三角形的一生:NVIDIA 逻辑管线详解
Life of a triangle - NVIDIA's logical pipeline | NVIDIA Developer
一、GPU 为何需要如此复杂的架构?
核心问题:数据放大与可变工作负载
图形渲染天然具备 数据放大(Data Amplification) 特性,导致工作负载高度不可预测:
- 每个 DrawCall 产生的三角形数量各不相同
- 经过 裁剪(Clipping) 后的顶点数量与原始三角形顶点数不同
- 经过 背面剔除(Back-face Culling) 和 深度剔除(Depth Culling) 后,并非所有三角形都需要生成像素
- 三角形在屏幕上的覆盖面积差异巨大——可能覆盖数百万像素,也可能一个像素都没有
架构演进:从物理管线到逻辑管线
| 时代 | 架构特点 |
|---|---|
| G80 之前(DX9 硬件、PS3、Xbox 360) | 物理管线 :芯片上有不同的物理阶段,工作依次流过各阶段 |
| G80 统一架构 | 顶点着色器和片元着色器开始根据负载共享部分计算单元,但图元/光栅化仍是串行处理 |
| Fermi 及之后 | 完全并行的逻辑管线 :通过复用芯片上的多个引擎实现逻辑上的管线步骤 |
并行处理的直观理解
假设有两个三角形 A 和 B,它们的工作可以同时处于不同的逻辑管线阶段:
- 三角形 A :
- 已完成顶点变换,正在等待光栅化
- 部分像素正在执行 像素着色器 指令
- 部分像素正被 深度缓冲(Z-cull) 拒绝
- 部分像素已经在写入 帧缓冲(Framebuffer)
- 部分像素仍在等待处理
- 三角形 B :
- 与此同时,我们可能正在获取三角形 B 的顶点数据
类比理解 :想象一条分流的河流。多条并行的管线流各自独立,每条流都有自己的时间线,有些分支比其他的更多。如果我们根据当前正在处理的三角形或 DrawCall 对 GPU 的各个单元进行颜色编码,你会看到五彩斑斓的闪烁灯光。
核心思想 :将一个大任务(将 DrawCall 的三角形渲染到屏幕上)拆分成许多小任务甚至子任务,这些任务可以并行运行。每个任务被调度到可用的资源上,调度不受任务类型限制(顶点着色可以与像素着色并行进行)。
二、GPU 硬件架构概览

整体架构图
自 Fermi 以来,NVIDIA 采用了相似的架构原则:
GPU 整体结构
├── Giga Thread Engine(千兆线程引擎,管理所有工作)
├── GPC (Graphics Processing Cluster) × N
│ ├── Raster Engine × 1(光栅化引擎)
│ └── SM (Streaming Multiprocessor) × M
│ ├── Poly Morph Engine(多边形变形引擎)
│ ├── Warp Scheduler(Warp 调度器)
│ ├── Dispatch Units(分发单元)
│ └── Cores(CUDA 核心,执行数学运算)
├── Crossbar(交叉开关,实现跨 GPC 的工作迁移)
└── ROP (Render Output Unit) 子系统(渲染输出单元)
核心组件详解
| 组件 | 功能说明 |
|---|---|
| Giga Thread Engine | 全局工作调度引擎,管理 GPU 上所有正在进行的工作 |
| GPC(Graphics Processing Cluster) | 图形处理集群,包含多个 SM 和一个光栅引擎 |
| SM(Streaming Multiprocessor) | 流式多处理器,程序员所编写的着色器程序在此执行 |
| Raster Engine | 光栅化引擎,将三角形转换为像素信息 |
| Crossbar | 交叉互联网络,允许工作跨 GPC 或其他功能单元(如 ROP)迁移 |
| ROP(Render Output Unit) | 渲染输出单元,处理最终的像素写入 |
|
SM 内部结构
SM 是着色器程序实际执行的地方,包含:
- Cores :执行线程数学运算的核心(一个线程可以是一次顶点着色器或像素着色器的调用)
- Warp Scheduler :Warp 调度器,管理一组 32 个线程(称为一个 Warp ),并将指令分配给分发单元
- Dispatch Units :分发单元,将指令发送给核心执行
GPU 核心 vs CPU 核心的本质区别
| 特性 | GPU 核心 | CPU 核心 |
|---|---|---|
| 智能程度 | 非常"笨",只会执行简单指令 | 非常"聪明",能处理复杂逻辑 |
| 指令示例 | "将寄存器 4234 与寄存器 4235 相加,存入寄存器 4230" | 复杂的分支预测、乱序执行等 |
| 智能所在 | 智能在更高层级——调度器指挥整个线程集合 | 智能在核心本身 |
类比 :GPU 就像一个交响乐团的指挥,单个乐手(核心)只需要演奏简单的音符,而指挥(调度器)负责协调整个乐团。
可扩展性设计
不同 GPU 产品的单元数量配置不同:
- GM204(高端桌面):4 个 GPC,每个 GPC 有 4 个 SM
- Tegra X1(移动端):1 个 GPC,2 个 SM
两者都基于 Maxwell 架构设计。SM 的内部设计(核心数量、指令单元、调度器数量等)也随着代际演进而变化,使芯片能够从高端桌面扩展到笔记本再到移动设备。
三、三角形生命周期:逻辑管线 10 步详解
前提假设 :为简化说明,假设 DrawCall 引用的 索引缓冲(Index Buffer) 和 顶点缓冲(Vertex Buffer) 已经填充好数据并驻留在 GPU 的 DRAM 中,且只使用顶点着色器和像素着色器。
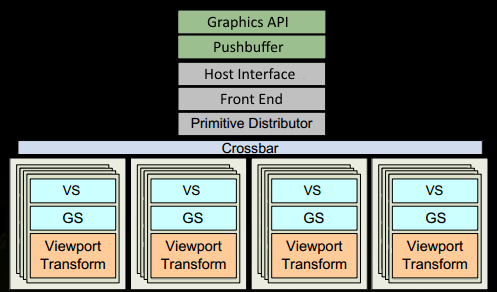
阶段 1:应用程序发起 DrawCall
程序通过图形 API(DX 或 GL)发起 DrawCall
- 这个调用最终到达 驱动程序(Driver)
- 驱动程序执行一些 合法性验证 ,检查调用是否"合法"
- 将命令以 GPU 可读的编码格式 插入到 Pushbuffer 中
⚠️ 性能关键点 :CPU 端是常见的性能瓶颈,程序员正确使用 API 以及利用现代 GPU 能力的技术非常重要。
阶段 2:命令传输到 GPU
驱动程序将 Pushbuffer 中的工作发送给 GPU 处理
- 在累积了足够的工作后,或者在显式调用 flush 后,驱动程序将缓冲的工作发送给 GPU(操作系统参与此过程)
- GPU 的 Host Interface(主机接口) 接收命令
- 命令通过 Front End(前端) 进行处理
阶段 3:图元分发
在 Primitive Distributor(图元分发器)中开始工作分发
- 处理 索引缓冲 中的索引
- 生成 三角形工作批次(Triangle Work Batches)
- 将批次发送到多个 GPC 进行处理
阶段 4:顶点数据获取
在 GPC 内部,SM 的 Poly Morph Engine 负责获取顶点数据
- 根据三角形索引从显存中获取顶点数据
- 这个步骤称为 Vertex Fetch(顶点获取)
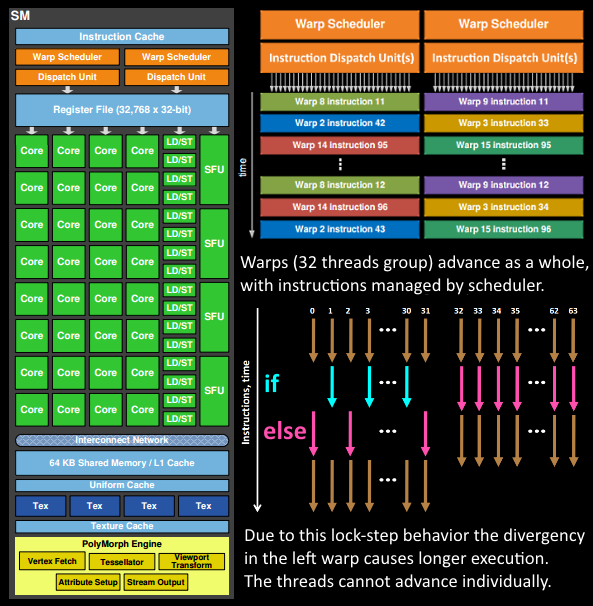
阶段 5:Warp 调度与顶点着色器执行
数据获取完成后,32 个线程组成的 Warp 被调度到 SM 内部,开始处理顶点
Warp 执行机制详解
- SM 的 Warp 调度器 按顺序为整个 Warp 发射指令
- 线程以锁步(Lock-step)方式执行 :所有线程执行相同的指令
- 如果某些线程不应该执行当前指令,它们会被 单独屏蔽(Masked out)
需要屏蔽的情况
- 分支发散(Branch Divergence) :当前指令属于
if (true)分支,但某线程的数据计算结果为false - 循环终止差异 :某些线程已达到循环终止条件,而其他线程尚未达到
⚠️ 性能影响 :着色器中的 分支发散越多 ,Warp 中所有线程花费的时间就越长。线程无法单独前进,只能作为 Warp 整体前进!但不同的 Warp 之间是相互独立的。
指令执行与延迟隐藏
- 指令完成时间差异 :一个 Warp 的指令可能一次完成,也可能需要多个分发周期(例如 SM 的加载/存储单元通常比基本数学运算单元少)
- 延迟隐藏机制 :由于某些指令(特别是内存加载)需要较长时间完成,Warp 调度器会简单地 切换到另一个不在等待内存的 Warp
- 这是 GPU 克服内存读取延迟的关键概念 :通过切换活跃线程组来隐藏延迟
快速切换的代价
为了实现快速切换,调度器管理的所有线程都在 寄存器文件(Register File) 中拥有自己的寄存器:
- 着色器程序需要的寄存器越多 → 能容纳的线程/Warp 越少
- 能切换的 Warp 越少 → 等待指令完成时能做的有用工作越少(特别是等待内存获取时)
📝 优化启示 :减少着色器的寄存器使用量可以增加 Warp 占用率,从而更好地隐藏内存延迟。
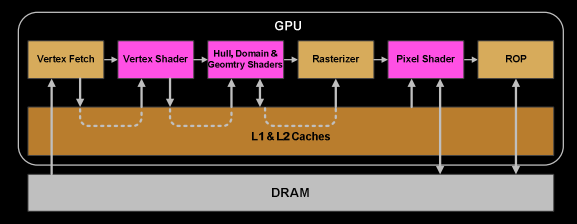
阶段 6:视口变换与裁剪
一旦 Warp 完成顶点着色器的所有指令,其结果将进行 Viewport Transform(视口变换)处理
- 三角形被 裁剪空间体积(Clipspace Volume) 裁剪
- 三角形准备好进行光栅化
- 这些跨任务的通信数据使用 L1 和 L2 缓存 进行传递
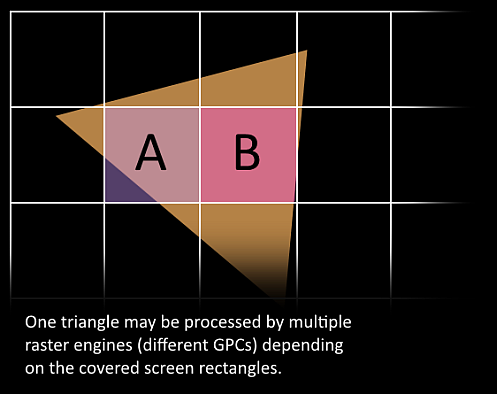
阶段 7:工作重分发(跨 GPC)
这是令人兴奋的阶段——三角形即将被切分,并可能离开它当前所在的 GPC
- 使用三角形的 包围盒(Bounding Box) 来决定哪些光栅引擎需要处理它
- 因为每个光栅引擎负责屏幕上的多个 Tile(瓦片)
- 通过 Work Distribution Crossbar(工作分发交叉开关) 将三角形发送到一个或多个 GPC
💡 关键点 :我们在这里有效地将一个三角形拆分成了许多更小的任务。
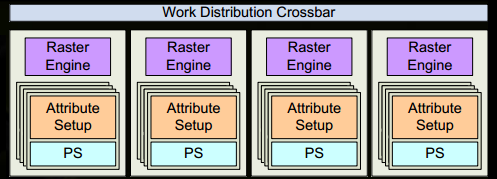
阶段 8:属性设置与光栅化
目标 SM 上的 Attribute Setup(属性设置)确保插值器格式正确
- 确保在顶点着色器中生成的输出( 插值量 Interpolants )以像素着色器友好的格式存储
GPC 的光栅引擎处理接收到的三角形
- 为其负责的屏幕区域生成 像素信息
- 同时处理 背面剔除(Back-face Culling) 和 Z-cull(深度剔除)
阶段 9:像素着色器执行

再次将 32 个像素线程组成批次进行处理
更准确地说,是 8 组 2×2 像素 Quad ,这是像素着色器中始终使用的最小工作单位。
为什么是 2×2 Quad?
2×2 Quad 允许我们计算导数(Derivatives) ,用于:
- 纹理 Mip Map 过滤 :Quad 内纹理坐标变化大 → 使用更高级别的 Mip
- 屏幕空间导数 :
dFdx、dFdy等函数
辅助调用(Helper Invocation)
- Quad 内那些采样位置实际上不覆盖三角形的线程会被 屏蔽
- 这些线程称为 Helper Invocation (在 GLSL 中可通过
gl_HelperInvocation查询) - 它们参与计算以提供导数值,但不会写入结果
像素着色器的 Warp 执行
- 本地 SM 的 Warp 调度器管理像素着色任务
- 执行与顶点着色器阶段相同的 Warp 调度器指令游戏
- 锁步处理特别有用 :我们可以几乎免费地访问像素 Quad 内的值,因为所有线程都保证将数据计算到相同的指令点(参见
NV_shader_thread_group扩展)
阶段 10:ROP 处理与帧缓冲写入
像素着色器完成颜色计算后,还需要考虑深度值和 API 的三角形顺序
在将数据交给 ROP(Render Output Unit)子系统 之前,必须考虑三角形的原始 API 顺序。
ROP 执行的操作
| 操作 | 说明 |
|---|---|
| 深度测试(Depth Testing) | 判断当前像素是否应该被写入 |
| 帧缓冲混合(Blending) | 与已有颜色进行混合 |
| 原子操作 | 这些操作必须是原子的(一次一组颜色/深度) |
⚠️ 原子性必要性 :确保不会出现一个三角形的颜色和另一个三角形的深度值混在一起的情况(当两者覆盖同一像素时)。
内存压缩
- NVIDIA 通常会应用 内存压缩 来减少内存带宽需求
- 这增加了 "有效"带宽 (详见 GTX 980 白皮书)
四、CPU-GPU 同步的性能影响
为什么同步开销如此大?
当需要与 CPU 同步时:
- 必须等待所有工作完成 :没有新工作被提交,所有单元变为空闲
- 重新填充管线需要时间 :发送新工作后,需要一段时间才能让所有单元再次满载
- 大型 GPU 影响更大 :单元越多,重新填充的时间越长
💡 优化建议 :尽量避免 CPU-GPU 同步,使用异步技术和多缓冲策略。

五、可视化验证
使用 NV_shader_thread_group 扩展,可以根据不同的 SM 或 Warp ID 对渲染结果进行颜色编码:
- 结果 不会帧间一致 ,因为工作分发在每帧之间会变化
- 场景使用多个 DrawCall 渲染,其中一些可能并行处理
- 使用 NSIGHT 工具可以观察到部分 DrawCall 并行性
六、关键要点总结
| 概念 | 核心理解 |
|---|---|
| 逻辑管线 vs 物理管线 | 现代 GPU 实现的是逻辑管线,通过复用物理单元实现并行处理 |
| Warp | 32 线程的执行单位,锁步执行,是 GPU 调度的基本粒度 |
| 分支发散 | 同一 Warp 内的分支会导致所有线程等待,应尽量避免 |
| 延迟隐藏 | 通过 Warp 切换隐藏内存延迟,需要足够的 Warp 占用率 |
| 2×2 Quad | 像素着色的最小单位,用于计算导数 |
| 工作重分发 | 三角形可能跨 GPC 分发,通过 Crossbar 实现 |
| 原子 ROP 操作 | 保证混合和深度测试的正确性 |
| CPU-GPU 同步 | 代价高昂,会导致管线排空和重新填充 |