从顶点着色器到网格着色器:GPU 几何管线的演进之路
From vertex shader to mesh shader - AMD GPUOpen
1. 引言
本文的核心问题:传统的顶点着色器管线存在哪些局限?网格着色器如何克服这些局限?它在 AMD RDNA™ 架构上又是如何工作的?
本文将沿着以下线索展开:
传统顶点管线 → RDNA™ 的 NGG 管线如何处理顶点 → 传统管线的痛点 → 网格着色器如何解决这些痛点 → 放大着色器如何进一步扩展灵活性
2. 传统顶点管线
2.1 基本概念:顶点缓冲与索引缓冲
 在传统图形管线中,一个网格(Mesh)通常由以下两部分定义:
在传统图形管线中,一个网格(Mesh)通常由以下两部分定义:
- 顶点缓冲(Vertex Buffer):存储所有顶点数据(位置、法线、UV 等)。
- 索引缓冲(Index Buffer):每三个索引为一组,定义一个三角形;每个索引指向顶点缓冲中的某个顶点。
索引缓冲的核心价值:避免数据重复。多个三角形可以共享同一个顶点,只需在索引缓冲中重复引用该顶点的索引即可,而不必在顶点缓冲中复制该顶点的全部数据。
本文聚焦点:后文的所有比较和讨论都基于"带索引缓冲的顶点着色"(Indexed Vertex Shading)模式。
2.2 传统几何管线的着色器阶段
 在图元被光栅化和像素着色之前,数据需要经过 输入装配器(Input Assembler) 以及最多四个可编程着色器阶段:
在图元被光栅化和像素着色之前,数据需要经过 输入装配器(Input Assembler) 以及最多四个可编程着色器阶段:
| 着色器阶段 | 职责 | 处理粒度 |
|---|---|---|
| 顶点着色器(Vertex Shader) | 将顶点从顶点缓冲的输入格式变换到裁剪空间(clip-space),或为后续阶段准备数据 | 每个线程处理一个顶点 |
| 外壳着色器(Hull Shader) | 处理高阶控制面片的控制顶点 | 控制顶点 |
| 域着色器(Domain Shader) | 处理一维或二维域中的采样点;与外壳着色器共同构成硬件曲面细分的可编程阶段 | 域采样点 |
| 几何着色器(Geometry Shader) | 对点、线或三角形图元进行操作,可生成一个或多个新图元 | 图元 |
关键约束:顶点着色器是每条几何管线必需的阶段。
本文简化:本文仅关注顶点着色器如何映射到 RDNA™ 硬件。几何着色器和曲面细分阶段将在后续文章中讨论。
2.3 顶点复用的核心挑战
由于索引缓冲允许多个三角形共享顶点,GPU 理应能够复用已经变换过的顶点,从而减少昂贵的顶点着色操作次数。输入装配器(Input Assembler)负责解析索引缓冲并启动后续的顶点处理。
那么,如何实现顶点复用呢?
最朴素的想法:先对顶点缓冲中的所有顶点运行一次顶点着色器,存储变换后的结果,然后再装配三角形。
为什么行不通:
- 内存容量:存储数百万个变换后的顶点可能超出 GPU 的片上内存容量。
- 延迟过大:必须等所有顶点着色器执行完毕才能开始图元装配和光栅化,严重拖慢流水线。
正确的方向:需要一套系统,能够分批并行地着色顶点,同时将已着色的顶点装配成图元,而其他顶点仍在处理中甚至尚未开始处理。
在 RDNA™ 显卡上,这一机制通过 Next Generation Geometry(NGG) 技术实现。
3. NGG 与图元子组(Primitive Subgroups)

3.1 NGG 管线的核心组件
为了理解 NGG 管线的各组件如何协同工作,我们以一个带索引的绘制调用(Indexed Draw Call)为例进行说明。假设绘制调用仅使用顶点着色器,不使用几何或曲面细分着色器。
以 DirectX 12 为例,提交如下绘制命令:
graphicsCommandList->DrawIndexedInstanced(
12, /* 索引数量 */
1, /* 实例数量 */
0, /* 起始索引位置 */
0, /* 基准顶点位置 */
0 /* 基准实例位置 */
);命令提交后,经 API 运行时和 GPU 驱动处理,绘制命令被发送到 GPU,由以下组件依次处理:
| 组件 | 职责 |
|---|---|
| 命令处理器(Command Processor) | 接收来自 GPU 驱动的绘制/分发/其他命令,根据当前命令配置其他组件(如几何引擎) |
| 几何引擎(Geometry Engine) | 从索引缓冲加载索引;设置并启动顶点着色器实例 |
| 双计算单元(Dual Compute Unit) | 实际执行顶点着色器(以及任何其他着色器)的地方。几何引擎指定每个线程应处理哪个顶点;计算单元从顶点缓冲获取顶点数据,着色后将变换结果存储到着色器导出 |
| 着色器导出(Shader Export) | 一块内存区域,接收并存储来自计算单元的顶点和图元信息 |
| 图元装配器(Primitive Assembler) | 从着色器导出中读取图元连接信息和变换后的顶点位置,装配成独立三角形,输出到光栅化器 |
| 光栅化器(Rasterizer) | 接收装配好的三角形,确定每个三角形需要着色的片元(Fragment) |
3.2 图元子组的构建过程

这是 NGG 管线中实现顶点复用的核心机制。
几何引擎从索引缓冲中选取一个子集的三角形(例如四个三角形),然后执行以下操作:
步骤 1:扫描这些三角形的索引,提取出一个唯一顶点索引列表(即去重后的顶点列表)。
步骤 2:将原始索引缓冲中的顶点索引重新编号,使其引用唯一顶点列表中的位置(而非原始顶点缓冲中的位置)。
结果:这对组合——重新编号的索引(称为图元连接信息/Primitive Connectivity)+ 唯一顶点列表——在概念上构成了一个小型网格,也就是一个 meshlet,拥有自己独立的顶点集和索引集。
为什么叫"图元连接信息"而不叫"索引"?因为这些索引不再直接引用原始顶点缓冲中的顶点,而是引用本子组内唯一顶点列表中的条目。
关键限制:图元连接信息中的索引只能引用同一图元子组内的顶点,因此着色后的顶点也只能在同一图元子组内被复用。
一个图元子组处理完毕并发送后,几何引擎对索引缓冲中的下一个子集重复相同过程,直到所有图元都被渲染完毕。
3.3 顶点复用与顶点缓存优化
核心问题:由于图元子组有最大顶点数和最大图元数的限制,完美的顶点复用(每个顶点只处理一次)通常是不可能的。
如果引用同一顶点的多个三角形被分到了不同的图元子组,GPU 就会对同一顶点多次调用顶点着色器,产生冗余计算,降低性能。
解决方案:顶点缓存优化(Vertex Cache Optimization)
虽然各图元子组是独立计算和光栅化的(这与传统的"存储变换后顶点供后续三角形复用"的顶点缓存不同),但"顶点缓存"这个术语仍然常被用来描述图元子组的行为。
优化策略:通过重新排列索引缓冲,将共享同一顶点的三角形聚集在一起,使它们更可能被分到同一个图元子组中,从而最大化顶点复用。
实际案例:Stanford Bunny
| 指标 | 未优化 | 使用 meshoptimizer 优化后 |
|---|---|---|
| 顶点数 | 34.8k | 34.8k |
| 顶点着色器调用次数 | 143.9k | 48.9k |
| 重复因子 | 4.13 | 1.40 |
| Visualization: Different colors represent different primitive subgroups. |  | 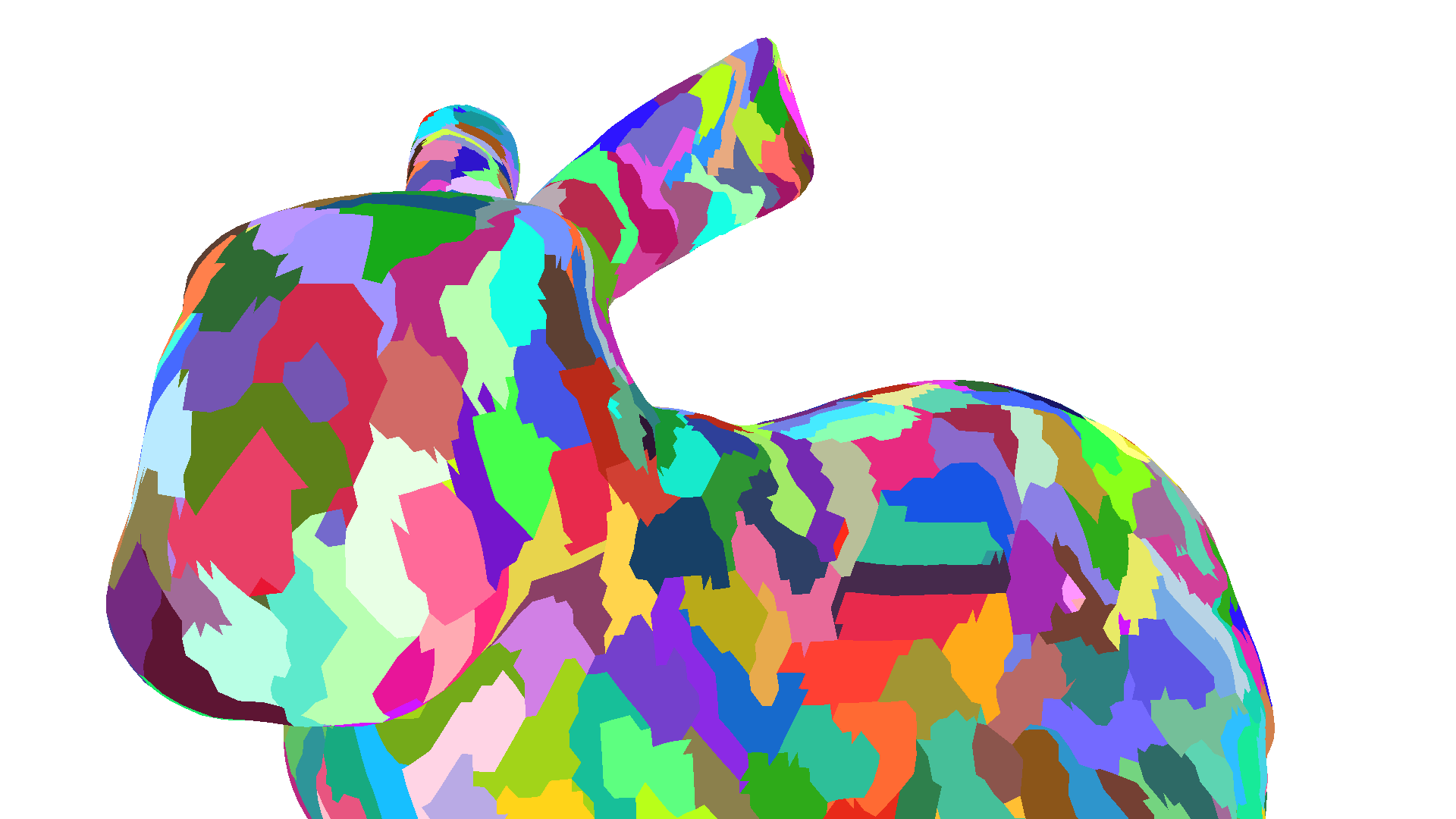 |
Stanford Bunny 是一个有约 7 万个三角形、约 3.5 万个顶点的光扫描模型。由于其光扫描特性,顶点按网格状排列,三角形按垂直线组织。这种布局导致子组内的顶点最多只被复用两次,造成大量重复着色。使用 meshoptimizer 库的
meshopt_optimizeVertexCache函数优化后,重复因子从 4.13 降至 1.40,性能显著提升。重要建议:这种预处理可以且应该静态地应用于所有三角形网格。
4. 图元着色器(Primitive Shaders)
4.1 NGG 管线的两个着色器阶段
在 NGG 管线中,传统的顶点、几何、可编程曲面细分着色器被整合为两个着色器:
| 着色器 | 概念映射 | 职责 |
|---|---|---|
| 表面着色器(Surface Shader) | 对应外壳着色器(Hull Shader)阶段 | 预曲面细分处理 |
| 图元着色器(Primitive Shader) | 直接写入着色器导出的顶点和图元区域 | 直接馈送光栅化器 |

4.2 图元着色器的工作流程
图元着色器用于处理图元子组。其每个线程被分配一个顶点索引和一个图元:
步骤 1:线程接收其分配的图元的连接信息。
步骤 2:线程从对应的顶点缓冲中加载其分配的顶点信息。
步骤 3:线程执行顶点着色(变换等计算)。
步骤 4:线程发出
exp指令,将图元连接信息和变换后的顶点同时导出到着色器导出(Shader Export)。
扩展能力:由于图元着色器可以修改图元连接信息,它也可以用来实现曲面细分域着色器和几何着色器的功能。
4.3 图元装配与光栅化
图元装配器从着色器导出中加载一个图元的连接数据和它引用的三个顶点,装配三角形,执行裁剪(Culling)和视图变换,然后将图元发送到光栅化器。至此,数据走完了整条 NGG 管线。
4.4 传统顶点管线的痛点总结
经过以上分析,传统带索引的顶点管线仍然面临以下挑战和局限:
- 无法直接控制顶点着色器的调用和顶点复用:开发者无法精确指定哪些顶点应被复用。
- 顶点缓存优化实现困难:需要考虑各种硬件厂商和硬件代际的差异,没有一种方案能在所有 GPU 上表现同样好。
- 索引缓冲格式固定:必须遵循 GPU 能理解的固定格式,限制了基于索引的压缩技术的灵活性。
5. 网格着色器(Mesh Shaders)

5.1 概述
网格着色器于 2019 年引入 Microsoft DirectX® 12,2022 年以 VK_EXT_mesh_shader 扩展的形式引入 Vulkan。
核心思想:网格着色器引入了一条全新的、类计算(compute-like) 的几何管线,让开发者直接向光栅化器发送顶点和图元的批次(Batch)。
这些批次通常被称为 meshlet,由少量顶点和一个引用这些顶点的三角形列表组成。
meshlet vs. 图元子组:概念上,meshlet 与前文讨论的图元子组非常相似——都可以表示大网格的一小部分。但关键区别在于:meshlet 完全由用户定义,因此不仅可以用于传统三角形网格,还可以用于渲染程序化几何(如地形)或细分曲面等。
5.2 两个新的着色器阶段
网格着色器引入了两个新的 API 着色器阶段:
| 着色器阶段 | 是否必需 | 职责 |
|---|---|---|
| 任务着色器 / 放大着色器(Task / Amplification Shader) | 可选 | 控制启动哪些以及多少个网格着色器线程组 |
| 网格着色器(Mesh Shader) | 必需 | 输出顶点和图元集合到光栅化器 |
⚠️ 重要:这两个新阶段完全替换传统的顶点、外壳、域、几何着色器管线,不能与任何传统阶段混合使用。
5.3 编程模型:类计算着色器
这是网格着色器最重要的设计转变:
| 特性 | 传统顶点管线 | 网格着色器 |
|---|---|---|
| 线程组织 | 每个线程处理一个顶点/采样点/图元,线程间无可见性和通信 | 线程组(Thread Group),与计算着色器一致 |
| 输出方式 | 每个线程输出对应的单个元素 | 每个线程组输出可变数量的顶点和图元;任何线程可以写任何顶点或图元 |
| 线程与数据的绑定 | 线程与顶点/图元一一对应 | 无需将图元或顶点绑定到特定线程 |
| 线程间通信 | 不支持 | 支持 wave intrinsics 和 group shared memory,线程可协作计算 |
5.4 启动方式
传统绘制调用指定要处理的顶点数或索引数。网格着色器的启动方式完全不同:
// DirectX 12
graphicsCommandList->DispatchMesh(threadGroupCountX, threadGroupCountY, threadGroupCountZ);
// Vulkan
// vkCmdDrawMeshTasksEXT(commandBuffer, groupCountX, groupCountY, groupCountZ);与计算着色器一样,指定一个三维网格的线程组数量。
5.5 网格着色器的核心优势
① 跳过输入装配器(Input Assembler)
网格着色器的线程组直接启动,完全绕过输入装配器。这意味着:
- 开发者对导出哪些图元拥有完全控制权。
- 对输入数据没有任何格式限制。与计算着色器一样,网格着色器可以读取甚至写入任何资源。
② 顶点复用变为离线预处理
绕过输入装配器意味着顶点复用的计算被转移到了预处理阶段。这带来的好处是:
- 避免了每帧或每次绘制调用都重新计算复用信息。
- 复用信息可以在多次绘制调用和多帧之间共享。
③ 消除输入装配器瓶颈
输入装配器不再参与管线,因此它不可能成为管线瓶颈。这使得网格着色器能够直接随不同 GPU 配置扩展性能。
④ 淘汰传统几何放大模型
退役了曲面细分和几何着色器的固定功能几何放大编程模型,网格着色器中的几何放大更好地映射到通用计算硬件,减轻了对固定功能硬件的依赖。
⑤ 直接控制图元裁剪
开发者可以直接控制哪些图元需要光栅化,从而实现:
- 单个图元级别的裁剪
- 结合放大着色器,实现整个 meshlet 级别的裁剪
⑥ 线程组内协作
线程组内的线程可以通过 wave intrinsics 和 group shared memory 协作计算一个或多个顶点/图元。
5.6 网格着色器优势总结
网格着色器的类计算编程模型使开发者能够克服传统顶点管线的关键限制,同时为高级渲染技术(如三角形裁剪、实时几何解压缩)提供了更大的灵活性。
6. 网格着色器与 NGG 管线的映射

6.1 映射关系
回顾 NGG 管线的两个着色器阶段:
- 表面着色器(Surface Shader)
- 图元着色器(Primitive Shader):能够将顶点属性和图元连接信息导出到图元装配器
图元着色器的这种能力——同时导出顶点和图元——可以直接用于实现网格着色器的功能。
6.2 启动机制
DispatchMesh 命令直接指定一个三维网格的线程组。这些线程组直接映射到图元组(Primitive Groups)。
关键区别:无需在启动前进行任何顶点去重或复用扫描。网格着色器的启动非常类似于计算着色器的分发。
但是,网格着色器的线程组仍然通过几何引擎启动。在网格着色器模式下,几何引擎的职责变为:
- 跟踪和管理着色器导出中的分配
- 管理图元装配器的状态(图元模式、裁剪设置等)
- 最重要的是:由于顶点和图元数量在启动网格着色器前是未知的,几何引擎需要接收实际的顶点和图元数量,并将其转发给图元装配器。
6.3 快速启动模式(Fast Launch Mode)
由于网格着色器下几何引擎的职责与传统顶点着色大不相同,几何引擎实现了一个特殊的快速启动模式:
绕过所有顶点复用检查和图元子组构建阶段,直接启动线程组。
7. 放大着色器(Amplification Shaders)

7.1 概述
放大着色器是网格着色器之前运行的一个可选着色器阶段,用于控制后续网格着色器线程组的启动。
核心能力:每个放大着色器线程组可以启动可变数量的网格着色器线程组——即"放大"GPU 上执行的总工作量。
与曲面细分的区别:曲面细分着色器通过固定功能硬件在控制面片内部放大图元数量。放大着色器则在更粗的粒度上工作,只指定要启动的网格着色器线程组数量。不过,也可以用放大着色器模拟固定功能曲面细分的效果。
7.2 工作机制
放大着色器通过调用 DispatchMesh 内置函数来启动网格着色器:
DispatchMesh(threadGroupCountX,
threadGroupCountY,
threadGroupCountZ,
payload);关键细节:
| 方面 | 说明 |
|---|---|
| payload | 用户自定义的负载数据,从放大着色器传递到所有后续启动的网格着色器 |
| 与 CPU 侧的区别 | CPU 可以在不同 DispatchMesh 调用之间修改 Root Signature,但放大着色器不能 |
7.3 CPU 侧的启动方式
从 CPU 启动放大着色器的方式与启动网格着色器完全相同:都使用 DispatchMesh 命令。
选择逻辑:如果图形管线状态(Pipeline State)中指定了放大着色器,
DispatchMesh命令中的三维网格就指的是放大着色器线程组的网格。是启动网格着色器还是放大着色器不可在运行时动态选择,需要使用不同的图形管线状态。
7.4 与 GPU Work Graphs 的区别
这种 GPU 端的直接工作放大可能看起来类似于近年引入的 GPU Work Graphs,但放大着色器有以下关键限制:
| 限制 | 说明 |
|---|---|
| 一对一绑定 | 一条网格着色器图形管线只包含一个放大着色器和一个网格着色器。放大着色器只能控制启动多少线程组,不能选择使用哪个网格着色器或像素着色器 |
| 单级放大 | 放大着色器只能调用网格着色器,不能调用其他放大着色器或自身。即只支持一级工作放大 |
| 单次调用 + 单 payload | 放大着色器线程组内的 DispatchMesh 内置函数只能调用一次,且只接受一个 payload 供所有后续网格着色器线程组使用 |
7.5 应用场景
即使有上述限制,放大着色器仍然通过允许完全在 GPU 端进行动态工作放大或缩减来扩展网格着色器管线的灵活性。典型应用包括:
① Meshlet 或实例裁剪(Culling)
为每个 meshlet 或实例启动一个放大着色器线程。该线程测试其对应 meshlet/实例的可见性(例如,通过将包围盒与相机视锥体进行比较)。不可见的 meshlet/实例不启动任何网格着色器线程组,从而完全跳过其渲染。
② 动态 LOD(Level-of-Detail)
类似于实例裁剪的模式:为每个网格实例启动一个放大着色器线程。每个线程根据其实例到相机的距离,选择相应的细节级别进行渲染。
③ 程序化或细分几何的放大
放大着色器可以通过将工作负载动态拆分到多个网格着色器线程组来扩展网格着色器的输出能力,适用于程序化几何或细分曲面等场景。
注意事项:在实例裁剪和动态 LOD 场景中,一个放大着色器线程组内的不同线程可能希望启动不同数量的网格着色器线程组。这会使 payload 中网格着色器线程组到特定元素的分配变得略微复杂。
8. 总结与展望
8.1 管线演进的全景图
传统管线:
CPU Draw Call → 输入装配器 → 顶点着色器 → [曲面细分] → [几何着色器] → 光栅化器
网格着色器管线:
CPU DispatchMesh → [放大着色器] → 网格着色器 → 光栅化器
8.2 核心收益总结
| 收益 | 详细说明 |
|---|---|
| 🎯 输入灵活性 | 不再受限于固定的顶点/索引缓冲格式,可以使用任意数据结构和压缩格式 |
| ⚡ 更高效的剔除 | 支持 Meshlet 级和图元级的早期剔除,避免无用的顶点着色 |
| 🔄 GPU 驱动的工作分配 | 通过放大着色器,LOD 选择和实例化可以完全在 GPU 端动态完成 |
| 🧩 协作式处理 | 工作组内的线程可以通过共享内存协作,比传统的"每线程处理一个顶点/图元"模型更灵活 |
| 📦 统一的编程模型 | 编程模型与计算着色器高度一致,降低了学习成本 |
8.3 需要注意的问题
| 注意事项 | 说明 |
|---|---|
| 预处理开销 | 需要将网格离线拆分为 Meshlet,增加了资产管线的复杂度 |
| 不是万能的 | 对于简单场景或几何体量小的情况,网格着色器可能并不比传统管线更快 |
| 硬件支持 | 需要较新的 GPU(AMD RDNA™ 2+、NVIDIA Turing+) |
| 跨工作组顶点复用 | 和传统管线一样,跨 Meshlet 的顶点复用问题依然存在,需要在 Meshlet 构建阶段优化 |
8.4 本文核心要点回顾
| 主题 | 关键内容 |
|---|---|
| 传统顶点管线 | 使用顶点缓冲 + 索引缓冲;通过输入装配器解析索引;顶点复用依赖图元子组机制 |
| NGG 管线 | 几何引擎将三角形分组为图元子组(类似 meshlet);顶点只在子组内复用;需要离线顶点缓存优化 |
| 传统管线痛点 | 无法直接控制顶点着色器调用和复用;缓存优化跨硬件难以通用;索引格式固定限制灵活性 |
| 网格着色器 | 类计算编程模型;开发者完全控制几何处理管线;跳过输入装配器;支持线程组内协作;映射到 NGG 图元着色器,使用快速启动模式 |
| 放大着色器 | 可选的前置阶段;GPU 端动态工作放大/缩减;支持 meshlet 裁剪、动态 LOD、程序化几何放大 |
总结一句话:网格着色器将传统管线中"固定功能输入装配 + 多个僵化着色器阶段"的设计,替换为一个灵活的、计算式的、协作式的工作组模型。开发者获得了对几何处理全流程的完全控制权,代价是需要承担更多的数据组织责任(如 Meshlet 构建)。这是 GPU 图形管线从"硬件驱动"向"软件驱动"演进的重要一步。
附录:输入装配器瓶颈分析与网格着色器的解决方案
附录 A:网格着色器的核心优势总览
网格着色器通过引入类计算着色器(Compute-like)编程模型,实现了对几何体处理流程的完全控制。其核心收益可归纳为以下三点:
| 传统管线的痛点 | 网格着色器的解决方式 |
|---|---|
| 顶点复用受限于子组划分,跨子组重复着色不可避免 | 通过离线预处理构建 Meshlet,将复用问题前置解决 |
| 输入装配器(IA)作为固定功能单元,成为管线吞吐瓶颈 | 完全跳过 IA,以 DispatchMesh 直接启动线程组 |
| 数据格式僵化,无法自定义压缩或动态生成 | 开发者自由定义数据读取方式,支持图元级剔除、几何解压缩、动态工作负载放大等高级技术 |
附录 B:输入装配器(IA)的瓶颈深度分析
B.1 索引解析与顶点去重的计算复杂性
输入装配器的核心职责是:根据索引缓冲区确定哪些顶点需要被着色,并将其组织为图元。为实现顶点复用,IA 必须执行复杂的索引解析与去重(De-duplication) 操作。这一过程带来三重开销:
(1)内存访问延迟
IA 需要先读取索引缓冲区,再根据索引查找并获取顶点数据。这至少涉及两级间接内存访问。当索引或顶点数据在显存中分布不连续,或索引缓冲区规模庞大时,将产生显著的内存带宽消耗与访问延迟。
(2)运行时去重的计算开销
在 AMD RDNA™ 的 NGG(Next Generation Geometry) 架构中,几何引擎在构建图元子组(Primitive Subgroup) 时,必须对索引进行运行时扫描以生成唯一顶点列表。这一去重检查本质上是串行或半并行操作,构成不可忽视的固定开销。
(3)子组边界导致的复用失效
理想状态下,每个顶点只需着色一次。然而,由于 IA(或 NGG)将网格强制划分为固定大小的子组进行并行处理,被不同子组同时引用的顶点将不可避免地被重复着色。这虽非 IA 自身的计算瓶颈,却是其"基于索引的绘制模型"在硬件并行化过程中产生的系统性效率损耗。
B.2 固定功能硬件对管线可扩展性的制约
作为传统图形管线的前置固定功能(或半固定功能)阶段,IA 的设计前提是标准化的顶点与索引格式。这一设计在现代 GPU 架构下暴露出三个结构性限制:
(1)数据格式僵化
IA 仅能处理 GPU 预定义的固定格式索引与顶点数据。开发者无法在数据输入端实施自定义的压缩编码、优化布局或动态数据生成策略。
(2)串行化风险
在高度并行的 GPU 架构中,任何需要执行复杂查找与决策逻辑的固定功能阶段,都可能成为流水线的串行化瓶颈。当绘制调用数量激增或图元规模庞大时,IA 的处理吞吐量可能无法匹配后续高度并行的着色器阶段,形成前端瓶颈。
(3)与现代计算架构的适配性差
现代 GPU 趋向于统一的通用计算核心(如 AMD 的 Compute Unit 或 NVIDIA 的 CUDA Core),更适合类计算着色器的并行执行模型。IA 的逐索引、逐顶点串行处理方式与这一架构范式存在根本性的映射效率问题。
附录 C:网格着色器对 IA 瓶颈的解决路径
网格着色器并非"优化"输入装配器,而是从架构层面彻底绕过了这一阶段。其解决路径可概括为三步:
| 解决策略 | 具体机制 | 对应解决的瓶颈 |
|---|---|---|
| 跳过 IA 阶段 | 使用 DispatchMesh 命令直接启动线程组,不经过输入装配器 | 消除固定功能单元的串行化风险 |
| 预处理顶点复用 | 将顶点复用与去重工作(即 Meshlet 的构建)从运行时迁移至离线预处理阶段 | 消除运行时去重的计算开销与跨子组复用失效问题 |
| 计算模型接管几何处理 | 几何体处理转变为类计算着色器模型,线程组可自由定义数据读取与输出方式 | 消除数据格式僵化限制,充分利用现代 GPU 的并行计算单元 |
本质变化:传统管线中,几何体的输入格式与分组方式由硬件(IA)决定;网格着色器管线中,这一切由开发者在着色器代码中自行定义,硬件只负责提供通用计算资源。
本附录基于原文对 AMD RDNA™ NGG 管线的描述整理,旨在为正文中的管线演进叙述提供补充性的技术细节参考。