Lumen:Unreal Engine 5 实时全局光照系统
SIGGRAPH 2022 Advances in Real-Time Rendering in Games course
Lumen Real-time Global Illumination in Unreal Engine 5
动机与目标
为什么需要完全动态的间接光照?
- 玩家交互自由度:烘焙光照(Baked Lighting)严重限制了玩家与世界的交互——连 开门 或 摧毁墙壁 这种简单交互都会因为静态光照而出问题。如果简单交互都能被动态间接光照解决,就能催生更多复杂的交互玩法。
- 光照美术工作流改善:传统工作流中,美术需要等待 数分钟甚至数小时 的光照烘焙才能看到结果。目标是让美术 即时看到 光照效果,从而大幅提升最终光照品质。
- 支撑大型开放世界:巨型开放世界根本 无法进行全场景烘焙,加上大型团队(数百人每天都在修改关卡),烘焙光照永远不可能保持最新状态。
- 品质对标烘焙光照:不只是解决室外场景的动态间接光照,还要达到 与烘焙光照可比的品质,包括所有间接光照细节和 间接阴影。
核心挑战
- 算力差距巨大:离线烘焙的处理时间比实时求解间接光照多出约 10 万倍。
- 全局光照的本质不连贯性(Incoherency):GI 光线传播在空间上是不连贯的,而 GPU 天生为 内存和执行的连贯性(Coherency) 而设计,这形成根本矛盾。
- 问题空间极大:技术路线选择极多,很难判断哪条路径可行、哪条不可行。
- 性能与品质的狭窄平衡点:就像站在山脊上,任何方向的微小偏移都会导致 性能或品质的下滑。
Lumen 算法总览
问题一:如何在场景中追踪光线?
硬件光追的局限
- 硬件光线追踪(Hardware Ray Tracing) 是未来方向,但需要向下兼容:
- PC 市场仍有大量 不支持硬件光追 的显卡
- 主机硬件光追 性能不够快
- 大量 重叠网格(Heavily Overlapping Meshes) 的场景在硬件光追的 两级加速结构(Two-Level Acceleration Structure, TLAS/BLAS) 下很慢
软件光追的探索历程
早期尝试:Card Height Fields(卡片高度场)
- 通过多个 正交相机(Orthographic Cameras) 捕获场景,生成所谓的 Cards
- 对 Card 高度场进行光线追踪,命中时采样 Card 上的光照
- 优势:2D 表面表示,比体素(Voxels)等 3D 表示具有 更高的空间分辨率;利用高度场特性(类似 视差遮蔽映射 Parallax Occlusion Mapping)实现快速软件追踪
- 致命缺陷:无法用高度场完整覆盖整个场景,缺失覆盖的区域会导致漏光(Leaking)
最终方案:Mesh Signed Distance Fields(网格有符号距离场,Mesh SDF)
- 每个网格预计算一个 有符号距离场
- 可靠遮挡:所有区域都有覆盖,不会出现漏光
- 快速追踪:通过 Sphere Tracing(球体步进) 跳过空白空间,实现高效软件光追
- 局限:距离场表面求交只能得到 命中位置和法线,无法获取材质属性或光照信息
Surface Cache(表面缓存)
- 光线命中 SDF 表面后,从 Cards(即 Surface Cache) 中 插值获取光照信息
- 缺失覆盖只会导致 能量损失,而非漏光——这比高度场方案好得多
- "Card Height Fields 用于追踪失败了,但用于光照成功了"
Surface Cache 的额外优势:
- 共享材质求值:多条光线命中同一区域时复用材质计算结果
- 直接控制更新频率:可以按需更新缓存
- 为硬件光追解锁快速路径:后续 Patrick 部分会深入介绍
问题二:如何求解完整的间接光照路径(多次反弹)?
单次反弹(Single Bounce)不够,室内场景需要 多次反弹的漫反射(Multi-bounce Diffuse),还需要全局光照同时出现在 反射(Reflections) 中。
分层求解策略
| 反弹次数 | 漫反射(Diffuse) | 镜面反射(Specular) |
|---|---|---|
| 第一次反弹(最重要) | Final Gather(最终聚集) | Reflection Denoising(反射降噪) |
| 后续反弹 | 通过 Surface Cache 的 反馈(Feedback) 自读取传播 | 同左 |
- Surface Cache 会从自身读取(gather from itself),每次更新传播一次额外的间接光照反弹
问题三:如何解决光传输中的噪声?
- 实时条件下甚至 连每像素一条光线都承受不起,但高质量室内场景实际需要 数百个有效采样
- 核心降噪策略(通过 Final Gather 技术族实现):
- 自适应降采样(Adaptive Downsampling):尽量少追光线
- 空间与时间复用(Spatial & Temporal Reuse):最大化利用每条光线
- 乘积重要性采样(Product Importance Sampling):将光线发往最有价值的方向
不同域的求解

| 表面类型 | 求解域 |
|---|---|
| 不透明物体(Opaque) | 2D 屏幕空间域 |
| 透明物体和雾(Transparency & Fog) | 可见视锥体内所有3D点 |
| Surface Cache | 纹理空间域 |
反射降噪
- 同样使用 空间与时间复用
- 尽可能 复用漫反射光线(Reuse Diffuse Rays) 给反射使用
Lumen 功能汇总
Lumen 最终提供的完整功能集:
- ✅ 多次反弹间接光照(Multi-bounce Indirect Lighting)
- ✅ 天空遮蔽(Sky Shadowing)
- ✅ 自发光照明(Emissive Lighting)——无需美术手动放置光源(但对自发光区域的 最小尺寸和最大亮度 有限制)
- ✅ 体积雾上的 GI(Volumetric Fog GI)
- ✅ 透明物体上的 GI(Transparency GI)
- ✅ 反射(Reflections)
- ✅ 通过 Surface Cache 实现 高效统一架构
- ✅ 支持 软件光追 / 硬件光追 按项目需求切换
混合光线追踪管线(Hybrid Ray Tracing Pipeline)
总体架构
Lumen 使用 混合光线追踪管线,允许混合搭配不同追踪技术。执行顺序为:
每种追踪方法完成后,会写出 光线已行进的距离 和 是否命中,下一种方法从该位置 接续追踪(Resume)。
Screen Traces(屏幕空间追踪)

为什么先执行 Screen Traces?
- 光线起点附近最精确:屏幕空间数据在近处分辨率最高
- 处理表示不匹配(Representation Mismatch):软件光追和硬件光追的几何表示都与 光栅化 G-Buffer 存在差异,可能导致:
- 自相交(Self-Intersection):光线起点在表示体内部
- 漏光(Leaking):表示体间存在缝隙
- 补充未被主追踪方法覆盖的几何类型:例如软件光追 不支持骨骼网格(Skinned Meshes),但 Screen Traces 能从第三人称角色上获取间接阴影
- 任意尺度工作:无论放大到多近都能提供细节 GI
关键实现细节:
- 不使用线性步进(Linear Steps)——线性步进会跳过薄物体(如走廊),导致漏光
- 改用 HZB 遍历(Hierarchical Z-Buffer Traversal):对最近深度的 HZB mip 进行 无栈遍历(Stackless Walk)
- 限制掠射角光线的迭代次数(如平行于墙面的光线)
- 漫反射光线使用 半分辨率 加速追踪
准确交接(Handoff)策略:
- 当光线离开屏幕或穿过表面背后时,回退到光线上最后一个未被遮挡的位置,确保下一个追踪方法不会从错误位置开始导致漏光
结论:Screen Traces 是 净品质增益,但使用越多,其失败时的瑕疵越明显。对硬件光追还有 小幅性能增益,因为大部分光线在复杂表面几何附近就已被解决。
光线压缩(Ray Compaction)

Screen Traces 完成后,部分光线已有结果,其余需要继续追踪。直接在所有空闲追踪通道上运行下一方法会浪费算力。
压缩策略对比:
| 方案 | 方法 | 问题 |
|---|---|---|
| 简单压缩 | 使用 Local Atomics 分配压缩索引 | 光线被 打乱(Scrambled),同一 Wave 内的光线起始位置分散到场景各处,破坏连贯性 |
| 保序压缩(Order-Preserving Compaction) ✅ | 在 更大的线程组(Thread Group) 内执行 快速前缀和(Fast Prefix Sum) 分配索引 | 保持光线空间局部性,显著提升后续追踪的缓存命中率 |
保序压缩 确保同一 Wave 内的光线仍然来自相近的屏幕区域,维持内存访问的连贯性,带来 显著加速。
Lumen 中的软件光线追踪与表面缓存
为什么需要软件光线追踪?
- Unreal Engine 需要支持 不同平台 和 不同类型的内容,需要多种工具来应对广泛的使用场景
- 核心动机:
- 在 没有 DXR(DirectX Raytracing)支持 的硬件上运行 Lumen
- 需要能够 向下缩放(Scale Down) 性能开销
- 软件光追 无法完全替代硬件光追,但拥有对 追踪循环的完全控制权,可以做出不同的性能/品质权衡
- 硬件光追的固有问题:BVH 中 重叠实例(Overlapping Instances) 会迫使光线逐一访问每个实例以找到最近命中,且无法修改其加速结构
基础图元(Primitives)
两种基本图元
| 图元类型 | 适用对象 |
|---|---|
| Mesh Distance Field(网格距离场) | 每个网格一个 |
| Height Field(高度场) | 每个地形组件(Landscape Component)一个 |
两级存储结构
- 底层(Bottom Level):存储每个图元的距离场/高度场数据
- 顶层(Top Level):扁平的 实例描述符数组(Flat Instance Descriptor Array)
- 这种设计可以 利用实例化(Instancing) 共享存储,显著 降低内存占用 ——对任何体积表示都至关重要
Mesh Distance Field(网格距离场)
生成流程
- 在 网格导入时(Mesh Import) 预计算,与其他网格数据一并存储
- 使用 Embree 点查询(Point Query) 高效找到每个体素到最近三角形的距离
- 从每个体素发射 64 条光线,统计 背面命中数(Backface Hits) 来判定该点在几何体 内部还是外部,从而确定距离场的 符号(Sign)
存储优化:窄带距离场 + 虚拟体积纹理
- 体积结构的分辨率扩展性差、内存消耗大
- 因此只存储 窄带距离场(Narrow Band Distance Field),放入 带 Mipmap 的虚拟体积纹理(Mipmapped Virtual Volume Texture) 中
- Mip 0:分辨率由网格大小和导入设置决定
- Mip 1:分辨率减半、最大物体空间距离翻倍,以此类推
流式加载(Streaming)
- 每帧调度一个 Shader 遍历所有实例,根据 与相机的距离 计算每个距离场资产所需的 Mip 级别
- 将请求 下载到 CPU,按需 加载新的距离场 Mip 或 丢弃不再使用的 Mip
- 距离场砖块(Bricks)存储在 固定大小的池(Fixed Size Pool) 中,由 简单的线性分配器(Linear Allocator) 管理
- 优势:无需处理 可变大小的 3D 分配 或 内存碎片化 问题
光线步进(Ray Marching)
- 使用 Mipmap 加速光线步进(Ray Marching):
- 靠近表面时:切换到更高精度的 Mip
- 远离表面时:切换到更低的 Mip,以更大步长快速穿越空白空间
- 类似于 Sebastian Aaltonen 在 Claybook 中使用的技术
- 出于性能考虑,将光线步进迭代次数 限制为 64 次
- 若达到上限,则 停止遍历并在当前光线距离处报告命中
- 找到命中点后,使用 中心差分法(Central Differencing)取 6 个样本 计算 几何法线
- 该法线用于后续从 Surface Cache 中采样材质和光照
Landscape Height Field(地形高度场)
结构
- 地形被划分为 组件(Components),每个组件对应一个 高度场 和一份 Surface Cache
- 顶层处理:高度场实例与 Mesh Distance Field 实例 共用剔除和遍历代码
- 底层差异:不使用 3D 距离场,而是对 2D 高度场 进行光线步进,寻找 零交叉点(Zero Crossing)
命中判定流程
- 找到两个采样点:一个在高度场 之上,一个在 之下
- 在两点之间进行 线性插值 近似最终命中点
- 在该点从 Surface Cache 中 评估不透明度(Opacity),决定:
- 接受命中 → 从 Surface Cache 计算光线辐射度(Ray Radiance)
- 跳过命中 → 继续在高度场下方追踪(处理如透明区域等情况)
场景级追踪:加速结构的选择
问题
已知如何追踪单个实例,但 不可能遍历场景中所有实例逐一光线步进,需要场景级加速结构。
尝试过的方案
| 方案 | 问题 |
|---|---|
| 均匀网格(Uniform Grids) | 每帧构建一次、可多 Pass 复用,但 长距离不连贯光线性能不足;跨越多个单元格的物体处理复杂;重叠实例仍需逐一步进 |
| 软件 BVH 遍历 | 内核过于复杂 |
关键洞察:只追踪短光线
- 核心认识:只需要在光线的 前一小段 使用精确场景表示,之后可以切换到 粗粒度场景表示(Coarse Scene Representation)
- 当光线足迹(Ray Footprint)变宽时,切换到不同的追踪方法
- 这同时解决了 物体重叠问题:可以将整个场景 合并为统一的简化全局表示
Global Distance Field(全局距离场)
为什么选择全局距离场?
在寻找"粗粒度全局场景表示"的过程中尝试了多种方案:
| 方案 | 问题 |
|---|---|
| 构建时合并整个场景 | 工作流受限,不支持动态物体 |
| 运行时体素化 + 体素锥追踪(Voxel Cone Tracing) | 将几何属性合并到体积中会导致 漏光(Leaking),尤其在低 Mip 层级 |
| 体素位砖块(Voxel Bit Bricks) | 每个体素存 1 bit 标记有无几何体;简单光线步进 出奇地慢;加了邻近图加速后,本质上等同于在画体素 → 不如直接用距离场 |
最终方案:将所有 Mesh Distance Field 和 Height Field 合并到以相机为中心的 Clip Map 距离场中。
结构细节
- 默认使用 4 层稀疏 Clip Map,每层都是 虚拟体积纹理(Virtual Volume Texture)
- 每个 Clip Map 存储距离场砖块,每个砖块存储 窄带距离场
- 与 Mesh Distance Field 的 Mipmap 层级不同,这里使用 Clip Map 层级:目的是 距离相机越远的场景越简化
更新策略
合并场景中所有物体开销巨大,必须大量缓存:
- 增量更新:仅更新自上一帧以来 发生变化的部分
- 时间分片(Time Slicing):更远的 Clip Map 更新频率更低
- 每层独立 LOD 设置:在较远的 Clip Map 中 丢弃较小物体
- 最远 Clip Map 需合并的实例数最多,这大幅提升了更新性能
动静分离(Dynamic / Static Brick Splitting)
- 场景中通常只有少量物体在移动,绝大部分完全静态
- 将缓存分为 动态砖块 和 静态砖块
- 例如:汽车移动时,不需要重新计算周围静态建筑物 的距离场
缓存更新流程
- 追踪场景修改:在 GPU 上构建 被修改砖块列表
- 剔除(Culling):将场景中所有物体对当前 Clip Map 进行剔除,再将结果与被修改砖块列表进行裁剪
- 最后一步剔除中,采样 Mesh Distance Field 进行比纯解析包围盒检查 更精确的剔除
- 得到:
- 需要更新的 被修改砖块列表
- 每个被修改砖块对应的 被剔除物体列表
- 分配/释放持久化砖块,然后执行更新
单个砖块更新
- 遍历影响该砖块的所有物体,逐体素计算 最小距离(Min Distance)
- 非均匀缩放(Non-Uniform Scale)问题:
- 距离场中存储的距离只对 均匀缩放 有效
- 尝试过通过 解析梯度找最近点 再重新计算距离,但由于距离场分辨率有限,实际效果不佳
关键技术要点总结
| 概念 | 要点 |
|---|---|
| 软件光追存在价值 | 向下兼容无 DXR 硬件、完全控制追踪循环、可做不同权衡 |
| 两级结构 | 底层图元 + 顶层实例描述符,利用实例化节省内存 |
| Mesh SDF 生成 | Embree 点查询 + 64 射线背面计数确定符号 |
| 窄带 + 虚拟纹理 | 只存近表面距离、按需流式加载 Mip |
| Mipmap 加速步进 | 近处用高 Mip 精确、远处用低 Mip 快速跳过 |
| 短光线 + 全局距离场 | 前段用精确 Mesh SDF,后段用合并的全局距离场 |
| 增量 + 动静分离 + 时间分片 | 三重策略保证全局距离场更新性能 |
Lumen 软件光线追踪:全局距离场、追踪管线与距离场问题解决方案
全局距离场(Global Distance Field)
非均匀缩放问题
- 非均匀缩放的物体无法简单变换距离场(距离值会失效)
- 最终的实用方案:用 解析对象包围盒的距离(Distance to Analytical Object Bounds) 来约束距离场
- 大多数非均匀缩放的物体形状较简单(如墙壁),所以实践中 效果很好
动态物体更新
- 更新动态砖块(Dynamic Bricks)时,需要将 重叠的静态砖块合成(Composite) 进去
- 将静态与动态缓存 合并为最终距离场 用于追踪
粗糙图(Coarse Map)
- 四分之一分辨率 的 非稀疏距离场体积(Non-Sparse Distance Field Volume)
- 用于加速 空白空间跳跃(Empty Space Skipping)
- 为什么不直接用 Clip Map 层级步进?因为不同 Clip Map 有 不同 LOD 级别,较大的 Clip Map 可能 缺少某些物体
- 粗糙图分辨率很低,每帧 全量更新整个体积:
- 采样全局距离场
- 执行若干次 Eikonal 传播迭代(Eikonal Propagation Iterations) 来扩展距离值
全局距离场追踪流程
- 从最小的 Clip Map 开始,逐级循环
- 每步先采样 连续的粗糙 Mip Map
- 若接近表面,再采样 稀疏砖块(Sparse Bricks)
- 找到命中后,用 6 次采样计算表面梯度,并从 Surface Cache 获取光照
近场追踪:影响力网格(Influence Grid)
核心思路
- 有了全局距离场作为 远场追踪的回退方案(Far-field Fallback),Mesh Distance Field 只需要负责 短距离追踪
- 不再需要 BVH 或世界空间网格,改用 影响力网格(Influence Grid)
- 每个格子存储一个 所有需要求交物体的列表——如果光线从该格子出发,就检测这些物体
影响力网格构建流程
- 视锥剔除(Frustum Culling):对所有场景物体进行剔除
- 标记活跃体素(Mark Active Froxels):只标记包含几何体的体素,避免在追踪时浪费时间
- 物体→体素分配:
- 第一轮:粗略的 包围盒测试(Bounds Test)
- 第二轮:精确的 距离场采样(Distance Field Sample)
- 紧凑化(Compact):将每个格子的物体列表压缩为 连续数组
像素追踪(GI / 反射)
- 加载光线起点所在的格子 → 遍历格子内所有物体 → 逐一 Ray March 直到找到最近命中
- 产生 非常简单且内存访问连贯(Coherent) 的追踪内核
方向光阴影射线(Directional Shadow Rays)
特殊挑战
- 方向光阴影射线是 平行的,无法依赖锥形足迹(Cone Footprint)随距离变宽
- 因此需要追踪 全长光线(Full Length Rays)
解决方案:光源空间 2D 网格
- 将物体剔除到 光源空间 2D 网格(Light Space 2D Grid) 中,每个格子包含从该格子出发射线需要求交的物体数组
- 填充方式:通过 光栅化物体的 OBB(Object Oriented Bounds) 来散布物体
- 在像素着色器中,用 Mesh Distance Field 采样 做精细剔除
- 压缩后,追踪阴影射线时:加载对应格子 → 遍历所有物体 → Ray March 直到找到任意命中即可停止(阴影只需 any-hit)
完整软件光线追踪管线
追踪按以下 分层级联顺序 执行:
Screen Space Traces(屏幕空间追踪)
↓ 未命中则继续
Short Mesh Distance Field Traces(短距离网格距离场追踪)
↓ 未命中则继续
Global Distance Field Traces(全局距离场追踪)
↓ 未命中则继续
Skylight Sampling(天光采样)
- 每一层都只处理上一层未解决的光线,逐步 从近到远、从精确到粗略 地求解
距离场的实际问题与解决方案
问题一:非封闭网格(Open Meshes)
- 很多网格不是封闭的(如扫描模型、单面几何体),光栅化没问题,但距离场会产生 伸出几何体外的负值区域,破坏追踪
- 解决方案:距离场生成时,在 4 个体素之后插入虚拟表面(即将负值距离在 4 个体素后回绕/截断)
- 并非完美——仍会导致光栅化与 Ray Marching 之间的 不匹配,但远好于巨大的负值区域
问题二:薄网格(Thin Meshes)
核心困难
- 距离场分辨率有限,无法表示小于两个体素间距的细节
- 薄墙若位于采样点之间,距离场永远不会产生零值或负值 → Ray Marcher 永远无法命中
- 梯度计算也会出错(薄墙周围梯度为零)
- 在 室内暗、室外亮 的常见场景中,哪怕 一条光线穿墙 就会导致 灾难性的漏光(Massive Light Leaks)
解决方案:距离场膨胀(Distance Field Expand)
- 将距离场膨胀 半个体素对角线(Half a Voxel Diagonal) 的距离
- 膨胀后可以 可靠命中 任何表面,梯度也会修正(计算点离表面更远,距离场值更可靠)
- 膨胀在运行时执行,保留原始距离场数据
膨胀的副作用
| 副作用 | 描述 |
|---|---|
| 过度遮挡(Over-Occlusion) | 膨胀使物体看起来"更胖",导致额外遮挡 |
| 表面偏移过大(Large Surface Bias) | 需要更大偏移来逃离表面,破坏接触阴影(Contact Shadows) |
改进:渐进式膨胀(Gradual Expand)
方案一:线性增长膨胀(用于 GI / 漫反射光线)
- 从表面出发时 膨胀为零,随着远离表面 线性增加膨胀量
- 这样光线初始段可以正常追踪,保留接触阴影
- 对于阴影射线,在光线末端也需要将膨胀 线性回退到零,避免命中光源所在的表面
方案二:基于距离的自适应膨胀(用于反射)
- 对于掠射角(Grazing Angles),线性增长膨胀太快,导致光线 自交(Self-Intersect)
- GI 和漫反射可以容忍,但 反射中自交表现很差(宁可轻微漏光也不要过度遮挡)
- 反射方案:每步根据 当前到表面的距离 尽可能多地膨胀,确保总是能逃离初始表面
实际效果
- 成功 保留了接触阴影,同时 可靠命中薄表面
- 对实体几何(如墙壁)效果极佳
问题三:植被(Foliage)
过度遮挡问题
- 距离场膨胀对 植被 效果很差——会完全阻止光线穿过树叶间隙
- 解决方案: 覆盖度(Coverage) 启发式
Coverage 机制
- 根据 双面材质(Two-Sided Material) 标记距离场实例
- 将此标记重采样为全局距离场的 独立通道(Separate Channel)
- Coverage 区分:
- 实心薄表面(如墙壁)→ 应阻挡所有光线
- 部分透明表面(如树叶)→ 应允许部分光线通过
追踪时的 Coverage 应用
- 每步采样 Coverage 值:
- 增大 Ray Marching 步长 → 更容易穿过树叶间隙
- 减小膨胀量 → 减少过度遮挡
- 使用 随机透明度(Stochastic Transparency):每次命中时根据 Coverage 概率决定是 接受命中 还是 继续追踪
植被动画问题
- 预计算距离场 不支持动画,导致自阴影问题
- 修复方式:在 Coverage 通道标记的植被上添加 额外表面偏移(Extra Surface Bias)
- 效果:树木不再完全阻挡光线,阳光可以穿过树叶并在树木之间反弹
距离场追踪的总结评价
适用场景
- 对 GI 和粗糙反射(Rough Reflections) 表现出色
- 可以解析细微的间接阴影细节(如灯具、电视投射到墙上的间接阴影)
- 不适合镜面反射(Mirror Reflections)
关键优势
| 优势 | 说明 |
|---|---|
| 无需特殊硬件 | 所有平台支持 |
| 引擎通用工具 | 距离场同时服务于 Lumen、粒子碰撞、物理碰撞等多种系统 |
| 可向下缩放 | 通过全局距离场将整个复杂场景(含大量实例重叠)合并为单一距离场,在运行时完成 |
Lumen Surface Cache:表面参数化与虚拟表面缓存系统
核心问题:距离场命中后如何着色?
距离场的局限
- 距离场 没有顶点属性(Vertex Attributes),无法在命中点运行材质着色器
- 只能获取 位置(Position)、法线(Normal)和网格实例数据(Mesh Instance Data)
- 因此需要一种 无 UV 的表面表示(UV-less Surface Representation) 来为命中点着色
为什么需要缓存?
- 自定义材质图(Material Graphs) 可能非常复杂,每条光线都求值代价太高
- 直接光照 涉及多个投射阴影的光源,开销大
- 多次反弹 更昂贵:每次命中需递归追踪多条光线,每条都要求值材质和光照
- 缓存可以 复用材质求值和光照计算结果,避免递归式多弹反射追踪
表面参数化的需求
- 基于表面空间(Surface Space):体积表示无法正确处理 薄墙(Thin Walls),会导致 漏光(Light Leaks)
- 可扩展(Scalable):能参数化复杂场景中 海量实例
- 分辨率可提升:能用于 反射(Reflections),需要高分辨率
其他方案为何不可行
| 方案 | 问题 |
|---|---|
| UV 展开 | 复杂网格产生大量 UV Chart,难以合并;需要顶点属性(距离场没有) |
| 体积 UV(Volumetric UVs) | 无法表示薄墙;远距离 LOD 方案不明确 |
| 体素颜色 / Surfels | 分辨率有限,无法用于反射 |
Lumen 的方案:投影卡片(Projected Cards)
什么是 Cards?
- 可描述为 轴对齐的均匀矩形 Surfel 簇(Uniform Rectangular Clusters of Surfels)
- 本质上是用 正交投影 捕获的网格表面参数化
Cards 的优势
- 基于投影:不需要任何顶点属性即可求值
- 规则结构:查找速度快
- 运行时捕获:可缩放到任意分辨率,无需预烘焙
- 支持双面薄墙:能正确表示两面的薄壁结构
Card 生成流程(网格导入时预计算)
约束与简化
- 所有 Cards 轴对齐(Axis-Aligned):简化生成和查找
- 尝试过自由朝向的 Cards,但难以放置且额外灵活性 收益不大
第一步:三角形网格 → 轴对齐 Surfel
- 将网格 体素化:每个 2D 格子发射 64 条光线 穿过物体
- 根据每个 3D 格子的光线命中数,超过阈值则生成 Surfel(表面元素)
- 记录 表面覆盖率(Surface Coverage):后续评估簇的重要性
- 记录 前一次光线命中位置:用于判断 Surfel 是否从簇的近平面可见
第二步:内外判定与遮挡计算
- 每个 Surfel 发射 64 条光线,统计 三角形背面命中数
- 多数命中为背面 → 该 Surfel 在 几何体内部 → 丢弃
- 基于命中平均距离计算 表面遮挡度(Surface Occlusion)
- 遮挡度用于确定 聚类该 Surfel 的重要性
第三步:初始聚类(K-Means 启发式)
生成策略:选取一个未使用的 Surfel,迭代式生长簇——
权重因子:
- 到簇边界的距离(优先选近的)
- Surfel 遮挡度(优先选最重要的)
- 簇的长宽比(Cluster Ratio)(优先选接近正方形的)
- 近平面可见性检查
生长过程:
- 持续添加最佳 Surfel,直到无有效候选
- 计算簇质心,从质心重新生长
- 达到重新生长次数上限或簇不再变化后,加入列表
- 寻找下一个未覆盖的 Surfel,重复
第四步:全局优化
- 从当前质心 并行重新生长所有簇
- 迭代直到达到上限或收敛
- 并行生长可能产生 过小的簇 或 空白区域:
- 每次迭代后 移除过小的簇
- 在空白区域 插入新簇
第五步:转化为 Cards
- 按 覆盖率排序 所有簇
- 选取用户指定数量的 最重要簇 转换为 Cards
虚拟表面缓存(Virtual Surface Cache)
两种相互冲突的需求
| 需求 | GI(全局光照) | 反射(Reflections) |
|---|---|---|
| Card 数量 | 多且小 | 少且大 |
| 分辨率 | 低分辨率(GI 低频) | 高分辨率(镜面反射需匹配屏幕像素密度) |
| 覆盖范围 | 一致覆盖一切 | 仅选定表面 |
- 典型案例:Matrix Awakens Demo —— 大量建筑实例需要 GI 反弹,同时多个反射表面需要高分辨率 Cards
虚拟页面管理
GI 页面:低分辨率、常驻(Always Resident)
- 基于 与相机的距离 在相机周围分配
- LOD 方案:移除过小的 Cards
反射页面:稀疏、按需分配(Sparse, On-Demand)
- 基于 反射光线命中点 分配
- 不再使用时 释放
反馈机制(Feedback System)
- 光线命中时写入反馈:记录需要的分辨率和更新频率
- 每次命中会采样并混合 多个页面 → 首先 随机选择最重要的一个(Stochastic Selection)
- 更新该页面的 最后使用时间,将请求的 Mip 级别 写入反馈缓冲区
- GPU 端压缩反馈:将请求插入 GPU 哈希表 后紧凑化
- 最终数组包含 唯一页面 + 每页命中次数
- 下载到 CPU 排序后,用于 映射(Map)和取消映射(Unmap) 页面
页面分配策略
| 情况 | 处理方式 |
|---|---|
| Card 大于页面大小 | 拆分为多个物理页面,分别分配 |
| Card 小于页面大小 | 子分配(Sub-allocation):一个物理页面内用 2D 分配器 放置多个小 Card |
- 子分配的优势:大页面不浪费边界空间,小分配不需要向上取整到物理页面大小
页面表回退(Page Table Fallback)
- 扁平化查找:请求缺失的高分辨率页面时,页面表自动指向 低分辨率常驻页面
- 一次查找即可获取结果,无需递归搜索回退页面
Card 捕获(Card Capture)
运行时渲染
- 使用 正交相机(Orthographic Camera) 将网格渲染到 Cards 中
- 写入表面属性:Albedo、法线 等
- 运行时捕获的优势:
- 可以 按需提升分辨率
- 支持 材质变化,无需管理预计算数据
更新策略:固定预算
- 每帧收集页面更新请求
- 按 与相机的距离 和 最后使用时间 排序
- 选取固定数量的 最重要页面 进行捕获更新
- 为支持 动画材质(Animated Materials),每帧额外更新少量 最旧的页面
Nanite 加速
- 传统方式渲染大量小网格会因 LOD 和大量小 Draw Call 而很慢
- 借助 Nanite:
- 单次 Draw Call 渲染所有几何体
- 连续 LOD 级别 简化渲染到小目标中的网格
- 大幅加速捕获,允许更频繁地更新 Cards
捕获输出
- 渲染材质和网格数据到 固定的、视角无关的 GBuffer 结构
- 对 高光(Specular)和次表面散射(Subsurface) 响应的处理:
- 通过 修改 Albedo 来近似补偿能量损失,而非完整存储这些属性
Lumen Surface Cache:采样、光照计算与全局集成
Surface Cache 采样流程
命中点查找与采样
- 查找 Card Grid:根据 网格索引(Mesh Index) 定位对应的 Card 网格
- 查找格子(Cell):在网格中定位格子,获取 6 张 Cards(对应六个轴对齐方向)
- 选择投影 Cards:根据 表面法线 选取 3 张最相关的 Cards 进行投影
- 逐 Card 采样:
- 从 Surface Cache 采集 4 个深度样本,执行 手动双线性过滤(Manual Bilinear Filtering)
- 用 Surface Cache 中存储的深度 与 光线命中深度的差值(Delta) 加权每个纹素,丢弃被遮挡的样本
- 用 Card 投影法线 加权纹素,防止投影拉伸(Projection Stretching)
- 丢弃标记为无效的纹素(Invalid Texels)
- 混合所有样本,计算命中点的最终 Surface Cache 属性
无效纹素标记
- 在捕获阶段标记 无效纹素(Invalid Texels):后续采样时跳过这些无有效数据的纹素
- 捕获时 禁用 Alpha 遮罩(Alpha Masking):需要区分"缺少表面缓存"和"Alpha 遮罩的表面点"
- 这也方便后续运行 Any-Hit Shader 时无需处理材质着色器
运行时压缩
- 捕获的 Surface Cache 数据在运行时进行 BC 压缩(BC Compressed),最大限度减少 内存开销
合并 Cards(Merged Cards)
问题:大量小实例聚合
- 某些内容由 许多小实例聚合成大物体(如建筑物由大量小构件组成)
- 要么生成 过多 Cards,要么 直接丢弃整个物体——都不可接受
解决方案
- 运行时合并 Cards:
- 自动检测 重叠的小实例组
- 或使用 用户提供的分组标签(Group Tags)
- 每个分组获得 6 张 Cards,从六个方向捕获(类似 立方体贴图 Cube Map)
- 假设观察者在聚合组 外部(通常成立),这是一个很好的近似
- 利用 Nanite 将整个组渲染到每张 Card 中,速度很快
Surface Cache 光照计算
多次反弹的重要性
- 没有多次反弹时,场景一半是黑的,反射也消失
- 直接光照的多条阴影光线或间接光照的递归追踪都 开销巨大
- 理想情况:所有光照都能从 Surface Cache 获取
类似光照贴图的挑战
- 从纹素追踪光线时,需要基于 表面法线和光线方向 设置合适的 偏移(Bias) 以逃离表面
- 某些纹素可能位于 几何体内部,双线性过滤会导致 穿墙漏光
- 解决方案:丢弃命中三角形背面的光线,使几何体内部的纹素变为黑色
光照更新策略
分页更新(Page-based Update)
- 光照 无法每帧全量更新,需要缓存并 每帧只更新一部分页面
- 页面选择依据两个属性:
- 上次使用时间(Last Used):GPU 反馈机制,每次光线命中时写入当前帧号
- 上次更新时间(Last Updated):每次页面更新时递增
- 直接光照和间接光照分别跟踪,更新比率不同:
- 直接光照更便宜,更新更频繁
- 间接光照更昂贵,更新更慢
页面选择:直方图法
- 构建 直方图(Histogram),从最重要的桶开始逐桶选取,直到达到 预算上限
页面重映射
- 当需要 调整 Card 大小或映射新页面 时,尝试 重采样之前的光照数据,避免丢弃昂贵的计算结果
直接光照管线
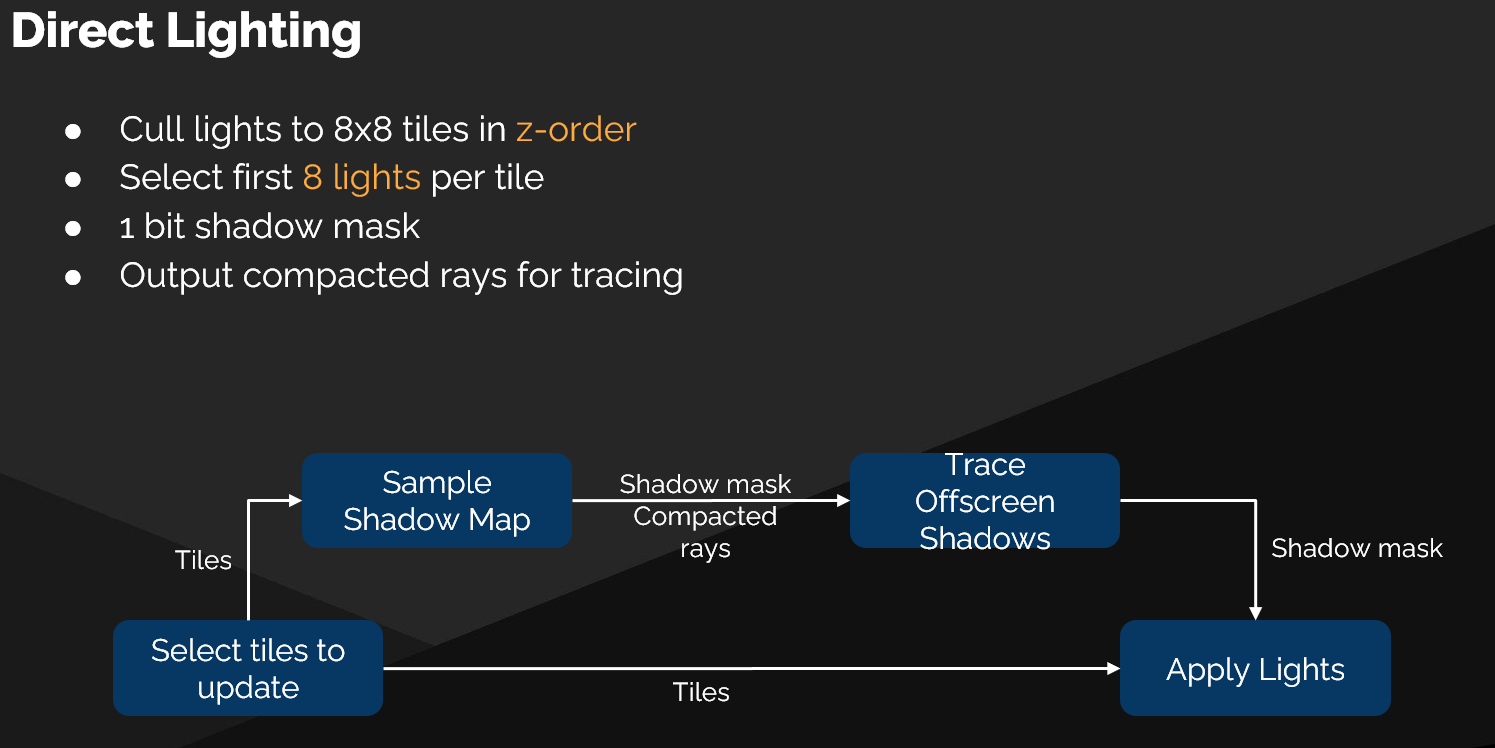
Tile 化与光源选择
- 将选中的页面切分为 8×8 Tiles
- 以 Z 序(Z-Order) 输出 Tiles,最大化 追踪连贯性(Trace Coherency)
- 每个 Tile 选择最多 8 个光源(目前取前 8 个,未来计划用更智能的选择策略)
阴影遮罩(Shadow Mask)
- 每个光源占 1 bit 的阴影遮罩,用于合成多种阴影方法
- 流程:
- 采样现有阴影贴图(Shadow Maps) 填充阴影遮罩
- 构建 无法由阴影贴图解决的阴影光线的紧凑列表(通常是相机背后的纹素)
- 追踪阴影光线 完成阴影遮罩
- 运行光照 Pass,使用阴影遮罩计算光照值
间接光照管线
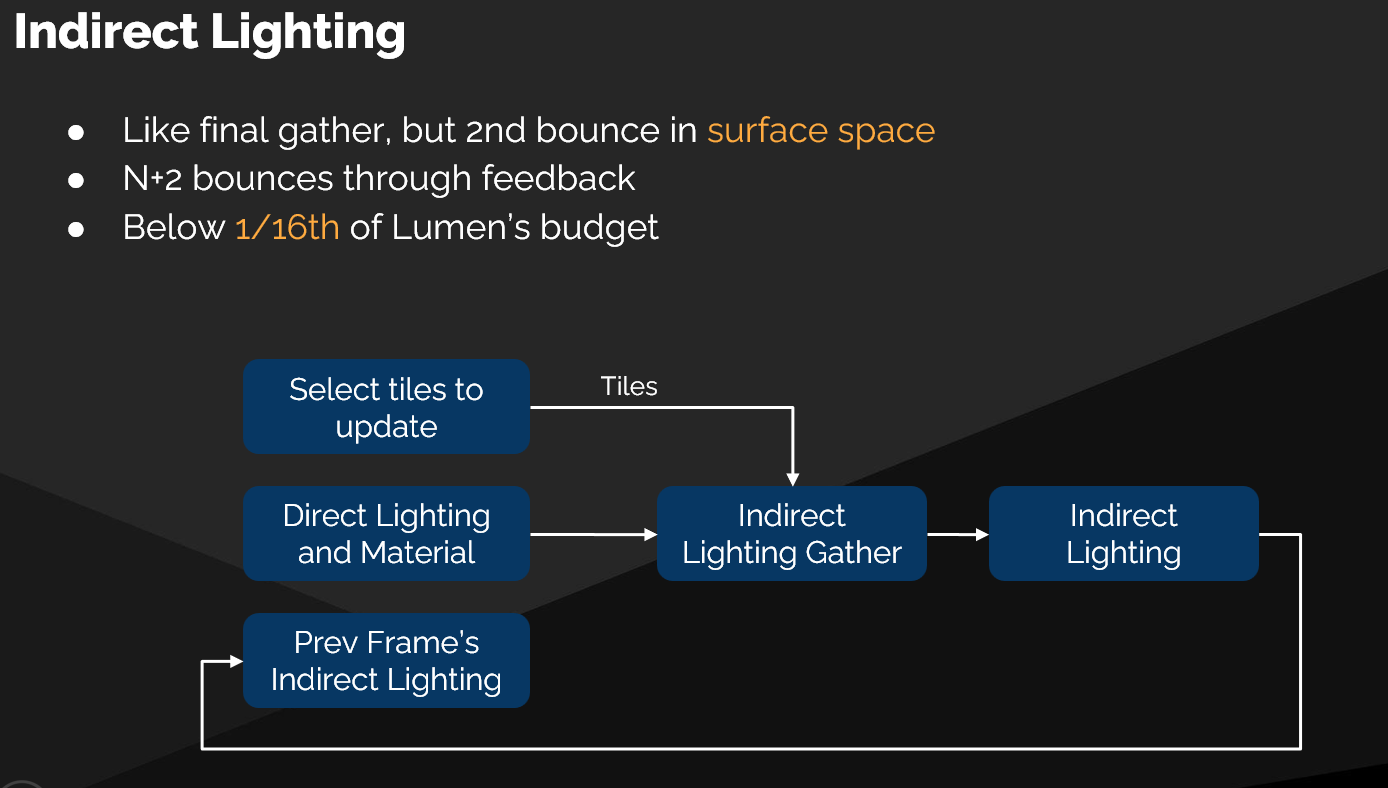
多次反弹实现
- 在 Surface Space 中执行 Final Gather(最终收集) 来计算二次反弹
- 每条间接光线命中时采样:
- 当前帧的直接光照
- 上一帧的间接光照
- 每帧计算 前两次反弹,后续反弹通过 反馈(Feedback) 逐帧累积
半球探针降采样追踪
- 预算极为有限,理想情况需要每纹素至少 64 条光线,但开销过大
- 解决方案:在 4×4 Tile 上放置 半球探针(Hemispherical Probe),仅从探针纹素追踪
- 实现 降采样追踪(Downsampled Tracing)
- 仍保留 表面法线细节
- 每帧基于 帧索引(存储在每个 Surface Cache 页面中) 旋转 探针位置和追踪方向
探针去噪与插值
- 低追踪数量导致探针 噪声很大,需要 空间和时间复用
- 每个纹素取 4 个最近探针 进行插值
- 防漏光启发式:
- 平面权重(Plane Weighting):用探针的平面方程跳过位于其背后的纹素
- 探针深度图可见性检查(Probe Depth Map Visibility):检查探针与目标纹素之间是否可见
- 插值结果 时序混合(Temporally Blended) 到间接光照图集中
- 跟踪 累积帧数,限制最多 4 帧 以减少 拖影(Ghosting)
品质对比
- Surface Cache 间接光照 vs 像素级 Final Gather:
- 二次反弹品质较低(受性能约束)
- 但 大致匹配像素级 Final Gather
- 对 漫反射多弹反射 和 粗糙反射 品质足够
- 通常也 足以应对镜面反射
全局距离场的光照采样:Voxel Lighting Volume
问题
- 全局距离场是 合并的场景表示,命中后 不知道是哪个网格实例,无法直接采样 Surface Cache
解决方案:全局 Clip Map 合并 Cards
- 将所有 Cards 合并到以相机为中心的 一组全局 Clip Map 中
- 每个体素存储 每轴对齐方向的辐照度(Radiance per Axis-Aligned Direction)
- 采样时在 方向之间和邻近体素之间进行插值
- Alpha 通道存储 权重(Weight):用于处理缺失命中和 Card 重投影到固定世界空间轴
缓存与增量更新
- 全量更新每帧太贵,利用缓存
- 类似全局距离场更新,追踪场景修改(Scene Modifications),仅更新 被修改的砖块
更新流程
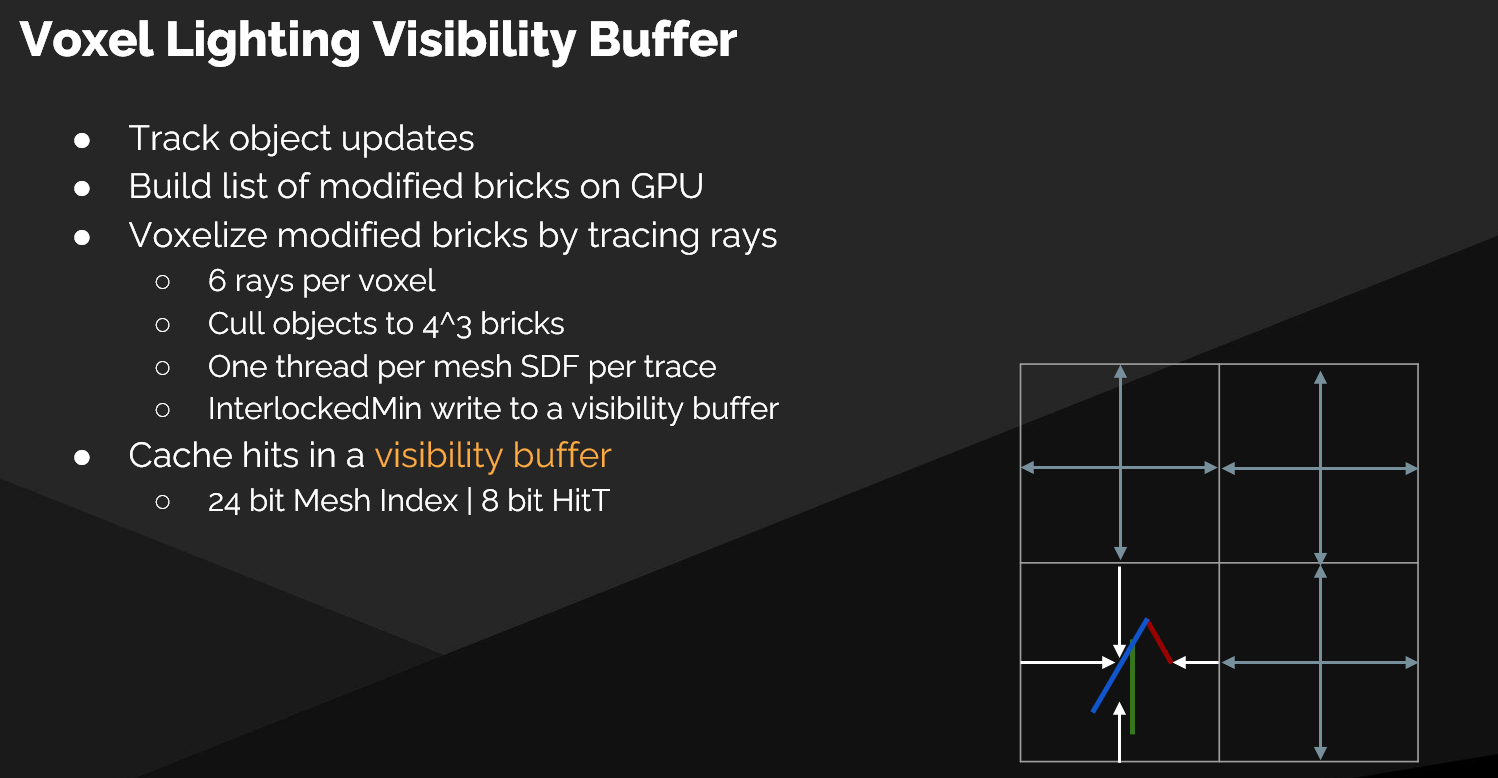
- 为每个修改过的砖块构建 内部物体列表
- 运行光线追踪 Pass:每线程一条追踪,Ray March 单个物体
- 输出到 可见性缓冲区(Visibility Buffer),使用 Atomic Min 写入
- 缓存几何追踪结果(而非光照),仅在 网格移动时重新追踪
- 光照变化难以追踪且可能每帧变化,因此缓存几何更合理
- 每帧着色整个可见性缓冲区:
- 先 紧凑化(Compact) 稀疏的可见性缓冲区
- 为每个有效条目采样 Surface Cache 计算最终光照
- 同时计算 投影权重,存入体素光照体积的 Alpha 通道
Surface Cache 的局限性
| 局限 | 说明 |
|---|---|
| 体素光照品质 | 仅有两张 Cards 的精度,未来需要改进 |
| 不支持网格动画 | Cards 在网格导入时放置,不支持骨骼动画;对树叶通过增加深度权重偏移(Depth Weight Bias)部分缓解,适用于小变形但 不适用于角色 |
| 多层网格 | 树木等多层结构无法用合理数量的层来展开;在反射中可能明显,但对漫反射光线仅导致少量 能量缺失 |
Surface Cache 的优势总结
- 使距离场追踪成为可能:为距离场命中点提供完整的材质和光照数据
- 通用缓存工具:缓存各种昂贵计算,不仅服务于软件追踪,也为 硬件光线追踪 提供快速路径——跳过昂贵的命中点材质和光照求值
- 高品质多次反弹:对可信的全局光照和反射至关重要
Lumen 硬件光线追踪(Hardware Ray Tracing)
动机与目标
使用硬件光线追踪的三大理由:
- 精确的光线-物体求交:使用原始三角形数据计算精确交点
- 动态材质与光照求值:使 清晰的屏幕外反射(Sharp Offscreen Reflections) 成为可能
- 现代主机硬件支持:硬件光追在主机上的普及使该技术的覆盖面大幅扩展
早期实验:整合 UE4 模型
UE4 光追反射模型
- Lumen 硬件光追最初从 反射(Reflections) 入手
- 直接整合了 UE4 的光追反射模型:提供了即时的动态材质和光照求值方案
UE4 模型的核心缺陷:镜面遮蔽缺失
- 最显著的问题:缺少正确的镜面遮蔽(Specular Occlusion)
- 表现:镜面球中,未被遮挡的天光(Unshadowed Skylight) 在室内添加了不自然的蓝色色调
- 这个问题在多个场景中都清晰可见
Surface Cache 管线(快速路径)
核心思路
- 放弃动态求值,完全依赖 Surface Cache 进行光照查找
- 定位为硬件光追的 快速路径(Fast Path)
激进优化策略
| 优化措施 | 效果 |
|---|---|
| 强制 BVH 中所有物体为不透明 | 消除 Any-Hit Shader,避免其运行时开销 |
| 单一 Closest-Hit Shader | 替代 UE4 的多材质 Closest-Hit Shader,仅提取 几何法线 和 Surface Cache 参数化数据 |
| Ray Generation Shader 完成光照 | 以法线加权的 Surface Cache 求值方式应用光照 |
Surface Cache 的优势
- 单次求值同时获得直接光照和间接光照
- 解决了 UE4 模型的天光遮蔽问题,修正了镜面遮蔽
Payload 大幅瘦身

| 管线类型 | Payload 大小 | 存储内容 |
|---|---|---|
| UE4 高质量模型 | 64 字节 | G-Buffer 类参数:Base Color、Normal、Roughness、Opacity、Specular 等 |
| Surface Cache 模型 | 20 字节 | Surface Cache 查找所需的最少参数 |
- Payload 中有若干位标记为 Material 位,虽然 Surface Cache 管线本身不需要,但用于后续 Hit Lighting 管线的排序阶段
Shader Binding Table 简化
- 新模型的绑定循环 不再需要获取材质相关资源,显著节省 CPU 时间
- 但 无法完全消除绑定循环:DXR 中需要顶点和索引缓冲区绑定来重建表面法线,且 UE5 目前不使用 Bindless 资源
两种光照评估模式
混合策略的探索
- 将两种模型混合,可以按需 条件性分离 Surface Cache 的各项(Albedo、直接光照、间接光照),根据需要的动态求值级别灵活选择
- 这也提供了一种机制:将 Surface Cache 的间接光照 与 UE4 模型的动态求值 结合,从根本上解决天光遮蔽问题
关键发现
- 部分动态求值(Partial Dynamic Evaluation)的开销与完全动态求值几乎相同
- 因此最终只暴露 两种配置:
| 模式 | 描述 | 用途 |
|---|---|---|
| Surface Cache 模式 | 完全使用 Surface Cache 查找 | 通用快速路径 |
| Hit Lighting 模式 | 修改后的 UE4 模型 + Surface Cache 间接光照 | 仅用于反射 |
Hit Lighting 管线
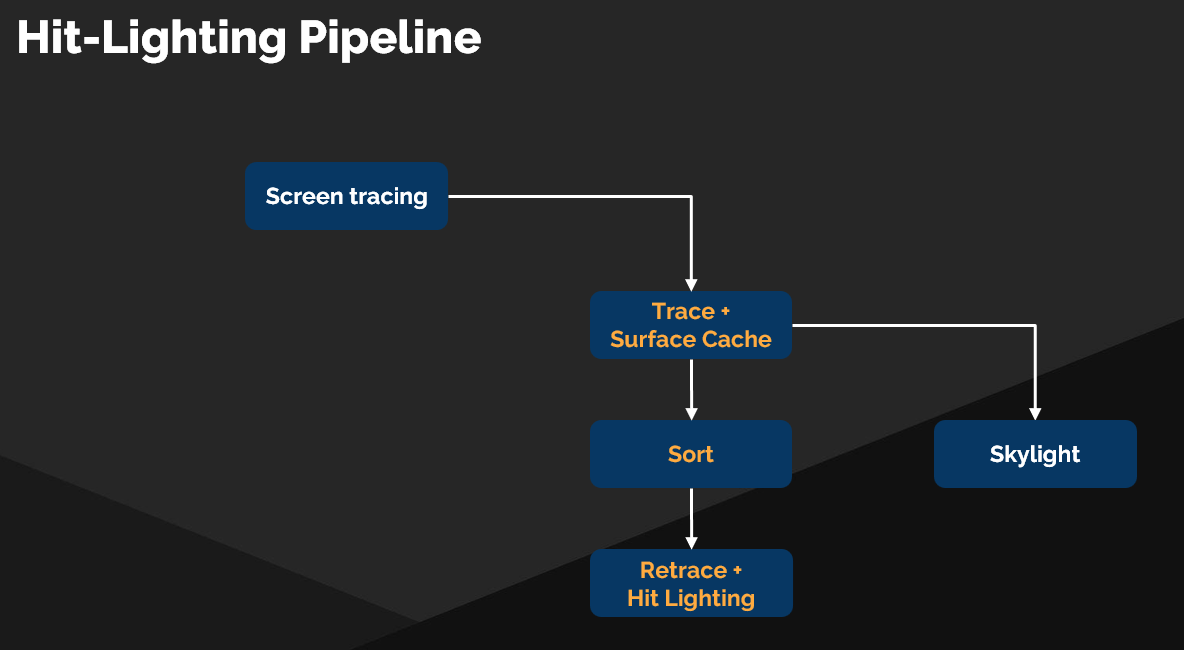
- 实现了修改版的 排序延迟追踪管线(Sorted Deferred Tracing Pipeline)
- Surface Cache Payload 中包含 Material ID,正是为排序优化服务
- 流程:
- Surface Cache 追踪阶段(也作为 Hit Lighting 的前置阶段)
- 排序(Sorting)
- 重新追踪(Retracing) 进行动态材质和光照求值
- 灵活性:可以 逐光线选择 是否启用动态求值
- 例如:对 没有 Surface Cache 参数化的网格(如骨骼网格 Skeletal Mesh)启用 Hit Lighting
- 镜面球中骨骼网格的直接光照反射 只有 Hit Lighting 模式才能实现
半透明与 Alpha 遮罩处理
核心挑战
- Surface Cache 管线将所有几何体视为 完全不透明,消除了 Any-Hit Shader
- 但部分不透明几何体需要特殊处理
两种材质策略
| 材质类型 | 处理方式 |
|---|---|
| 半透明材质(Translucent) | 完全跳过该网格 |
| Alpha 遮罩材质(Alpha Masked) | 求值 Surface Cache 不透明度,若低于 50% 则跳过 |
迭代穿越方案
- 由于没有 Any-Hit Shader,在 Ray Generation Shader 中迭代穿越场景
- 遇到部分不透明表面时继续追踪
- 迭代次数由 Max Translucent Skip Count 参数控制
- 可正确处理:
- 穿越半透明几何体片段
- 通过 Surface Cache 不透明度重建 Alpha 遮罩
GPU 驱动管线与 DXR 1.1
调度控制需求
- Lumen 的 GPU 驱动管线不直接操作屏幕像素,而是操作 Probe、Surface Cache 纹素、屏幕 Tile
- 硬件光追在很多情况下是 次级追踪类型,作为 回退技术(Fallthrough Technique)
- 因此必须使用 间接调度(Indirect Dispatch)
DXR 1.1 语义
- PC 平台 Lumen 优先使用 DXR 1.1 语义
内联光线追踪(Inline Ray Tracing / Ray Query)
| 特性 | 优势 |
|---|---|
| 避免 Shader Binding Table 复杂性 | 可在标准 Compute Shader 和 Pixel Shader 中使用硬件遍历 |
| 编译器优化空间大 | Ray Generation 模式下需手动最小化跨 Trace Call 的活跃状态(Live State),内联追踪编译器可自动优化 |
| 主机平台已使用 | 主机光追内建函数可直接提供几何法线,无需额外顶点/索引缓冲区 → Surface Cache 管线可完全使用内联光追,显著提速 |
PC 的限制
- PC 上 Surface Cache 管线 无法完全使用内联光追:因为需要向 Hit Group Shader 提供 网格特定的顶点和索引缓冲区数据
The Matrix Awakens 面临的挑战
Nanite 回退网格(Nanite Fallback Meshes)
- The Matrix Awakens 场景极其复杂
- 需要将 Nanite 网格 纳入硬件光追的 BVH 中
- 使用 回退网格(Fallback Meshes) 作为 Nanite 几何体在光追加速结构中的代理
远场追踪(Far-Field Tracing)
- 需要将追踪距离扩展到 远场
- 处理超大规模开放世界中的光线追踪覆盖范围
完整硬件光追管线总结
最终 UE5 发布的硬件光追管线包含:
- Surface Cache 追踪阶段(快速路径,20 字节 Payload)
- 可选的 Hit Lighting 阶段(排序 + 重追踪,用于反射中的动态材质/光照求值)
- 半透明/Alpha 遮罩迭代穿越
- GPU 驱动的间接调度
- DXR 1.1 + 内联光追(主机上充分利用)
- Nanite 回退网格集成
- 远场追踪扩展
Lumen 硬件光线追踪:大规模场景、Nanite 集成与最终管线
The Matrix Awakens 的挑战
规模与性能压力
| 挑战 | 细节 |
|---|---|
| 海量实例数 | 内容规模从 50 万接近 100 万活跃实例,远超初始实验的 10 万上限 |
| 大量动态物体 | 大量车辆和行人需要频繁 BLAS 动态 Refit |
| 材质复杂度 | Master Material 包含大量指令和数十次 虚拟纹理采样(Virtual Texture Fetches) |
| 目标平台 | Xbox Series X/S 和 PS5——有原生光追支持,但计算能力和遍历速度 弱于高端 PC |
Hit Lighting 不可行
- 材质复杂度使 Hit Lighting 模式的 求值成本极高(PS5 上的计时报告显示开销惊人)
- 即使质量方面,由于 Demo 对 天光项(Skylight Term) 的强烈依赖,两种管线现在都从 Surface Cache 获取天光,Hit Lighting 并未带来显著质量提升
- 原计划对动态物体使用 Hit Lighting,但 预算不足
主机 API 的优势
- 主机 API 提供更大的光追管线 灵活性
- 静态网格的加速结构可以 预构建并流式加载(Pre-built & Streamed),显著减少每帧的 BLAS 构建/Refit 时间
Nanite 与硬件光追的兼容问题
核心矛盾
- Matrix Awakens 中绝大部分资产使用 Nanite 渲染
- 但加速结构 无法支持 Nanite 原生几何分辨率
- 原因包括:
- Nanite 的动态 LOD 与 BVH 结构不兼容
- 高质量 Nanite 光追支持仍是 活跃的研究领域
解决方案:Nanite Fallback Mesh
- 使用 Nanite 回退网格(Fallback Meshes) 作为光栅化几何的简化表示,存入 BLAS
- 但回退网格 不保证与基础网格的拓扑一致性
自交叉问题(Self-Intersection)
- 从 G-Buffer 直接追踪光线时,回退网格的近似形状会导致 自交叉伪影
- 传统的 Ray Bias 无法有效解决
- 在车辆渲染中尤为明显
解决方案:两阶段追踪
参考 Tchiboukdjian & Lermusiaux(2004)的方案,但完整实现太昂贵,改用简化版:
第一阶段:发射短光线(到定义的 epsilon 距离),忽略背面(Ignore Back Faces)
第二阶段:成功穿越 epsilon 后,发射长光线,不带面朝向属性限制
- 屏幕空间追踪 也能缓解自交叉(提供与视锥对齐的起始 t 值),但在 帧边缘不可靠
- 最终 两种技术同时使用
远场追踪(Far-field Tracing)

问题:限制追踪距离的代价
- 为控制性能,将最大追踪距离限制为 200 米,与光追网格剔除距离对齐
- 但这导致:
- 车辆反射中 看不到远处天际线
- 全局光照的 天空遮蔽完全丢失,产生严重漏光
解决方案:利用 HLOD 系统
- 使用 World Partition 的 HLOD 表示:网格被 简化并合并,为远距离几何创建聚合体
- 特殊之处:由于追踪距离受限,需要在光栅化器通常还不需要替换时就 提前引入 HLOD
- 导致 两种网格表示同时占据 TLAS 中相同空间
近场/远场分离
- 用 Ray Mask 标记 HLOD 网格为 远场几何(Far-field Set)
- 追踪分为两阶段:
| 追踪类型 | 流程 |
|---|---|
| 有序遍历(Ordered Traversal) | 先追踪 近场 → 未命中的光线 → 再追踪 远场 |
| 阴影光线(Shadow Rays) | 先远场,后近场(远场实例更少、几何更简单,遍历更快) |
TLAS 重叠问题
- 将近场和远场几何放入同一 TLAS 不理想:产生不必要的几何重叠
- 虽然 Ray Mask 避免了多余遍历,但对 TLAS 构建质量的损害严重
- 早期实验显示:叠加远场表示导致近场遍历成本 增加 44%
解决方案:平移偏移(Translational Offset)
- 理想方案是支持 多 TLAS,但在紧张的开发周期中不适合做此架构变更
- 折中方案:对远场几何应用 全局平移偏移
- 仍有性能损失,但偏移 显著降低了开销
远场追踪的视觉影响
- 反射遮蔽(Reflection Occlusion) 改善最为显著
- 远处的 全局光照贡献 也得到恢复
- 整体质量提升明显
最终分层遍历管线(Final Tiered Traversal Pipeline)
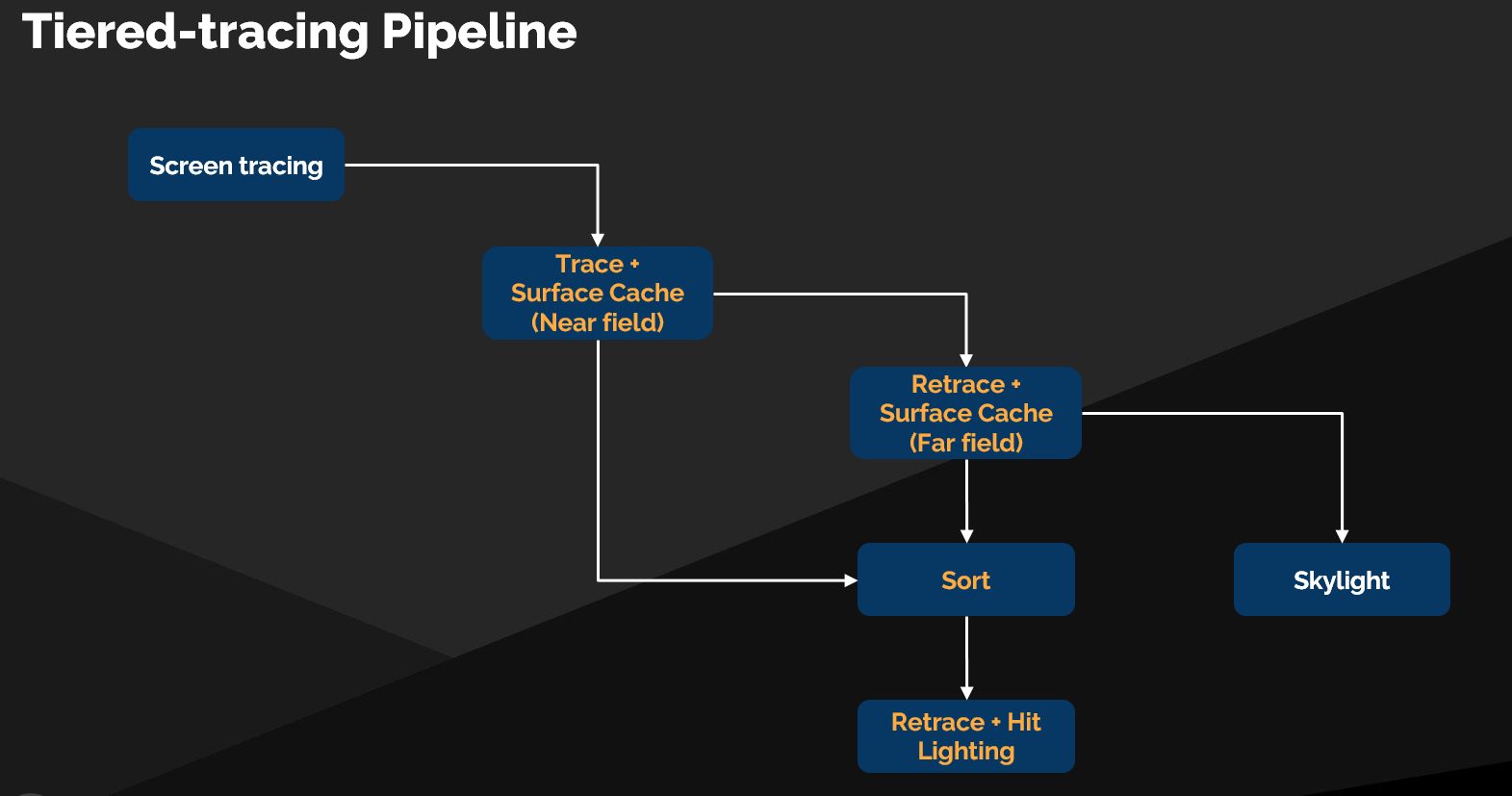
两种着色模型
| 模式 | 目标 |
|---|---|
| Surface Cache 模式 | 速度优先 |
| Hit Lighting 模式 | 质量优先(仅用于反射) |
两种几何表示
| 表示 | 特性 |
|---|---|
| 近场(Near-field) | 高质量几何,有限追踪距离 |
| 远场(Far-field) | 低质量但更高性能,扩展追踪距离 |
完整管线流程
1. Surface Cache 阶段(近场 + 远场级联)
├── 命中 → 可选地排队进入 Hit Lighting
└── 未命中 → 级联到下一级
2. Hit Lighting 阶段(可选,仅反射)
├── 近场命中 → 压缩 & 排队
└── 远场命中 → 压缩 & 排队
3. 未命中 → 天光求值(Skylight Evaluation)
优化策略
- 先解决所有 Surface Cache 阶段,再可选地将结果排队给 Hit Lighting,最小化 Dispatch 开销
- 中间添加 压缩步骤(Compaction):将近场未命中的光线整理为新的 Ray Tiles,再间接 Dispatch 追踪远场
总结
硬件光追模型相比 UE4 原始模型的三大改进:
- Surface Cache 集成:构建了 极简遍历方案,以性能为核心设计
- 远场几何表示:解决了海量实例的复杂度问题,同时 显著扩展了有效追踪距离
- 几何 LOD 不匹配处理:解决了将复杂 Nanite 资产纳入光追时的 固有几何 LOD 差异问题
Lumen 光线追踪方法:性能对比与选择指南
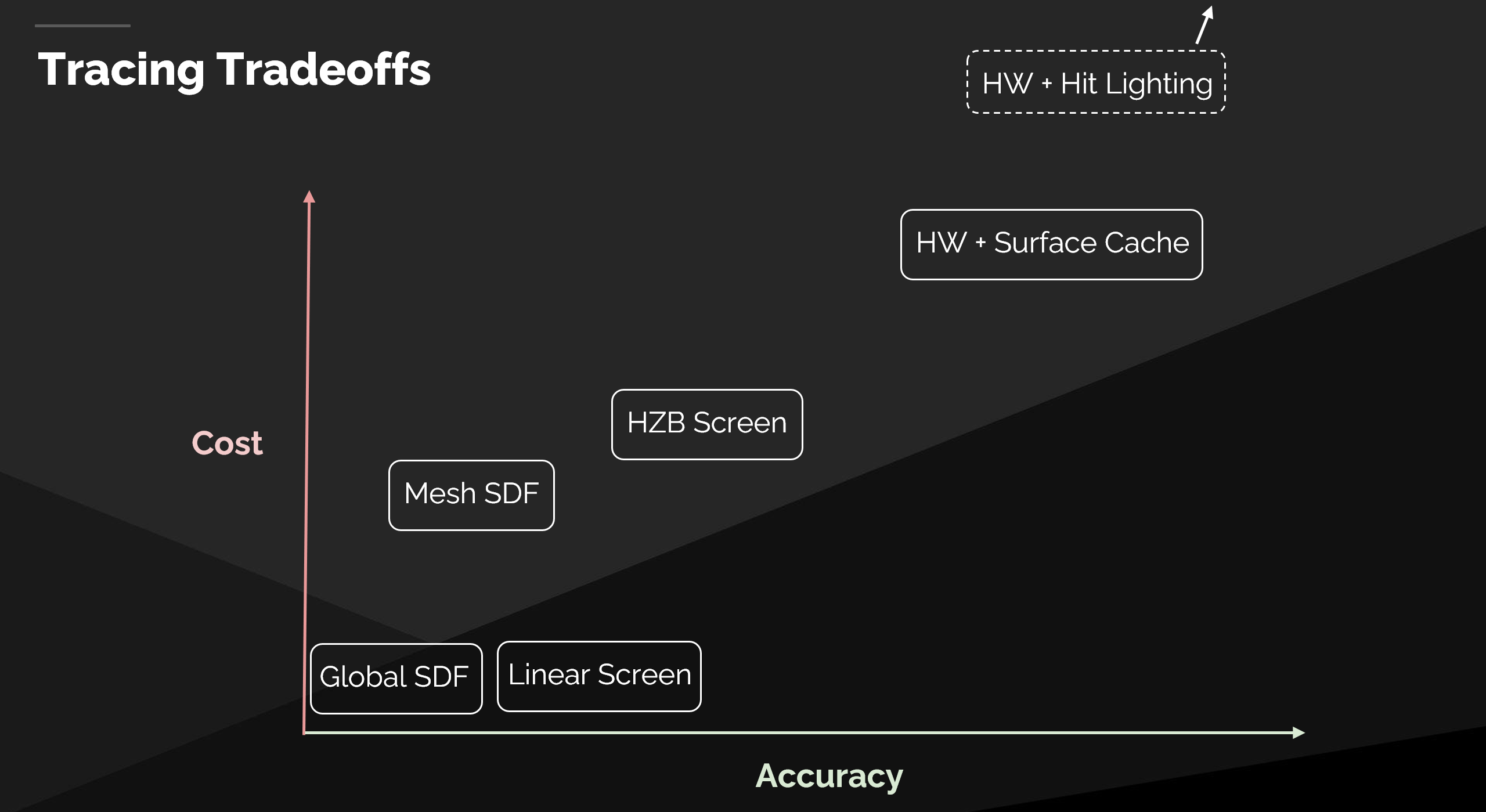
追踪方法总览:成本 vs 精度
| 追踪方法 | 成本 | 精度 | 备注 |
|---|---|---|---|
| 全局距离场追踪(Global SDF) | ★☆☆☆☆ 最低 | ★☆☆☆☆ 最低 | 需搭配更精确的方法(屏幕追踪或 Mesh SDF) |
| 软件光线追踪(Software RT) | ★★☆☆☆ 较低 | ★★★☆☆ 中等 | 屏幕追踪 + Mesh SDF + 全局 SDF 组合 |
| 硬件光线追踪 - Surface Cache | ★★★★☆ 较高 | ★★★★☆ 较高 | 精确三角形求交,Surface Cache 光照 |
| 硬件光线追踪 - Hit Lighting | ★★★★★ 极高(超出图表范围) | ★★★★★ 最高 | 动态材质 + 光照求值,仅用于反射 |
项目选择指南
选择软件光线追踪的场景
- 需要 最快追踪速度:如次世代主机上的 60 FPS 目标
- 大量重叠网格、Kit-bashing 风格内容
- 案例:Lumen in the Land of Nanite、Valley of the Ancients
选择硬件光线追踪的场景
- 需要 最高质量:如 建筑可视化(Architectural Visualization)
- 需要 镜面反射(Mirror Reflections)
- 需要 蒙皮网格(Skin Meshes) 显著影响间接光照
- 案例:The Matrix Awakens
实际场景性能对比
场景一:Lumen in the Land of Nanite
特征:巨大的网格重叠量(每个洞穴表面点约 100 个重叠网格)
本质上是 Nanite 压力测试
硬件光追:极其昂贵 ——光线必须遍历每一个重叠网格
⚠️ 性能完全不可接受,无法发布
软件光追:快速的合并版本(Merged SDF),
不受重叠网格数量影响
✅ 唯一可行的选择
场景二:Lyra(UE5 示例游戏)
特征:几何体基本不重叠
硬件光追:表现良好
软件光追:表现良好
→ 两者成本差异不大,质量差异也不大
→ 取决于硬件支持情况,两者皆可
场景三:The Matrix Awakens
特征:开放世界城市场景
硬件光追:成本与软件光追几乎相同
+ 更高质量的反射
+ 远场 GI 支持巨大视距范围
✅ 更好的选择
软件光追:成本相当,但质量略逊
关键洞察
没有一种追踪方法在所有场景都最优。 Lumen 提供两种追踪方法作为项目级别的选择,而非一刀切的方案。
核心决策因素:
- 内容结构:重叠网格多 → 软件光追;几何简洁 → 硬件光追皆可
- 质量需求:镜面反射 / 最高品质 → 硬件光追
- 性能预算:60 FPS / 主机平台 → 软件光追
- 硬件能力:是否支持原生光追加速
这种灵活的分层架构正是 Lumen 的设计核心——通过 共享的 Surface Cache 和 统一的光照管线,使两种追踪方法可以无缝切换,而上层的全局光照和反射系统不受影响。
Lumen Final Gather:屏幕空间辐射缓存与降噪管线
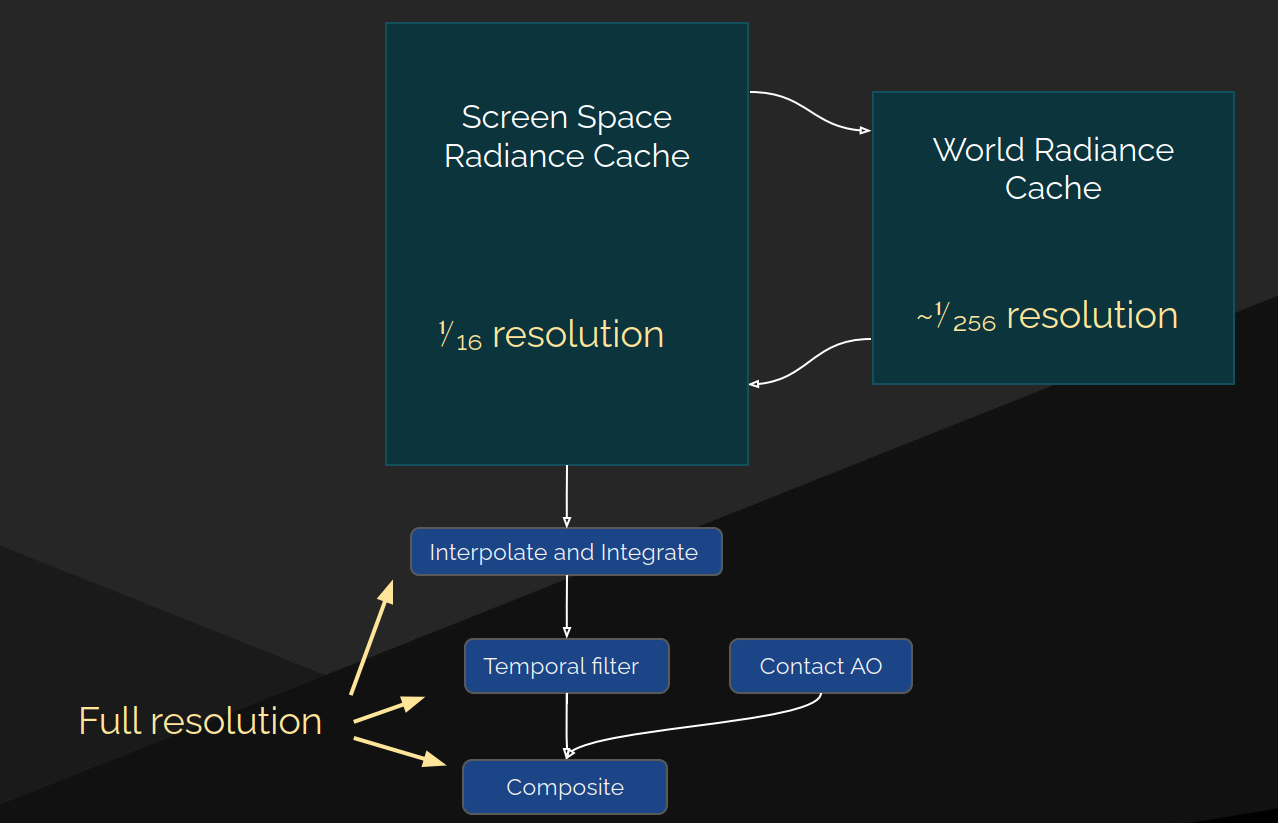
核心问题:光照传输中的噪声
- 每像素连一条光线都无法负担——左图展示了每像素一条路径的效果:充满噪声
- 高质量室内 GI 需要 数百个有效采样
- 这是实时间接光照需要解决的 第三个基本问题
早期实验:预过滤锥体追踪(Cone Tracing)
原理
- 对 Mesh SDF 进行锥体追踪
- 锥体与表面相交时,根据 锥体交叉尺寸 计算 Surface Cache 的 MIP 级别进行采样 → 获得预过滤光照
- 锥体与表面擦过(Near Miss)时为 部分遮挡 → 转化为透明度问题
- 利用距离场获取 锥体轴到表面的距离,近似遮挡量
- 多个无序的部分命中通过 加权混合 OIT(Weighted Blended OIT) 合并
优势
- 单条锥体等效于 多条光线的结果,极大降低噪声
- 没有硬边缘,不会产生噪声
致命缺陷
| 问题 | 描述 |
|---|---|
| 漏光 vs 过度遮挡 | 始终需要在两者之间取舍,无法同时解决 |
| 小型远距窗口 | 无法解析来自远处小窗户的光照 |
| 仅支持软件光追 | 无法与硬件光追兼容 |
→ 最终放弃锥体追踪,转向 蒙特卡洛积分(Monte Carlo Integration)
现有方案的两个极端
极端一:辐照度场(Irradiance Fields / Probe Volumes)
- 在体积中放置探针,预积分辐照度,插值到屏幕像素
- 核心问题:辐照度在 探针处 而非 像素处 计算
- 导致 漏光和过度遮挡
- 探针放置极难调对
- 体积表示 → 只能负担 低空间分辨率 → GI 看起来 平坦
极端二:逐像素追踪 + 屏幕空间降噪
- 从实际像素追踪,事后用屏幕空间降噪器处理噪声
- 问题:
- 降噪器需要 去相关的光线集(覆盖完整半球)→ 光线 不连贯,追踪慢
- 降噪操作在 屏幕空间 进行 → 开销极高
- 没有降采样过滤的机会
- 遮挡揭露(Disocclusion)问题:新暴露区域样本不足,无法收敛
Lumen 的方案:屏幕空间辐射缓存(Screen Space Radiance Caching)
核心思想
我们想要 逐像素追踪的精度(如间接阴影),但成本 显著低于 逐像素追踪方案。
- 从放置在像素上的探针(Screen Probes)追踪 → 本质上是 自适应降采样
- 每个维度约 1/16 分辨率
- 探针 均匀放置,几何细节多的区域 细分放置更多探针
- 追踪后将辐射度 插值到同一平面内的其他像素 → 限制漏光仅在同一平面内(难以察觉)
- 探针放置网格逐帧 抖动(Jitter),通过 时间累积 获得良好覆盖
Final Gather 三大组成部分
┌─────────────────────────────────────────────────────┐
│ 全分辨率层 │
│ 插值 → 积分 → 时间滤波 → Contact AO │
├─────────────────────────────────────────────────────┤
│ 屏幕空间辐射缓存(Screen Space) │
│ ~1/16 分辨率,处理近距离光照 │
├─────────────────────────────────────────────────────┤
│ 世界空间辐射缓存(World Space) │
│ 更低空间分辨率,更高方向分辨率 │
│ 处理远距离光照(>2m) │
└─────────────────────────────────────────────────────┘
场景构建过程(从远到近)
- 天光(Skylight):基础环境光
- + 世界空间辐射缓存:解决 2 米以外的光照(如左侧墙壁)
- 墙上的探针精确解析了 窗户光照
- 但右侧探针可能 穿墙可见
- + 屏幕空间辐射缓存:捕获所有近距离光照 → 产生 间接阴影(降采样空间)
- + Contact AO:弥补降采样丢失的 遮蔽细节
屏幕空间辐射缓存详解
大空间滤波的低成本实现
- 在 探针空间 而非 屏幕空间 过滤
- 探针空间的 3×3 滤波核 ≈ 屏幕空间的 48×48 滤波核 的降噪效果
- 只需加载 探针位置,无需加载所有像素的位置和法线
重要性采样(Importance Sampling)
- 使用上一帧屏幕空间辐射缓存 重投影到当前帧 作为入射光照的 精确估计
- 辐射缓存按 方向和位置索引,可高效查找上一帧的所有光线
- 重投影失败时(如屏幕边缘)→ 回退到 世界空间辐射缓存,仍保持有效的重要性采样
乘积重要性采样(Product Importance Sampling)

通常只在离线渲染中可行,Lumen 实现了实时版本。
- 降采样空间中可以负担 每探针启动整个线程组 来做更好的采样
- 优于仅采样 BRDF 或仅采样光照,也优于 多重重要性采样(MIS)(MIS 会丢弃低权重方向的追踪工作)
示例:墙上探针的乘积重要性采样
左:BRDF → 仅单半球方向有效
中:上一帧入射光照 → 大部分光照来自两个方向
右:乘积采样 → 将无用光线重新分配到最重要的方向
白色光线 = 超采样最重要方向的生成光线
- 效果:等效于追踪 4 倍光线的质量,实际不追踪更多光线
世界空间辐射缓存详解
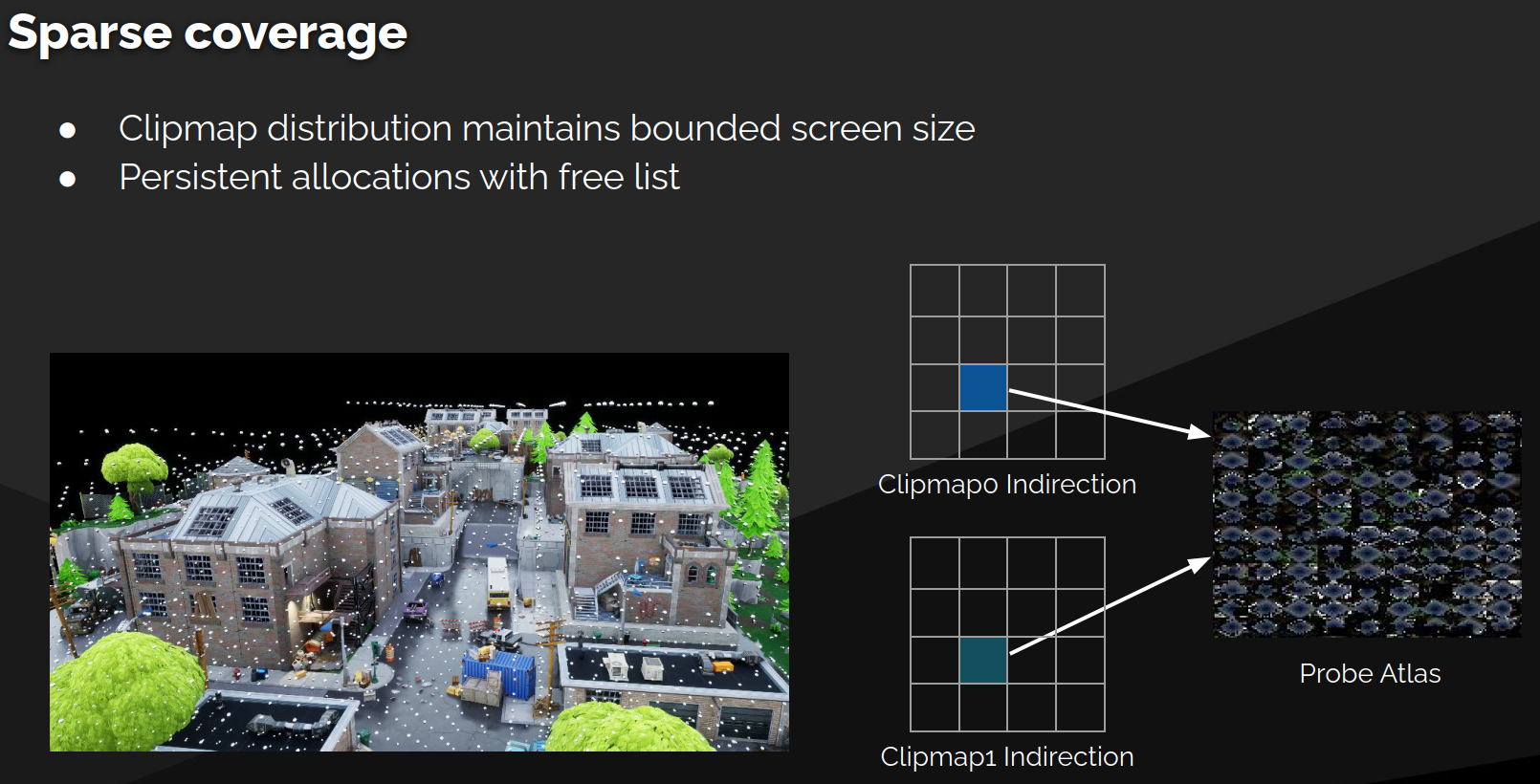
定位
- 处理 远距离光照:更高方向分辨率,更低空间分辨率
- 解决关键场景:房间内所有光照来自远处小窗户——少量光线极易错过
与屏幕空间缓存的集成
- 缩短屏幕探针光线,未命中时 → 从世界空间辐射缓存 插值
- 世界空间缓存探针位置 稳定 → 误差稳定 → 容易隐藏
空间分布
- 使用 Clip Map 分布,维持探针间 有界屏幕尺寸
- 避免过采样或欠采样
- 覆盖稀疏但足够
持久化与更新
- 探针使用 持久分配(Persistent Allocations),跨帧存活
- 帧间复用:携带上一帧仍需要的探针到新帧
- 新探针追踪:相机或场景运动揭露的新位置
- 子集重追踪:传播光照变化穿过世界
GPU 优先队列(改进)
- 使用 GPU 优先队列 选择固定数量的探针更新
- 为整个缓存提供 固定更新成本,即使输入变化
Matrix Awakens 夜间模式压力测试
- 完全由 自发光网格 照明,大部分光照来自 小型明亮灯泡网格
- GI 方法需处理直接光照(非显式采样光源)→ 极端压力测试
- 世界空间辐射缓存以 更高方向分辨率 更精确地解决直接光照
- 时间稳定性优异
全分辨率时间滤波器
设计原则
- 需要 稳定的时间滤波器 来掩盖探针位置和方向的抖动
- 不使用邻域钳制(Neighborhood Clamp)
- 改为基于 深度和法线差异 拒绝历史样本
- 结果非常稳定,但 对光照变化反应慢 → 移动物体后出现 鬼影(Ghosting)
改进措施
| 措施 | 原理 |
|---|---|
| 快速运动物体检测 | 检测光线命中快速移动物体 → 加速该像素的时间滤波器 |
| Contact AO 后置 | 最短距离遮蔽在时间滤波 之后 应用 → 零延迟 |
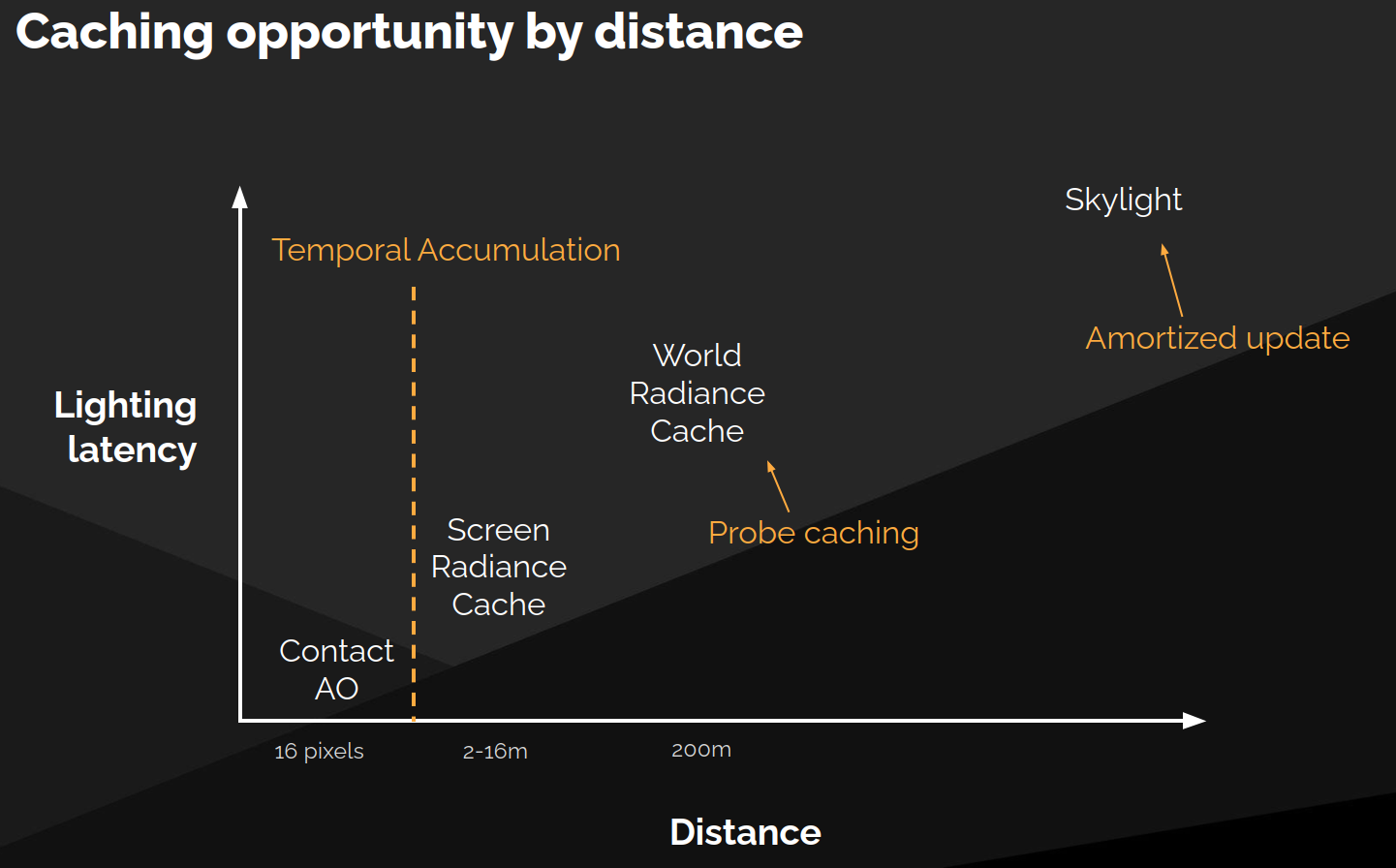
分层延迟容忍
大多数动态场景变化中,远距离光照可以容忍更多延迟。
| 光照范围 | 延迟容忍度 | 缓存策略 |
|---|---|---|
| 最短距离间接光照 | ⚡ 零延迟 | Contact AO 在时间滤波后即时应用 |
| 屏幕空间辐射缓存 | 🕐 少量延迟 | 时间累积 |
| 世界空间辐射缓存 | 🕐🕐 中等延迟 | 整个探针跨帧复用 |
| 天光 | 🕐🕐🕐 大量延迟 | 多帧缓慢更新 |
Lumen 的 Final Gather 天然适配这种分层延迟利用——因为它本身就将辐射度按距离范围分离,用不同技术解决。
设计总结
核心洞察:
├─ 锥体追踪降噪好但漏光不可解 → 放弃
├─ 体积探针精度低,逐像素追踪太贵 → 需要中间方案
├─ Screen Probes = 自适应降采样的像素级探针
│ ├─ 探针空间小核 = 屏幕空间大核 → 廉价大范围滤波
│ ├─ 乘积重要性采样 → 4× 等效质量无额外成本
│ └─ 同平面插值 → 漏光极小
├─ World Space 缓存补充远距离高方向分辨率
│ └─ 解决小窗户照亮大房间的经典难题
└─ 分层延迟容忍 → 各层按需缓存,最大化复用
Lumen:半透明/雾气 GI、反射系统、性能与未来展望
半透明与雾气的全局光照
挑战
| 约束 | 描述 |
|---|---|
| 多层半透明 | 必须支持任意数量的半透明层(如灰尘粒子) |
| 雾气 GI | 需要在整个可见深度范围内求解,且覆盖 完整球面(非半球) |
| 预算极紧 | 仅有不透明 Final Gather 约 1/8 的预算 |
未对天光投影阴影的半透明粒子效果极差(如右图的灰尘粒子完全失去光照层次)。
体积 Final Gather(Volumetric Final Gather)

流程概览:
1. 用 Froxel 网格(视锥体对齐的 3D 网格)覆盖视场
2. 追踪八面体探针(Octahedral Probes)
3. HZB 测试跳过不可见探针
4. 空间滤波 + 时间累积 → 降噪
5. 预积分为球谐辐照度(SH Irradiance)
6. 前向半透明 Pass / 体积雾 Pass 插值辐射度
远距离光照的噪声问题

- 即使追踪数量较多,远距离光照噪声 仍无法解决
- 典型案例:洞穴完全由通过小孔进入的天光照亮
- 解决方案:使用 另一套世界空间辐射缓存(World Space Radiance Cache)
- 更高方向分辨率 → 稳定的远距离光照
- 探针放置在可见网格周围
- 追踪后将辐射度预过滤为 MIP 层级,减少混叠
- 缩短追踪距离,未命中时从世界探针插值
- 世界探针光线数量是普通光线的 16 倍
关键优化:与不透明缓存重叠调度
半透明辐射缓存与不透明世界辐射缓存 调度重叠,使其众多 Dispatch 填入间隙,几乎零额外开销。
Lumen 反射系统
管线总览
基于 Thomas Kolák 的随机积分 + 屏幕空间降噪方案:
1. 光线生成 → 重要性采样可见 GGX 斜率(Visible GGX Slope)
2. 光线追踪 → 使用 Lumen 追踪管线
3. 空间重用 → 屏幕空间邻域查找 + BRDF 重加权
4. 时间累积 → 减少 Fireflies
5. 双边滤波 → 清理剩余噪声
6. 全帧 TAA → 最终清理
Matrix Awakens 中的逐步效果
| 阶段 | 效果 |
|---|---|
| 原始追踪 | 大量噪声 |
| 空间重用后 | 噪声显著减少,仍可见 |
| 时间累积后 | Fireflies 大幅减少,亮区仍有噪声 |
| 双边滤波后 | 残余噪声清理 |
| 全帧 TAA 后 | 进一步平滑 |
双边滤波细节

- 作为 最后手段,在物理正确的重用不够时启用
- 仅在空间重用后 高方差区域 运行
- 在 遮挡揭露区域(Disocclusion) 以 双倍强度 强制启用(无时间历史)
- 使用 Tone Mapped Weighting 去除 Fireflies
- 在空间重用阶段使用会压碎高光 → 仅在双边滤波中使用
粗糙度分级优化:核心性能策略
| 粗糙度范围 | 策略 | 效果 |
|---|---|---|
| 0.4 ~ 1.0(最粗糙) | 重用漫反射 GI — 从屏幕空间辐射缓存采样,以 GGX 重要性采样方向插值 | 跳过反射光线,成本降低 50%~70% |
| 0.3 ~ 0.4(中等光泽) | 缩短反射光线 + 未命中时从 世界空间辐射缓存 插值 | 减少方向发散,无需光线排序;Matrix Awakens 中路面反射 额外降低 16% |
| 0.0 ~ 0.3(镜面/近镜面) | 完整光线追踪 + 降噪管线 | 最高质量 |
Clear Coat 反射的高效复用
双层车漆材质:
├── 底层(光泽漆面)→ 重用屏幕空间辐射缓存(免费)
└── 顶层(Clear Coat)→ 仅追踪新光线
Tile-Based 反射管线
- 基于 Tile 的调度 → 高效跳过天空和漫反射重用区域
- 管线包含 大量 Dispatch(追踪管线更多),Tile 化确保仅处理需要的屏幕区域
- 反射管线 多次运行:
- 至少一次用于 不透明物体
- 可能额外运行用于 半透明反射 和 水面反射
Tile 边界处理的陷阱

- 降噪 Pass 读取邻域像素 → 邻域可能未被处理
- 解决方案:在时间滤波之前的 Pass 中 清除 Tile 边界
- 仅清除 未使用 Tile 中的纹素(避免与空间重用 Pass 的线程产生竞态条件)
半透明反射
┌─────────────────────────────────────────┐
│ 玻璃(最前层) │
│ → 深度剥离提取最前层到最小 G-Buffer │
│ → 重新运行反射管线(仅有效像素) │
│ → 禁用降噪器以减少管线开销 │
│ → 镜面反射质量 │
├─────────────────────────────────────────┤
│ 其他半透明层 │
│ → 使用不透明 Final Gather 的世界辐射缓存 │
│ → 低分辨率光栅化标记所需探针 │
│ → 像素着色器中插值光泽反射 │
└─────────────────────────────────────────┘
性能与可扩展性
测试条件
- 渲染分辨率:1080p
- 输出分辨率:通过时间超分辨率(TSR)上采样至 4K
- 这比原生 4K + 低质量设置的图像质量 更好
质量预设
| 预设 | 目标帧率 | 关键差异 |
|---|---|---|
| High | 60 FPS | 无 Mesh SDF 追踪,仅全局距离场(最快) |
| Epic | 30 FPS | 4× 每像素光线数,完整分辨率反射 |
场景性能数据
Lumen in the Land of Nanite(软件光追)
| 设置 | Lumen 总成本 | 备注 |
|---|---|---|
| High | 2.8 ms | 无光滑材质 → 反射成本极小,轻松 60 FPS |
| Epic | 4.6 ms | 4× 光线 → 更精确的间接阴影 |
Lyra 示例游戏(软件光追)
| 设置 | Lumen 总成本 | 备注 |
|---|---|---|
| High | 4.3 ms | 外观简洁但实时 GI + 反射工作量大 |
| Epic | — | 全分辨率反射 |
The Matrix Awakens(硬件光追 + 远场)
| 设置 | Lumen 总成本 | 备注 |
|---|---|---|
| High | 6.4 ms | 复杂场景,追踪成本更高 |
| Epic | 11.3 ms | 显著更高质量 |
建筑可视化场景(2080 Ti,Epic 设置)
| 配置 | Lumen 成本 | 备注 |
|---|---|---|
| 默认 Epic | 7.3 ms | 放大特定区域有少量可见噪声 |
| Final Gather 1 ray/pixel | 更高 | 极度平滑的间接光照 |
未来工作
| 方向 | 描述 |
|---|---|
| 发光网格显式采样 | 在降采样辐射缓存中显式采样 Emissive Meshes |
| Surface Cache 覆盖率 | 持续改善覆盖率,支持蒙皮网格(Skin Meshes) |
| 无 Surface Cache 模式 | 可能非常昂贵,仅适用于高端硬件 |
| 60 FPS 质量提升 | 在极紧预算下持续优化 |
| 植被质量 | 仍在改进中 |
整体架构回顾
Lumen 完整管线总览
┌──────────────────────────────────────────────────────────┐
│ 场景表示层 │
│ Mesh SDF / Global SDF / Surface Cache / Cards │
├──────────────────────────────────────────────────────────┤
│ 追踪方法层 │
│ 软件光追(SDF) ←──项目选择──→ 硬件光追(BVH) │
│ + 屏幕空间追踪(两者共用) │
├──────────────────────────────────────────────────────────┤
│ 光照评估层 │
│ Surface Cache(快速路径) / Hit Lighting(仅反射) │
├──────────────────────────────────────────────────────────┤
│ Final Gather 层 │
│ 屏幕空间辐射缓存 → 世界空间辐射缓存 → 全分辨率积分 │
├──────────────────────────────────────────────────────────┤
│ 反射管线 │
│ GGX 采样 → 追踪 → 空间重用 → 时间累积 → 双边滤波 │
│ + 粗糙度分级复用(辐射缓存) │
├──────────────────────────────────────────────────────────┤
│ 半透明 / 雾气 GI │
│ 体积 Final Gather(Froxel)+ 世界辐射缓存 │
├──────────────────────────────────────────────────────────┤
│ 输出 │
│ 1080p Lumen → TSR → 4K 输出 │
└──────────────────────────────────────────────────────────┘
总结
Lumen 是一个 完全动态的全局光照与反射系统,其核心设计哲学是:
- 分层缓存:Surface Cache → 屏幕辐射缓存 → 世界辐射缓存,每层解决不同空间/方向频率的问题
- 最大化复用:粗糙反射复用漫反射 GI、半透明复用不透明缓存、Clear Coat 复用底层结果
- 可扩展架构:软件/硬件光追可互换、High/Epic 预设覆盖 30~60 FPS
- 预算感知:Tile 化跳过无需处理的区域、分页更新 Surface Cache 光照、直方图式预算分配
这套系统首次在 主机硬件 上实现了无需预计算的、完全动态的多次反弹全局光照,同时保持了可发布的性能水平。