From vertex shader to mesh shader
From vertex shader to mesh shader - AMD GPUOpen
从顶点着色器到网格着色:演进的动机
传统顶点渲染管线依赖于顶点着色器逐个处理顶点,并使用索引缓冲区实现数据复用。然而,这种基于索引的绘制方式在GPU内部通过NGG技术被分解为独立的原始子组(Primitive Subgroups)进行批处理和并行化,这在实现高效并行性的同时,也带来了顶点重复着色的问题,限制了理想的顶点复用率。这是推动向更灵活、更高性能的网格着色(Mesh Shading) 演进的主要原因。
一、传统顶点渲染管线(Vertex Pipeline)
传统网格定义与绘制流程

-
核心观点: 传统上,网格由顶点数组(Vertex Buffer)和可选的索引数组(Index Buffer)定义。为了减少数据重复,GPU通常采用索引顶点着色(Indexed Vertex Shading),即通过索引来引用顶点,形成三角形。
-
关键术语:
-
顶点缓冲区 (Vertex Buffer): 存储几何体的顶点数据(如位置、法线、UV等)。
-
索引缓冲区 (Index Buffer): 存储索引,定义了哪些顶点组成三角形(或点、线)。
-
输入装配器 (Input Assembler, IA): 负责解析索引缓冲区,并准备顶点数据以供后续着色器处理。
-
顶点着色器 (Vertex Shader, VS): 必需的几何体管线阶段,逐个顶点执行,将输入顶点从局部空间转换到裁剪空间 (Clip-space)。
-
几何体管线中的可编程阶段
 传统几何体管线由多个可编程着色器组成,它们在输入装配器之后对数据进行处理:
传统几何体管线由多个可编程着色器组成,它们在输入装配器之后对数据进行处理:
-
顶点着色器 (Vertex Shader, VS): 处理单个顶点。
-
外壳着色器 (Hull Shader, HS) / 域着色器 (Domain Shader, DS): 共同构成硬件曲面细分 (Hardware Tessellation) 的可编程阶段。
-
几何着色器 (Geometry Shader, GS): 作用于完整的图元(点、线或三角形),可以生成一个或多个新的图元。
📝 注意: 在传统管线中,顶点着色器是每条几何体管线都必需的阶段。
二、AMD NGG 技术与原始子组(Primitive Subgroups)
NGG 工作原理概述
为了在不存储所有已转换顶点的前提下实现并行处理和图元组装,AMD RDNA™ 架构引入了下一代几何体(Next Generation Geometry, NGG) 技术。
-
核心观点: NGG 的核心在于将一个绘制调用分解为独立的原始子组(Primitive Subgroups) 进行并行处理。每个子组被视为一个独立的“小网格”或 Meshlet。
-
关键术语:
-
命令处理器 (Command Processor): 接收驱动发送的绘制/调度命令。
-
几何引擎 (Geometry Engine): 负责加载索引、设置并启动顶点着色器实例。
-
双计算单元 (Dual Compute Unit): 实际执行顶点着色器的地方。
-
着色器输出 (Shader Export): 存储计算单元输出的顶点和图元信息。
-
图元装配器 (Primitive Assembler): 从着色器输出读取信息,将顶点装配成三角形,然后送往光栅化器。
-

原始子组的创建与处理
-
几何引擎从索引缓冲区中选取一个图元子集。
-
几何引擎扫描这些图元的索引,创建一个唯一顶点索引列表。
-
几何引擎将原始的索引重新索引,使其相对于这个“唯一顶点索引列表”。
-
这个由重新索引(Primitive Connectivity)和唯一顶点列表组成的对,就形成了一个原始子组 (Primitive Subgroup),概念上相当于一个Meshlet。
- 关键点: 原始子组内的顶点将被一起处理。一旦顶点处理完成,通过其原始连接性索引(即重新索引后的索引)即可装配成三角形,送往光栅化。

三、顶点复用与性能瓶颈
原始子组的限制与顶点重复着色
-
核心观点: 原始子组内的连接性索引只能引用子组内的顶点。因此,顶点复用仅限于单个子组内部。如果一个顶点被多个原始子组引用,它就会被重复着色。
-
顶点着色器调用次数 (Vertex Shader Invocations):
-
理想情况是:调用次数 = 唯一顶点数(每个顶点只着色一次)。
-
实际情况是:调用次数 唯一顶点数,重复着色会导致冗余计算,降低性能。
-
重复因子 (Duplication Factor): ,该值越接近 1.0 性能越好。
-
优化策略:顶点缓存优化 (Vertex Cache Optimization)
-
核心观点: 通过预处理网格来优化索引缓冲区的顺序,将共享相同顶点的图元聚集在一起,从而提高它们被包含在同一个原始子组的可能性,以此减少重复着色。
-
Mesh Optimizer (例如 zeux's meshoptimizer): 是一种常用的库,通过调整索引顺序来近似GPU的顶点缓存行为,最大化原始子组内部的顶点复用。
| Mesh | Optimized Mesh | |
|---|---|---|
| Vertices | 34.8k | 34.8k |
| Vertex Shader Invocations | 143.9k | 48.9k |
| Duplication Factor | 4.13 | 1.40 |
| Visualization: Different colors represent different primitive subgroups. |  | 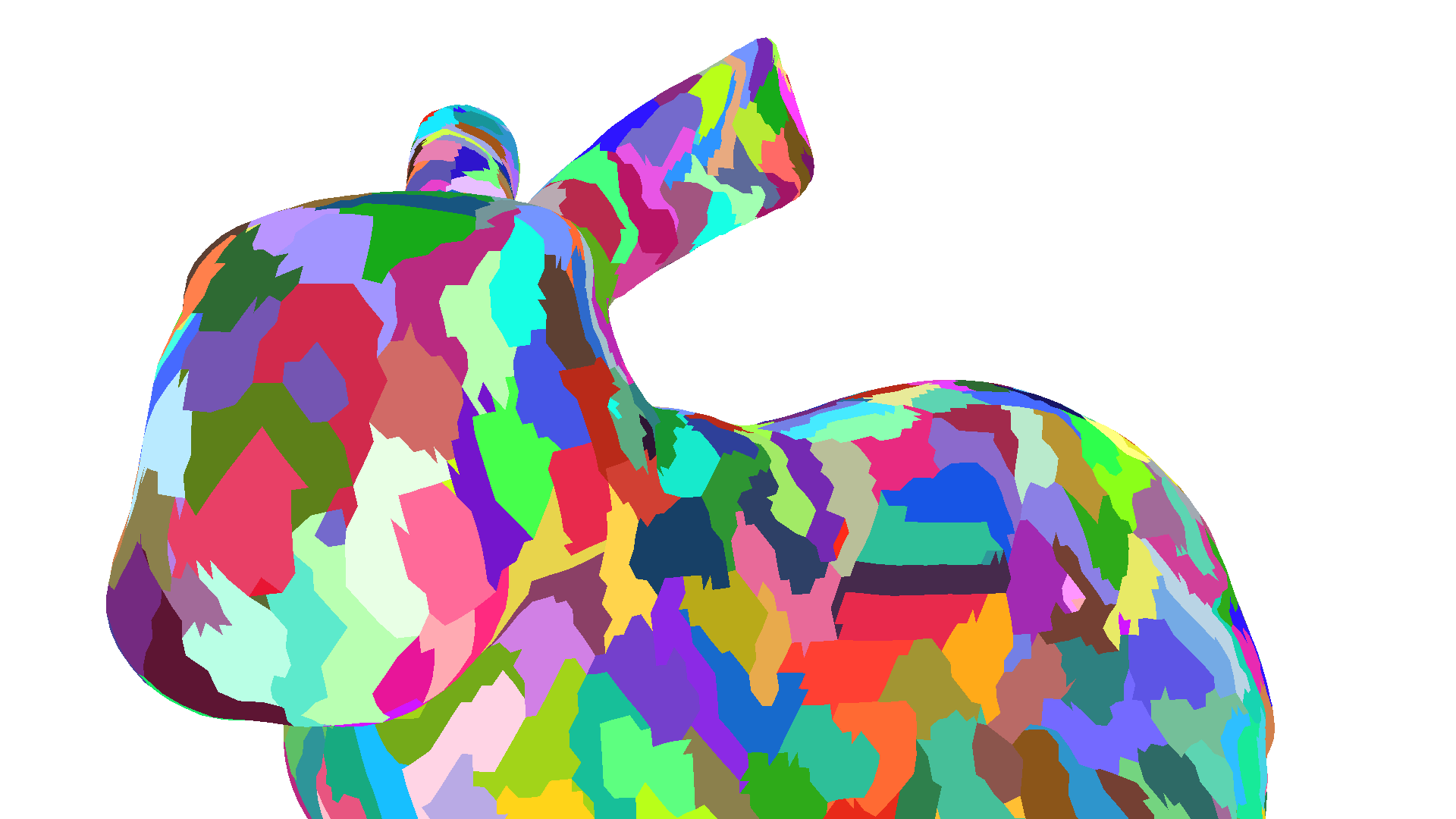 |
📝 总结: 传统顶点管线虽然通过索引复用顶点数据,但受限于 NGG 技术的原始子组边界,无法实现理想的全局顶点复用,需要通过外部的顶点缓存优化预处理来缓解重复着色问题。这是向网格着色这种能更精细、更灵活控制几何体处理流程的新范式过渡的重要驱动力。
几何体管线的现代演进:从原始着色器到网格着色器
AMD RDNA™ 架构下的 NGG(Next Generation Geometry) 管线将传统几何体功能合并到 原始着色器(Primitive Shader) 中以处理原始子组。然而,传统管线缺乏对顶点复用和图元生成的直接控制。网格着色器(Mesh Shader) 引入了类计算着色器(Compute-like) 的编程模型,取代了旧的几何体管线,赋予开发者对几何体数据和渲染工作量的完全控制,从而克服了旧管线(如顶点缓存优化复杂性、固定格式限制)的诸多限制。
一、原始着色器 (Primitive Shaders)
NGG 管线中的功能合并
-
核心观点: 原始着色器是 NGG 技术中用于处理原始子组的关键阶段,它将传统管线中顶点着色器、域着色器和几何着色器的部分功能集成在一起。
-
关键术语:
-
表面着色器 (Surface Shader): 概念上对应于旧管线的外壳着色器 (Hull Shader),在曲面细分之前运行。
-
原始着色器 (Primitive Shader): 能够直接写入着色器输出 (Shader Export) 的顶点和图元部分,从而直接送入光栅化器。
-

原始着色器的执行细节
-
执行方式: 原始着色器中的每个线程分配给一个顶点索引和一个原始图元。
-
处理流程: 线程接收图元连接性信息,加载对应的顶点数据,执行顶点着色,最后发出
exp指令将转换后的顶点和图元连接性信息导出到着色器输出。 -
灵活性: 原始着色器能修改图元连接性信息,因此可以实现曲面细分域着色器和几何着色器的功能。
传统顶点管线的限制与挑战
尽管 NGG 提高了并行性,但基于索引的顶点管线仍存在以下限制:
-
顶点复用控制权缺失: 开发者无法直接控制顶点着色器的调用和顶点复用,依赖于硬件内部的 NGG 机制。
-
顶点缓存优化复杂: 外部的顶点缓存优化(如
meshoptimizer)旨在兼容多种硬件,难以在所有 GPU 上都达到最优性能。 -
固定数据格式限制: 索引缓冲区必须遵守 GPU 理解的固定格式,限制了实现基于索引的几何体压缩等技术的灵活性。
二、网格着色器 (Mesh Shaders)

引入与核心概念
-
核心观点: 网格着色器(Mesh Shaders)是 DirectX 12 (2019) 和 Vulkan (2022) 引入的类计算着色器几何体管线,用于取代传统的几何体管线(VS/HS/DS/GS),实现了对网格小片 (Meshlets) 批处理的直接控制。
-
关键术语:
-
网格小片 (Meshlets): 一小批顶点和引用这些顶点的三角形列表,由开发者完全定义。
-
任务/放大着色器 (Task/Amplification Shader, AS): 可选阶段,用于控制启动多少网格着色器线程组。
-
网格着色器 (Mesh Shader, MS): 必需阶段,输出顶点和图元集合到光栅化器。
-
-
替代关系: Mesh/Amplification Shaders 替换了旧管线中的 VS/HS/DS/GS,不能混合使用。
类计算着色器的编程模型
-
组织结构: 网格着色器采用线程组 (Thread Groups) 组织,与现代 GPU 统一计算架构一致。
-
协作优势: 线程组内的线程可以通过 Wave Intrinsics 和组共享内存 (Group Shared Memory) 进行通信,协作计算顶点和图元。
-
输出控制: 任何线程都可以写入任何顶点或图元,实现灵活的图元生成。
调度与控制
- 调度命令: 使用
DispatchMesh命令(Vulkan 为vkCmdDrawMeshTasksEXT)以三维网格的方式直接指定要启动的网格着色器线程组数量。
graphicsCommandList->DispatchMesh(threadGroupCountX, threadGroupCountY, threadGroupCountZ);
-
跳过输入装配器:
DispatchMesh跳过了输入装配器 (IA) 阶段。-
益处: 开发者对输入数据和输出图元拥有完全控制,可以实现图元剔除和实时几何体解压缩等高级技术,并消除 IA 可能带来的管线瓶颈。
-
代价: 顶点复用计算必须作为预处理或在着色器内部完成,而不是依赖硬件运行时处理。
-
网格着色器与 NGG 的映射

-
核心观点: 网格着色器通过 NGG 架构的快速启动模式 (Fast Launch Mode) 来实现,直接将 Mesh Shader 线程组映射到 NGG 的原始子组 (Primitive Groups)。
-
流程:
DispatchMesh命令依然通过几何引擎 (Geometry Engine) 启动,但几何引擎在此时跳过了顶点去重和原始子组形成阶段,直接负责:-
跟踪和管理着色器输出的内存分配。
-
管理图元装配器的状态。
-
接收 Mesh Shader 输出的顶点和图元计数,并转发给图元装配器(因为数量在启动前未知)。
-
放大着色器 (Amplification Shaders, AS)

-
核心观点: 放大着色器是一个可选阶段,在网格着色器之前运行,用于在 GPU 上动态控制后续要启动的 Mesh Shader 线程组数量(即工作负载放大或减少)。
-
工作机制: AS 线程组可以调用
DispatchMesh着色器内在函数来启动 MS 线程组,并可以传递一个用户定义的载荷 (Payload) 给所有后续启动的 Mesh Shaders。
DispatchMesh(threadGroupCountX, threadGroupCountY, threadGroupCountZ, payload);
-
应用场景:
-
Meshlet 或实例剔除 (Culling): 根据可见性测试(如视锥体剔除)动态减少工作量。
-
动态 LOD (Level-of-Detail): 根据距离等因素选择性地启动不同细节级别的 MS 线程组。
-
几何体放大: 动态地将工作负载分配给多个 MS 线程组(例如,用于程序化几何体或细分曲面)。
-
⚠️ 限制: AS 只能调用 Mesh Shader,且只能调用一次;它只能传递单一载荷给所有被启动的 MS 线程组。
总结:Mesh Shaders 的优势
网格着色器通过引入类计算编程模型,实现了对几何体处理的完全控制,从而:
-
克服了传统管线中顶点复用受限和优化复杂的问题。
-
移除了 输入装配器 瓶颈,让管线更具可扩展性。
-
允许开发者实现图元级别的剔除、实时几何体解压缩和动态工作负载放大等高级渲染技术。
输入装配器 (IA) 的瓶颈分析
一、索引解析与顶点去重 (De-duplication) 的复杂性
-
核心观点: IA 的主要任务是根据索引缓冲区来决定哪些顶点需要被着色(即调用顶点着色器),并将其组织成图元。在这个过程中,为了实现顶点复用,IA 需要进行复杂的索引解析和去重工作。
-
瓶颈体现:
-
数据依赖与内存延迟: IA 必须读取索引缓冲区,然后根据索引去查找和获取顶点数据。这个过程涉及多次内存访问和查找,如果索引/顶点数据在内存中分布不连续,或者索引缓冲区很大,会导致大量的内存带宽和延迟消耗。
-
运行时计算开销: 在 AMD 的 NGG(下一代几何体)架构中,虽然通过原始子组(Primitive Subgroups)的机制试图将工作并行化,但几何引擎在形成子组时,需要运行时扫描索引以创建唯一的顶点列表(即执行顶点去重检查)。这个运行时检查本身就是一种串行或半并行的计算开销。
-
理想复用与实际实现之间的冲突:
-
理想情况下,一个顶点应该只被着色一次。
-
但由于 IA(或 NGG)必须将网格划分为固定大小的子组/批次进行并行处理,如果一个顶点被不同子组引用,就会导致重复着色。虽然这不是 IA 本身 的计算瓶颈,但却是 IA 这种基于索引的绘制模型在硬件并行化时带来的整体管线效率瓶颈。
-
-
二、固定功能硬件与管线可扩展性限制
-
核心观点: IA 作为一个传统的固定功能(或半固定功能)管线阶段,其设计是基于标准的顶点和索引格式,这限制了渲染管线的灵活性和可扩展性。
-
瓶颈体现:
-
数据格式僵化: IA 只能处理 GPU 定义的固定格式的索引和顶点数据。这使得开发者无法在数据输入端实现自定义的压缩、优化或动态数据生成技术。
-
串行化风险: 在高度并行的 GPU 架构中,任何固定功能的、需要执行复杂查找和决策的阶段,都可能成为串行化瓶颈,拖慢整个几何体处理流水线。特别是当绘制调用数量极多或图元数量巨大时,IA 的处理速度可能跟不上后续高度并行的着色器阶段。
-
难以适应现代 GPU 架构: 现代 GPU 趋向于统一的计算核心(如 CUDA Cores 或 Compute Units),更适合类计算着色器(Compute-like) 的并行模型。IA 作为传统管线的前置阶段,其工作方式(逐索引/逐顶点处理)与现代计算模型的映射效率不高。
-
网格着色器如何解决 IA 瓶颈?
网格着色器(Mesh Shaders) 通过以下方式彻底绕过了 IA 瓶颈:
-
跳过 IA 阶段: 使用
DispatchMesh命令直接启动线程组,完全跳过 IA。 -
预处理顶点复用: 将顶点复用和去重的工作(即 Meshlet 的创建)从运行时转移到离线预处理阶段。
-
计算模型接管: 将几何体处理转变为类计算着色器模型,使几何体处理工作更适合现代 GPU 的并行计算单元,从而消除 IA 作为一个独立固定功能单元的瓶颈。