移动 GPU 基础概述
"It's about getting the prettiest pixels from a system when you have less than 3 Watts to spend"
移动 GPU 的主要用途
3D 游戏
- 传统认知中 GPU 的核心用途,延续自桌面 PC 和游戏主机
- 移动端 3D 游戏市场持续增长,如 Fortnite 、 PUBG 、 王者荣耀 等
- 这类游戏专门针对移动端优化,追求高品质画面
2D 游戏
- 实际上,Google Play 商店中约 75% 的游戏是 2D 游戏
- 目标设备跨度大:从入门级手机到旗舰机
- 虽然图形简单,但要在低端设备上流畅运行仍面临 性能挑战
操作系统 UI 渲染
- 几乎所有移动平台的 系统 UI 都由 GPU 渲染
- Android 示例:
- 主屏幕 = 原生 3D 应用
- 动态壁纸 = 原生 3D 应用
- 系统合成器实时合成所有内容
- 同样适用于:网页浏览器加速、普通应用的 UI 框架
- 关键结论 :GPU 必须在简单 3D 图形上做到 极致能效 ,因为这类负载 全天候运行
视频与摄像头集成
- 应用场景:机顶盒(卫星/有线解码)、智能手机摄像头
- GPU 需要高效处理 视频流和相机图像
- Mali GPU 可直接访问 YUV 编码数据 ,而非仅限传统 RGB 格式
通用计算(GPGPU)
GPU 本质是 数据并行处理器 ,图形只是其擅长的并行问题之一。
| 应用领域 | 说明 |
|---|---|
| 计算机视觉 | 对图像/传感器数据运行并行算法,推断物体分类或语义 |
| 机器学习 | 神经网络归结为大规模 矩阵乘法 ,GPU 极其擅长 |
移动系统渲染管线概览
基本数据流
CPU(应用 + 图形驱动)
↓
命令 + 资源(纹理、着色器、数据)
↓
GPU
↓
完成的窗口表面(帧缓冲)
↓
显示处理器(Display Processor)
↓
屏幕输出
移动端 vs 桌面端的关键区别
| 方面 | 桌面 PC | 移动端 |
|---|---|---|
| 显示处理器 | 集成在 GPU 内部 | 独立 IP 模块 ,通常由不同公司开发 |
| Mali GPU 职责 | — | 仅负责渲染,将窗口写回 主内存 |
| 显示输出 | GPU 直接驱动 | 由另一个硬件模块从内存读取并输出到屏幕 |
核心概念 :移动端 GPU(如 Mali)与显示处理器解耦,GPU 渲染结果先写回内存,再由显示模块读取——这一架构对理解后续的 Tile-Based Rendering 至关重要。
GPU 自主命令生成能力
现代 GPU 的自主性演进
资源自生成
- GPU 可以 渲染到纹理(Render to Texture),实现复杂的渲染管线
- 支持 有趣的后处理效果,全部由 GPU 自行完成
命令流修改
| 技术 | 说明 |
|---|---|
| Draw Indirect | GPU 可修改 CPU 提交的任务参数 |
| Multi-Draw Indirect | 批量间接绘制,进一步减少 CPU 干预 |
- 当前限制:API 尚未完全通用化,GPU 只能填充 CPU 提供的 绘制模板 的部分字段
- 发展趋势:GPU 自主命令提交能力持续增强,CPU 可卸载更多工作,降低 CPU 负载
桌面 vs 移动:功耗鸿沟
桌面游戏 PC 的功耗特征
| 参数 | 典型值 |
|---|---|
| 系统功耗 | 200–400 瓦 (CPU + GPU + DRAM) |
| 散热能力 | 80–160 CFM(立方英尺/分钟)气流 |
| 散热手段 | 大型散热片、水冷、多风扇 |
核心原理:每瓦输入功率 = 等量废热输出。高功耗必须匹配强力主动散热。
移动设备的物理约束
SoC 封装结构
┌─────────────────┐
│ DRAM Die │ ← 内存芯片
├─────────────────┤
│ Logic Die │ ← CPU、GPU、加速器
│ (CPU+GPU+Accel) │
└─────────────────┘
Package-on-Package (PoP)
- 优点:PCB 简化、布线更少、效率更高
- 致命缺点:所有发热大户 集中在一处
散热劣势
| 因素 | 影响 |
|---|---|
| 无主动散热 | 无风扇、无散热片 |
| 外壳材质 | 玻璃/塑料 = 热绝缘体 |
| 保护壳 | 皮革/塑料壳进一步隔热 |
移动端热预算
- 仅为桌面 PC 的约 1%
- 形象比喻:比一个 5W LED 节能灯泡 还要少一半!
移动 SoC 渲染子系统架构
CPU 异构设计(big.LITTLE 及其演进)
核心类型
| 类型 | 特点 | 数量(典型) |
|---|---|---|
| Big 核 | 物理尺寸大、 单线程性能最高 | 1–2 |
| Medium 核 | 性能/能效平衡 | 2 |
| Little 核 | 小巧、 最省电 、峰值性能低 | 4–6 |
| Prime 核(最新) | 单核极高频率,专攻极端单线程负载 | 1 |
调度策略
- 操作系统根据 负载需求 动态分配任务:
- 轻负载 → Little/Medium 核
- 重单线程负载 → Big/Prime 核
缓存层级
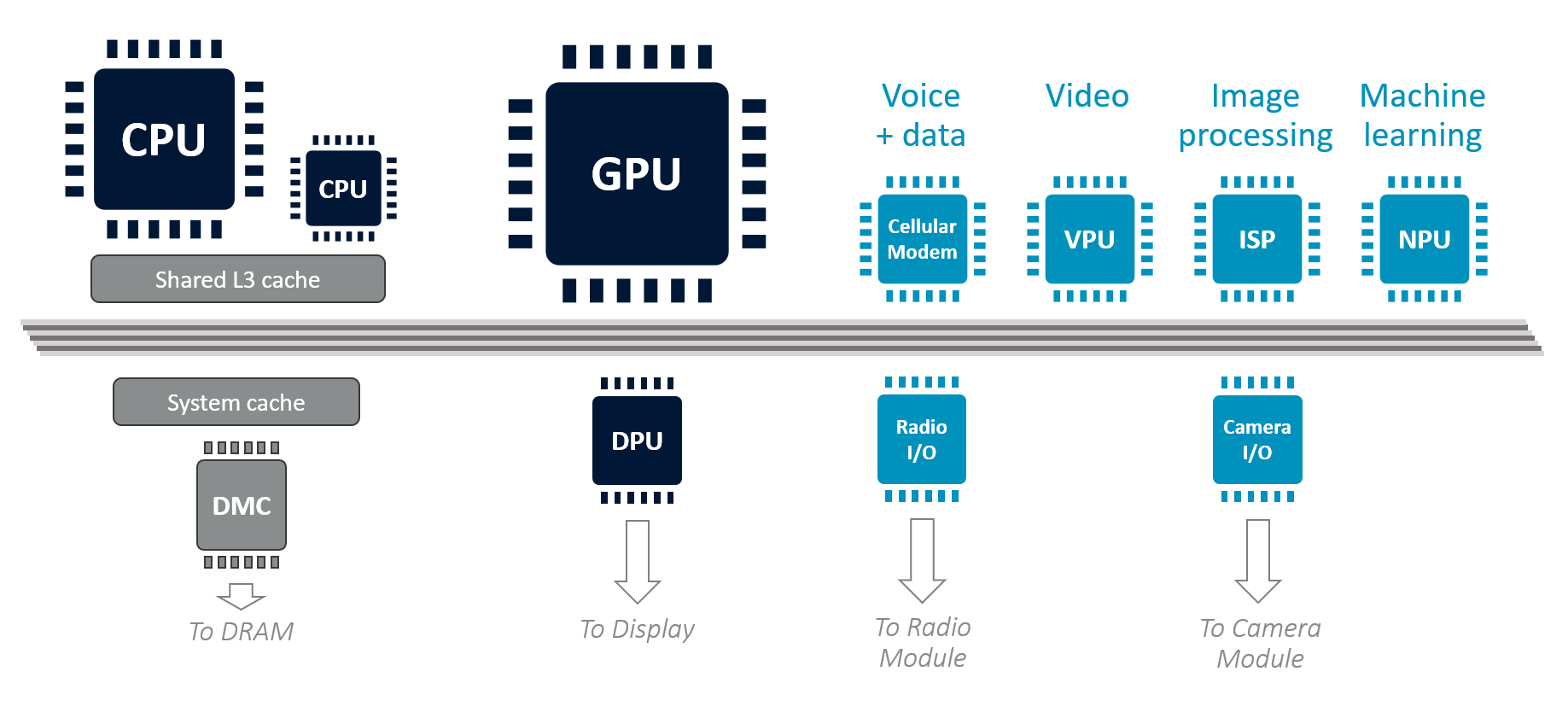
- L3 缓存:所有 CPU 核心共享,提供一致性后端
- System Cache:位于所有 IP 与 DRAM 之间(取决于芯片厂商设计)
显示处理器(Display Processor)
为何叫"处理器"而非"控制器"
现代显示处理器具备 独立图像处理能力:
| 功能 | 说明 |
|---|---|
| 旋转 | 画面方向调整 |
| 缩放 | 分辨率变换 |
| 多层合成 | 例如 Android 主屏图标层 + 背景壁纸层 |
| 色彩转换 | YUV → RGB 等 |
硬件限制与回退机制
显示处理器受 硬实时约束(必须匹配屏幕刷新率),当任务超出能力时:
- 层数过多
- 分辨率过高
- 需要过多旋转/色彩转换
→ 回退到 GPU 软件合成,生成扁平化表面再交给显示控制器
Vulkan 中的注意事项
- 应用直接控制 屏幕旋转 等参数
- 最佳实践:确保提交给显示控制器的内容在其能力范围内
- 代价:不当配置导致 GPU 回退合成 → 浪费宝贵的功耗预算在无附加值的工作上
DRAM 访问:移动端最大的功耗黑洞
内存带宽的能耗代价
经验公式
- 误差范围约 ±30%(取决于制程和 DRAM 技术)
- 示例:5 GB/s 流量 ≈ 消耗 0.5W
实际约束
| 总功耗预算 | 可用 DRAM 带宽上限 |
|---|---|
| 2–3 W | 5–7 GB/s(持续) |
超出此范围会挤占 CPU/GPU 的功耗预算。
完整 SoC 功耗分配示例
各模块竞争同一预算
┌─────────────────────────────────────┐
│ Total Power Budget: 2.5 W │
├────────────────┬────────────────────┤
│ DRAM Bandwidth │ 0.5 W (≈5 GB/s) │
│ CPU │ 0.75 W │
│ GPU │ 1.25 W │
│ DPU (Display) │ Low power, but │
│ │ bandwidth counted │
│ │ under DRAM │
└────────────────┴────────────────────┘
域专用加速器(共享功耗)
| 加速器 | 功能 |
|---|---|
| Modem | 语音/数据通信 + 射频 IO |
| Video Codec | 视频编解码 |
| ISP | 相机原始数据处理 |
| NPU/DSP | 机器学习推理 |
| GPS | 定位 |
关键洞察:玩《Pokémon GO》时,相机 + GPS + 网络同时工作,可能吃掉 0.5–1W,留给渲染的预算骤降!
频率-电压-功耗曲线:移动优化的核心
典型 Big Core 功耗曲线
功耗 (W)
↑
│ ╱ 超频区(陡峭)
│ ╱
│ ╱ ← 标称频率(Nominal)
│ ╱ ~750 mW @ 14 性能点
│ ╱
│ ╱ 降频区(平缓)
│╱
└─────────────────────→ 性能
| 工作点 | 特性 |
|---|---|
| 超频 | 曲线陡峭 → 性能微增,功耗暴涨 |
| 标称 | 设计参考点(如 0.75V) |
| 降频 | 曲线平缓 → 性能略降,能效显著提升 |
能效视角:为何要多核?
能效 = 性能 / 功耗
| 频率 | 绝对性能 | 能效(性能点/瓦) |
|---|---|---|
| 最高频 | 最高 | ~13 |
| 标称频 | 14 | ~18 |
| 半频 | 7 | ~35(提升 ~95%!) |
结论
为何手机有 8 核:多线程并行 → 每核可降频运行 → 整体能效更高
效率 vs 效能:优化的哲学
Peter Drucker 的经典论断
"Efficiency is doing things right. Effectiveness is doing the right things."
效率是把事情做对,效能是做对的事情。
应用于图形优化
| 误区 | 正确思路 |
|---|---|
| 死磕 Shader 微优化 | 先审视 算法是否正确 |
| 榨干现有管线 | 考虑 管线架构本身 是否合理 |
错误的算法实现得再好也没用——优化要从全局视角出发。
渲染管线速览
三阶段流程
┌────────┐ ┌───────────┐ ┌──────────┐
│ Vertex │ ──→ │ Rasterize │ ──→ │ Fragment │
└────────┘ └───────────┘ └──────────┘
顶点处理
- 输入: 网格(Mesh) ——物体的"无限薄表皮",内部是空的
- 任务:每帧将每个顶点 动画/变换 到屏幕位置
光栅化
- 将三角形的 矢量形式 转换为 像素覆盖
- 决定哪些像素需要着色
片元着色
- 对每个光栅化后的像素运行 Fragment Shader
- 应用材质、光照、纹理等 → 最终画面效果
图形渲染管线详解
管线核心思想
顶点输入 ──→ 几何处理 ──→ 光栅化 ──→ 片元着色 ──→ 帧缓冲输出
│ │ │ │
大量顶点 屏幕空间三角形 像素覆盖 像素上色
核心目标:尽可能快地处理海量顶点、填充海量像素。移动端通常只使用基础阶段。
完整管线架构
四大模块
| 模块 | 职责 |
|---|---|
| CPU | 应用逻辑、提交命令 |
| 命令处理器 | 解析驱动发来的 GPU 指令 |
| 几何处理 | 网格数据 → 屏幕空间三角形 |
| 像素处理 | 屏幕三角形 → 像素着色 |
资源上传流程
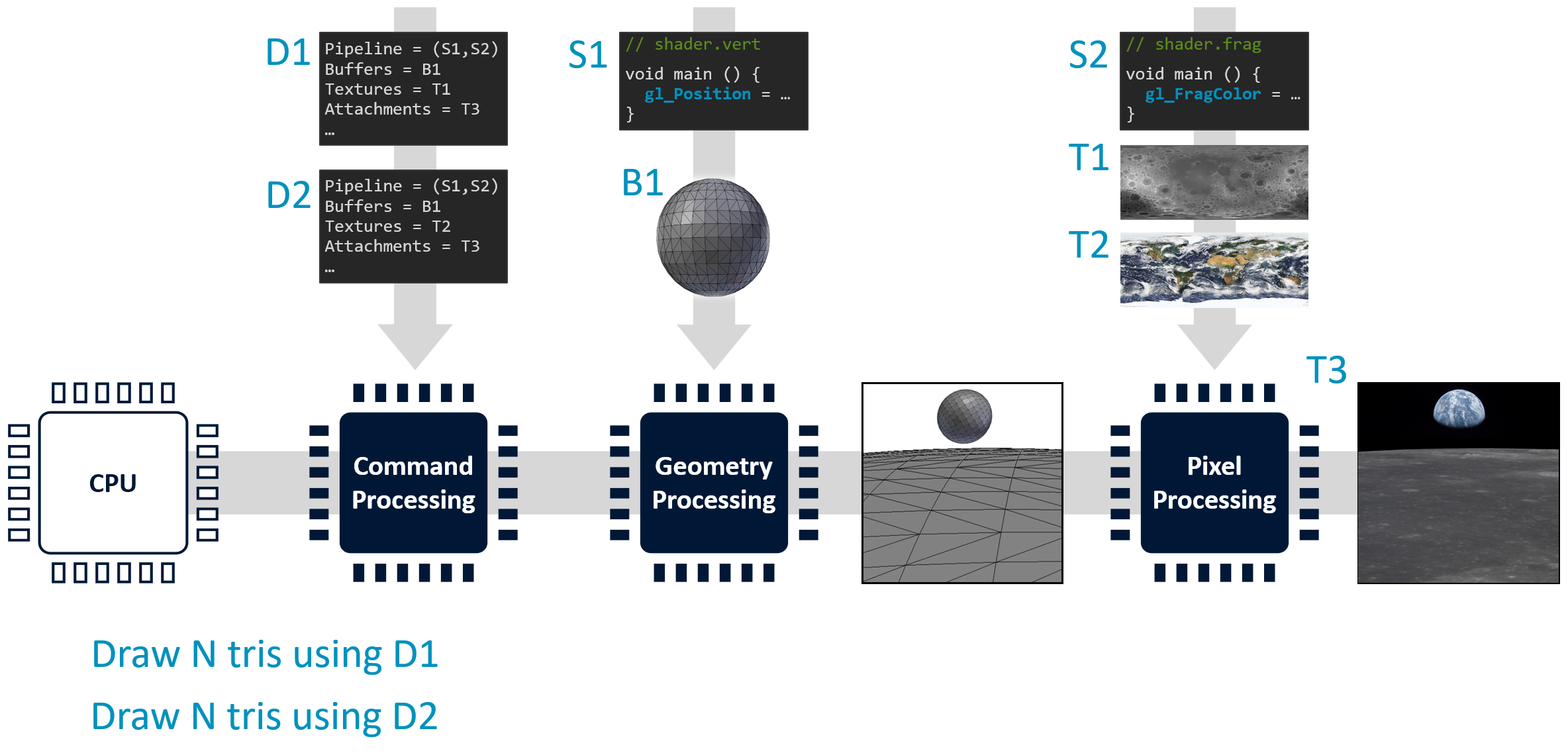
1. 上传资源
├─ 着色器程序
├─ 缓冲区 / 纹理
├─ 参数(混合开关、深度测试等)
└─ 描述符集(Descriptor Set)
描述符 = C 结构体
└─ 资源位置指针
↓
2. CPU 提交 Draw Call
"用描述符集 1 绘制 N 个三角形"
典型渲染帧
- 每帧约 1000 次 Draw Call
- 每次 Draw Call:命令处理 → 几何处理 → 像素处理
计算着色器(Compute Shader)
独立于渲染管线
┌─────────────────┐
│ Main Memory │
│ (Input/Output) │
└─────────────────┘
↓
┌─────────────────┐
│ Compute Shader │ ← 通用并行处理
└─────────────────┘
↓
Buffer / Texture
- 输入:可来自任意阶段
- 输出:可被任意阶段读取
- 特点:不属于固定功能管线,但 极其重要
几何处理阶段详解
阶段构成
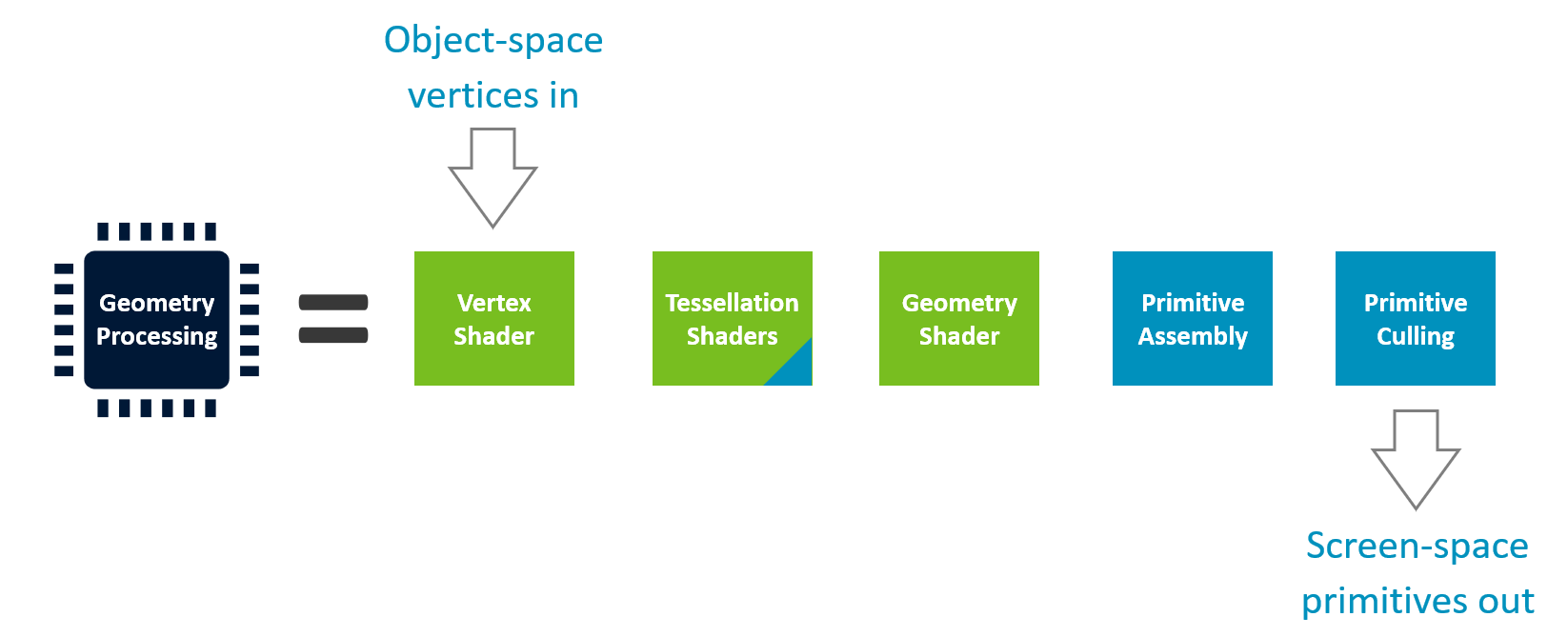
| 颜色标识 | 含义 |
|---|---|
| 绿色 | 应用程序可编程(Shader) |
| 蓝色 | 固定功能,仅可配置参数 |
各阶段功能
顶点着色器(Vertex Shader)
- 职责:物体空间 → 屏幕空间变换 + 逐顶点计算
- 必经阶段,无法跳过
曲面细分(Tessellation)
| 特性 | 说明 |
|---|---|
| 结构 | 2 个着色阶段 + 1 个固定功能细分器 |
| 功能 | 将粗糙 Patch 细分为更多三角形 |
| 优点 | 可改变物体 轮廓边缘 |
| 缺点 | 非常昂贵,难以正确使用 |
| 移动端现状 | 几乎不用(仅在 Benchmark 中见过) |
⚠️ 曲面细分与 Tile-Based 架构 配合不佳
几何着色器(Geometry Shader)
| 特性 | 说明 |
|---|---|
| 功能 | 每次调用可输出 多个图元 |
| 历史用途 | 粒子系统、爆炸、烟雾等 |
| 现代建议 | 不要使用! |
为何弃用?
- 设计缺陷导致 三角形重复
- 效率极低
- 替代方案:用 Compute Shader 实现相同功能
移动端实际内容中 从未见过 几何着色器(仅 Benchmark)
管线优化:裁剪提前
规范定义 vs 实际实现
问题:OpenGL/Vulkan 规范将 Culling 放在最后
顶点着色 → 曲面细分 → 几何着色 → 图元装配 → 【裁剪】
↑
所有工作都做完了,
才发现三角形不可见!
Mali 现代架构优化
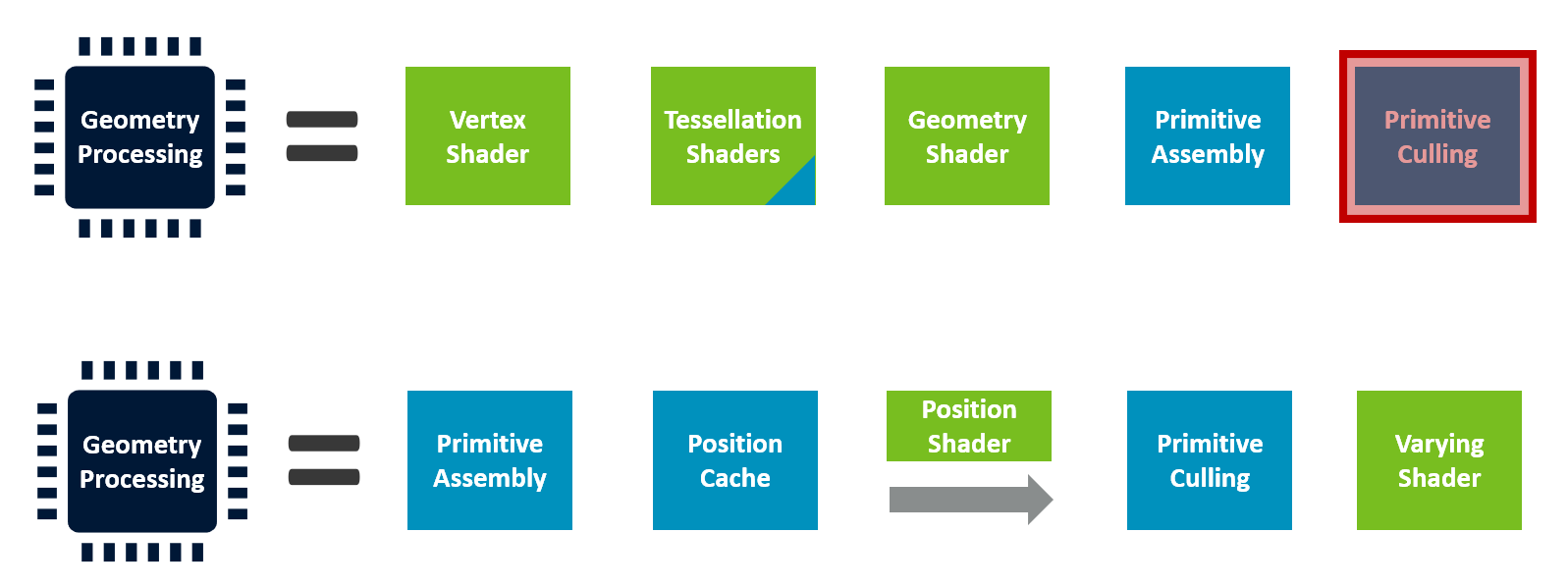
顶点着色器拆分:
Part 1: 仅计算 Position
↓
【裁剪 & 剔除】 ← 提前执行!
↓
Part 2: 计算其他逐顶点数据(仅对可见三角形)
效率收益
| 场景 | 收益 |
|---|---|
| 良好应用(~50% 在视锥外) | Part 2 只跑 一半顶点 |
| 较差应用(更多视锥外物体) | 收益 更大 |
这是 通用硬件优化,非 Mali 独有。核心原则:裁剪越早越好。
像素处理阶段
阶段构成
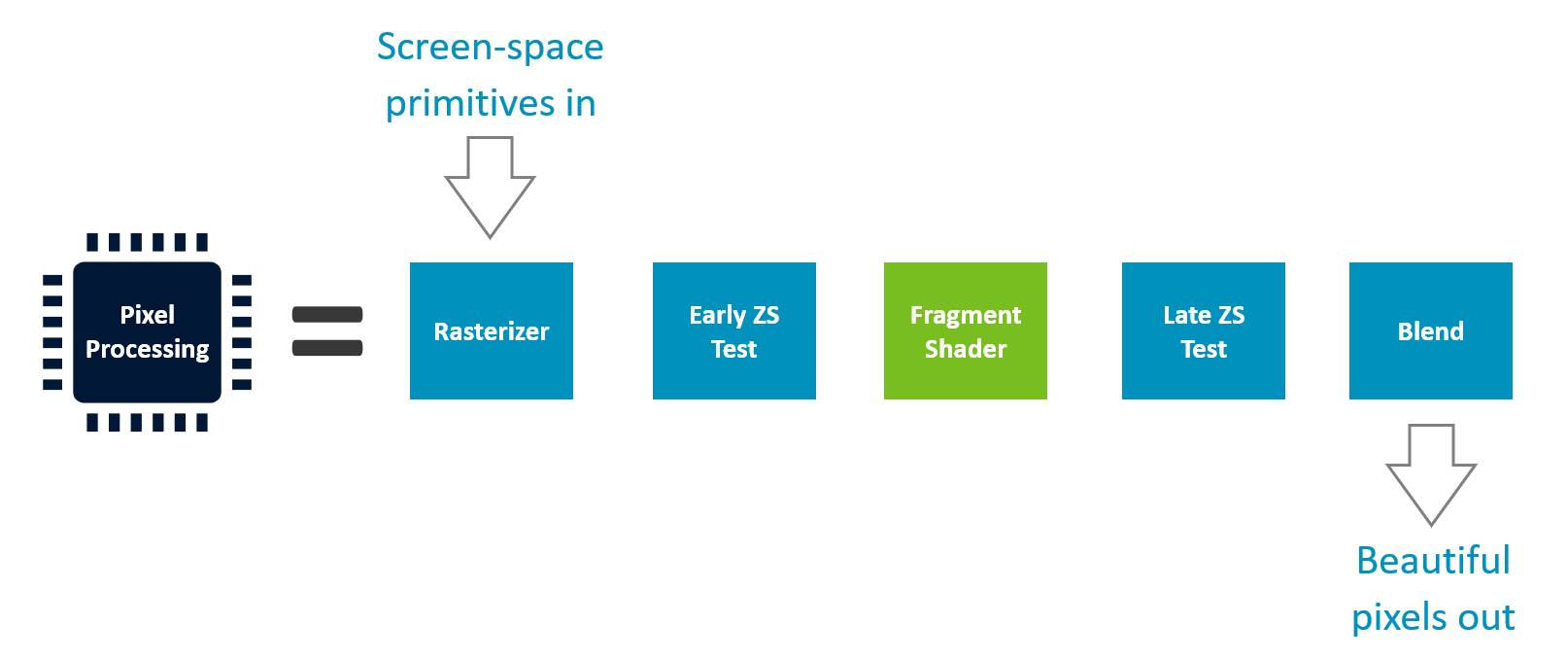
ZS 测试双层结构
| 测试 | 时机 | 作用 |
|---|---|---|
| Early ZS | 片元着色 之前 | 尽早剔除不可见片元,节省着色开销 |
| Late ZS | 片元着色 之后 | 处理 Shader 中修改深度的情况 |
关键优化点:尽量让 Early ZS 生效,避免无效着色。
像素处理阶段详解
光栅化(Rasterization)
基本原理
- 将 矢量三角形 转换为 离散采样点(像素)
- 测试三角形覆盖了哪些像素采样点
Quad:2×2 像素块
┌───┬───┐
│ P │ P │ ← 一个 Quad = 4 个像素
├───┼───┤ 始终以此为最小单位处理
│ P │ P │
└───┴───┘
为何必须用 Quad?
- 提供 导数信息 、
- 用于 Mipmap 级别选择(纹理采样需要知道像素间变化率)
小三角形的效率问题
| 覆盖情况 | 实际像素 | 消耗资源 |
|---|---|---|
| 完整 Quad | 4 | 4 |
| 部分 Quad(仅 1 像素) | 1 | 4(浪费 75%!) |
示例:
三角形实际覆盖:10 像素
因 Partial Quads:消耗 20 像素的资源
→ 50% 效率损失
核心结论:小三角形代价极高
- 顶点数据更多(覆盖相同面积需更多三角形)
- 顶点开销摊分到更少片元
- Partial Quads 导致 线程利用率下降
深度/模板测试(ZS Test)
Early ZS(早期深度测试)
光栅化 ──→ ██ Early ZS ██ ──→ 片元着色
↓
被遮挡片元提前剔除
| 条件 | 效果 |
|---|---|
| 前向后渲染 不透明物体 | 遮挡片元被 直接跳过 ,省去着色开销 |
| 后向前渲染 | Early ZS 失效 → 严重 Overdraw |
最佳实践:不透明物体 从近到远 排序渲染!
Late ZS(后期深度测试)
何时需要 Late ZS?
- 片元着色器 写入深度值(
gl_FragDepth) - Alpha Test(如树叶镂空)
// 示例:Alpha Test
void main() {
float alpha = texture(tex, uv).a;
if (alpha < 0.5) discard; // ← 此时才知道是否丢弃
// ...
}驱动优化:提前触发 Late ZS
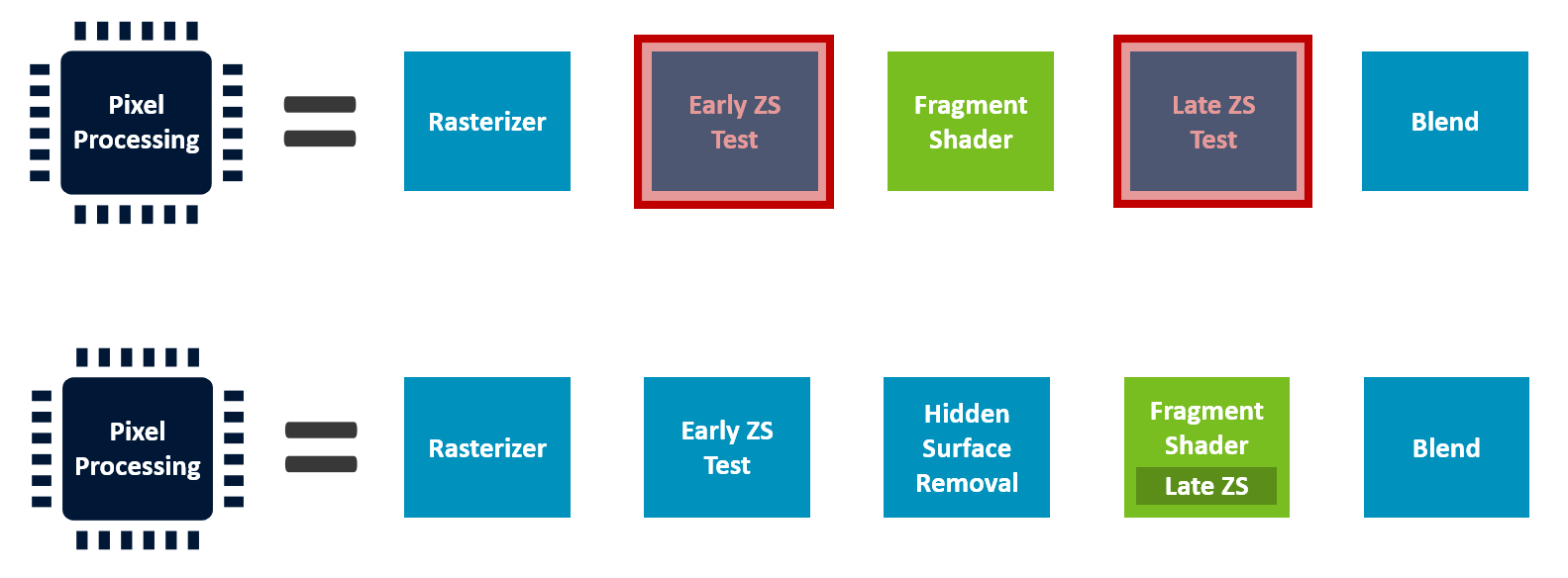
片元着色器
├─ 读取 Alpha
├─ 判断 discard ──→ 触发 Late ZS ──→ 剔除
└─ 剩余计算(若被剔除则跳过)
无需等整个 Shader 跑完,尽早剔除 减少浪费。
隐藏面消除(Hidden Surface Removal, HSR)
微架构级优化
- 非标准化:各 GPU 厂商自有实现(Arm、Qualcomm、Apple 等)
- 目标:消除 Early ZS 无法架构性处理的遮挡
| Early ZS 的局限 | HSR 的补充 |
|---|---|
| 依赖渲染顺序 | 可在更早阶段剔除 |
| 无法处理乱序提交 | 硬件级重排/缓存 |
管线并行与瓶颈分析
理想流水线
时间 →
┌─────────────────────────────────────────────────┐
│ CPU: [DC1][DC2][DC3][DC4][DC5]... │
│ Geom: [DC1][DC2][DC3][DC4]... │
│ Pixel: [DC1][DC2][DC3]... │
└─────────────────────────────────────────────────┘
↑
稳态:三阶段并行工作
好处:
- 硬件利用率最大化
- 可在 最低频率 下运行 → 最佳能效
管线阻塞:glFinish 的灾难
时间 →
┌─────────────────────────────────────────────────┐
│ CPU: [DC1]█████████████[DC2]█████████████... │
│ Geom: [DC1] [DC2] │
│ Pixel: [DC1] [DC2] │
└─────────────────────────────────────────────────┘
↑ ↑
glFinish glFinish
(CPU 等待) (CPU 等待)
| 问题 | 影响 |
|---|---|
| 管线排空 | CPU 必须等待所有 GPU 工作完成 |
| 串行执行 | 无并行 → 吞吐量骤降 |
避免:
glFinish及类似的同步调用(除非调试)
瓶颈识别
场景:CPU Bound
时间 →
┌─────────────────────────────────────────────┐
│ CPU: [██████][██████][██████][██████] │ ← 100% 忙碌
│ GPU: [ ][ ][ ][ ][ ][ ][ ][ ] │ ← 出现空闲
└─────────────────────────────────────────────┘
诊断:
- CPU 始终满载
- GPU 在几何/像素处理间出现 空闲间隙
- 结论:CPU 是瓶颈,优化重点在应用层
瓶颈类型总结
| 瓶颈位置 | 表现 | 优化方向 |
|---|---|---|
| CPU Bound | GPU 有空闲 | 减少 Draw Call、批处理、多线程命令录制 |
| Geometry Bound | 像素阶段等待 | 减少顶点数、简化顶点着色器 |
| Pixel Bound | 几何阶段等待 | 降分辨率、简化片元着色器、减少 Overdraw |
| 带宽 Bound | 全阶段都慢 | 压缩纹理、减少 Render Target 切换 |
管线瓶颈识别
核心原则
- 其他阶段在最慢阶段的"阴影"中并行运行
- 优化方向:找到并解决瓶颈阶段
工具价值:Mobile Studio 等性能分析工具的核心能力就是 识别瓶颈阶段
GPU 架构概览
核心处理模块
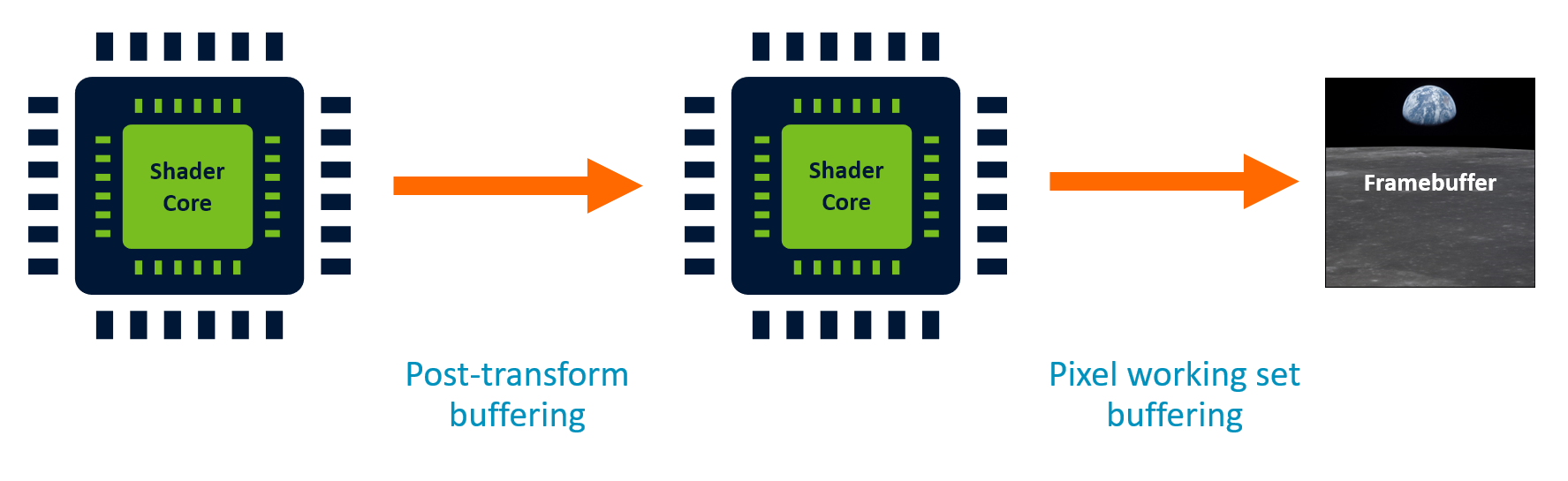
关键设计问题
| 问题 | 影响 |
|---|---|
| 后变换缓冲 | 几何输出存哪?如何传给像素阶段? |
| 帧缓冲工作集 | ZS 测试、混合、MSAA 的热数据存哪? |
厂商差异点:不同 GPU 的"胶水"设计是主要区分因素
立即模式渲染器(Immediate Mode Renderer, IMR)
历史背景
- 软件渲染器时代(80 年代末–90 年代初)的经典设计
- 代表硬件:3DFX Voodoo(早期消费级 3D 显卡)
工作原理
处理顺序
Draw Call 1: 三角形 1 → 2 → 3 → ...
Draw Call 2: 三角形 1 → 2 → 3 → ...
↓
严格按应用提交顺序逐个处理
关键特征
任意三角形可触及屏幕任意位置
- 无空间局部性假设
- 渲染绿色条纹时,需重新加载已渲染的蓝色背景区域
IMR 管线结构
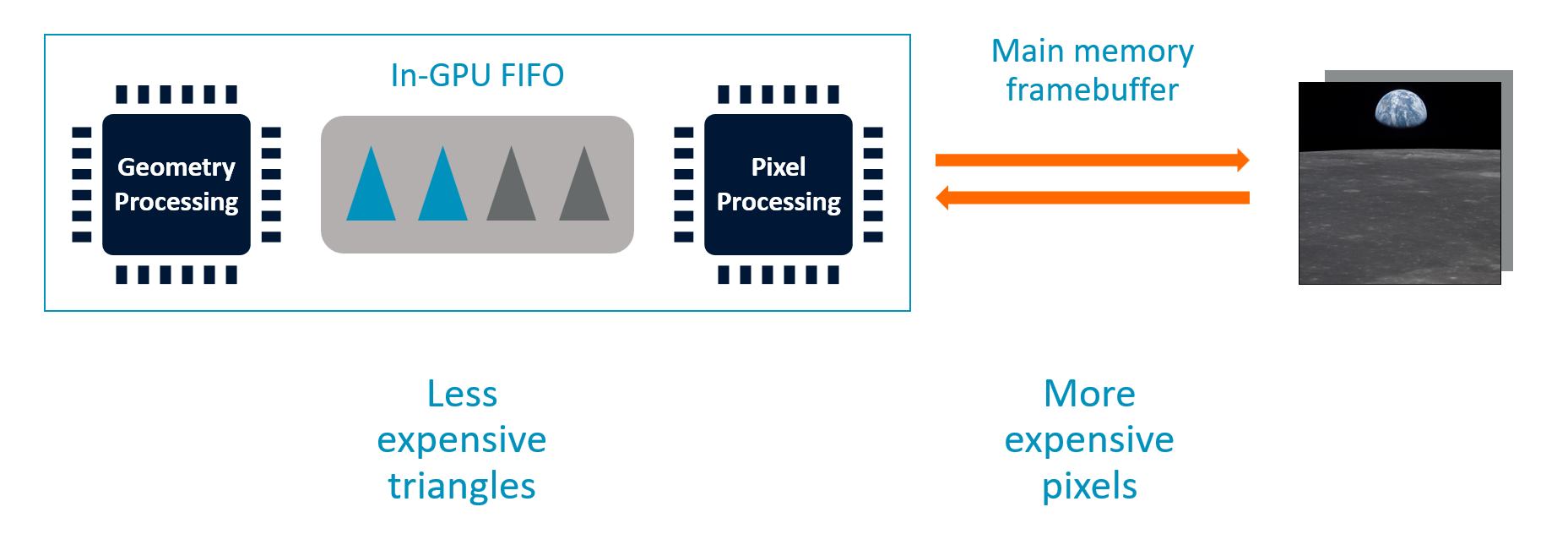
FIFO 缓冲机制
| 情况 | 行为 |
|---|---|
| FIFO 满 | 几何处理 暂停 ,等待空间 |
| FIFO 有空间 | 几何处理继续 |
帧缓冲存储
- 帧缓冲 必须存于主内存(数十 MB:颜色 + 深度 + 模板)
- 每个三角形可能访问任意位置 → 频繁 内存往返
IMR 的权衡
| 方面 | 成本 |
|---|---|
| 三角形 | ✅ 便宜 — 数据留在片上 FIFO |
| 像素 | ❌ 昂贵 — 反复访问主内存 |
像素成本来源
- ZS 测试:读取深度值
- 混合:读取目标颜色
- MSAA:多采样点读写
可通过 帧缓冲压缩 和 缓存 缓解,但无法根本消除
IMR 的延迟特性
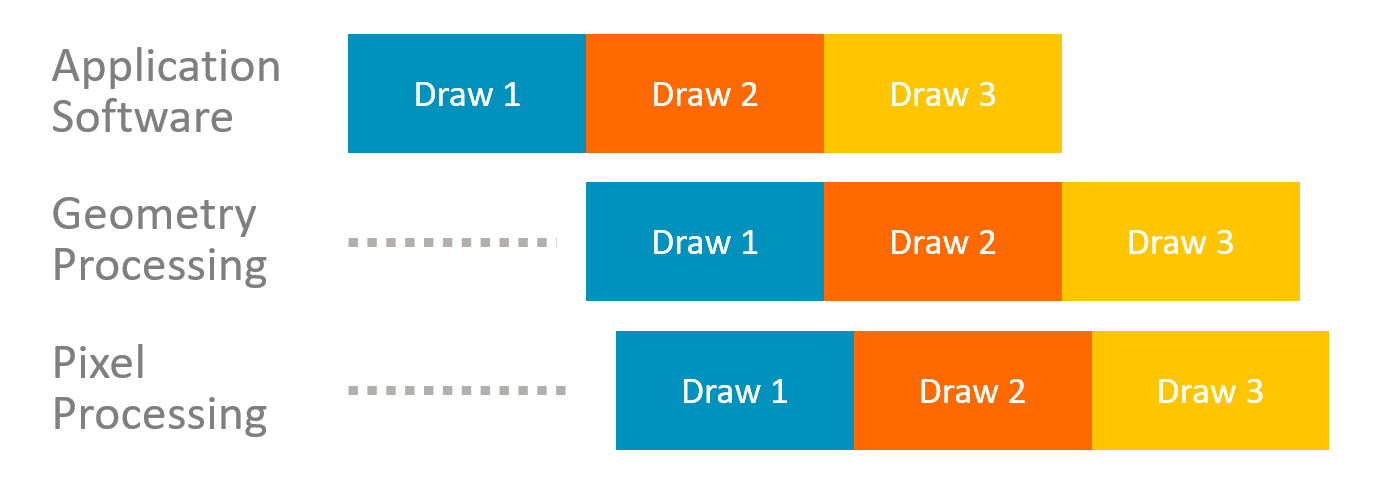
Time →
┌──────────────────────────────────────────────────────────┐
│ Draw Call: [Submit] │
│ Geometry: [Process] │
│ FIFO: [First Triangle Enqueued] │
│ Pixel: [Start Immediately] │
└──────────────────────────────────────────────────────────┘
优势
- 极低延迟:首个三角形进入 FIFO 即可开始像素处理
- 紧密流水:几何与像素阶段高度重叠
- 甚至 同一 Draw Call 内部 也能重叠
小结:IMR 适用场景
| 优势 | 劣势 |
|---|---|
| 低延迟、紧密流水 | 帧缓冲带宽消耗大 |
| 三角形开销低 | 多层渲染时 Overdraw 严重 |
下一节预告:Tile-Based Rendering(TBR)如何解决 IMR 的带宽问题
分块渲染器(Tile-Based Renderer, TBR)
核心设计思想
Screen Divided into Tiles
┌─────┬─────┬─────┬─────┬─────┬─────┬─────┬─────┐
│16×16│ │ │ │ │ │ │ │
├─────┼─────┼─────┼─────┼─────┼─────┼─────┼─────┤
│ │ │ │ │ │ │ │ │ ← 每个Tile独立渲染至完成
├─────┼─────┼─────┼─────┼─────┼─────┼─────┼─────┤
│ │ │ │ │ │ │ │ │
└─────┴─────┴─────┴─────┴─────┴─────┴─────┴─────┘
Mali GPU 使用 16×16 像素 Tile(其他厂商 Tile 尺寸可能不同)
两阶段分离管线
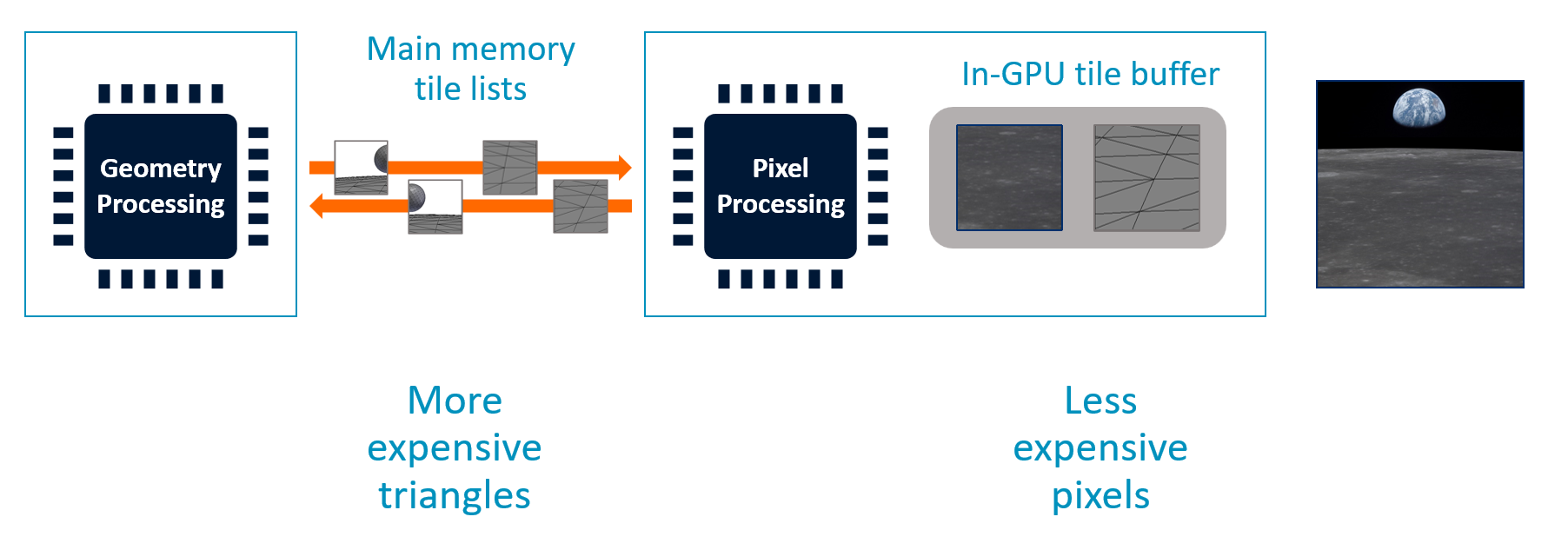
┌───────────────┐ ┌─────────────┐ ┌───────────────┐
│ Geometry │ │ │ │ Pixel │
│ Processing │──Write─→│ Main Memory │──Read─→ │ Processing │
│ (All Finished)│ │ │ │ (Per Tile) │
└───────────────┘ │• Vertex Data│ └───────────────┘
│• Tile List │ ↓
└─────────────┘ ┌───────────────┐
│ Tile RAM │
│ (On-chip HW) │
└───────────────┘
Tile List 结构
| Tile 坐标 | 关联三角形 ID |
|---|---|
| (0, 0) | △1, △5, △23, ... |
| (0, 1) | △2, △5, △8, ... |
| ... | ... |
必须先完成全部几何处理 → 才能知道每个 Tile 涉及哪些三角形
Tile RAM:像素效率的关键
存储内容
| 数据类型 | 说明 |
|---|---|
| 颜色 | RGBA |
| 深度 | Z 值 |
| 模板 | Stencil |
| 多采样 | MSAA 采样点 |
瞬态附件(Transient Attachments)
渲染过程:
深度缓冲 → 用于 ZS 测试
↓
Tile 完成:
✅ 颜色 → 写回主内存
❌ 深度 → 直接丢弃(不写回!)
功耗节省:无需持久化的数据(如临时深度)可完全避免内存写入
TBR 的优势
零带宽操作
| 操作 | IMR | TBR |
|---|---|---|
| ZS 测试 | 读写主内存 | ✅ 零带宽 |
| 混合(Blending) | 读写主内存 | ✅ 零带宽 |
| MSAA 4× | 4× 内存开销 | ✅ 零额外带宽 |
其他优势
- 瞬态内存:Vulkan 可不分配物理 RAM
- HSR 更高效:Tile 内遮挡消除效果更好
- 跳过未修改 Tile:无变化则不写回
- Tile 内着色优化:空间局部性极佳
TBR 的代价
三角形成本翻倍
IMR: 顶点 ──→ [片上 FIFO] ──→ 光栅化
│
始终在片上
TBR: 顶点 ──→ 几何处理 ──→ [写回主内存] ──→ [再读回] ──→ 光栅化
↑ ↑
额外写入 额外读取
曲面细分 / 几何着色器的困境
| 技术 | IMR 表现 | TBR 表现 |
|---|---|---|
| 曲面细分 | ✅ 展开数据留在 FIFO | ❌ 展开后写回主内存 |
| 几何着色器 | ✅ 同上 | ❌ 同上 |
这就是为何移动端很少使用曲面细分——原本为 IMR 设计的技术在 TBR 上代价极高
其他代价
- 需分配 后变换存储缓冲(驱动管理)
- 更粗粒度流水线:以 Render Pass 为单位
- 更严格的 API 要求:正确使用才能获得 Render Pass 重叠
流水线行为对比
IMR:Draw Call 级流水
DC1: [Geom][Pixel]
DC2: [Geom][Pixel]
DC3: [Geom][Pixel]
← 低延迟,细粒度 →
TBR:Render Pass 级流水
RP1: [====== Geom ======][====== Pixel ======]
RP2: [====== Geom ======][====== Pixel ======]
← 高延迟,但仍可重叠 →
正确使用 API 是获得 Render Pass 重叠的前提!
为何移动端选择 TBR?
移动内容特征
| 特征 | 影响 |
|---|---|
| 大量 2D UI / 图层 | 像素开销为主 |
| 休闲游戏 | 几何量少 |
| 轻量 3D(<25 万三角形/帧) | 三角形开销可接受 |
| MSAA 需求 | TBR 零额外带宽 |
核心结论
手机 UI 全天候运行——像素能效决定续航!
架构谱系:并非非此即彼
◀───────────────── Architecture Spectrum ─────────────────▶
│ │
│ IMR TBR │
│ (Classic Desktop) (Classic Mobile) │
│ │
│ ●──────────────────●──────────────────● │
│ │ │ │ │
│ 3DFX Adreno Mali │
│ Voodoo (Larger Tiles) (Strict TBR) │
│ │
│ Modern Desktop GPUs are adopting │
│ Speculative Tilebased tech │
| 实现 | 特点 |
|---|---|
| Mali | 严格 TBR,Render Pass 前后经主内存 |
| Adreno | 更大 Tile,可能有混合策略 |
| 现代桌面 GPU | 开始借鉴 TBR 技术(如软件分块) |
没有绝对优劣——设计选择取决于目标工作负载!
GPU Shader Core 架构:从 CPU 演进理解
CPU 的问题域
特征
| 维度 | CPU 特点 |
|---|---|
| 线程数 | 低(16–32 线程) |
| 程序类型 | 长程序、控制流代码 |
| 优化目标 | 单线程延迟 |
核心挑战:让少量线程跑得更快
对内存延迟极度敏感
Cache Miss 发生:
CPU 等待 ~200 周期
↓
没有其他工作可填充空闲
↓
性能严重下降
CPU 的流水线与延迟隐藏
基础流水线
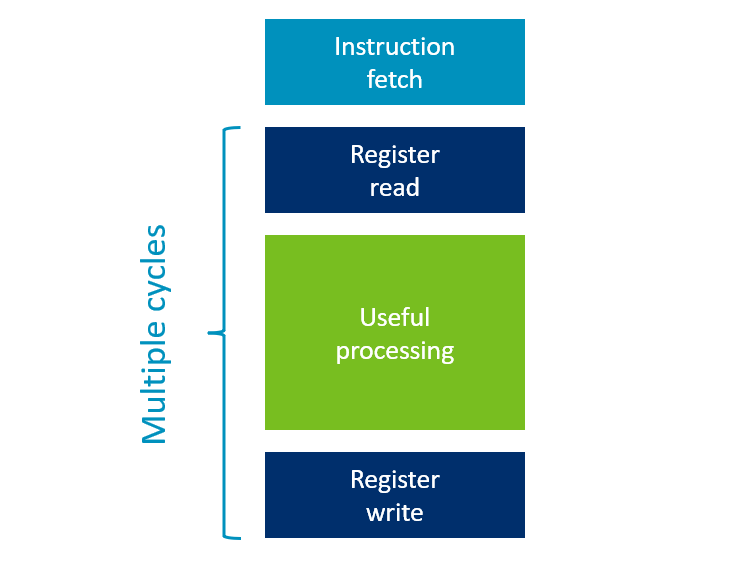
延迟隐藏硬件(橙色部分)
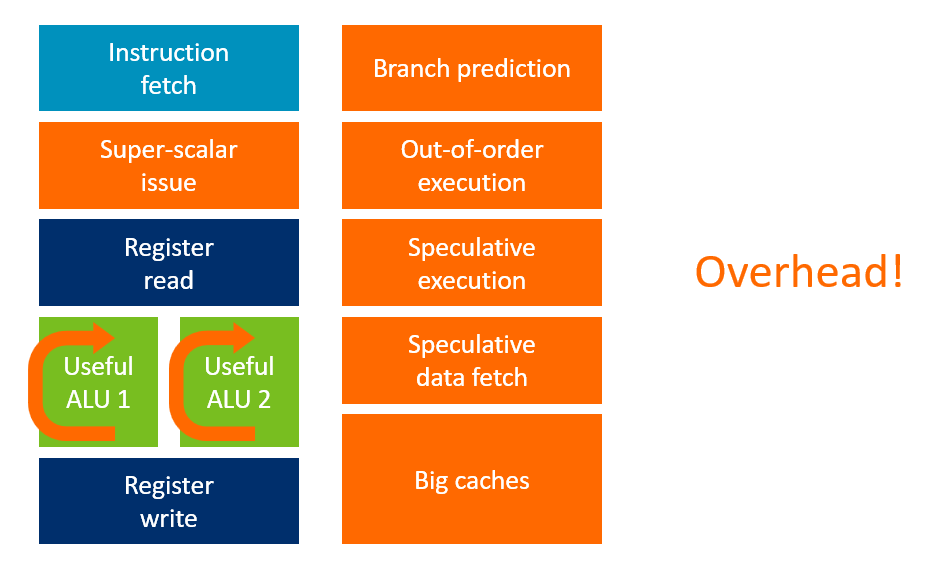
| 技术 | 作用 |
|---|---|
| 寄存器前递 | 中途传递结果,减少依赖等待 |
| 分支预测 | 猜测跳转目标,提前发射指令 |
| 超标量 | 从串行指令流中提取并行性 |
| 乱序执行 | 大窗口(~128 条)寻找并行机会 |
| 推测执行 | 预取可能用到的数据 |
| 大缓存 | 减少 Cache Miss(MB 级 L1/L2) |
CPU 的效率困境
| 颜色 | 含义 | 能耗 |
|---|---|---|
| 绿色 | 实际计算单元 | 有效功耗 |
| 橙色 | 延迟隐藏硬件 | 额外开销 |
Arm Big vs Little 核心差异:Big 核心加了更多"橙色"→ 性能提升,但 能效下降
SIMD:CPU 的效率亮点
原理
一条指令:vec4 add
↓
指令获取/译码:1 次
实际计算: 4 次并行
↓
控制开销摊薄到 1/4
局限
- 程序必须 有 SIMD 操作 才能利用
- 标量代码无法受益
GPU:完全不同的问题域
特征对比
| 维度 | CPU | GPU |
|---|---|---|
| 线程数 | 16–32 | 数十万–数百万 |
| 关注点 | 单线程延迟 | 整体吞吐量 |
| 程序类型 | 复杂控制流 | 大量相似计算 |
关键洞察
我们不关心一个顶点/像素的延迟,只关心最终帧缓冲的完成时间
GPU 的设计哲学
利用问题的并行性
顶点:数十万个 ──→ 每个运行 Vertex Shader
像素:数百万个 ──→ 每个运行 Fragment Shader
↓
完美并行!
扩展策略
| 平台 | Shader Core 数量 |
|---|---|
| 移动端 | ~20 |
| 桌面端 | ~128 |
设计原则:打造最节能的单元,然后 大量复制
为何 GPU 不需要那些"橙色"硬件?
| CPU 问题 | GPU 解法 |
|---|---|
| Cache Miss 等待 | 切换到其他线程(成千上万可选) |
| 流水线气泡 | 线程间隐藏延迟 |
| 分支预测失败 | SIMT 执行模型处理 |
核心思想:用 海量线程 替代 复杂硬件 来隐藏延迟
GPU Shader Core 架构:多线程延迟隐藏
从 CPU 设计出发
假设场景
- 流水线深度:10 周期(从读取到写回)
- 策略:让 10 个线程轮流发射
周期 0: Thread 0 → 进入流水线
周期 1: Thread 1 → 进入流水线
周期 2: Thread 2 → 进入流水线
...
周期 9: Thread 9 → 进入流水线
周期 10: Thread 0 → 第二条指令(此时第一条已完成!)
消除 CPU 的"橙色"硬件
| CPU 技术 | GPU 是否需要 | 原因 |
|---|---|---|
| 超标量发射 | ❌ | 有多个线程可选,无需从单线程找并行 |
| 乱序执行 | ❌ | 切换线程即可,无需重排单线程指令 |
| 分支预测 | ❌ | 等 10 周期后条件码已确定 |
| 结果前递 | ❌ | 上条指令结果已写入寄存器 |
| 大缓存 | ❌ | 用线程数换取延迟容忍 |
代价:需要存储 10 份线程状态(寄存器、PC 等)
扩展到 1000 线程:隐藏内存延迟
内存延迟问题
- DRAM 访问:100+ 周期
- 10 线程不够填满空闲
解决方案
1000 个线程中:
├─ 1 个:正在发射
├─ ~10 个:在流水线中执行
└─ 其余:等待 DRAM 返回(睡眠状态)
只要每周期有 1 个线程就绪 → 完全隐藏内存延迟!
关键洞察:GPU 拥有海量线程,可以用 线程数量 换取 延迟容忍
SIMT:旋转 90° 的 SIMD
CPU SIMD 的局限
传统 SIMD:
vec4 add → 单线程内找向量操作
↓
问题:程序必须有向量指令
现实:大多数时候 NEON (ARM架构SIMD架构扩展) 闲置
GPU 的创新:SIMT(旋转 90°)
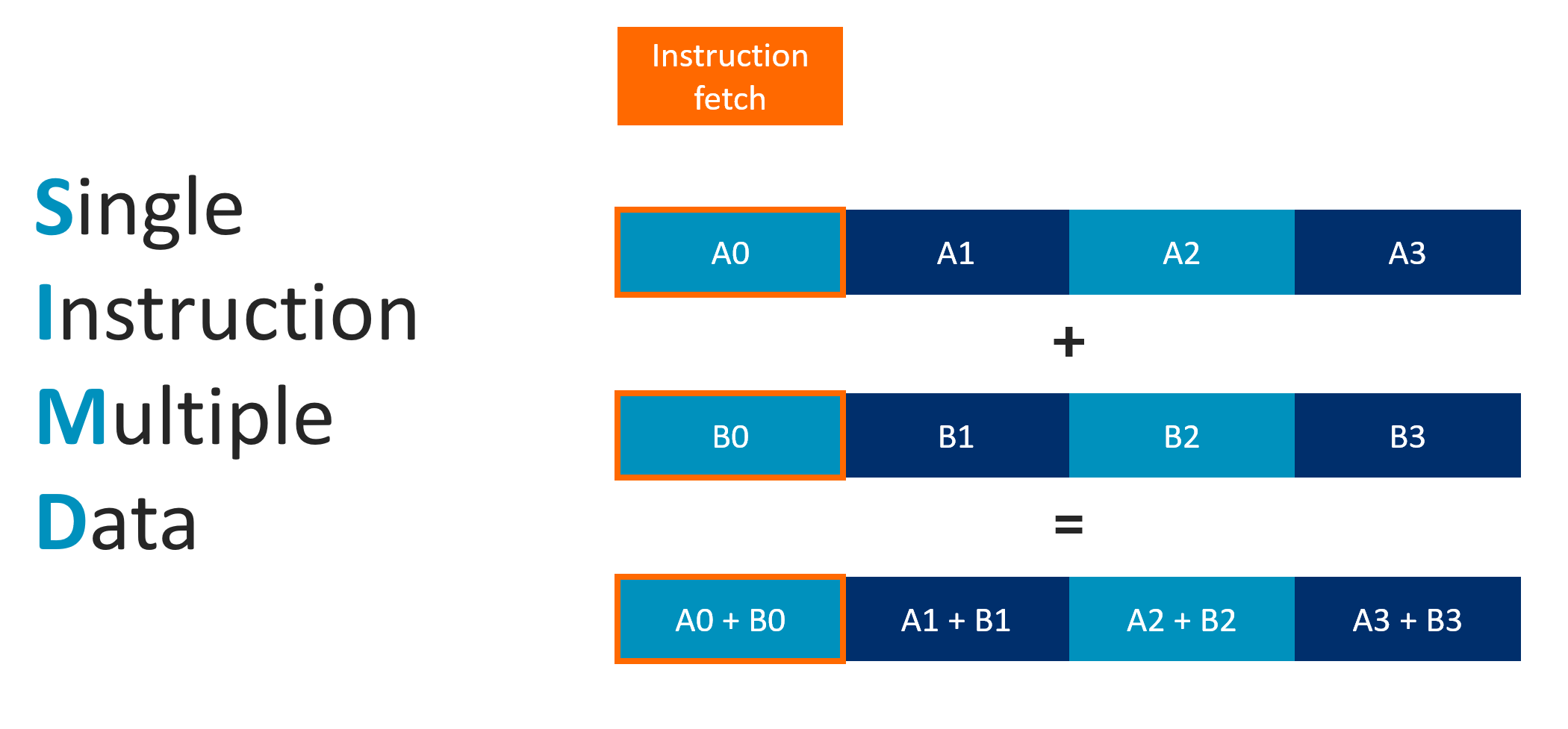
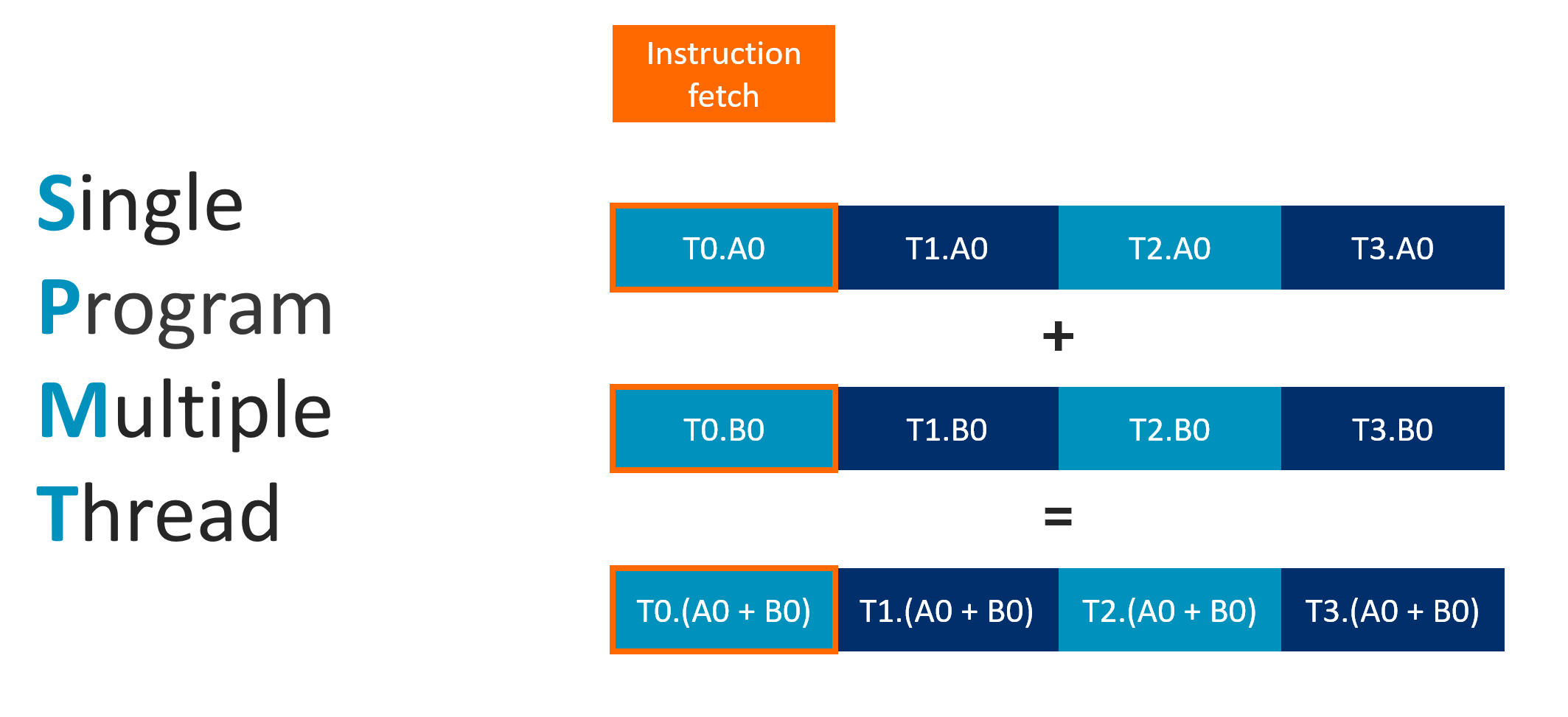
核心要求
- 多个线程 锁步执行(Lockstep)
- 来自 同一 Draw Call
- 运行 相同着色器程序
- 拥有 相同 PC(程序计数器)
术语对照
| 厂商/规范 | 名称 |
|---|---|
| NVIDIA | Warp |
| AMD | Wavefront |
| Vulkan | Subgroup |
| Arm Mali | Warp |
Warp 宽度的优势
Warp 宽度 = 16(Mali 最新 GPU)
↓
控制开销摊薄到 1/16:
- 指令获取:1 次 / 16 ops
- 译码逻辑:1 份 / 16 ops
- 控制状态:1 份 / 16 ops
分支发散(Divergence)问题
场景
if (condition) {
// 路径 A
} else {
// 路径 B
}Warp 内行为

效率损失:分支发散导致 硬件利用率下降
最佳实践
- 最小化 Warp 内控制流分歧
- 同一 Draw Call 的线程尽量走相同路径
固定功能加速器
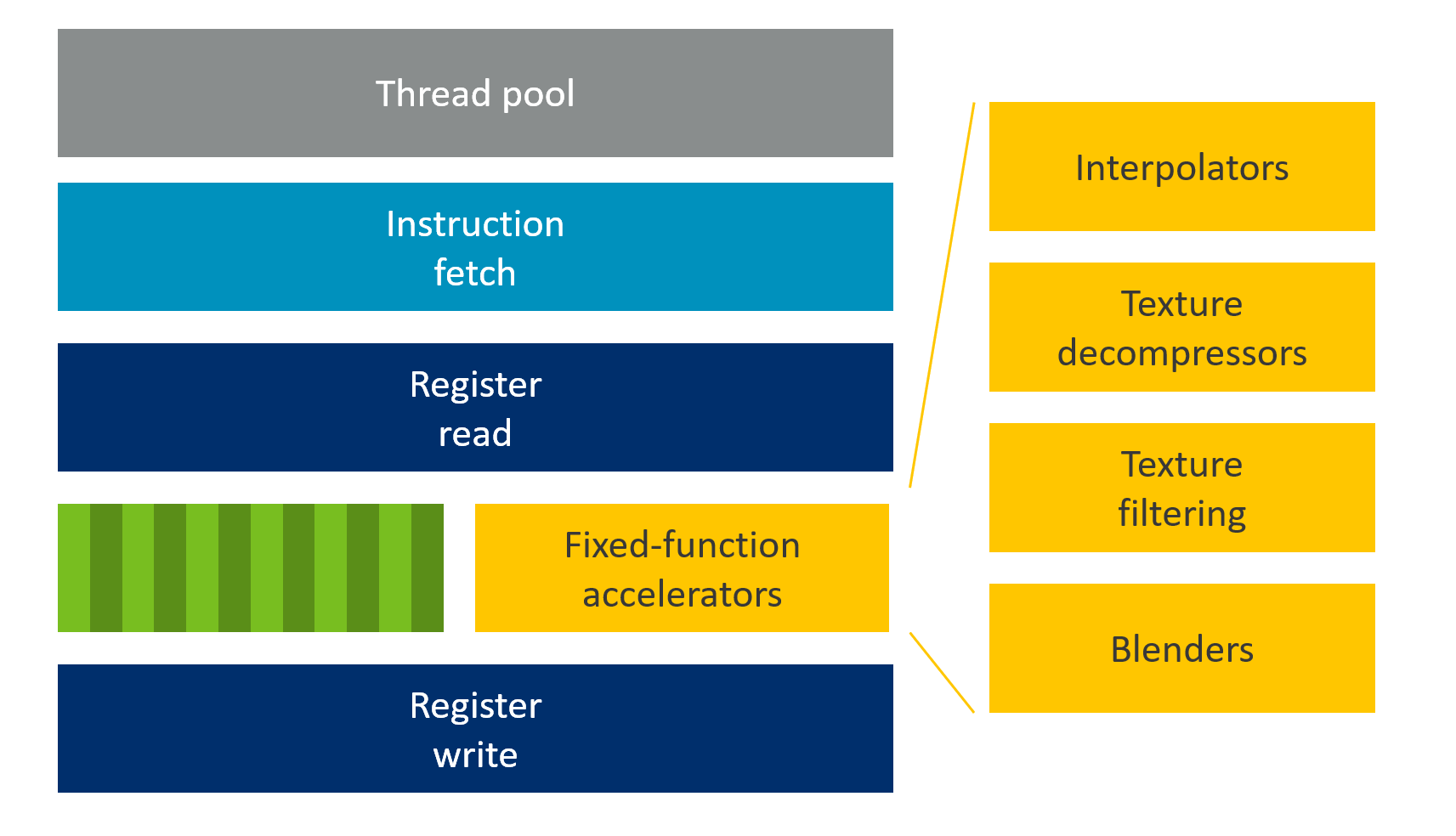
为何使用固定功能?
| 操作 | 可编程 Shader | 固定功能 |
|---|---|---|
| 纹理过滤 | FP16 计算 | 定点、更少位宽 |
| 混合 | 通用 ALU | 专用硬件 |
| 变化量插值 | 通用指令 | 专用插值器 |
权衡:消耗硅面积,但 大幅节省能耗
Mali Shader Core 总览
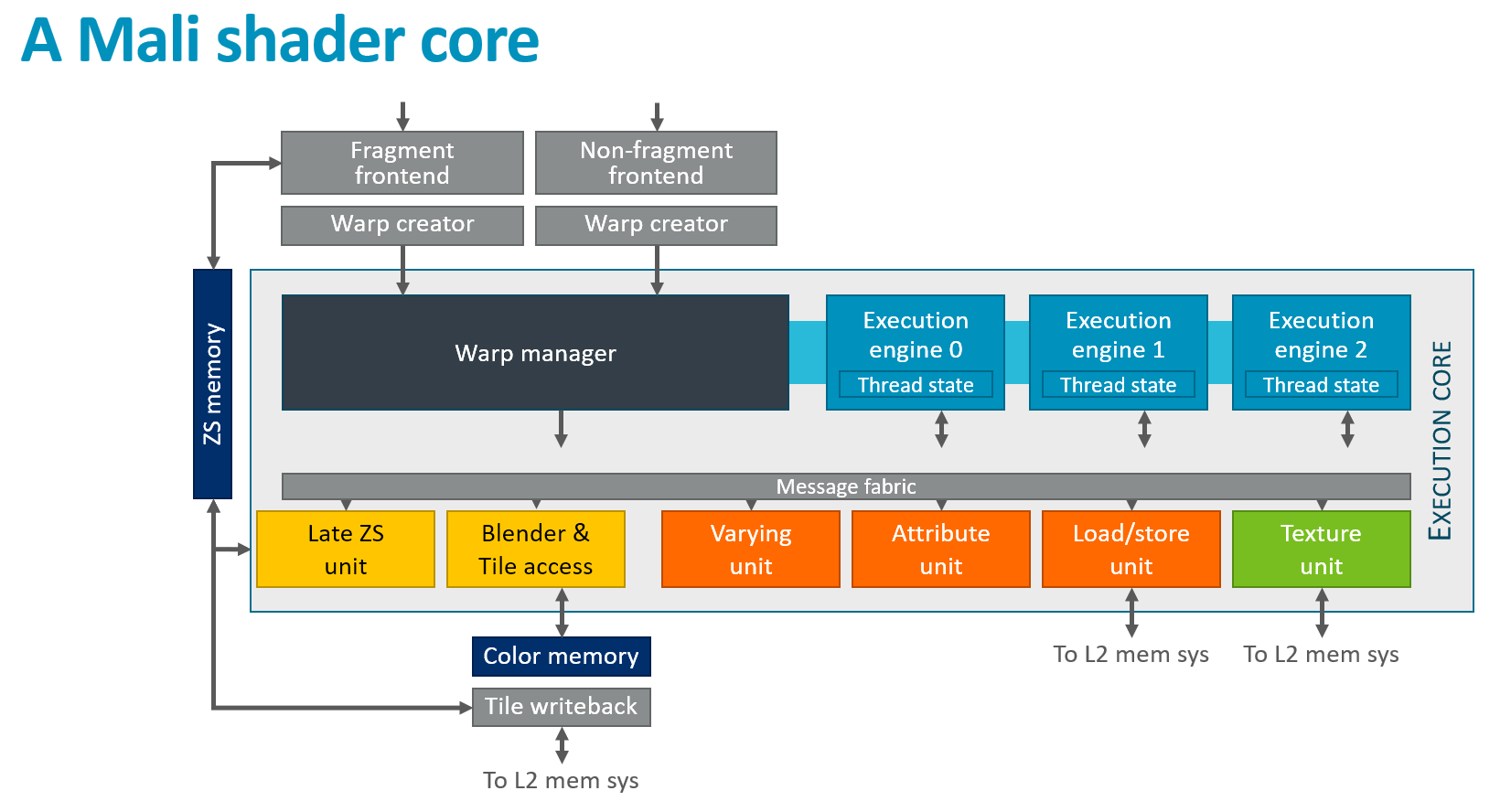
只有蓝色部分执行着色器程序,其余为专用硬件
核心要点总结
| 设计决策 | CPU | GPU |
|---|---|---|
| 延迟隐藏 | 硬件复杂度(乱序/预测) | 线程数量 |
| 向量化 | 程序必须有 SIMD 指令 | 硬件打包多线程 |
| 分支处理 | 分支预测 | 锁步 + 掩码 |
| 能效优化 | 大缓存 | 固定功能加速器 |