UE5中的开放世界光线追踪 (Ray Tracing Open Worlds in Unreal Engine 5)
SIGGRAPH 2022 Advances in Real-Time Rendering in Games course
Ray Tracing Open Worlds in Unreal Engine 5
项目背景与目标
- UE5 的核心目标:渲染大规模开放世界,实现前所未有的 细节层次(Level of Detail) 和 全局光照(Global Illumination) 质量
- 为此开发了多项关键技术:Lumen(动态全局光照)、Nanite(虚拟化几何体)、World Partition(世界分区流式加载)
- 其中部分系统依赖 光线追踪(Ray Tracing) 来获取场景的全局信息,因此必须大幅改进引擎的光线追踪系统
- 本讲内容主要来自 《The Matrix Awakens》 UE5 技术演示的开发经验
- 该演示在 PS5 和 Xbox Series S/X 上运行,目标 30fps
- 包含高速追逐场景(带大量快速镜头切换)和可自由漫游的大型城市
- 城市部分后来以 City Sample 示例项目的形式开源发布
使用光线追踪的系统
1. Lumen — 动态全局光照
- UE5 的 动态 GI 解决方案,是一个包含多个 Pass 的大型复杂系统
- 在《The Matrix Awakens》中,为了获得最佳质量,Lumen 依赖 光线追踪 来获取精确的场景表示
- 详细原理可参考同课程中的 Lumen 专题讲座
2. Shadows — 光线追踪阴影
- 支持使用 完全基于光线追踪的技术 来模拟真实光源的阴影
- 在《The Matrix Awakens》中,仅在过场动画(Cutscenes)期间使用,因为过场对阴影质量要求最高
3. Niagara — VFX 粒子系统
- UE 的 VFX 系统 Niagara 支持使用光线追踪进行:
- 粒子碰撞检测
- 更实验性的 载具与世界碰撞检测
构建光线追踪场景(Building the Ray Tracing Scene)
场景规模与挑战
- 《The Matrix Awakens》的城市面积约 16 平方公里,由 850 万个 Mesh Instance 构成
- 任意时刻约有 150 万个实例 处于加载状态(通过 World Partition 系统进行流式加载/卸载)
- 实例数量巨大的原因:城市采用 程序化生成 + 模块化网格(Modular Meshes) 构建
- 每栋建筑由数百个模块化组件拼成 → 单栋建筑就包含数百个实例
- 优势:几何数据可高效复用,降低整体内存消耗
- 劣势:实例数量爆炸,导致此前从未遇到过的性能问题
为什么需要大范围场景表示?
- 准确计算全局光照需要 覆盖玩家周围大面积区域 的场景表示
- 若场景表示范围有限,反射会出现严重错误:
- 例如:建筑反射完全丢失附近建筑,只反射了本应被遮挡的天空

- 例如:建筑反射完全丢失附近建筑,只反射了本应被遮挡的天空
大规模世界光线追踪的三大挑战
- 实例数量庞大 → 导致 TLAS 重建(Rebuild) 开销巨大
- BLAS 内存占用 很高
- 整体追踪性能 受限
核心方案:近场与远场分离(Near Field & Far Field)
设计思路
关键洞察:高频细节对远距离的全局光照和反射贡献极小,因此 只需在玩家附近维持高质量表示。
基于此,将光线追踪场景拆分为两个 LOD 层级:
近场(Near Field)
- 覆盖范围:玩家周围约 150 米半径
- 目的:提供详细的反射和全局光照
- 内容:
- 使用与主视图渲染相同或相近 LOD 的网格
- 包含 静态和动态网格(如骨骼动画角色)
远场(Far Field)

- 覆盖范围:玩家周围约 1 公里半径
- 目的:提供大尺度场景的光线追踪表示,同时使用更少实例和更简化的网格
- 内容:
- 仅包含静态网格(远距离的载具、行人等动态物体对 GI 贡献很小)
- 使用 UE 已有的 HLOD(Hierarchical Level of Detail) 系统
- HLOD 将 多个静态网格合并为单个代理网格(Proxy Mesh)
- 可生成 更低顶点数 的几何体
- 一个 HLOD 实例可以代表多栋建筑 → 原本需要数千个 Mesh Instance 的区域只需少量 HLOD 实例
效果对比
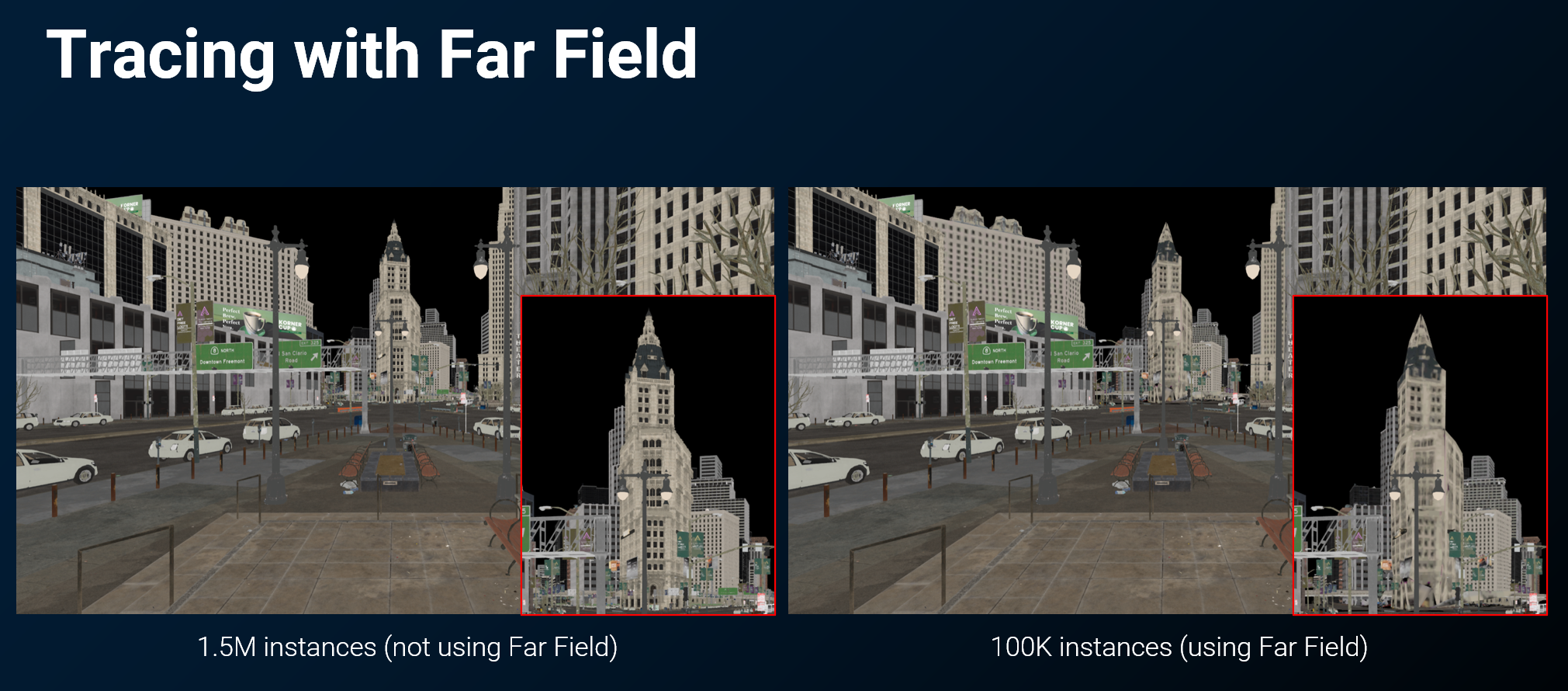
| 方案 | 实例数 | 覆盖范围 | 质量 |
|---|---|---|---|
| 暴力全量 | ~150 万 | 全部已加载 | 最高 |
| 近场 + 远场 | ~15 万(约 1/10) | 近场 150m + 远场 1km | 近处几乎无差异,远处几何/纹理简化 |
- 远处简化带来的不匹配(如不正确的自阴影)在主要用途(远距离 GI 和反射)中 不太明显,优势远大于缺陷
近场与远场的光线追踪融合
问题:不能简单合并为单个 TLAS
- 近场中表示的物体 也被包含在远场的 HLOD 中
- 由于 HLOD 是简化几何体,HLOD 三角面可能 穿插到近场几何体前方
- 导致光线在近场范围内错误地命中远场几何体
解决方案:分别追踪
- 先对近场追踪光线
- 若光线 未命中任何近场几何体就终止了(即射出了近场范围),则 发射第二条光线继续对远场追踪
- 第二条光线会带来一些额外开销,但整体仍比暴力方案快得多
远场光线起始距离的问题与修正
- 问题:若远场光线恰好从近场光线停止的位置开始,由于远场几何体与近场 不完全对齐,可能导致:
- 光线起始点 位于建筑内部
- 近场与远场之间出现 可见缝隙(Gap)
- 修正方法:
- 对远场光线的起始距离施加一个 负偏移(Offset),即让远场光线 稍微往回退一点 开始
- 利用远场表示与近场存在的 重叠区域,使光线能正确命中近场遗漏的几何体
- 若近场/远场交界处仍有可见过渡,可额外施加 交叉淡入淡出(Cross Fade)
TLAS 构建策略:避免遍历开销
方案一:Instance Mask 标记(简单但有缺陷)
- 在单个 TLAS 中,通过 Instance Mask 的特定位 标记远场实例
- 问题:TLAS 构建器(BVH Builder)不了解分别追踪的使用意图,会将两种表示的实例 混合在 BVH 节点中 → 遍历时产生 显著额外开销
方案二:大偏移分离(实际出货方案)
- 对远场所有实例施加一个 大位置偏移(Large Offset),使其在空间上 完全不与近场重叠
- 这样 BVH 构建器自然不会混合两种表示的节点 → 避免大部分遍历开销
- 《The Matrix Awakens》由于项目后期时间紧迫,实际使用了此方案出货
方案三:独立 TLAS(最优方案)
- 为近场和远场 各自构建独立的 TLAS
- 根据光线类型选择对哪个 TLAS 进行追踪
- 优势:
- 完全消除 重叠实例带来的遍历开销
- 远场 TLAS 可以 以更低频率重建,甚至 仅在加载时构建一次
- 无需追踪两个表示同时存在的情况(因为分步追踪)
性能对比总结
| 方案 | 实例数 | 性能 | 覆盖范围 |
|---|---|---|---|
| 暴力(Brute Force) | ~150 万 | 最慢 | 全部已加载区域 |
| 仅近场(Near Field Only) | 大幅减少 | 最快 | 仅 150m 半径 |
| 近场 + 远场(Near + Far Field) | ~15 万 | 比暴力快很多,比仅近场略慢 | 150m(高细节)+ 1km(简化) |
关键要点总结
- 模块化构建 节省内存但导致实例数爆炸,需要专门优化光线追踪场景
- 近场/远场分离 是在大规模世界中平衡光线追踪质量与性能的核心策略
- HLOD 天然适合作为远场表示:合并实例、简化几何体、大幅减少实例数
- 分别追踪时需注意 起始距离偏移 和 交叉淡入淡出 来处理两层表示的不对齐
- TLAS 构建策略对遍历性能影响巨大:独立 TLAS > 大偏移分离 > Instance Mask 标记
实例处理与 TLAS 构建
实例剔除(Instance Culling)
基本策略
- 对加载的约 150 万个实例 进行剔除,近场和远场使用 不同的距离阈值
- 除了距离剔除外,还基于实例 包围球的投影立体角(Solid Angle of Projected Bounding Sphere) 进行剔除
- 原因:远离摄像机的小物体对最终画面贡献极小,可以安全移除
层级剔除(Hierarchical Culling)
- 逐一剔除 150 万个实例 开销过大,因此采用 层级化剔除 加速
- 模块化网格的问题:由小模块组成的建筑中,模块会被 单独剔除,导致建筑的某些部分从反射中消失(例如一面墙突然不见)
- 解决方案 — 剔除组(Culling Groups):
- 将同一建筑的所有模块分配到 同一个剔除组(由程序化生成系统自动完成)
- 剔除时使用 整个组的包围盒 进行判断 → 建筑要么整体保留、要么整体剔除
- 剔除效果:从 ~150 万 实例降至约 ~10 万 实例,其中绝大部分属于 近场
GPU 驱动的 TLAS 构建
传统方式的瓶颈
- 玩家移动时,不同实例会被加载/卸载,动态物体(如汽车)每帧都可能改变变换
- 因此必须 每帧重建 TLAS
- 传统做法:在 CPU 端从多个数据源收集 10 万个实例的描述符,填充缓冲区后上传到 GPU → CPU 开销显著
改进方案:Compute Shader 构建实例缓冲区
- 使用 Compute Shader 在 GPU 端直接填充 结构化缓冲区(Structured Buffer)
- 布局在 D3D12 和 Vulkan 下基本相同
- 核心优势:
- 引擎已有用于 GPU Driven Rendering 的实例数据缓冲区 → 直接从已有 GPU 缓冲区复制数据,避免 CPU 重复收集和上传
- 对于 GPU 上直接生成的物体(如 粒子),无需 Readback 即可获取变换信息
- 部分 实例剔除可以直接在 GPU 上执行
TLAS 构建时间与优化
- 10 万实例的 TLAS 构建耗时约 2 毫秒
- 优化策略:尽早在帧中启动 TLAS 重建,并利用 Async Compute 与其他工作重叠执行
- 最终对实际帧时间的影响降低到约 0.3 毫秒
几何体处理与 BLAS 管理
两类几何体
静态网格(Static Meshes)
- 顶点数据 运行时不修改 → 初次构建 BLAS 后 无需重建或更新
- 每个 LOD 级别各有一个 BLAS,切换 LOD 时直接切换对应的 BLAS,无需重建
动态网格(Dynamic Meshes)
- 顶点在运行时被修改(如骨骼动画、材质驱动的顶点偏移)
- 每次顶点变化都需更新或重建 BLAS
- 需要包含 当前帧顶点位置 的缓冲区:
- 蒙皮角色:使用 Skin Cache 系统 — 计算当前帧蒙皮后的顶点位置并缓存到缓冲区中
- 材质顶点偏移(水面、植被等):运行 Compute Shader 将当前帧顶点数据写入缓冲区
- 关键开销:每个动态网格实例需要 一个 BLAS + 对应的顶点缓冲区
- 大量蒙皮角色活跃时,这些缓冲区可迅速累积到 数百 MB
- 缓解措施:
- 使用 Async Compute 并 限制每帧更新的 BLAS 数量
- 在《The Matrix Awakens》中,对动态网格使用 激进的低精度 LOD,同时减少 BLAS 更新时间和内存占用
BLAS 构建策略
运行时构建(Runtime Build)— PC 平台唯一方案
- GPU 开销显著,尤其在流式加载网格时问题突出
- 预算控制:
- 不以 BLAS 数量为限制单位,而是以 三角形数量 为预算 → GPU 开销更加稳定可预测
- 构建请求按 用户自定义优先级 排序
- 被跳过的请求 优先级每帧递增,防止被无限期推迟
BVH 压缩(Compaction)
- 对静态网格的 BVH 进行 Compaction 可节省 大量内存
- 原理:将 BVH 数据从原始缓冲区 拷贝 到更紧凑的缓冲区
- 限制:
- 压缩过程中需要 同时保留原始和压缩版本的内存 → 限制并发压缩命令数以控制 峰值内存
- 需要 GPU Readback 获取实际 BVH 大小 → 增加延迟
- 策略:在压缩完成之前,使用 未压缩的 BLAS 继续渲染,避免增加流式加载延迟
离线构建(Offline Build)— 主机平台独有优势
- 主机平台可以 完全离线构建 BLAS,然后像普通资源一样 流式加载
- 多重优势:
- 节省运行时 GPU 时间:流式加载时直接拷贝,无需构建和压缩
- 更高质量的 BVH:离线构建时间不受限,可使用 更复杂的 BVH 构建算法 → 追踪性能更好、BVH 更小
- 更精细的参数调控:可调整参数在 追踪性能和 BVH 大小 之间取得平衡
- 《The Matrix Awakens》中优先 最小化内存:调整 分裂因子(Split Factor) ,通过多次实验找到在 相同追踪性能下最小内存 的配置
BLAS 批处理(Batching)
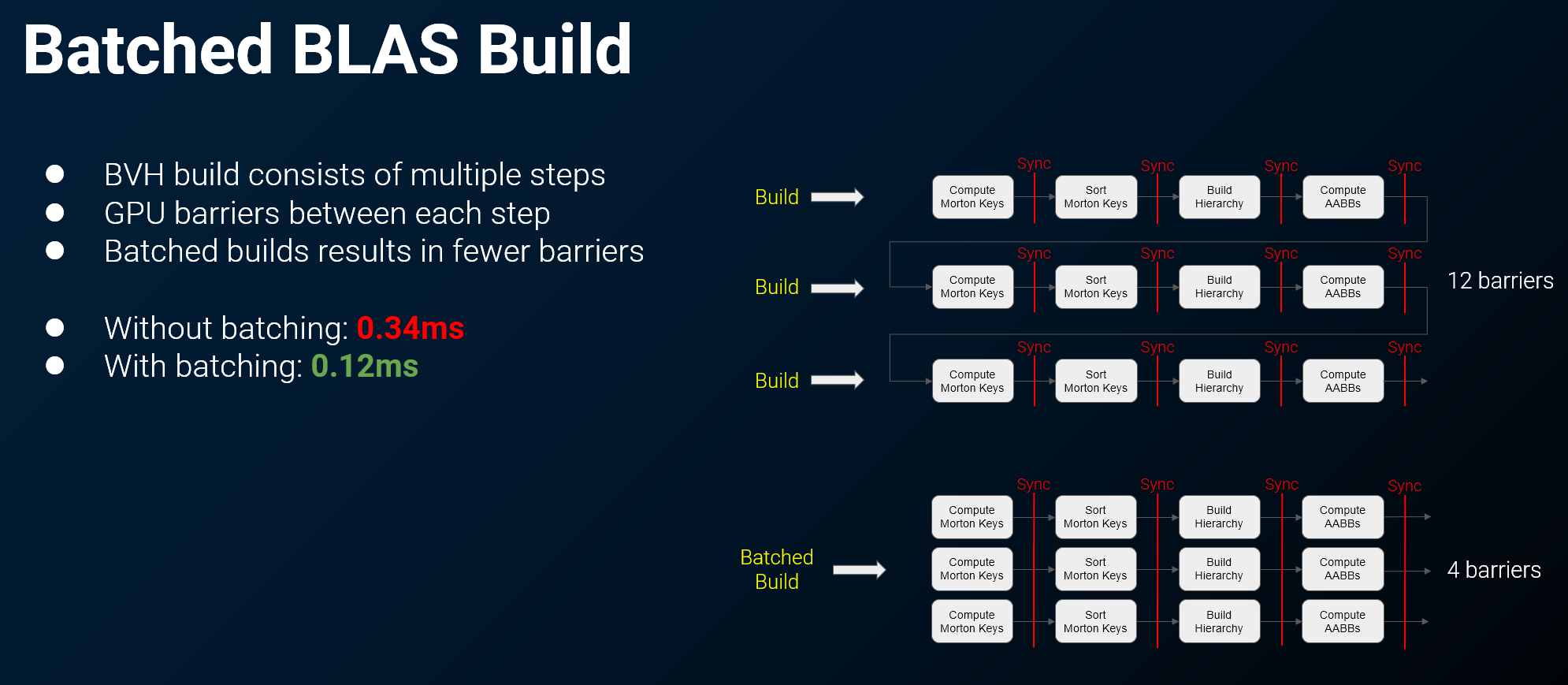
- 在主机平台(Vulkan),可以 批量处理 BLAS 构建和更新
- 为什么有效:
- 构建一个 BVH 内部包含 多个步骤,步骤之间需要 GPU Barrier
- 逐个构建 → 大量 Barrier → GPU 大部分时间在等待
- 批量处理 → 每个步骤可由多个 BLAS 同时执行,Barrier 开销只支付一次
- 效果:在《The Matrix Awakens》中,加速结构更新时间平均 减少近 1/3
光线追踪 Nanite 几何体
Nanite 简介
- Nanite 是 UE5 的 虚拟化几何体系统(Virtualized Geometry System),能够以实时帧率渲染 万亿三角形 级别的场景
光线追踪 Nanite 的挑战
| 挑战 | 说明 |
|---|---|
| 极高顶点数 | Nanite 允许使用超高面数资产,单个网格的 BLAS 可能占 数百 MB 内存,追踪性能也会下降 |
| 自定义压缩格式 | Nanite 在内存中以 高度压缩的私有格式 存储顶点数据,渲染时动态解压。构建 BLAS 需要先解压到独立缓冲区,且 Hit Shader 访问三角形数据也需要该缓冲区持续可用 |
| 动态流式加载 | 顶点数据随时被流入/流出,意味着每次发生时都可能需要 重建 BLAS |
当前解决方案:Fallback Meshes
- 在光线追踪场景中,使用 回退网格(Fallback Meshes) 代替 Nanite 原始数据
- 即 自动生成的 Nanite 几何体简化版本
- 内存压力增大:对于每个网格,需要同时保留:
- 用于光栅化的 压缩 Nanite 数据
- 用于光线追踪的 BLAS
- Hit Shader 访问所需的 额外顶点和索引缓冲区(BLAS 构建后仍需保留)
双 LOD 策略平衡质量与内存
- 使用 两个 Fallback LOD 级别 :
- LOD1(更低精度):始终保持加载
- LOD0(较高精度):按需流式加载/卸载,取决于:
- 该网格是否被 TLAS 实际引用
- 是否在 流式加载预算 范围内
- 流式加载由 TLAS 引用情况驱动(而非传统的基于摄像机距离的流式策略),因为 Fallback Meshes 仅用于光线追踪
内联光线追踪(Inline Ray Tracing)
背景:《The Matrix Awakens》中的材质评估
- Lumen 在该项目中使用 Surface Cache 评估材质,这是实现良好性能的关键组件(因为项目材质复杂度很高)
- 这意味着 Hit Shader 仅用于返回 材质 ID 和 几何法线,供 Surface Cache 进行采样和光照计算
- 所有网格共享 同一个 Hit Group → 理论上应接近光线追踪的"光速"性能
- 但实际发现:即使在这种极简配置下,依赖 Ray Generation Shader 的传统管线在某些场景仍然效率不佳
⚠️ 以下内容基于《The Matrix Awakens》发布时的 SDK 版本,光线追踪仍在持续演进中
传统光追管线的性能问题
问题一:VGPR 寄存器压力的全局影响
- 在光追管线中,驱动会根据 管线中最坏情况的 Shader 分配寄存器(VGPR)
- 后果:
- 某个阶段的高 VGPR 用量会 惩罚所有其他阶段
- Hit Shader 受 Ray Gen Shader 影响,反之亦然
- 如果管线中包含多个不同技术的 Ray Gen Shader,它们也会 互相影响
- 未使用或差异很大的 Shader 留在管线中 → 降低 Occupancy
- 主机端缓解:有编译器提示(Compiler Hints)可以为 Hit Group 最小化该问题
问题二:BVH 遍历着色器(Traversal Shader)的隐性开销
- Traversal Shader 负责实现 BVH 遍历主循环
- 遍历的其余部分(包括调用对应 Shader)在不同平台实现方式不同:
- 作为普通 Compute Shader 执行
- 或 内联到主 Shader 中
- BVH 遍历同样受 VGPR 压力影响 → 高 VGPR = 更少 Wavefront = 更少活跃 Lane 执行遍历 = 光追变慢
Xbox 的解决方案:专用状态对象(Specialized State Objects)
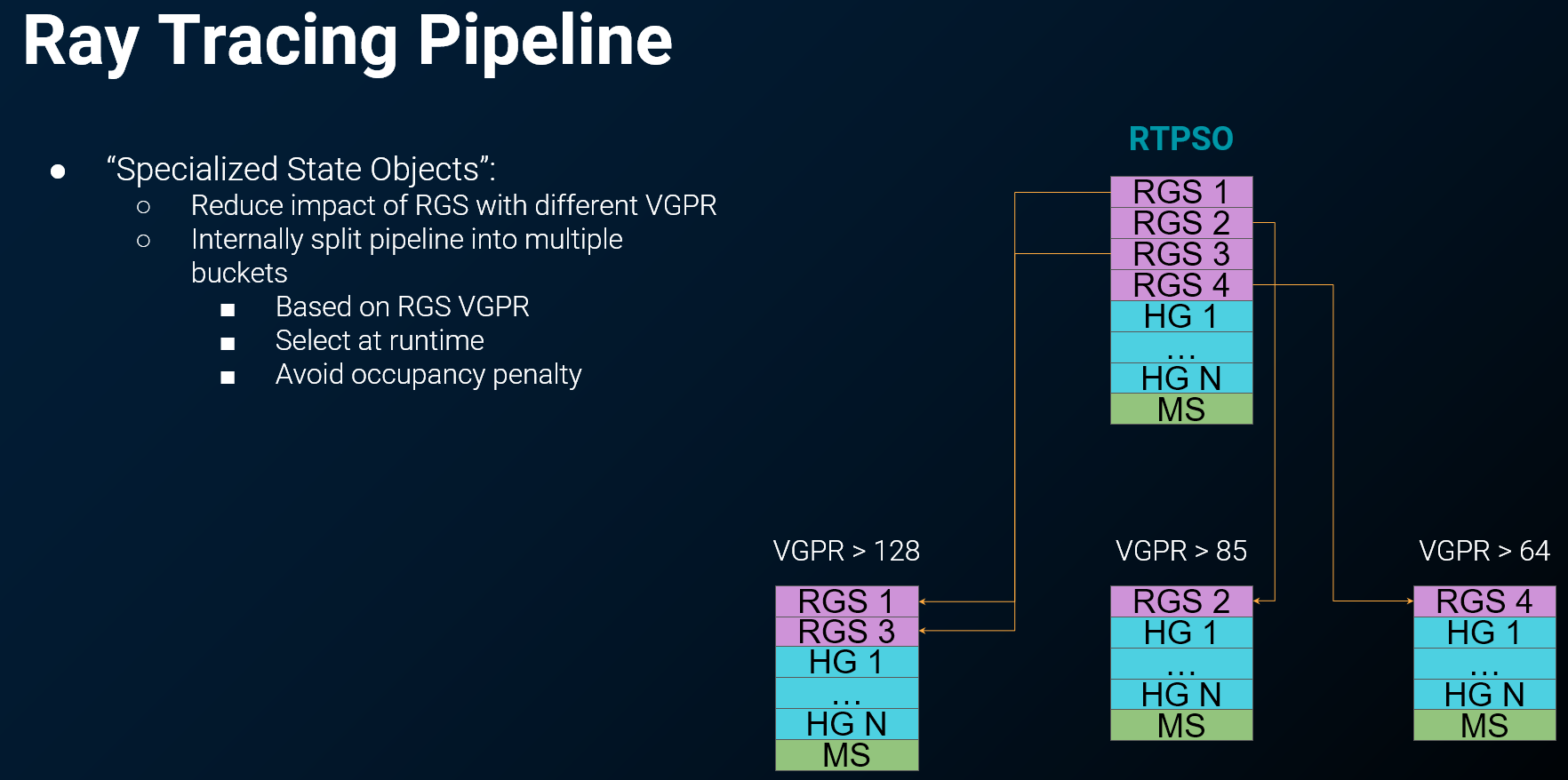
- 将高层光追管线在内部 拆分为多个独立管线,按 Ray Gen 的 VGPR 用量区分
- 运行时 选择合适的管线,避免始终承受最差情况的 Occupancy 惩罚
- PS5 不需要此方案:PS5 没有传统意义上的光追管线,每个 Ray Gen Shader 本质上就是 普通 Compute Shader,资源分配已知
问题三:Shader 调用机制的巨大开销
- 即使只有 一个 Hit Shader,如果编译器 没有将其内联,仍会触发完整的 Shader 调用机制
- GPU 需要 模拟函数调用栈:
- 切换到不同 Shader 前 → 保存当前状态
- 执行目标 Shader
- 恢复状态 并继续执行
各平台的状态保存方式
| 平台 | 状态存储位置 |
|---|---|
| Xbox | Scratch Memory(暂存内存) |
| PS5 | 可精细控制:LDS / Scratch / 保持在寄存器中,各类别可分别指定溢出量 |
| AMD(PC) | LDS |
| 其他厂商 | 可能不同 |
带宽视角的量化说明
- 假设目标 10 Giga-rays/s,Xbox 带宽 500 GB/s
- 则每条光线的读写预算仅 50 字节(包含所有 Buffer、纹理、UAV 读写 以及 状态保存/恢复)
- 状态保存/恢复很容易成为主导开销
内联光线追踪(Inline Ray Tracing)原理
基本概念
- 属于 DXR 1.1 规范的一部分(即 Ray Query)
- 是
TraceRay调用的替代方案,不使用独立的 Hit/Miss Shader - 所有着色逻辑由调用者处理,BVH 遍历代码 内联到主 Shader 中
- 若需模拟不同 Shader 行为 → 使用 switch 语句 等分支逻辑
核心优势
- 所有 Shader 代码对编译器可见 → 更多优化机会
- 消除状态保存/恢复开销 → 直接降低 VGPR 用量
- 提高 Occupancy → 更多 Wavefront 并行执行
适用性
- Lumen 中使用 Surface Cache 的 Pass 非常适合 内联光追(只有一个 Hit Group,逻辑简单)
- 不适用于 需要完整材质评估的 Pass(如光追阴影),因为这些需要多种 Hit Shader
性能对比结果
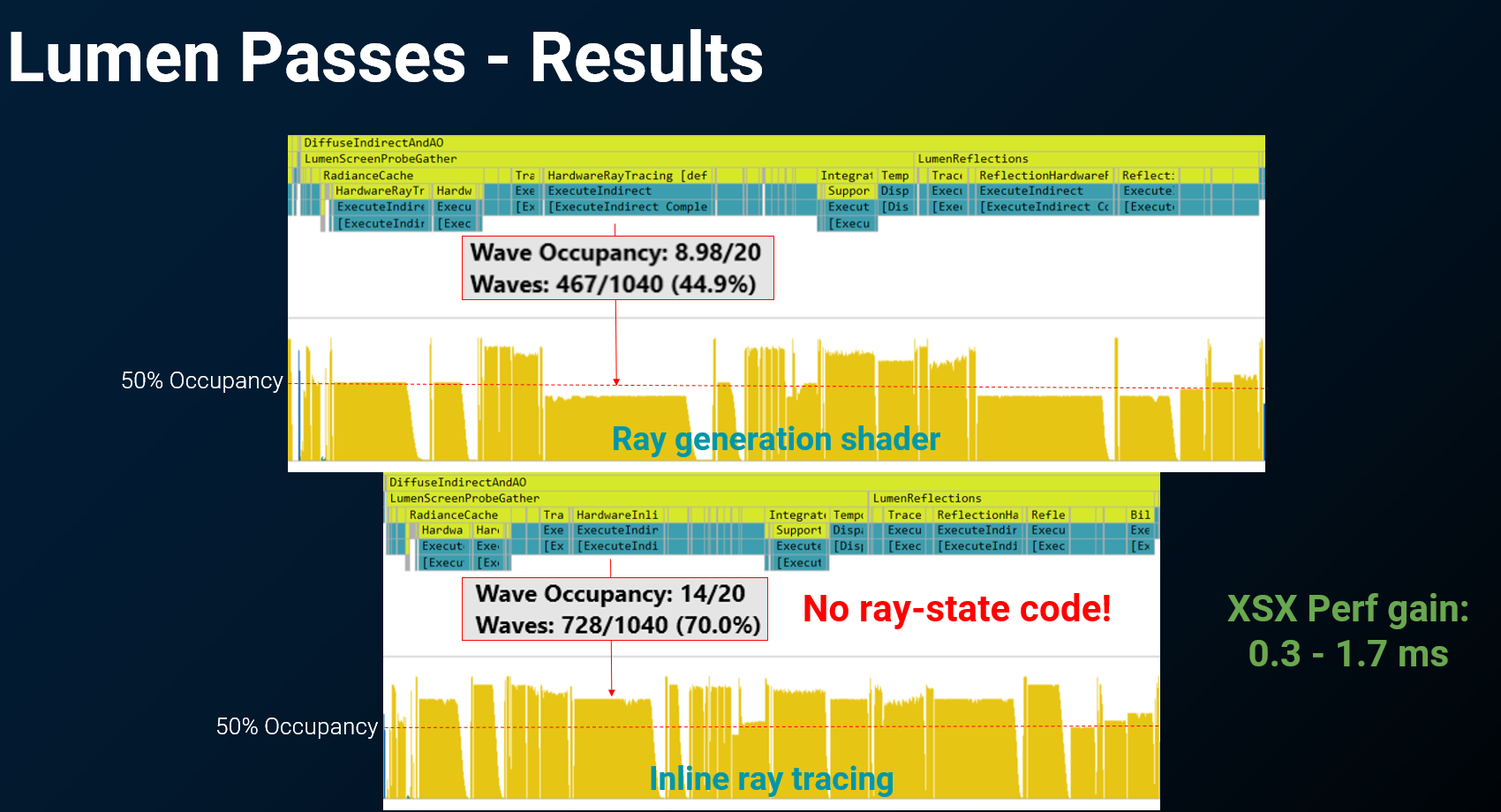
| 指标 | Ray Gen Shader 方式 | Inline Ray Tracing |
|---|---|---|
| 各 Pass 速度 | 基准 | 全部更快 |
| Occupancy | 较低 | 更高 |
| Xbox 平均节省 | — | ~0.5 ms |
| Xbox 最苛刻场景 | — | 最多节省 2 ms |
- 性能提升的主要来源:移除了状态保存/恢复代码 → VGPR 用量降低
UE5 中的实现细节
封装接口
- UE5 不直接暴露 Ray Query 对象
- 提供了一个类似
TraceRay的 通用函数,返回 遍历结果(Traversal Results)- 结果包含与 Ray Query 对象等价的数据
几何法线获取
- Surface Cache 光照需要 几何法线(Geometry Normal)
- 常规方式:通过 Bindless 或 Shader Binding Table 绑定顶点/索引缓冲区,在 Shader 中重建法线
- 主机端:有 硬件 Intrinsic 可直接获取交点处的法线,无需额外绑定
- PC 端:
- DXR(D3D12):由于 UE 的 Bindless 支持尚在开发中 → PC 上不支持内联光追,仍使用传统光追管线
- Vulkan:有替代方案绕过 Bindless 缺失 ↓
Vulkan 的 Bindless 替代方案
- 将每个顶点缓冲区和索引缓冲区的 GPU 地址 存储到一个统一缓冲区中
- 在 HLSL 中通过 GPU 地址 + SPIR-V Intrinsic 直接访问这些缓冲区
- 无需完整的 Bindless 资源绑定支持
Any Hit 与 Intersection 回调机制
- 利用新 HLSL 标准中的 模板(Templates) 支持:
- 可以传递 任意结构体 携带任意数据进出
TraceRayInline - 结构体需实现
OnAnyHit和OnProceduralPrimitive函数,遍历过程中自动调用
- 可以传递 任意结构体 携带任意数据进出
示例:Lumen 半透明评估的 Any Hit 回调
// 简化示例
struct LumenTranslucencyContext
{
// 携带所有所需数据
...
void OnAnyHit(...)
{
// 获取 Hit Group 数据
// 根据半透明标志(Translucency Flag)快速接受或拒绝
if (IsTranslucent)
AcceptHit();
else
IgnoreHit();
}
};- 通过这种回调模式,内联光追也能灵活处理 半透明物体 等特殊情况,同时保持编译器的完整优化视野
光线遍历(Ray Traversal)
核心问题:光线一致性(Ray Coherence)
为什么一致性至关重要
- 路径差异大的光线会 读取不同的 BVH 节点和三角形,所需的 遍历迭代次数 也各不相同
- 遍历性能主要受 内存延迟(Memory Latency) 主导 → 光线越一致,缓存命中率越高,带宽需求越低
- 因此保持光线的 空间和方向一致性 对性能至关重要
复杂场景带来的挑战
- 即使是 方向相似的光线,遍历迭代次数也可能差异巨大
- 某些 Shader 天生就会产生 不一致的光线分布
- 主机平台的特殊限制:
- BVH 遍历实现为 普通 Compute Shader,仅 AABB 和三角形求交由硬件加速
- 光线 不会被硬件重排序 来提升一致性
- 每条光线 始终在其生成的线程上运行
"长尾"问题(Long Tail Problem)
问题描述
- 同一个 Wave 中的线程完成遍历的时间不同
- 已完成的线程被标记为 Inactive,但 Wave 必须等待最慢的线程完成
- 这导致光追 Shader 出现 严重的长尾现象:整个 GPU 大部分时间在等待少数几个仍在遍历的线程
- 极端情况下:GPU 等待的时间甚至超过实际工作时间
- 此问题 在所有平台上 都存在,无论使用 Inline 还是 Ray Gen Shader
- 在《The Matrix Awakens》中,由于场景规模和复杂度,这是一个 重大性能瓶颈
方案评估
| 方案 | 思路 | 问题 |
|---|---|---|
| 光线排序 | 排序光线使同一 Wave 内迭代次数尽量相近 | 排序本身有开销;方向的微小变化就可能导致迭代次数剧变,无法保证有效 |
| 基于历史帧的调度 | 记录上一帧每组光线的最大迭代次数,下一帧优先发射最慢的组 | BVH 可能因物体移动而变化,上一帧的统计信息不再适用,同样无法保证 |
| 遍历迭代上限 ✅ | 设定遍历循环的最大迭代次数,超限后返回当前已有的命中结果(或返回无命中) | 可能返回 非最近命中(因为节点遍历顺序不保证命中从近到远),但 是唯一能确保消除长尾的方案 |
最终选择:遍历迭代上限(Traversal Iteration Limit)

- 由于可以访问主机端遍历代码,因此容易实现
- 核心保证:无论场景如何,都能 彻底截断长尾
遍历上限的实现细节与权衡
光照泄漏(Light Leaking)问题
- 因为截断遍历后返回的命中 可能不是最近命中,Lumen 中出现了各种 漏光现象
- 典型案例:高架桥下方的漏光(截图中可见)
- 修复方案:
- 将 "遍历是否完成" 的信息作为返回值的一部分
- 若遍历被截断 → 将其视为 命中,但返回 零辐射度(Zero Radiance)
- 即:被截断的光线贡献为黑色,宁可 过度遮挡(Over-Occlusion) 也不漏光
上限值的选择
- 上限太低:
- ✅ 性能大幅提升
- ❌ 大量不正确的命中 → 严重的 过度遮挡
- 上限太高:
- ❌ 几乎没有性能收益,只有极端情况被截断
- 问题:最佳值 高度依赖场景和内容,难以找到普适值
- 最终选择:《The Matrix Awakens》设定为 128 次迭代
- 在两个主机平台上节省约 0.5 毫秒
- 对大多数场景是较好的折中
管理光线一致性的技术手段
已有方案
- 光线排序(Ray Sorting)
- 光线分箱(Ray Binning)
- 光线紧凑化(Ray Compacting)
效果取决于具体场景
- 不同技术天然产生不同的光线分布:反射光线、辐照度探针光线、碰撞光线 等各有特点
- 同一 Wave 中方向差异大的光线 → 读取不同数据 → 带宽需求增加
- 最佳做法:可视化并追踪光线行为,针对性优化
遍历统计系统(Traversal Statistics)
可追踪的指标
由于可以访问主机端遍历代码,可以暴露几乎任意统计量:
| 统计指标 | 用途 |
|---|---|
| 每 Wave / 每线程的迭代次数 | 检查遍历迭代的 发散程度(Divergence) |
| 每条光线相交的三角形和内部节点数 | 粗略估算 内存流量 |
| 遍历 Occupancy(占用率) | 衡量 Wave 中有多少线程在活跃遍历 |
Occupancy 指标详解
- 定义:Wave 中正在活跃执行遍历的线程比例,在所有迭代上取平均值
- 起始时若全部线程参与遍历 → 100% Occupancy
- 随着线程逐个完成,Occupancy 逐渐下降
- 最终报告值:从开始到最后一个线程完成期间的 平均 Occupancy
- 低 Occupancy 的两种原因:
- 长尾:大部分线程已完成,少数线程仍在遍历
- 初始 Occupancy 就低:Wave 中本来就只有少数线程发起了遍历
实际案例:Lumen Surface Cache 直接光照 Pass
- 问题:从 Surface Cache Tile 发射光线计算直接光照是 有条件的(Conditional),导致许多线程根本不发射光线 → 初始 Occupancy 就很低
- 尝试修复 — 光线紧凑化(Ray Compacting):
- 将不同 Tile 的活跃光线 压缩到同一个 Wave 中 → Occupancy 提升
- 但副作用:一个 Wave 中的光线现在来自不同 Tile → 空间一致性下降 → 每个 Wave 需要读取更多不同的 BVH 节点和三角形 → 带宽增加
- 启示:Occupancy 与 Coherence 之间存在 权衡(Trade-off),遍历统计系统帮助定位和量化这类问题
调试与可视化(Debugging and Visualization)
主射线交点可视化
- 除了前面提到的遍历统计系统外,另一种直观方式是 显示主射线(Primary Ray)与场景的交点信息
- 各平台都提供了检查 加速结构(Acceleration Structure) 的工具,且每次更新都在改进
- 但团队仍然希望在 运行时(Runtime) 获取尽可能多的信息 → 因此在引擎中 内建了多种调试可视化模式
引擎内建的调试可视化模式
1. 三角形与实例可视化(Triangle & Instance Visualization)
- 用 不同颜色 显示每个三角形和每个实例
- 主要用途:捕捉构建 BLAS 时使用的 顶点缓冲区(Vertex Buffer) 或 索引缓冲区(Index Buffer) 损坏的错误
2. 性能热力图模式(Performance Heat Map)
- 以热力图形式展示 TraceRay Shader 的综合开销
- 包含 遍历开销 + Hit Shader 执行开销 的合计
- 非常有用:帮助定位光追 Shader 中 意料之外的高成本区域
3. 主机专用模式(Console-Specific Modes)
- 模仿 PIX 光线追踪性能模式 而添加
- 用于展示 遍历成本 和 BVH 质量
- 提供三种热力图:
| 热力图类型 | 显示内容 |
|---|---|
| 内部 BVH 节点求交次数 | 光线穿过了多少个 BVH 中间节点 |
| 三角形求交次数 | 光线与多少个三角形做了求交测试 |
| 总求交次数 | 以上两者之和 |
实际调试案例
案例一:脱落零件导致 BLAS 膨胀

- 现象:车辆碰撞后,保险杠从车身脱落,但仍然属于车辆的 同一个 BLAS
- 问题:保险杠与车身分离后距离很远 → BLAS 的包围盒 急剧膨胀 → 大量光线与这个巨大的 BLAS 求交 → 遍历成本虚高
- 通过可视化模式 发现了此问题
案例二:遍历上限的效果验证
- 场景:某些光线在角色附近经过复杂路径,再穿过树木,最终 未命中任何几何体
- 这些光线需要 超过 100 次迭代 才能完成,却几乎不贡献有效信息
- 通过 遍历热力图对比,清晰展示了 设置遍历上限(Traversal Limit) 如何有效控制此类光线的开销
案例三:Instance Mask vs. 独立 TLAS 的性能差异
- 对比方式:分别用热力图观察两种远场实现的遍历迭代次数
| 方案 | 遍历迭代次数 | 原因 |
|---|---|---|
| Instance Mask(所有实例在同一 TLAS 中,用掩码区分近场/远场) | 较高 | 所有实例都参与遍历,只有在 取回并求交实例后 才会根据掩码过滤 → 大量无效工作 |
| 独立 TLAS(近场和远场各自拥有独立的 TLAS) | 明显更低 | 每次 Trace 只遍历对应的 TLAS,不需要的实例 从一开始就不在结构中 |
- 结论:对于近场/远场分离的架构,使用 独立 TLAS 比 Instance Mask 方案的遍历效率显著更高
总结与关键要点回顾
UE5 大规模世界光线追踪的核心技术栈
| 技术 | 作用 |
|---|---|
| 近场/远场分离 | 将场景拆分为高精度近场(~150m)和简化远场(~1km),大幅降低实例数量和内存 |
| 层级剔除 + 剔除组 | 从 150 万实例高效剔除到约 10 万,模块化建筑整体剔除避免视觉瑕疵 |
| GPU 驱动的 TLAS 构建 | 使用 Compute Shader 在 GPU 端构建实例缓冲区,减少 CPU 开销 |
| BLAS 离线预构建 + 压缩 | 主机端离线构建 BLAS 并压缩存储,运行时仅需解压,节省 GPU 时间和内存 |
| 内联光线追踪(Inline RT) | 消除 Shader 调用开销和 VGPR 全局影响,简化状态管理,提升遍历效率 |
| 遍历迭代上限 | 截断异常长的遍历路径,彻底消除长尾问题,被截断的光线视为零辐射度命中 |
| 独立 TLAS(而非 Instance Mask) | 远场使用独立加速结构,避免无效实例的遍历开销 |
| 丰富的调试可视化 | 内建多种热力图和可视化模式,帮助定位 BVH 质量、遍历开销、缓冲区错误等问题 |
核心设计哲学
- "足够好"胜过"完美":远场不需要完整精度;被截断的光线宁可过度遮挡也不漏光
- GPU 驱动一切:尽可能将工作从 CPU 移至 GPU(实例缓冲区构建、剔除、BLAS 构建)
- 逐平台深度优化:充分利用各主机平台的特性(PS5 的寄存器控制、Xbox 的 Specialized State Objects、离线 BVH 预构建等)
- 可观测性优先:完善的调试和统计系统是在复杂场景中优化光追的基础