GPU Crash Debugging in Unreal Engine
GPU Crash Debugging in Unreal Engine: Tools, Techniques, and Best Practices | Unreal Fest 2023
GPU 崩溃的本质与挑战
CPU 崩溃 vs GPU 崩溃


- CPU 崩溃 相对直观:崩溃发生时立即获得 崩溃报告(Crash Report) ,所有线程被中断,可以直接检查程序在崩溃时刻的完整状态。
- GPU 崩溃 则截然不同,具有以下关键特性:
- GPU 同时运行的 线程数量远超 CPU ,当故障(fault)发生时,系统需要较长时间才能检测到崩溃。
- 崩溃报告的延迟性 :从实际 GPU 故障到收到崩溃报告之间可能有 超过 2 秒 的延迟。
- 状态信息不可靠 :由于 GPU 在故障后仍在继续执行,报告时获得的活跃作业(active jobs)可能已经与故障时刻完全不同——有些作业可能已完成,有些在故障时甚至还未启动。
- 无法确定真正的罪魁祸首 :除非有额外的主动监测手段,否则无法判断是哪个活跃作业导致了 GPU 崩溃。
Windows TDR 机制
什么是 TDR

- TDR 全称 Timeout Detection and Recovery(超时检测与恢复) ,是 Windows 系统用于检测 GPU 挂起(hang)的机制。
- 当 GPU 上提交的工作长时间未完成时,Windows 判定为 超时(Timeout) ,随后 重置 GPU 并 终止进程 。
- 正常情况下,GPU 工作应该快速、小量地完成,以保证流畅运行。
GPU 崩溃的两大类原因
1. 超时(Timeout)导致的崩溃
常见触发场景:
- 无限循环(Infinite Loops) :Shader 永远不结束,GPU 被卡死。
- 同步错误(Incorrect Synchronization) :GPU 被指令等待某个信号,但该信号永远不会到来,导致挂起。
- 极慢的 Shader :如 光线步进(Raymarching) 或 光线追踪(Raytracing) ,即使理论上会结束,但如果耗时超过 TDR 阈值也会触发崩溃。
- 物理显存耗尽(Out of Physical Memory) :GPU 开始使用 swap 后,性能急剧下降,最终触发 TDR。
- 驱动 Bug :驱动层面的问题也会表现为同样的超时错误。
2. 页面错误(Page Fault)导致的崩溃
- 类似于 CPU 上的 访问违规(Access Violation) 或 空指针异常(Null Pointer Exception) 。
- 在 DirectX 12 下,应用程序被允许进行精细的 显存管理 ,但这也引入了无效内存访问的风险。
- 如果访问了已被 驱逐(evicted) 的资源地址,GPU 就会崩溃。
- 同样存在 故障发生与崩溃报告之间的巨大延迟 。
实际案例
案例一:巫师 3 次世代版的同步 Bug
- 一个 Fence(栅栏同步) 缺少了信号(signal),导致 GPU 被永久挂起。
- 异常之处 :TDR 并未触发,程序直接永久冻结(与没有 TDR 机制时的表现一致)。
- 解决方法 :通过向 GPU 发送自定义命令来手动排查挂起原因。
案例二:过场动画团队的 TDR
- 过场团队在 Sequencer 中使用最高画质 + 无限视距渲染单帧,耗时数秒,超过 TDR 阈值。
- 解决方法 :针对 离线渲染(Offline Rendering) 场景,增大 TDR 延迟时间。
- 重要提醒 :不要在实时渲染场景中修改 TDR 延迟 ,否则会掩盖真实问题。仅在离线渲染等特殊场景下才建议调整。
案例三:PS5 上的页面错误
- 通过额外信息追踪到崩溃源自某个特定的 马克杯(mug)材质 ,该材质采样了多个 虚拟纹理(Virtual Textures) 。
- 关键线索是刚刚进行了引擎升级,许多功能尚未稳定。
- 最终确认为虚拟纹理的 Bug,先做 workaround,后等引擎补丁修复。
GPU 崩溃调试的准备工作
基础健全性检查(Sanity Check)
在深入调试之前,务必先排除基础问题:
- 更新显卡驱动 :驱动 Bug 本身就可能导致 GPU 崩溃,如果驱动有问题而去调查引擎代码,完全是浪费时间。
- 确认 GPU 硬件能力 :确保 GPU 性能和显存充足,尤其在使用光线追踪等新特性时。编辑器(Editor)运行时资源开销更大。
- 检查画质设置 :避免过高的质量设置导致资源耗尽。
- 避免全世界同时加载到显存 :这是显存耗尽崩溃的常见原因。
- 留意后台重负载进程 :如离线渲染等后台任务可能抢占 GPU 资源,间接导致崩溃。
Unreal Engine 中的 GPU 崩溃调试设置
核心调试开关
1. GPU Crash Debugging 标志
- 启用后会激活所有可用的 额外验证和 GPU 状态追踪工具 。
- 有性能开销 ,不建议默认开启,仅在调试时使用。
2. -d3ddebug 命令行参数
- 用于验证是否存在 格式错误的 D3D 命令(Malformed D3D Commands) 。
- 重要限制 :该验证在 CPU 端 执行,无法覆盖 GPU 端的所有错误,因为 CPU 端缺乏完整的 GPU 运行时信息。
- 优点是 简单快捷 ,适合作为第一步排查手段。
3. GPU Validation 标志
- 对 Shader 进行 插桩(Instrumentation) ,添加额外的运行时检查。
- 能捕获 CPU 端验证无法发现的错误:
- 不正确的描述符(Incorrect Descriptors)
- 引用已删除资源(References to Deleted Resources)
- 描述符堆越界索引(Indexing Beyond the End of a Descriptor Heap)
- 这些错误都可能导致页面错误。
4. 启用额外事件(Extra Events)
- 通过启用 材质绘制事件(Material Draw Events) 和 网格绘制事件(Mesh Draw Events) ,可以精确定位是哪个材质或网格导致了崩溃。
- 每个 Draw Call 都会包含详细的调试与性能分析信息。
- 性能代价很大 ,按需开启。
- 这些事件同样会出现在 GPU Profiler 中,便于对单个材质或网格进行性能分析。
- 前述马克杯案例正是通过启用 Mesh Events 轻松追踪到的。
5. 资源分配追踪 CVar
- 可以启用额外的 CVar 来追踪更多的 GPU 资源分配信息 ,用于页面错误的排查。
GPU Crash Debugging标志已包含此功能,两者启用其一即可,无需重复开启。
Unreal 的页面错误报告机制
- 活跃资源报告 :Unreal 会根据页面错误地址,报告该地址 前后 16MB 范围内 的所有活跃资源,有助于发现 越界访问(Out-of-Bound Access) 。
- 已释放资源报告 :Unreal 追踪最近 100 帧内释放的资源 ,报告与页面错误地址 直接重叠 的已释放资源,有助于发现 Use-After-Free 类型的 Bug。
GPU 崩溃调试工具详解
核心认知
- GPU 崩溃时 CPU 调用栈(CPU Stack)完全无用 ,因为导致崩溃的 GPU 命令是 很久以前提交的 ,CPU 端早已执行到了其他位置。
- 需要获取的是 GPU 在崩溃时刻的真实状态 ,这需要专门的工具和平台特定的手段。
PC 平台工具一览
| 工具 | 说明 |
|---|---|
| DRED(Device Removed Extended Data) | Windows 内置机制,提供大量额外的设备移除信息 |
| Breadcrumbs(面包屑) | 与 DRED 概念类似,但由用户/引擎自行实现,可自定义追踪粒度 |
| NVIDIA Aftermath | NVIDIA 专有工具,提供针对 N 卡的深度崩溃信息 |
| Radeon GPU Detective | AMD 专有工具,针对 A 卡的 GPU 崩溃调试 |
主机平台说明
- 主机平台的工具是 平台特定 的,崩溃时会生成 Dump 文件 ,可以详细查看 GPU 状态。
- 通常主机平台能提供的信息 比 PC 更多、更详细 。
- 建议 :如果能在主机上调试,优先选择主机而非 PC。
关键要点总结
- GPU 崩溃的核心困难在于 异步性 和 信息延迟 :崩溃报告可能滞后数秒,GPU 状态已面目全非。
- 两大崩溃类型:TDR 超时 (无限循环、同步错误、超慢 Shader、显存不足、驱动 Bug)和 页面错误 (无效内存访问)。
- 调试流程应从 基础排查 开始(驱动、硬件、设置),再逐步启用 调试标志和工具 。
- Unreal 提供了从
GPU Crash Debugging到d3ddebug、GPU Validation、Draw Events、资源追踪等多层次的调试手段。 - 平台专有工具(DRED、Aftermath、Radeon GPU Detective、主机 Dump)是定位崩溃根因的关键利器。
GPU 崩溃调试工具详解
DRED(Device Removed Extended Data)
基本概念
- DRED 全称 Device Removed Extended Data ,是 DirectX 12 提供的内置调试工具。
- 易于使用,适用于所有支持 DirectX 12 的硬件,且 Unreal 已原生支持 。
工作原理
- DRED 会在 每个渲染操作之后自动插入标记(Marker) ,整个过程是全自动的,用户几乎不需要手动控制。
- Unreal 近期新增了 轻量级 DRED(Lightweight DRED) 支持:
- 追踪更少的操作,开销更低。
- 因此可以更方便地 默认启用 。
崩溃报告内容
- 崩溃时,DRED 会报告一个 命令列表(Command List) ,显示崩溃瞬间已完成的操作序列。
- 例如:报告可能显示已完成 6~7 个操作,但 无法保证最后的操作就是真正导致崩溃的元凶 (因为前面提到的延迟问题)。
页面错误数据
- DRED 还包含 页面错误(Page Fault) 数据,非常有用:
- 报告 发生页面错误的虚拟地址 。
- 追踪 最近使用和释放的资源 ,不过不像 Unreal 内置追踪那样限定在 16MB 范围内。
- 页面错误报告会列出:
- 活跃对象(Active Objects) :当前仍在使用的资源。
- 最近释放的对象(Recently Freed Objects) :最近被释放但地址范围匹配的资源。
- 所有这些都在 页面错误发生的虚拟地址范围内 。
Radeon GPU Detective(AMD 专用)
特点
- 比 DRED 或 Breadcrumbs 更精确 。
- 拥有 更严格的检测机制 :指示驱动在更早的时间点崩溃,并携带 更多信息 。
- 同样支持 页面错误时的资源追踪 。
限制
- 需要在 驱动层级启用 ,要求驱动进入 特殊模式(Spatial Mode) 才能进行崩溃分析。
- 硬件限制 :仅支持 AMD RX 6000 和 7000 系列 显卡。
NVIDIA Aftermath(NVIDIA 专用)
特点
- 是 NVIDIA 版本的 GPU 崩溃分析工具,功能等同于 Radeon GPU Detective。
- 已集成到 Unreal 中。
- 当 TDR 发生时 ,生成一个 转储文件(Dump) ,供后续检查。
信息丰富度
- 相比 DRED 或 Breadcrumbs,Aftermath 包含 更多 GPU 状态信息 :
- 寄存器值(Register Values)
- 活跃的 Warp 信息(Active Warps)
- 同样追踪 虚拟地址 。
可发行性
- 与 Radeon GPU Detective 不同,NVIDIA Aftermath 可以随产品一起发行(Ship) ,这意味着可以在最终用户的机器上收集崩溃数据。
Breadcrumbs 系统(Unreal 自研)
定位
- Breadcrumbs 是 用户自行实现的 、等效于上述三种工具的替代方案。
- 需要 手动决定 何时写入标记、写入什么信息。
- DRED 底层机制类似,但 提供给用户的控制权更少 。
旧版 Breadcrumbs 的缺陷
- 只报告 最后一个开始或完成的标记 ,信息量非常有限,且 可能不正确 。
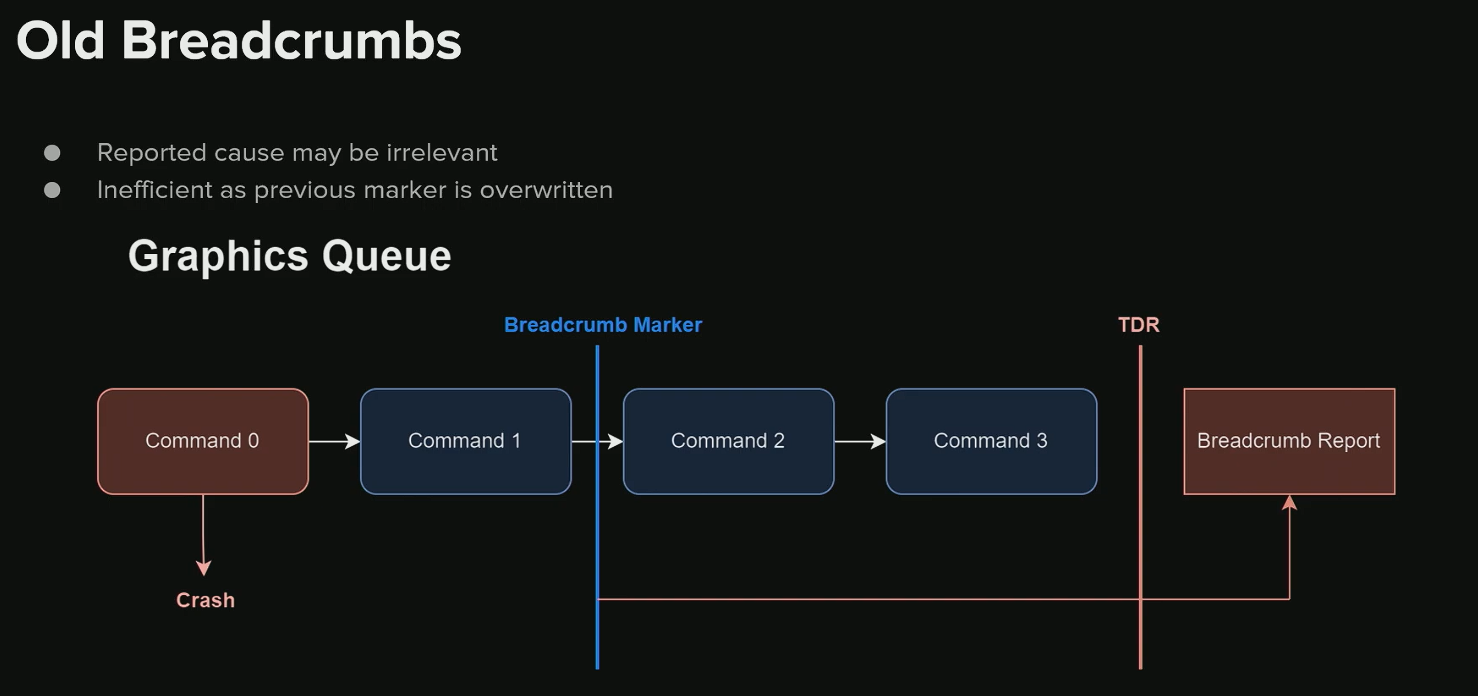
错误报告示例
假设命令执行顺序如下:
- Command 0 实际导致了崩溃。
- 但 GPU 在 TDR 触发前继续执行了 Command 1 。
- 旧版 Breadcrumbs 只报告 最后的标记 ,即 Command 1 之后的标记。
- 结果:报告会错误地指向 Command 1 ,这是一个 误导(Red Herring) 。
- 根据崩溃类型不同,实际故障与报告之间的时间差可能极大 。
新版 Breadcrumbs(从 RED Engine 移植)
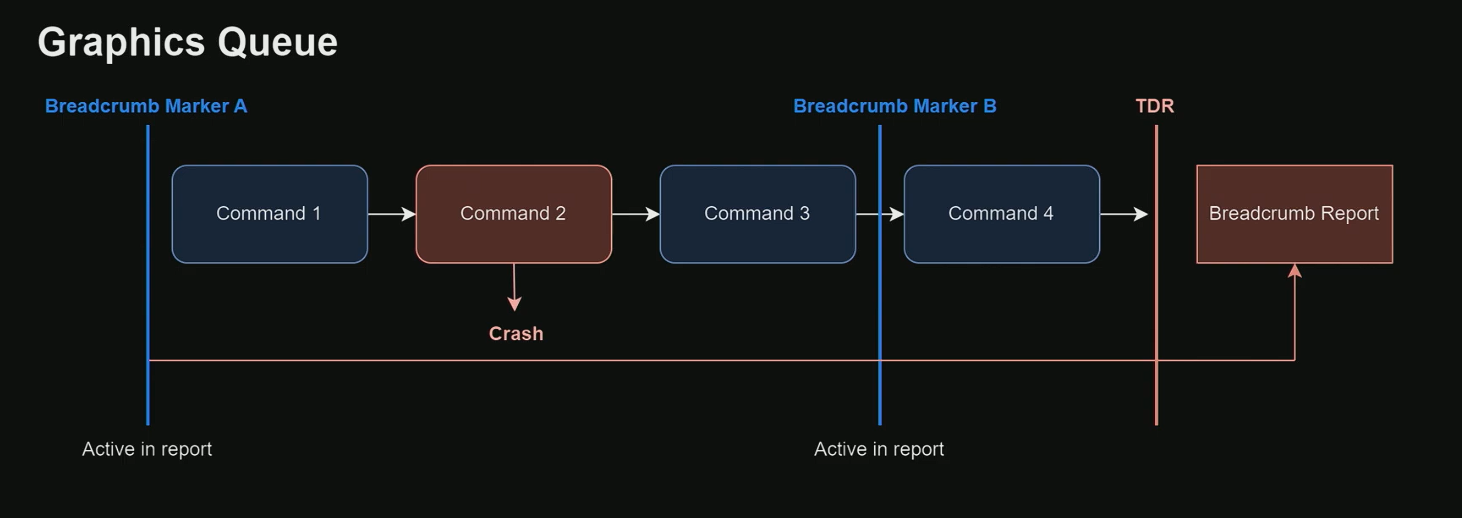
- 由 CD Projekt RED 从 RED Engine 移植到 Unreal ,已在 GitHub 上可用 。
核心改进
- 在 GPU 上维护一个 更大的缓冲区 ,追踪 所有作用域(Scopes) 的状态。
- 崩溃时,返回 所有活跃的 Breadcrumb 标记及其关联状态 。
改进示例
- 假设 Command 2 导致崩溃,且存在 标记 A 和 标记 B :
- TDR 触发时,新系统返回 所有活跃 Breadcrumbs 及其状态 。
- 报告展示完整的 层级结构(Hierarchy) 和每个作用域的状态。
报告特点
- 清晰显示哪些路径处于活跃状态 。例如:
- 可能同时看到 Nanite 硬件光栅化 和 软件光栅化 路径都在活跃——任一路径都可能是崩溃元凶。
- 旧版可能只会显示软件光栅化路径。
- 支持 Compute Queue :不仅追踪图形队列,还追踪 计算队列 上的标记层级。
新版 Breadcrumbs 实现细节
标记层级系统
- 所有标记具有 层级结构(Hierarchy) 。
- 标记的调度基于 GPU Profiler 的事件 ,通过 RHI Push Events 推送。
- RHI Push Events 触发对 共享缓冲区(Shared Buffer) 的写入。
- 写入操作使用 WriteBufferImmediate 命令,缓冲区包含所有标记。
- 层级结构与 GPU Profiler 中看到的完全一致 。
缓冲区分配
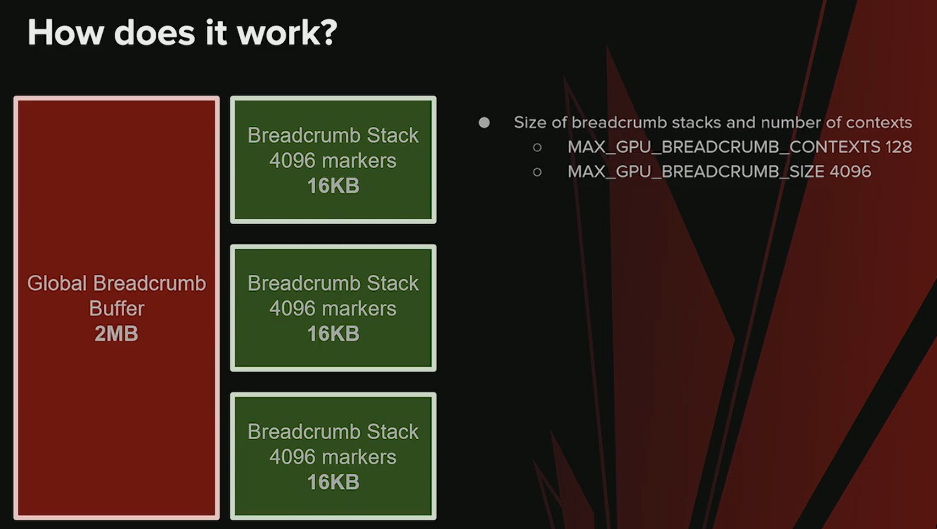
- 应用启动时 预分配 Breadcrumb 缓冲区 :
- 默认大小为 2MB 。
- 使用 OpenExistingHeapFromAddress 创建,使缓冲区在 CPU 和 GPU 之间共享 。
- 关键特性 :即使 GPU 崩溃、驱动不再允许访问 GPU,该缓冲区在 CPU 端 仍然可读 。
栈(Stack)结构
- 2MB 缓冲区作为 内存池 ,从中分配和回收栈。
- 单个栈 最多包含 4,096 个标记 。
- 一个栈用于容纳 完整的作用域层级 。
- 这些数值是根据 Unreal 的典型工作负载 选定的。
- 可通过修改 C++ 中的 define 宏 调整缓冲区大小。
WriteBufferImmediate 命令
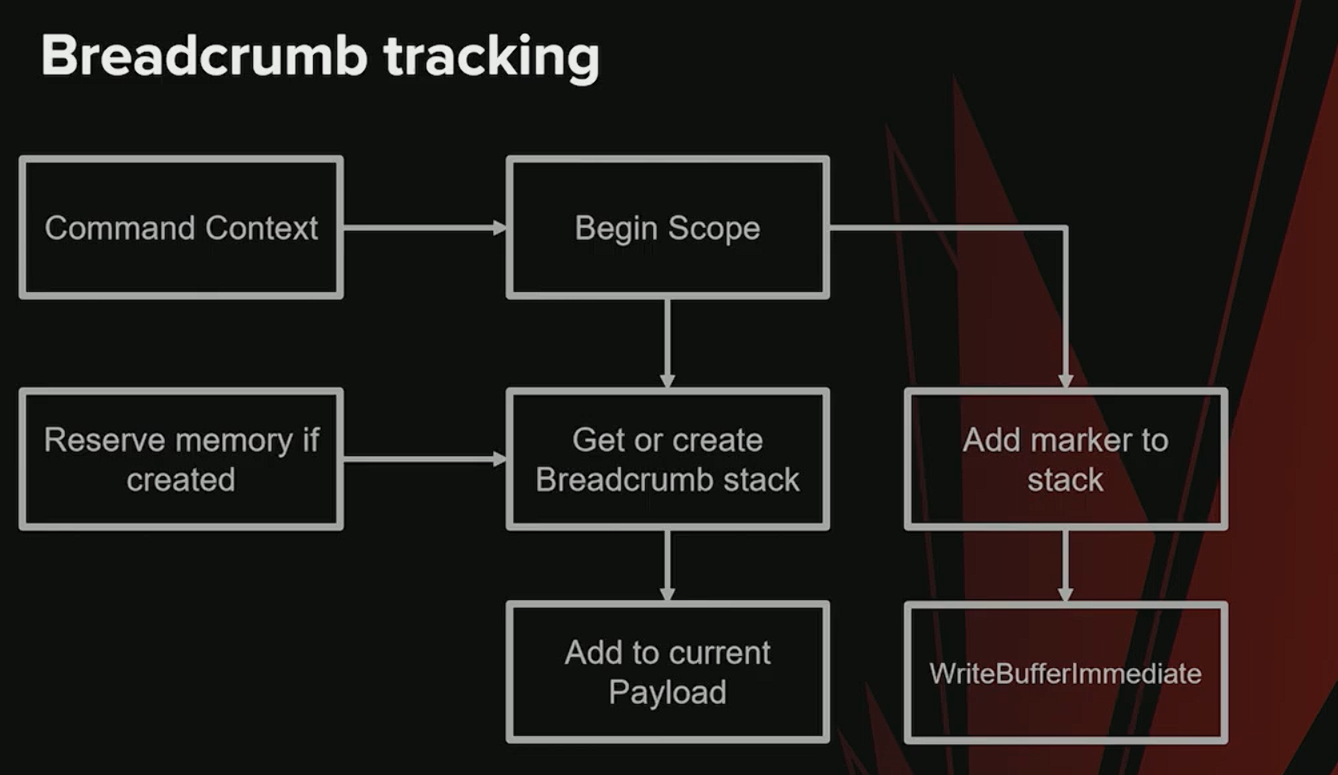 用于将标记写入 Breadcrumb 栈,需要传入:
用于将标记写入 Breadcrumb 栈,需要传入:
- 标记地址
- 标记值
- 写入模式
标记状态(Marker States)
| 状态 | 值 | 含义 |
|---|---|---|
| Non-Started | 0 | 默认状态,工作尚未开始 |
| Active | — | 工作已在 GPU 上开始执行 |
| Finished | — | 所有先前的工作已在 GPU 上完成 |
| Overflow | — | 超过 4,096 标记限制 |
| Invalid | — | 发生了其他错误 |
写入模式(Write Modes)
- Marker In :当所有 之前调度的工作已开始 时才写入。
- Marker Out :当所有 之前的工作已完成 时才写入(写操作被 延迟(Deferred) 直到工作完成)。
栈与标记的生命周期管理
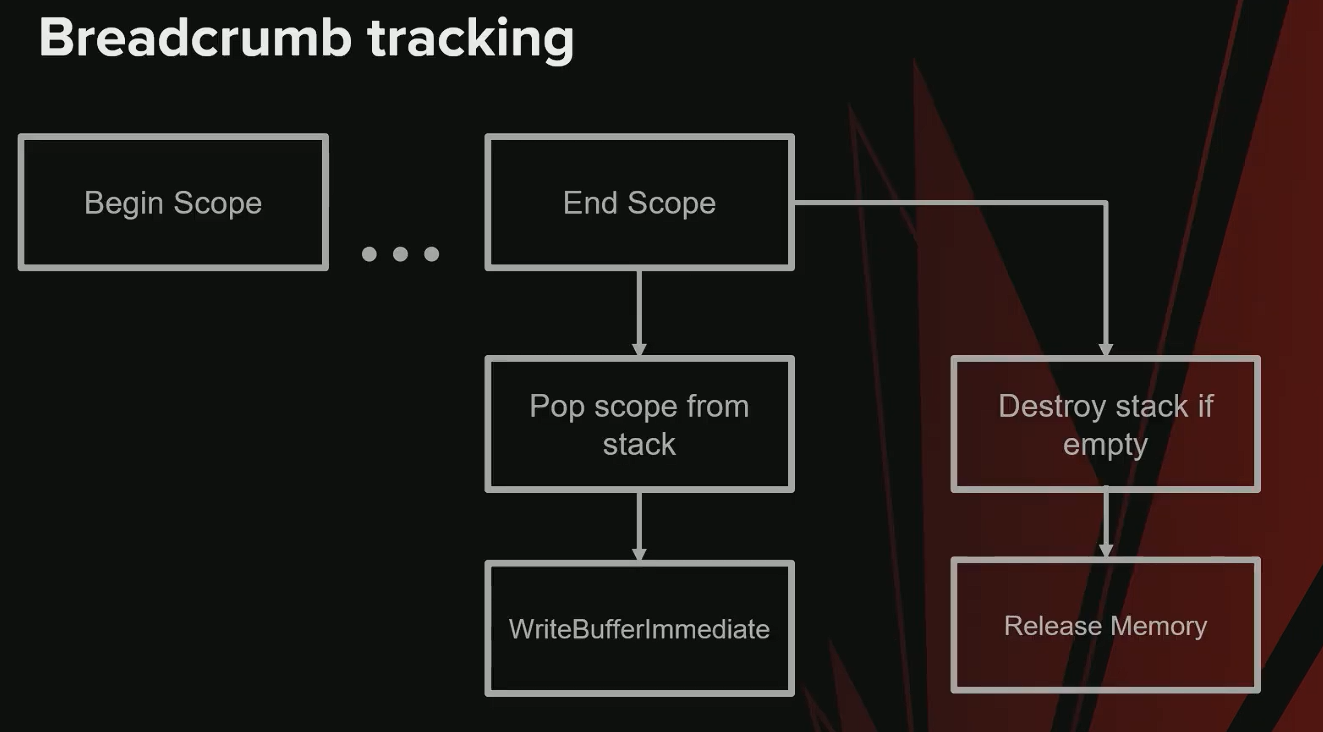
Begin Scope(开始作用域)
- Command Context 负责生成 GPU 工作,创建 命令列表(Command Lists) 并打包为 Payload 发送到 GPU。
- 进入作用域时,需要将标记的 Active 状态 写入 GPU。
- 获取当前 Payload 关联的 Breadcrumb Stack :
- 如果当前 Payload 尚无栈 → 从 内存池中预留内存 。
- 将栈添加到 Payload,然后 写入标记 并调用 WriteBufferImmediate 。
End Scope(结束作用域)
- 使用 WriteBufferImmediate 写入 Finished 状态 。
- 从栈中 弹出(Pop) 该作用域。
- 如果栈为空且无其他引用 → 销毁栈 ,内存归还池中供复用。
崩溃时的数据读取
- 收集所有活跃 Payload 及其关联的栈。
- 遍历所有栈中的标记 ,从 CPU 端仍可访问的缓冲区中 读取状态 。
- 将状态 打印到日志 。
Payload 生命周期与提交线程
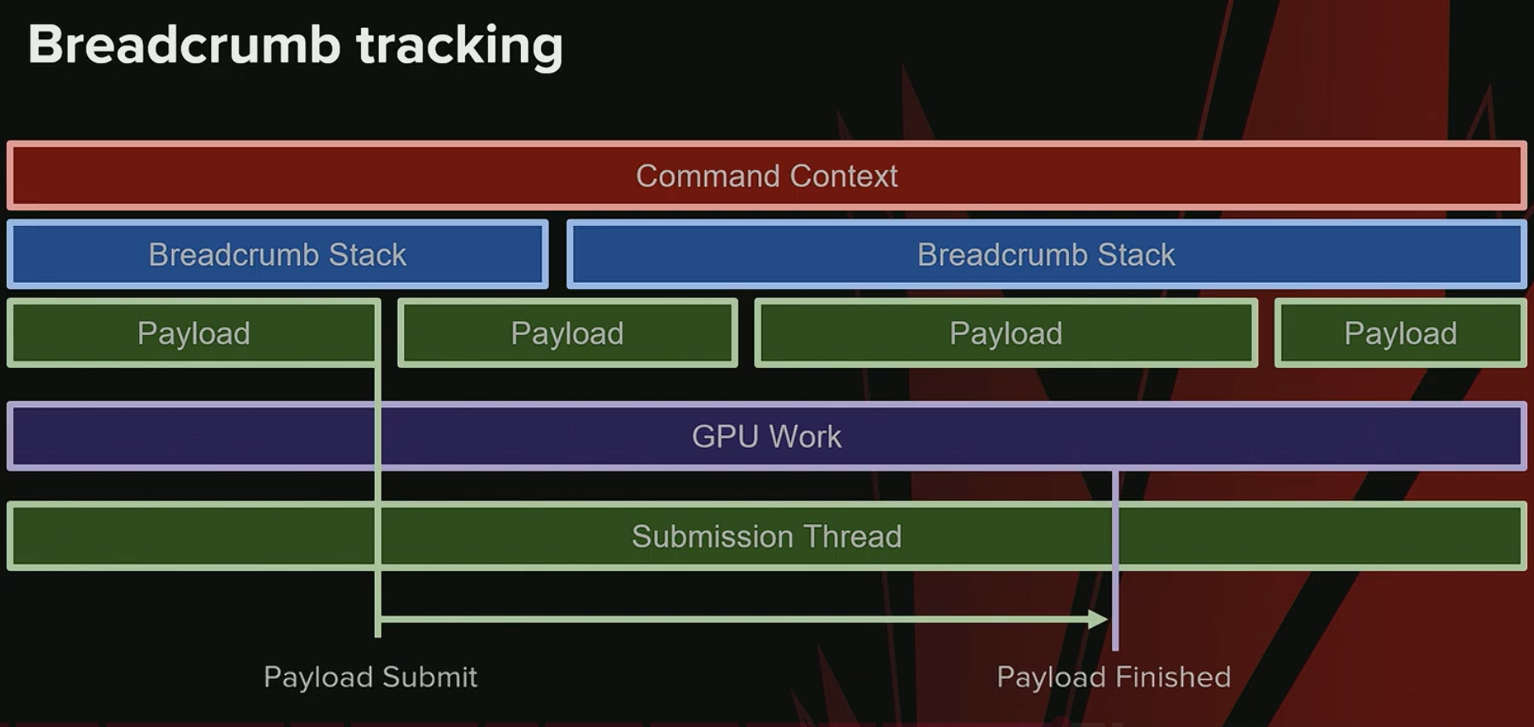
- Payload 提交到 GPU 后,工作开始执行。
- Unreal 的 提交线程(Submission Thread) 追踪所有 Payload 的完成情况。
- Payload 完成时 → 安全释放 该 Payload 引用的所有栈。
- Payload 合并 场景:如果多个 Payload 被合并,需要将所有 Breadcrumb 栈引用 合并到目标 Payload 中。
内存效率问题与优化
问题
- 每个栈固定从池中取 16KB 内存块。
- 在编辑器的某些工作负载下,一个栈可能 只包含一条命令 。
- 结果:实际只用了 4 字节 ,却占用了 16KB → 严重的内存浪费。
解决方案
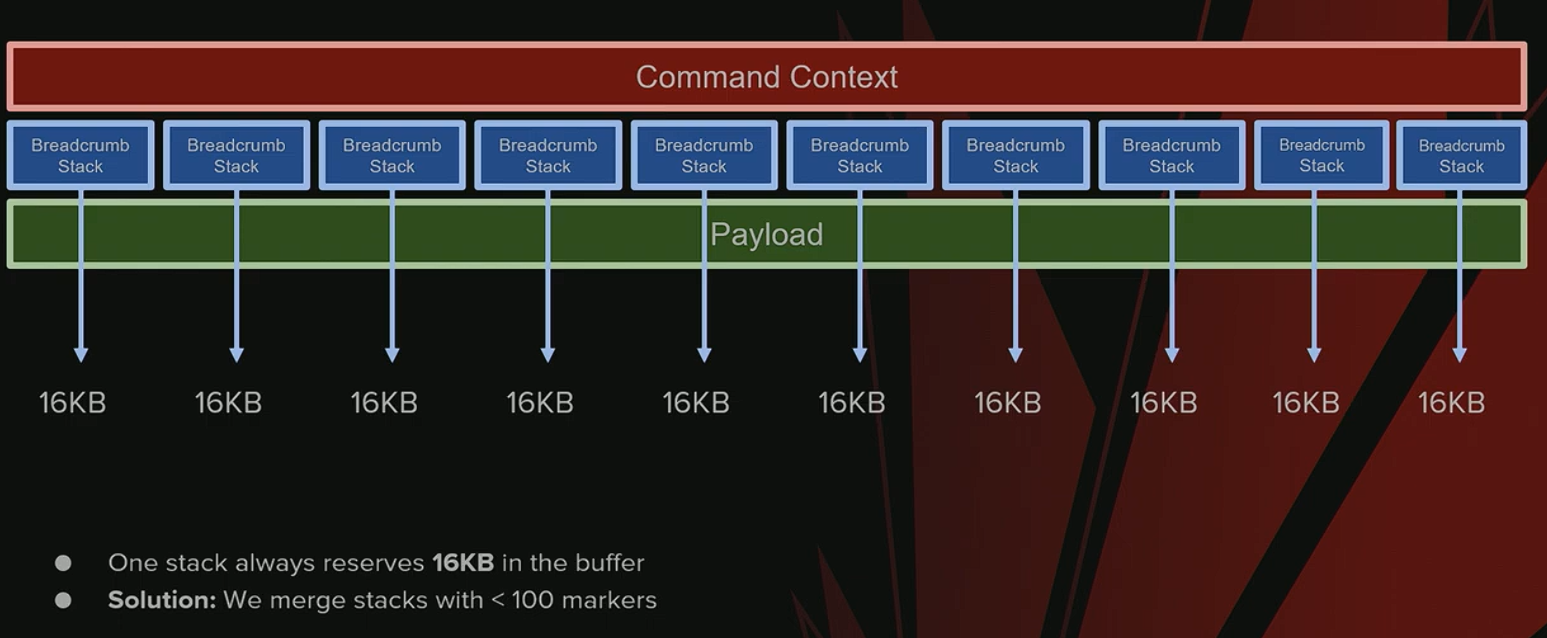
- 当栈中标记少于 100 个 时,将多个栈 合并 。
- 代价 :合并后的栈会被保持存活 更长时间 (因为需要等待所有关联 Payload 完成)。
工具对比总结
| 特性 | DRED | Radeon GPU Detective | NVIDIA Aftermath | Breadcrumbs(新版) |
|---|---|---|---|---|
| 平台 | 所有 DX12 硬件 | AMD RX 6000/7000 | NVIDIA GPU | 所有平台 |
| 精确度 | 中 | 高 | 高 | 中-高 |
| 自动化程度 | 全自动 | 需驱动级启用 | 集成到 Unreal | 手动控制 |
| 页面错误追踪 | ✅ | ✅ | ✅ | ❌(需配合其他工具) |
| 可随产品发行 | ✅ | ❌ | ✅ | ✅ |
| GPU 状态信息 | 有限 | 丰富 | 最丰富(含寄存器/Warp) | 作用域层级状态 |
| 用户控制权 | 低 | 中 | 中 | 高 |
Breadcrumbs 系统的局限性
缓冲区大小问题
- 游戏模式与编辑器模式下的 命令列表大小差异巨大 :编辑器中命令列表可能非常庞大。
- 如果 缓冲区空间不足 ,可能无法记录崩溃时标记的真实状态。
- 解决方案:调试编辑器崩溃时,可以手动 增大缓冲区大小 。
性能开销
- 向 CPU 和 GPU 添加 Write Buffer Immediate 命令存在 非零的性能开销 。
- 当 作用域(Scope)数量很多 时(例如报告每个 Mesh 和材质的绘制事件),开销会变得显著。
- DRED 默认对每个渲染操作都启用标记 ,因此开销较大。
- 发行建议 :如果要在正式发行的游戏中使用 Breadcrumbs,应 减少作用域数量 ,确保性能影响可忽略。
与厂商工具的对比
- 厂商专用工具 (如 NVIDIA Aftermath、Radeon GPU Detective)对硬件有更直接的访问权限,因此 更加精确 。
- 对于 复杂崩溃 ,推荐优先使用厂商工具而非 DRED 或 Breadcrumbs。
GPU 崩溃报告系统
旧系统的问题
- 最初过渡到 Unreal 时,采用非常简单的追踪方式:
- 所有 GPU 崩溃归入同一个 Jira 工单 。
- 需要 手动获取日志 才能了解崩溃详情。
- 工单基于 CPU 调用栈 分组,但所有 GPU 崩溃的 CPU 调用栈几乎相同,因此 毫无区分度 。
新系统的工作流程
整体流程
- 崩溃发生 → 收集 Breadcrumbs 数据
- 处理 Breadcrumbs :过滤并分组,仅保留相关标记
- 输出到日志 并上传崩溃报告
- 后端脚本 解析日志,提取 Breadcrumbs,生成哈希值,自动创建 Jira 工单
关键细节
- 未使用页面错误信息进行哈希 ,因为 Breadcrumbs 无法获取该数据。
- 如果使用 DRED、NVIDIA Aftermath 或 Radeon GPU Detective,则可以补充页面错误信息。
Breadcrumbs 过滤与哈希流程
分组依据
- 以 最后完成的作用域(Last Finished Scope) 和 活跃作用域(Active Scope) 作为分组依据。
- 目标:相同类型的崩溃归入同一个 Jira 工单 ,便于检查和按频率排列优先级。
五步过滤流程
第一步:解析日志
- 从崩溃时获取的日志中提取 Breadcrumbs 原始数据。
第二步:移除已完成的工作(保留最后一个)
- 对层级结构中的每个作用域,只保留最后完成的操作 ,移除其余已完成的操作。
- 这样既保留了一定的 上下文信息 ,又不会引入过多无用数据。
第三步:移除未启动的工作(保留最后一个)
- 同样,只保留最后一个未启动的作用域 ,因为它可以提供关于 GPU 上计划执行的工作类型的上下文。
- 移除其余所有未启动的作用域。
第四步:移除动态数据
- 过滤后的 Breadcrumbs 中仍然包含 用户指定的动态数据 ,例如:
- 纹理数量、缓冲区数量
- Lumen 场景更新中的 Card Capture 数量
- 使用的纹素大小(MB)
- 如果直接用这些数据做哈希,每次崩溃的数值不同会导致 产生大量不同的工单 。
- 解决方法非常简单 :将所有数字替换为
x。- 例如:
Lumen Scene Update (3 card captures, 128MB texels)→Lumen Scene Update (x card captures, xMB texels)
- 例如:
第五步:生成哈希并创建工单
- 对过滤后的 Breadcrumbs 输入 哈希函数 ,生成唯一哈希值。
- 以 最后活跃的作用域名称 作为工单标题(例如
Build Page Update Histogram)。 - 标题可能并非总是准确反映真正的崩溃原因,但作为额外信息仍然有用。
过滤效果
- 从原始的大量日志输出 → 经过过滤后只剩下 非常精简的调用栈 。
- 工单标题直接提示崩溃区域:阴影(Shadows) 、 蒙皮(Skinning) 、 Lumen 等,远比之前的"发生了一次 GPU 崩溃"有用得多。
总结与现有不足
假阴性问题(False Negatives)
- 由于 GPU 执行的 不确定性 ,无法确切知道:
- 崩溃时还有哪些 其他活跃工作 在运行。
- 哪个活跃工作真正导致了崩溃 。
- 结果:同一个崩溃可能生成多个不同的 Jira 工单 。
- 未来改进方向:可以通过 模式匹配(Pattern Matching) 来合并相似工单。
缺少页面错误支持
- Breadcrumbs 本身 无法访问页面错误数据 。
- 但 DRED 等工具可以 ,因此可以结合使用:记录页面错误信息和崩溃范围内的资源。
不可靠的报告
"Command List All Finished" 问题
- 最常见的工单类型 :所有标记都显示为"已完成"。
- 这意味着 Breadcrumbs 获取的标记状态全部为完成状态,无法提供任何有用信息。
- 可能是 驱动 Bug 或其他原因,原因不明。
- 此时只能依赖 更高级的工具 进一步调查。
信息过少的报告
- 有时返回的 Breadcrumbs 信息量极小 ,尤其在编辑器中大量工作同时进行时。
- 解决方法:
- 使用 更高级的调试工具 。
- 如果能在 主机平台(Console) 上复现,则可获取更多信息(主机平台提供更详细的 GPU 崩溃数据)。
核心要点回顾
| 方面 | 要点 |
|---|---|
| 工具选择 | 简单场景用 DRED/Breadcrumbs,复杂崩溃用厂商专用工具 |
| 发行版 | 减少 Breadcrumbs 作用域数量以降低开销 |
| 崩溃分组 | 过滤 → 去除动态数据 → 数字替换为 x → 哈希 → 自动建工单 |
| 当前局限 | 假阴性、缺少页面错误信息、"全部完成" 类无用报告 |
| 未来方向 | 模式匹配改进分组、集成页面错误数据、跨工具信息融合 |