 的上限。Invalid:发生了其他未知错误。
- 写入模式 (Write Modes):
Marker In:当之前所有已调度的 GPU 工作已经开始执行时,写入标记状态。这通常用于标记一个任务范围的开始。Marker Out:当之前所有已调度的 GPU 工作已经完成时,写入标记状态。这通常用于标记一个任务范围的结束。
GPU Breadcrumbs: 追踪与调试
标记写入模式 (Marker Writing Modes)
GPU 提供了两种模式将调试标记(markers)写入缓冲区,这两种模式对于精确判断执行状态至关重要。
Marker In: 仅当所有在此之前调度的任务都已在 GPU 上开始执行时,才会写入标记。这用于确认一个工作范围的起点。Marker Out: 仅当所有在此之前调度的任务都已在 GPU 上执行完成时,才会写入标记。这用于确认一个工作范围的终点。
堆栈与标记的管理流程 (Stack and Marker Management Workflow)
系统通过一个堆栈(Stack)结构来管理作用域(Scope)和标记,其核心流程由 Command Context 负责。
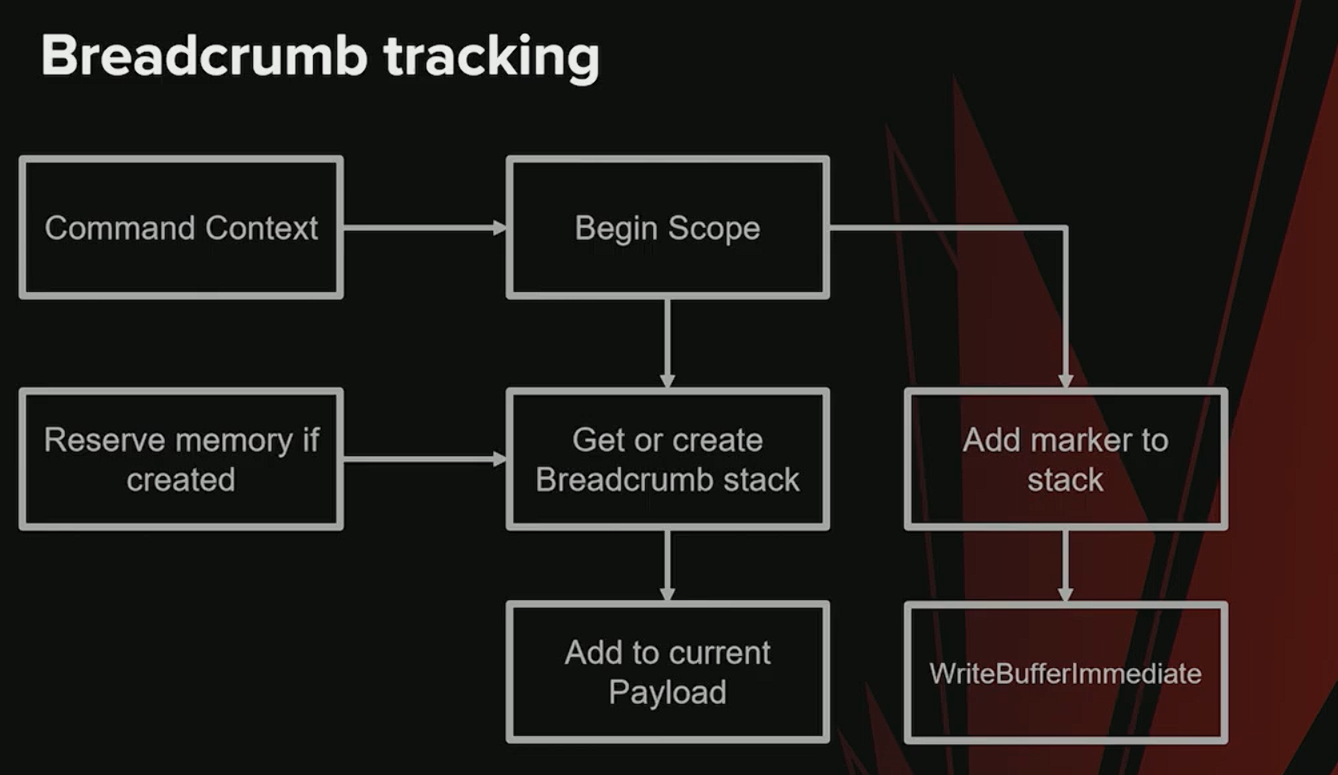
-
进入作用域 (
Begin Scope):- 获取 Breadcrumb Stack: 首先,系统会为当前的 GPU 工作负载(Payload)查找一个关联的 Breadcrumb Stack。
- 分配新堆栈: 如果当前 Payload 没有关联的堆栈,系统会从一个内存池(Pool)中申请一块新内存作为堆栈,并将其与该 Payload 关联。
- 添加标记: 将一个新的标记(marker)压入堆栈,并调度一个
WriteBufferImmediate命令,以Marker In模式将“已开始”(started)状态写入 GPU 缓冲区。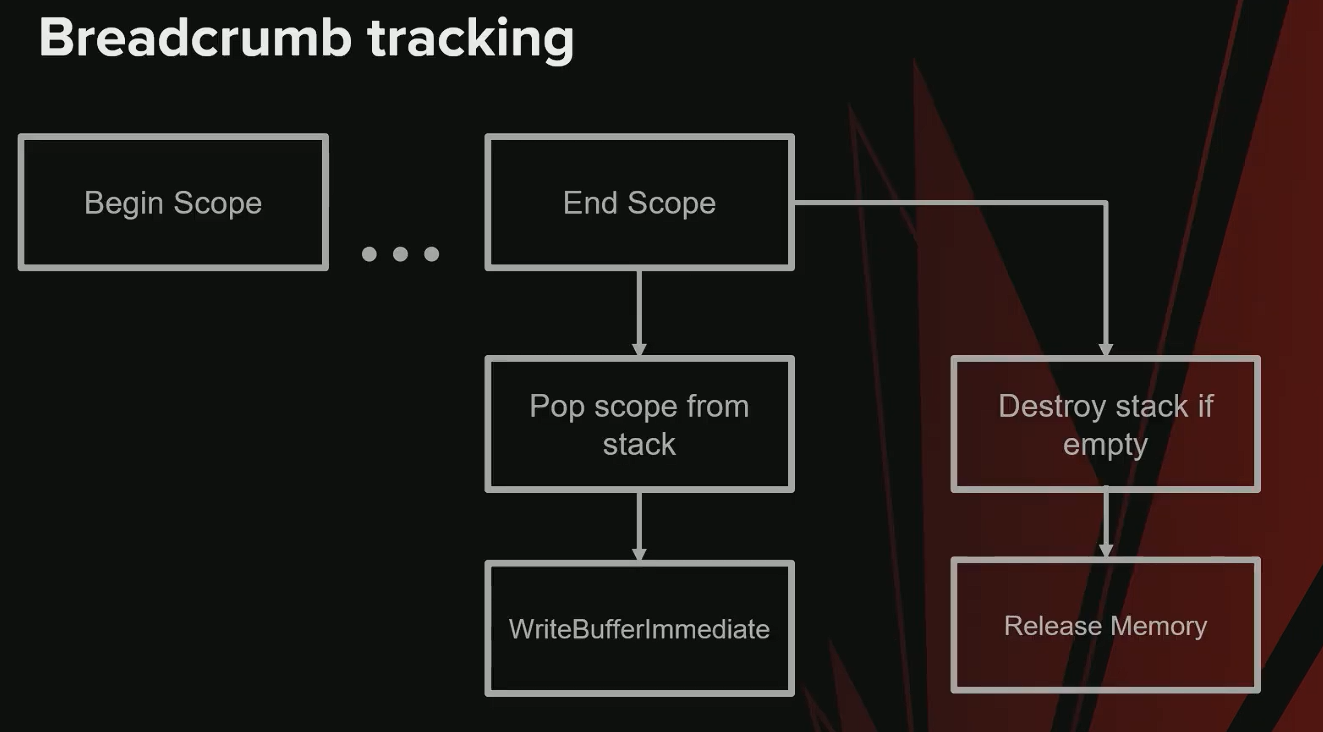
-
退出作用域 (
End Scope):- 写入完成标记: 调度另一个
WriteBufferImmediate命令,以Marker Out模式将“已完成”(finished)状态写入 GPU 缓冲区。 - 弹出作用域: 从堆栈中弹出当前作用域。
- 释放堆栈: 如果堆栈变为空,并且没有任何 Payload 引用它,则销毁该堆栈,将其内存归还给内存池以供后续重用。
- 写入完成标记: 调度另一个
GPU 崩溃后的数据分析 (Post-GPU Crash Analysis)
当 GPU 发生崩溃时,可以利用这些已写入的标记来定位问题。
- 检索 Payloads: 首先,获取 GPU 崩溃时所有活动的 Payloads。
- 收集堆栈: 收集与这些 Payloads 相关联的所有 Breadcrumb Stacks。
- 遍历标记: 遍历这些堆栈中的每一个标记。
- 读取状态: 从 CPU 仍然可以访问的 GPU 缓冲区中读取每个标记的状态(“started”或“finished”)。
- 输出日志: 将每个标记的作用域名称和状态打印到日志中。通过分析日志,可以精确地知道 GPU 在崩溃前执行到了哪个阶段,例如哪个 Pass 已经开始但尚未完成。
生命周期与实际挑战 (Lifecycle and Practical Challenges)
-
Payload 提交流程:
- UE 拥有一个专门的提交线程 (Submission Thread),负责跟踪所有提交到 GPU 的 Payloads。
- 当 GPU 完成一个 Payload 的所有工作后,提交线程会收到通知。
- 此时,系统可以安全地释放该 Payload 对其关联的 Breadcrumb Stacks 的所有引用。
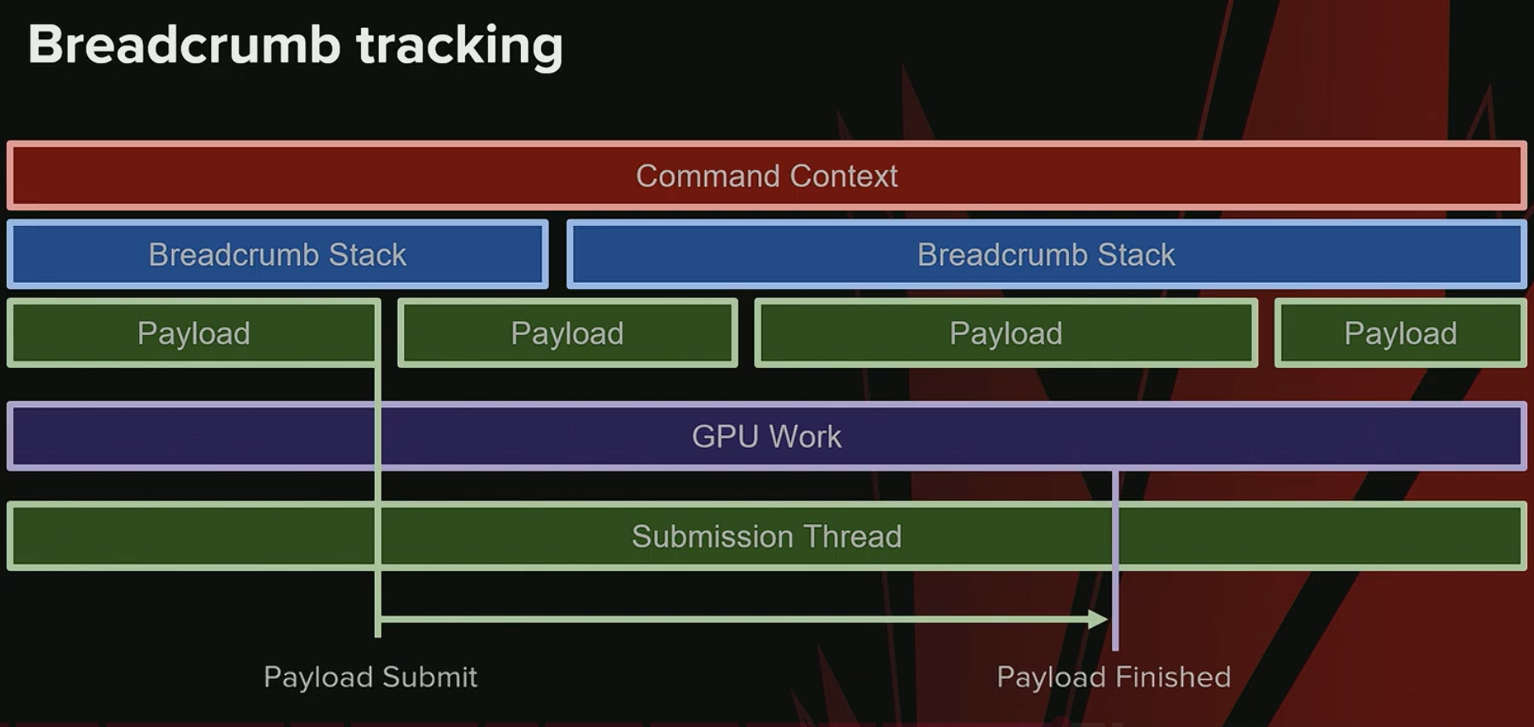
-
Payload 合并 (Merging):
- 在某些情况下,多个 Payloads 可能会被合并成一个。
- 当合并发生时,必须将所有源 Payloads 的 Breadcrumb Stack 引用合并到新的 Payload中,以确保追踪链的完整性。
-
潜在问题:
- 如果系统中产生大量的 Breadcrumb Stacks,可能会对性能或内存管理造成挑战。
Breadcrumbs 负载合并与内存优化
-
问题:内存效率低下
- 每个 Breadcrumbs 栈都会从内存池中分配一个固定的 16 KB 内存块。
- 在编辑器等特定工作负载下,一个栈可能仅包含一条命令(例如 4 字节),导致严重的内存浪费(使用 4 字节却分配 16 KB)。
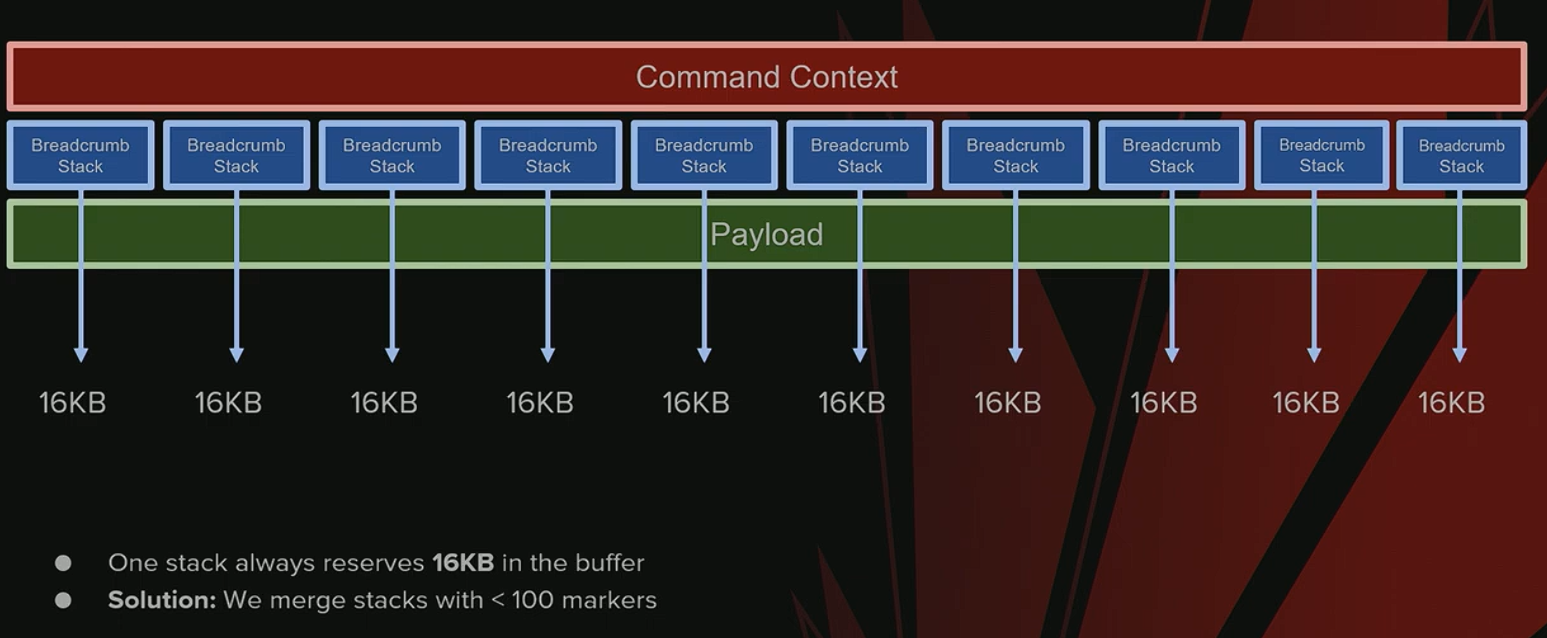
-
解决方案与权衡
- 合并策略:将标记数量少于 100 个的栈合并成一个,以提高内存利用率。
- 副作用:这种合并策略会导致这些栈的生命周期比实际需要的时间更长,是一种空间换时间的权衡。
Breadcrumbs 系统的局限性与开销
-
缓冲区大小问题
- 在编辑器中,命令列表可能变得异常庞大,有耗尽 Breadcrumbs 缓冲区的风险。
- 一旦缓冲区溢出,崩溃发生时的确切标记状态可能会丢失,影响问题定位。
- 调试建议:为了调试编辑器内的崩溃,可以手动增加缓冲区的大小。
-
性能开销
- 在 CPU 和 GPU 上添加
WriteBufferImmediate命令会带来不可忽视的性能开销。 - 当作用域(scopes)数量巨大时(例如,为每个网格和材质的绘制事件都添加标记),开销会非常显著。
- 以 DRED 为例:它默认对每个渲染操作都启用标记,因此性能成本很高。
- 在 CPU 和 GPU 上添加
-
发布游戏时的建议
- 如果计划在已发布的游戏中启用 Breadcrumbs 功能,强烈建议减少作用域的数量,以确保性能开销在可接受范围内。
-
与供应商工具的对比
- 供应商专用工具(如 NVIDIA Nsight, AMD RGP, PIX)通常更准确,因为它们能更直接地访问硬件底层信息。
- 对于复杂的崩溃问题,优先推荐使用供应商工具,而非 DRED 或 Breadcrumbs。
GPU 崩溃报告流程
-
核心定位方法
- 使用 Breadcrumbs 作为识别和定位 GPU 崩溃的主要技术手段。
-
早期的简陋系统
- 在项目初期,曾使用一个非常简单的系统,将所有 GPU 崩溃归类到同一个 Jira 工单中。
- 这种方式需要工程师手动检索日志文件来分析具体问题,效率低下。
-
旧系统的问题
- 工单是基于 CPU 调用栈创建的。然而,大多数 GPU 崩溃的 CPU 调用栈都非常相似(通常停在等待 GPU 的地方),因此这种分组方式几乎没有实际的诊断价值。
利用 Breadcrumbs 进行 GPU 崩溃分组
一、 新方法概述
为了更有效地对 GPU 崩溃进行分类和追踪,我们摒弃了基于 CPU调用栈(通常对于不同 GPU 崩溃都相同,因此用处不大)的旧方法,转而采用一种基于 GPU Breadcrumbs(GPU 命令标记)的新流程。
-
核心流程:
- 客户端:
- 当 GPU 崩溃发生时,捕获 Breadcrumbs 数据。
- 对 Breadcrumbs 进行过滤和分组,仅保留与崩溃最相关的信息。
- 将处理后的信息输出到日志并上传崩溃报告。
- 后端:
- 自动化脚本解析上传的日志文件。
- 再次过滤 Breadcrumbs,并对其内容进行哈希 (Hash) 计算。
- 根据生成的哈希值创建或更新一个唯一的工单(如 Jira Ticket)。
- 客户端:
-
哈希数据源:
- 目前,哈希的生成不依赖于页面错误(Page Fault)信息,因为系统暂时无法获取。
- 未来可以通过集成 DRED (Device Removed Extended Data)、NVIDIA Aftermath 或 Radeon GPU Detective (RGD) 等工具来补充这部分信息。
二、 分组策略与实现细节
我们的目标是将本质上相同的崩溃归类到同一个工单中,以便于工程师分析和确定修复的优先级。该系统已成功移植到 Unreal 引擎中。
- 后端处理步骤:
- 解析日志 (Parse Log): 读取客户端上传的崩溃日志。
- 过滤 Breadcrumbs (Filter Breadcrumbs):
- 这是最关键的一步,我们只保留两种信息:
- 最后一个已完成的作用域 (Last finished scope)
- 所有活跃的作用域 (Active scopes)
- 这样做可以极大地减少无关信息的干扰。
- 这是最关键的一步,我们只保留两种信息:
- 移除动态数据 (Remove Dynamic Data):
- 从过滤后的 Breadcrumbs 中剔除所有动态变化的数据,例如指针地址、实例ID、帧编号等。
- 这是确保相同根本原因的崩溃能生成相同哈希值的关键,否则每次崩溃都会产生一个新的工单。
- 生成哈希并创建工单 (Generate Hash & Create Ticket):
- 对净化后的 Breadcrumb 数据生成一个唯一的哈希值。
- 使用此哈希值作为该类崩溃的唯一标识来创建工单。
- 设置工单标题 (Set Ticket Title):
- 通常使用最后一个活跃作用域 (last active scope) 的名称作为工单标题。
- 这能为问题提供一个直观的线索,但它不一定是崩溃的根本原因,仅作参考。
三、 过滤示例:一个 TDR 崩溃
假设一个 TDR(Timeout Detection and Recovery)崩溃发生在 Lumen 的 BuildPageUpdatePriorityHistogram 作用域中。
-
原始日志:
- 原始的 Breadcrumb 日志会包含大量信息,记录了崩溃前执行的多个作用域。
- 这些信息中大部分是已成功完成的,与崩溃本身关联性不大。
-
第一步过滤:
- 移除所有已完成的工作,只保留最后一个已完成的工作。
- 通过这一步,可以迅速将分析范围缩小到崩溃发生前一刻的上下文,显著提高了信噪比。
GPU 崩溃日志处理与哈希化 (Breadcrumbs 系统)
1. 问题的提出:原始崩溃日志的噪音
- 原始的 GPU 崩溃日志(以 Lumen 中的
build page update priority histogram崩溃为例)包含了大量信息,但其中大部分与定位崩溃的根本原因无关。 - 直接使用这些冗长的日志进行分析或分组效率低下。
2. Breadcrumbs 生成流程:从原始日志到可哈希签名
为了从充满噪音的日志中提取一个稳定、唯一的签名(称为 Breadcrumbs)用于崩溃分组,需要执行一系列的过滤和标准化步骤。
步骤 1:过滤已完成的作用域 (Filtering Finished Scopes)
- 核心思想:为了在减少噪音的同时保留上下文,系统会移除调用栈中大部分已完成的工作。
- 具体规则:在层级结构的每个作用域中,移除除了最后一个之外的所有已完成的工作 (scopes)。
- 目的:保留最近完成的操作作为崩溃发生前的环境线索,同时去除大量无关的历史信息。
步骤 2:过滤未开始的作用域 (Filtering Non-Started Scopes)
- 核心思想:类似于处理已完成的工作,未开始的工作队列也需要被清理。
- 具体规则:移除除了最后一个之外的所有未开始的工作。
- 目的:保留即将执行的工作作为线索,它可能与崩溃的原因有关,或者提供了 GPU 当时计划执行任务的上下文。
步骤 3:数据标准化 (Data Normalization)
- 问题:经过前两步过滤后,调用栈虽然大大缩短,但仍然包含动态变化的用户数据。
- 例如,
access mode pass中的纹理和缓冲区数量,或Lumen scene update中的卡片捕获数量和纹理数据量(MB)。 - 如果直接对包含这些数字的字符串进行哈希,每次崩溃的具体数值不同都会导致生成不同的哈希值,使得相同的根本问题被归为不同的 Bug。
- 例如,
- 解决方案:采用一种简单而有效的方法进行标准化。
- 算法:将调用栈字符串中的所有数字替换为一个固定的占位符(例如 'x')。
- 结果:生成一个对于同类崩溃稳定且唯一的字符串,此时的 Breadcrumbs 已准备好用于哈希。
3. 哈希与工单创建 (Hashing and Ticket Creation)
- 哈希计算:将经过标准化处理后的 Breadcrumbs 字符串输入哈希函数,生成一个唯一的哈希值。
- 工单创建与分组:
- 使用此哈希值来对崩溃报告进行分组。所有具有相同哈希值的崩溃都将被归类到同一个问题单(Ticket)下。
- 工单标题生成:使用崩溃时最后一个活动作用域的名称(例如
build page update histogram)作为工单的标题。
4. 系统的成效与局限性
成效
- 更具信息量的崩溃标题:相比于笼统的 "GPU crash",新标题能直接指出问题可能发生的模块(如 Shadows, Skinning, Lumen 等),极大地提高了问题定位的效率。
局限性
- 分组存在“假阴性” (False Negatives):
- 根本原因在于 GPU 执行的非确定性 (Indeterminate nature)。
- 同一个根本原因的崩溃,可能会因为当时并行运行的其他工作不同,而产生略有差异的调用栈,从而导致生成了不同的哈希值和多个独立的工单。
- 无法精确定位根本原因:系统无法百分之百确定是哪个活动作用域真正导致了崩溃,它只能提供最有可能的线索。
- 未来改进方向:可以通过模式匹配 (pattern matching) 等技术来进一步优化分组逻辑,减少“假阴性”的出现。
- 当前不支持的场景:该系统目前不支持页面错误 (page faults) 类型的崩溃。
GPU Crash Dump 系统:局限性与未来展望
一、 未来改进方向
-
优化 Crash Ticket 分类
- 问题: 当前系统可能将同一个根本原因的崩溃归为几个不同的 ticket。
- 解决方案: 引入模式匹配 (Pattern Matching) 技术,更智能地对崩溃报告进行分组,提高问题聚合的准确性。
-
支持页面错误 (Page Faults) 分析
- 当前缺失: 系统目前不支持对 页面错误 导致的崩溃进行分析,因为 Breadcrumbs 无法访问所需数据。
- 潜在方案: 集成像 DRED (Device Removed Extended Data) 这样的工具。DRED 可以记录页面错误信息以及崩溃时相关的资源,从而弥补 Breadcrumbs 的不足。
二、 当前系统的局限性
-
Breadcrumbs 的不可靠性
- 核心问题: Breadcrumbs 系统返回的信息有时并不可靠,无法提供足够线索来定位问题。
- 典型案例: 最常见的 ticket 是 "Command list all finished"。这种情况发生在所有 marker 都显示为已完成时,但崩溃依然发生。这可能是驱动 Bug 或其他未知问题,Breadcrumbs 无法揭示根本原因。
-
信息量过少 (Tiny Breadcrumbs)
- 问题: 有时系统返回的 Breadcrumbs 非常微小,包含的信息极少,尤其是在编辑器等复杂场景中。尽管后台可能执行了大量工作,但捕获到的日志却不足以用于分析。
-
应对策略
- 当 Breadcrumbs 提供的信息不足时,开发团队会转而使用更高级的工具 (Advanced Tools) 进行深度挖掘。
- 如果问题可以在主机 (console) 上复现,则优先在主机上进行调试,因为主机平台通常能提供更丰富、更详细的调试信息。